
python模块部分----模块、包、常用模块
0.来源:https://www.cnblogs.com/jin-xin/articles/9987155.html
1.导入模块
1.1模块就是一个python文件,模块名是文件名
1.2导入模块的执行步骤:
先看有没有导入过,有的话不管,没有的话下一步
在sys.path中找到模块(除了内置Python的路径,还有当前执行文件路径)
创建新模块的命名空间,执行一遍模块代码,初始化模块
将模块导入进来
1.3import(导入模块)
直接导入整个模块,模块中的变量全部在他自己的命名空间中,不可覆盖原则,使用.变量名的形式可访问内部变量。因为已经执行过模块一次,内存中可以找到变量
1.4from XXX import YYY(导入具体的变量)
将变量导入到本模块的命名空间中,可覆盖原则
1.5__all__和from XXX import *
__all__和from XXX import *是成对使用的,互相作用,与其他的不作用。__all__限制能导入到其他模块命名空间中的变量有哪些
1.6__name__
#编写好的一个python文件可以有两种用途: 一:脚本,一个文件就是整个程序,用来被执行 二:模块,文件中存放着一堆功能,用来被导入使用 #python为我们内置了全局变量__name__, 当文件被当做脚本执行时:__name__ 等于'__main__' 当文件被当做模块导入时:__name__等于模块名 #作用:用来控制.py文件在不同的应用场景下执行不同的逻辑(或者是在模块文件中测试代码) if __name__ == '__main__':
1.7模块的搜索路径全在sys.path中
2.导入包
2.1包是多个模块的集合,其中含有__init__.py文件
#官网解释 Packages are a way of structuring Python’s module namespace by using “dotted module names” 包是一种通过使用‘.模块名’来组织python模块名称空间的方式。 #具体的:包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来 #需要强调的是: 1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错 2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块
2.2执行过程
与导入模块不同的是,执行的是__init__.py文件
2.3注意事项
#1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。 #2、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件 #3、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
2.4搜索路径sys.path
每次执行时候,搜索路径除了有python内置的默认库路径外,每次都会将当前的路径加入到sys.path中的第一个位置
这可能就会导致一个问题,当库文件的位置变化时候,加深一次或者怎么样的时候,__init__文件或者import可能就会发生错误。
推荐使用相对路径
2.5导入包的理解
其实就是在当前执行文件的路径找到相对应的文件夹(包)或者python文件
推荐使用各种./..找文件夹(路径)的方式找到即可
相对路径可能会导致包外可正常使用,包内互相导入可能会出错,因为包内向上翻目录时候可能会出错,因为寻找的根目录变了,根目录总是以执行文件所在的目录为根目录
2.6多重包的设置
一个包还包含其他包的时候,在包的__init__.py文件中要初始化也就是import他的子模块和子包,因为导入包就是导入__init__.py这个文件。你要让这个文件中能把所有的包和子模块加载进来,不然使用的时候XXX.YYY.ZZZ根本使用不了,内部的啥东西都使用不了,因为根本没有加载进来。
导入模块因为执行了他,所以内部变量都能找到,倒入包的时候不是执行整个包而是执行init文件,所以要把所有的东西导入到init文件中
2.7执行文件的根目录为今后一切找包的根目录,是今后一切import语句,from语句关键字的根目录,是sys.path的第一项!!!(理解、理解)
2.7.1包以及包所包含的模块都是用来被导入的,而不是被直接执行的。而环境变量都是以执行文件为准的
比如我们想在glance/api/versions.py中导入glance/api/policy.py,有的同学一抽这俩模块是在同一个目录下,十分开心的就去做了,它直接这么做
#在version.py中 2 3 import policy 4 policy.get()
没错,我们单独运行version.py是一点问题没有的,运行version.py的路径搜索就是从当前路径开始的,于是在导入policy时能在当前目录下找到
但是你想啊,你子包中的模块version.py极有可能是被一个glance包同一级别的其他文件导入,比如我们在于glance同级下的一个test.py文件中导入version.py,如下
from glance.api import versions ''' 执行结果: ImportError: No module named 'policy' ''' ''' 分析: 此时我们导入versions在versions.py中执行 import policy需要找从sys.path也就是从当前目录找policy.py, 这必然是找不到的 '''
2.8 绝对导入与相对导入总结


绝对导入与相对导入 # 绝对导入: 以执行文件的sys.path为起始点开始导入,称之为绝对导入 # 优点: 执行文件与被导入的模块中都可以使用 # 缺点: 所有导入都是以sys.path为起始点,导入麻烦 # 相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入 # 符号: .代表当前所在文件的文件加,..代表上一级文件夹,...代表上一级的上一级文件夹 # 优点: 导入更加简单 # 缺点: 只能在导入包中的模块时才能使用 #注意: 1. 相对导入只能用于包内部模块之间的相互导入,导入者与被导入者都必须存在于一个包内 2. attempted relative import beyond top-level package # 试图在顶级包之外使用相对导入是错误的,言外之意,必须在顶级包内使用相对导入,每增加一个.代表跳到上一级文件夹,而上一级不应该超出顶级包
3.约定优于配置
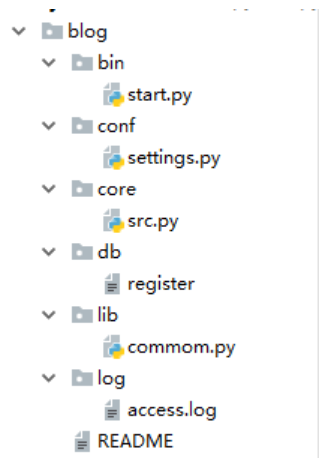
#===============>start.py # 开启项目的start文件。 import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from core import src if __name__ == '__main__': src.run() #===============>settings.py # 配置文件,放一些路径或者信息等配置 import os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) DB_PATH=os.path.join(BASE_DIR,'db','db.json') LOG_PATH=os.path.join(BASE_DIR,'log','access.log') LOGIN_TIMEOUT=5 """ logging配置 """ # 定义三种日志输出格式 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': LOG_PATH, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, }, } #===============>src.py # 主要逻辑部分: # 核心逻辑,代码放在这。 from conf import settings from lib import common import time logger=common.get_logger(__name__) current_user={'user':None,'login_time':None,'timeout':int(settings.LOGIN_TIMEOUT)} def auth(func): def wrapper(*args,**kwargs): if current_user['user']: interval=time.time()-current_user['login_time'] if interval < current_user['timeout']: return func(*args,**kwargs) name = input('name>>: ') password = input('password>>: ') db=common.conn_db() if db.get(name): if password == db.get(name).get('password'): logger.info('登录成功') current_user['user']=name current_user['login_time']=time.time() return func(*args,**kwargs) else: logger.error('用户名不存在') return wrapper @auth def buy(): print('buy...') @auth def run(): print(''' 购物 查看余额 转账 ''') while True: choice = input('>>: ').strip() if not choice:continue if choice == '1': buy() #===============>db.json # 重要数据放在这里 #===============>common.py # 公共组件放在这里:公共功能部分。 from conf import settings import logging import logging.config import json def get_logger(name): logging.config.dictConfig(settings.LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(name) # 生成一个log实例 return logger def conn_db(): db_path=settings.DB_PATH dic=json.load(open(db_path,'r',encoding='utf-8')) return dic #===============>access.log # 日志信息 [2017-10-21 19:08:20,285][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功] [2017-10-21 19:08:32,206][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功] [2017-10-21 19:08:37,166][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在] [2017-10-21 19:08:39,535][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在] [2017-10-21 19:08:40,797][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在] [2017-10-21 19:08:47,093][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在] [2017-10-21 19:09:01,997][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功] [2017-10-21 19:09:05,781][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在] [2017-10-21 19:09:29,878][MainThread:8812][task_id:core.src][src.py:19][INFO][登录成功] [2017-10-21 19:09:54,117][MainThread:9884][task_id:core.src][src.py:19][INFO][登录成功]
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
软件定位,软件的基本功能。
运行代码的方法: 安装环境、启动命令等。
简要的使用说明。
代码目录结构说明,更详细点可以说明软件的基本原理。
常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号