

【大数据之Hadoop篇】【1】hadoop集成环境搭建
1. 环境准备
1) hadoop集成环境至少需要三台虚拟机,所以先搭建一台ubuntu的虚拟机,配置好java环境,再克隆两台;
2) 修改主机名,sudo vim /etc/hostname,三台主机的名称分别为master、slave1、slave2。
3) 配置上网环境,设置静态ip,sudo vim /etc/network/interfaces,重启网络,sudo /etc/init.d/networking restart
auto eth0 iface eth0 inet static address 192.168.204.130 netmask 255.255.255.0 gateway 192.168.204.2 dns-nameservers 192.168.204.2
2. 修改hosts文件
1) 将三台虚拟机的ip地址都转换成域名访问,sudo vim /etc/hosts,格式如下:
ip1 master
ip2 slave1
ip3 slave2
3. ssh免密码登陆
1) 安装ssh,sudo apt-get ssh
2) 生成ssh密钥对,ssh-keygen -t rsa
3) 配置本地无密码登陆,cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
4) 测试本地无密码登陆,ssh localhost
5) 分发master主节点的公钥,
scp ~/.ssh/id_rsa.pub slave1:~/
scp ~/.ssh/id_rsa.pub slave2:~/
6) 将公钥追加到authorized_keys,cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
7) 验证是否相互之间是否可以无密码登陆,ssh master、ssh slave1、ssh slave2
注释:此处的三台虚拟机的authorized_keys,最好都含有三台主机的ssh公钥。
4. hadoop安装
1) 下载hadoop
2) 解压并移动到/usr/local文件夹中
tar -zxvf hadoop2.6.4.tar.gz
sudo mv hadoop2.6.4 /usr/local/hadoop
5. 配置hadoop环境变量
1) 在配置文件中追加环境变量, sudo vim /etc/profile,如下:
export JAVA_HOME=/usr/lib/jvm/jdk export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
注释:如果显示更详细的Hadoop启动和运行信息,添加export HADOOP_ROOT_LOGGER=DEBUG,console,不过一般不推荐用
6. 编辑hadoop配置文件
1) hadoop-env.sh,添加java环境变量
export JAVA_HOME=/usr/lib/jvm/jdk
2) core-site.xml,创建临时目录/home/gmr/tmp,这里一定要在用户名下,不然hadoop启动后,通过web检查显示为Unhealthy nodes
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/gmr/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
3) yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
4) mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
5) 创建namenode和datanode目录
mkdir -p ~/hdfs/namenode
mkdir -p ~/hdfs/namenode
sudo mv ~/hdfs /hdfs
6) hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
7) 配置masters和slaves文件
由于在/usr/local/hadoop/etc/hadoop/目录中没有masters文件,所以需要创建,cp slaves masters
在masters文件中删除所有,并添加master
在slaves文件中删除所有,并添加slave1、slave2
8) 分发配置好的hadoop到所有节点,并移动到/usr/local/hadoop
scp /usr/local/hadoop slave1:~/
scp /usr/local/hadoop slave2:~/
sudo mv ~/hadoop /usr/local/hadoop
7. 格式化namenode
hadoop namenode -format
8. 启动hadoop
start-all.sh
9. 验证hadoop集成环境是否正确搭建
1) jps命令查看


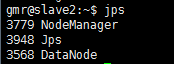
2) 网页查看


3) 启动JobHistoryServer进程的命令
mr-jobhistory-daemon.sh start historyserver

10. 运行示例程序
1) 创建hdfs文件夹,hadoop fs -mkdir -p input
2) 将本地文件传到hdfs文件夹中,hadoop fs -put test.txt input
3) 执行作业命令,hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+'
4) 查看结果,hadoop fs -cat output/part-r-00000
5) 可以根据网页来查看作业进度等信息,http://master:8088

