
转:http://blog.csdn.net/v_july_v/article/details/7184318
作者:July。
出处:结构之法算法之道
引言
昨日看到几个关键词:语义分析,协同过滤,智能推荐,想着想着便兴奋了。于是昨天下午开始到今天凌晨3点,便研究了一下推荐引擎,做了初步了解。日后,自会慢慢深入仔细研究(日后的工作亦与此相关)。当然,此文也会慢慢补充完善。
本文作为对推荐引擎的初步介绍的一篇导论性的文章,将略去大部分的具体细节,侧重用最简单的语言简要介绍推荐引擎的工作原理以及其相关算法思想,且为了着重浅显易懂有些援引自本人1月7日在微博上发表的文字(特地整理下,方便日后随时翻阅),尽量保证本文的短小。不过,事与愿违的是,文章后续补充完善,越写越长了。
同时,本文所有相关的算法都会在日后的文章一一陆续具体阐述。本文但求微言导论,日后但求具体而论。若有任何问题,欢迎随时不吝赐教或批评指正。谢谢。
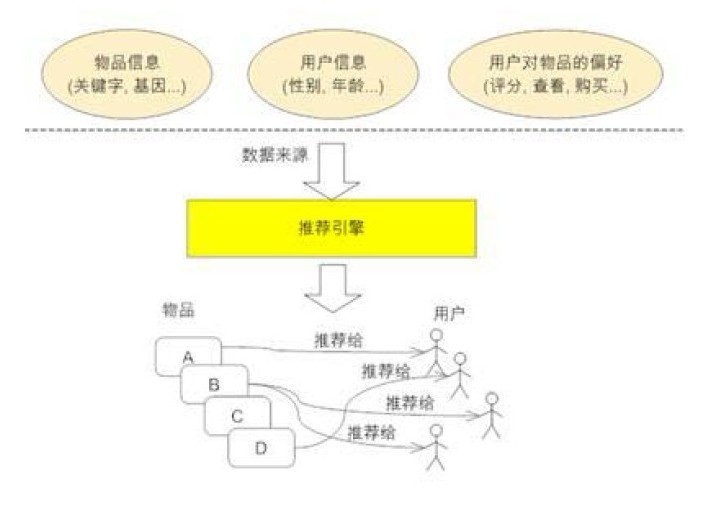
1、推荐引擎原理
推荐引擎尽最大努力的收集尽可能多的用户信息及行为,所谓广撒网,勤捕鱼,然后“特别的爱给特别的你”,最后基于相似性的基础之上持续“给力”,原理如下图所示(图引自本文的参考资料之一:探索推荐引擎内部的秘密):
2、推荐引擎的分类
推荐引擎根据不同依据如下分类:
- 根据其是不是为不同的用户推荐不同的数据,分为基于大众行为(网站管理员自行推荐,或者基于系统所有用户的反馈统计计算出的当下比较流行的物品)、及个性化推荐引擎(帮你找志同道合,趣味相投的朋友,然后在此基础上实行推荐);
- 根据其数据源,分为基于人口统计学的(用户年龄或性别相同判定为相似用户)、基于内容的(物品具有相同关键词和Tag,没有考虑人为因素),以及基于协同过滤的推荐(发现物品,内容或用户的相关性推荐,分为三个子类,下文阐述);
- 根据其建立方式,分为基于物品和用户本身的(用户-物品二维矩阵描述用户喜好,聚类算法)、基于关联规则的(The Apriori algorithm算法是一种最有影响的挖掘布尔关联规则频繁项集的算法)、以及基于模型的推荐(机器学习,所谓机器学习,即让计算机像人脑一样持续学习,是人工智能领域内的一个子领域)。
- 基于用户的推荐(通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢),
- 基于项目的推荐(发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,可能也喜欢C),
- 基于模型的推荐(基于样本的用户喜好信息构造一个推荐模型,然后根据实时的用户喜好信息预测推荐)。
- 第一类称为协同过滤,即基于相似用户的协同过滤推荐(用户与系统或互联网交互留下的一切信息、蛛丝马迹,或用户与用户之间千丝万缕的联系),以及基于相似项目的协同过滤推荐(尽最大可能发现物品间的相似度);
- 第二类便是基于内容分析的推荐(调查问卷,电子邮件,或者推荐引擎对本blog内容的分析)。
只是问题是,谁会不遗余力发完微博后,还去给它添加什么标签呢?所以,新浪微博还得努力,寻找另一种更好地分析微博内容的方式。不然系统全盘扫描海里用户的海里微博内容,则恐怕吃不消也负担不起。
然个人觉得倒是可以从微博关键词(标签tag云)和每个用户为自己打的标签(打着越多的共同标签可定义为相似用户)入手,如下图左右部分所示:


也就是说,通过共同的好友和通过间接关注的人来定义相似用户是不靠谱的,只有通过基于微博内容的分析寻找相似用户才是可行之道,同时,更进一步,通过微博内容分析得到标签tag云后,再从中找到相同或相近的标签tag云寻找相似的用户无疑比已有推荐好友方式(通过共同的好友和通过间接关注的人来定义相似用户)更靠谱。
3.1、多种推荐方式结合
在现行的 Web 站点上的推荐往往都不是单纯只采用了某一种推荐的机制和策略,他们往往是将多个方法混合在一起,从而达到更好的推荐效果。
举个例子如Amazon中除此基于用户的推荐之外,还会用到基于内容的推荐(物品具有相同关键词和Tag):如新产品的推荐;基于项目的协同过滤推荐(喜欢A,C与A类似,可能也喜欢C):如捆绑销售and别人购买/浏览的商品。
4、协同过滤推荐
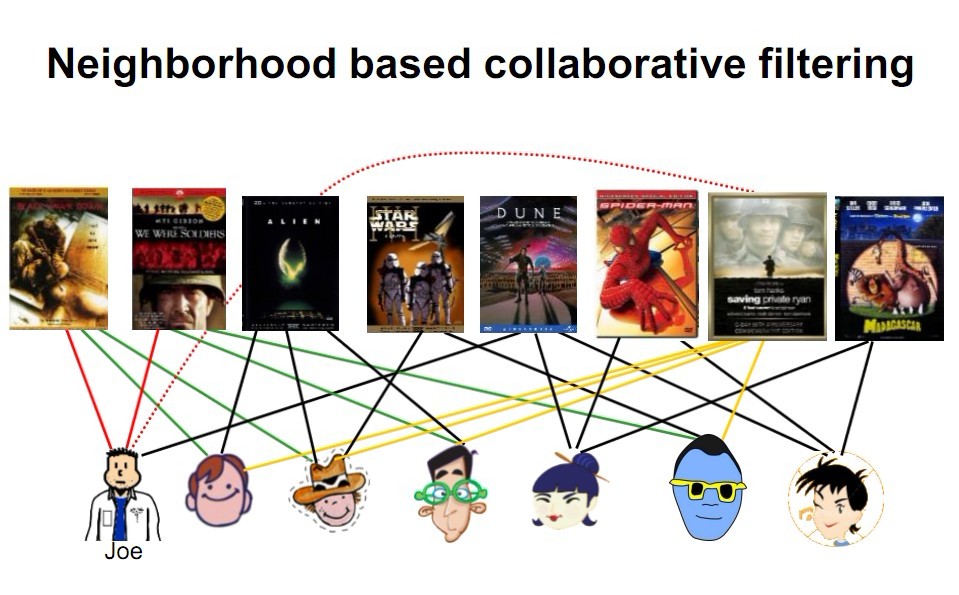
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友或者称之为广义上的邻居(neighborhood),看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。如下图,你能从图中看到多少信息?
4.1、协同过滤推荐步骤
做协同过滤推荐,一般要做好以下几个步骤:
1)若要做协同过滤,那么收集用户偏好则成了关键。可以通过用户的行为诸如评分(如不同的用户对不同的作品有不同的评分,而评分接近则意味着喜好口味相近,便可判定为相似用户),投票,转发,保存,书签,标记,评论,点击流,页面停留时间,是否购买等获得。如下面第2点所述:所有这些信息都可以数字化,如一个二维矩阵表示出来。
2)收集了用户行为数据之后,我们接下来便要对数据进行减噪与归一化操作(得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值)。下面再简单介绍下减噪和归一化操作:
- 所谓减噪:用户行为数据是用户在使用应用过程中产生的,它可能存在大量的噪音和用户的误操作,我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪音,这样可以是我们的分析更加精确(类似于网页的去噪处理)。
- 所谓归一化:将各个行为的数据统一在一个相同的取值范围中,从而使得加权求和得到的总体喜好更加精确。最简单的归一化处理,便是将各类数据除以此类中的最大值,以保证归一化后的数据取值在 [0,1] 范围中。至于所谓的加权,很好理解,因为每个人占的权值不同,类似于一场唱歌比赛中对某几个选手进行投票决定其是否晋级,观众的投票抵1分,专家评委的投票抵5分,最后得分最多的选手直接晋级。
3)找到相似的用户和物品,通过什么途径找到呢?便是计算相似用户或相似物品的相似度。
4)相似度的计算有多种方法,不过都是基于向量Vector的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐中,用户-物品偏好的二维矩阵下,我们将某个或某几个用户对莫两个物品的偏好作为一个向量来计算两个物品之间的相似度,或者将两个用户对某个或某几个物品的偏好作为一个向量来计算两个用户之间的相似度。
相似度计算算法可以用于计算用户或者项目相似度。以项目相似度计算(Item Similarity Computation)为列,通性在于都是从评分矩阵中,为两个项目i,j挑选出共同的评分用户,然对这个共同用户的评分向量,进行计算相似度si,j,如下图所示,行代表用户,列代表项目(注意到是从i,j向量中抽出共有的评论,组成的一对向量,进行相似度计算):
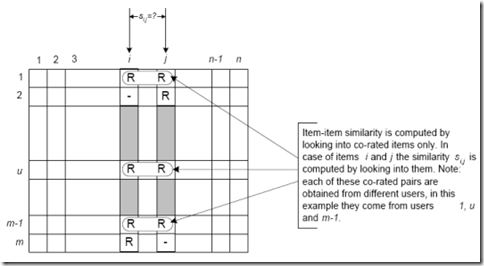
所以说,很简单,找物品间的相似度,用户不变,找多个用户对物品的评分;找用户间的相似度,物品不变,找用户对某些个物品的评分。
5)而计算出来的这两个相似度则将作为基于用户、项目的两项协同过滤的推荐。常见的计算相似度的方法有:欧几里德距离,皮尔逊相关系数(如两个用户对多个电影的评分,采取皮尔逊相关系数等相关计算方法,可以抉择出他们的口味和偏好是否一致),Cosine相似度,Tanimoto系数。下面,简单介绍其中的欧几里得距离与皮尔逊相关系数:
- 欧几里德距离(Euclidean Distance)是最初用于计算欧几里德空间中两个点的距离,假设 x,y 是 n 维空间的两个点,它们之间的欧几里德距离是:
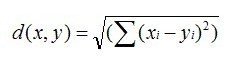
可以看出,当 n=2 时,欧几里德距离就是平面上两个点的距离。当用欧几里德距离表示相似度,一般采用以下公式进行转换:距离越小,相似度越大(同时,避免除数为0):
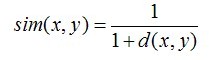
-
余弦相似度Cosine-based Similarity
两个项目 i ,j 视作为两个m维用户空间向量,相似度计算通过计算两个向量的余弦夹角,那么,对于m*n的评分矩阵,i ,j 的相似度sim( i , j ) 计算公式: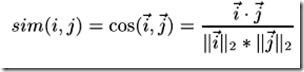 (其中 " · "记做两个向量的内积)
(其中 " · "记做两个向量的内积) - 皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,为了使计算结果精确,需要找出共同评分的用户。记用户集U为既评论了 i 又评论了 j 的用户集,那么对应的皮尔森相关系数计算公式为:
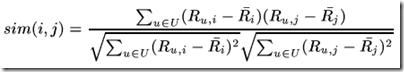
其中Ru,i 为用户u 对项目 i 的评分,对应带横杠的为这个用户集U对项目i的评分评分。
6)相似邻居计算。邻居分为两类:1、固定数量的邻居K-neighborhoods (或Fix-size neighborhoods),不论邻居的“远近”,只取最近的 K 个,作为其邻居,如下图A部分所示;2、基于相似度门槛的邻居,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,如下图B部分所示。
再介绍一下K最近邻(k-Nearest Neighbor,KNN)分类算法:这是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
7)经过4)计算出来的基于用户的CF(基于用户推荐之用:通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢),基于物品的CF(基于项目推荐之用:发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,那么你可能也喜欢C)。
一般来说,社交网站内如facebook宜用User CF(用户多嘛),而购书网站内如Amazon宜用Item CF(你此前看过与此类似的书比某某也看过此书更令你信服,因为你识书不识人)。
话虽如上所说,user多一般是社交性网站如Facebook故倾向于user-based(用户多,用户与用户之间因联系产生的数据也多),item多一般是购买性网站如Amazon故倾向于Item-based(物品多,用户少,故用户与用户之间鲜有联系,无用户数据,何来user-based?只好基于相似物品作文章即item-based,但实践中仍需具体情况具体分析。
如@wuzh670所说:当item数目不多+不显著增长时,item之间的关系在一段时间内相对稳定(对比user之间关系),对于实时更新item-similarity需求就降低很多,推荐系统效率提高很多,故弃用user-based会明智些。
4.2、基于项目相似度与基于用户相似度的差异
上述3.1节中三个相似度公式是基于项目相似度场景下的,而实际上,基于用户相似度与基于项目相似度计算的一个基本的区别是,基于用户相似度是基于评分矩阵中的行向量相似度求解,基于项目相似度计算式基于评分矩阵中列向量相似度求解,然后三个公式分别都可以适用,如下图:
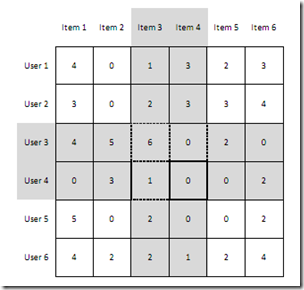
(其中,为0的表示未评分)
- 基于项目相似度计算式计算如Item3,Item4两列向量相似度;
- 基于用户相似度计算式计算如User3,User4量行向量相似度。
5、聚类算法
聚类聚类,通俗的讲,即所谓“物以类聚,人以群分”。聚类 (Clustering) 是一个数据挖掘的经典问题,它的目的是将数据分为多个簇 (Cluster),在同一个簇中的对象之间有较高的相似度,而不同簇的对象差别较大。
5.1、K 均值聚类算法
K-均值(K-Means)聚类算法与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。此算法假设对象属性来自于空间向量,目标是使各个群组内部的均方误差总和最小。
K均值聚类算法首先会随机确定K个中心位置(位于空间中代表聚类中心的点),然后将各个数据项分配给最临近的中心点。待分配完成之后,聚类中心就会移到分配给该聚类的所有节点的平均位置处,然后整个分配过程重新开始。这一过程会一直重复下去,直到分配过程不再产生变化为止。下图是包含两个聚类的K-均值聚类过程:
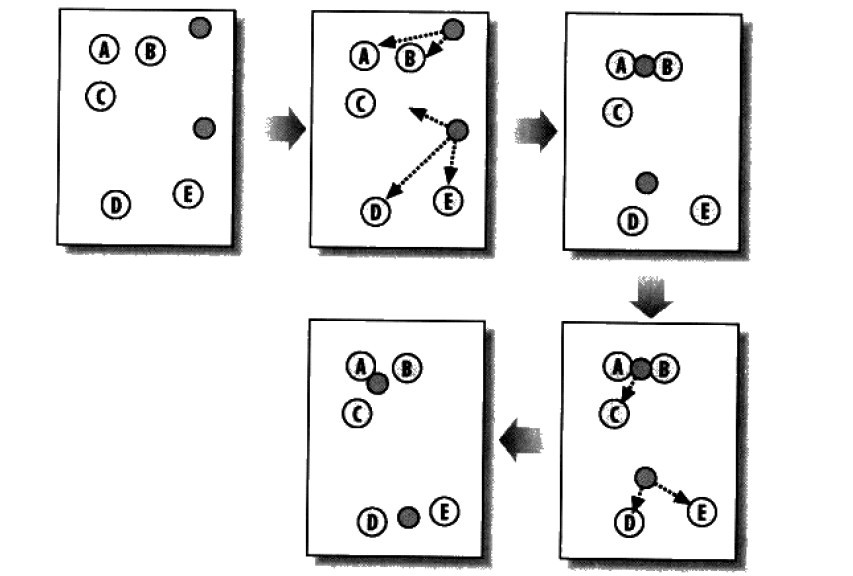
以下代码所示即是此K-均值聚类算法的python实现:
- //K-均值聚类算法
- import random
- def kcluster(rows,distance=pearson,k=4):
- # 确定每个点的最小值和最大值
- ranges=[(min([row[i] for row in rows]),max([row[i] for row in rows]))
- for i in range(len(rows[0]))]
- # 随机创建k个中心点
- clusters=[[random.random()*(ranges[i][1]-ranges[i][0])+ranges[i][0]
- for i in range(len(rows[0]))] for j in range(k)]
- lastmatches=None
- for t in range(100):
- print 'Iteration %d' % t
- bestmatches=[[] for i in range(k)]
- # 在每一行中寻找距离最近的中心点
- for j in range(len(rows)):
- row=rows[j]
- bestmatch=0
- for i in range(k):
- d=distance(clusters[i],row)
- if d<distance(clusters[bestmatch],row): bestmatch=i
- bestmatches[bestmatch].append(j)
- # 如果结果与上一次相同,则整个过程结束
- if bestmatches==lastmatches: break
- lastmatches=bestmatches
- # 把中心点移到其所有成员的平均位置
- for i in range(k):
- avgs=[0.0]*len(rows[0])
- if len(bestmatches[i])>0:
- for rowid in bestmatches[i]:
- for m in range(len(rows[rowid])):
- avgs[m]+=rows[rowid][m]
- for j in range(len(avgs)):
- avgs[j]/=len(bestmatches[i])
- clusters[i]=avgs
- # 返回k组序列,其中每个序列代表一个聚类
- return bestmatches
k-Means是一种机器学习领域中的一种非监督学习。下面,简要介绍下监督学习与无监督学习:
- 监管学习的任务是学习带标签的训练数据的功能,以便预测任何有效输入的值。监管学习的常见例子包括将电子邮件消息分类为垃圾邮件,根据类别标记网页,以及识别手写输入。创建监管学习程序需要使用许多算法,最常见的包括神经网络、Support Vector Machines (SVMs) 和 Naive Bayes 分类程序。
- 无监管学习的任务是发挥数据的意义,而不管数据的正确与否。它最常应用于将类似的输入集成到逻辑分组中。它还可以用于减少数据集中的维度数据,以便只专注于最有用的属性,或者用于探明趋势。无监管学习的常见方法包括K-Means,分层集群和自组织地图。
5.2、Canopy 聚类算法
Canopy 聚类算法的基本原则是:首先应用成本低的近似的距离计算方法高效的将数据分为多个组,这里称为一个 Canopy,我们姑且将它翻译为“华盖”,Canopy 之间可以有重叠的部分;然后采用严格的距离计算方式准确的计算在同一 Canopy 中的点,将他们分配与最合适的簇中。Canopy 聚类算法经常用于 K 均值聚类算法的预处理,用来找合适的 k 值和簇中心。
5.3、模糊 K 均值聚类算法
模糊 K 均值聚类算法是 K 均值聚类的扩展,它的基本原理和 K 均值一样,只是它的聚类结果允许存在对象属于多个簇,也就是说:它属于我们前面介绍过的可重叠聚类算法。为了深入理解模糊 K 均值和 K 均值的区别,这里我们得花些时间了解一个概念:模糊参数(Fuzziness Factor)。
与 K 均值聚类原理类似,模糊 K 均值也是在待聚类对象向量集合上循环,但是它并不是将向量分配给距离最近的簇,而是计算向量与各个簇的相关性(Association)。假设有一个向量 v,有 k 个簇,v 到 k 个簇中心的距离分别是 d1,d2⋯ dk,那么 V 到第一个簇的相关性 u1可以通过下面的算式计算:
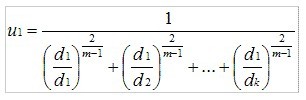
计算 v 到其他簇的相关性只需将 d1替换为对应的距离。从上面的算式,我们看出,当 m 近似 2 时,相关性近似 1;当 m 近似 1 时,相关性近似于到该簇的距离,所以 m 的取值在(1,2)区间内,当 m 越大,模糊程度越大,m 就是我们刚刚提到的模糊参数。
其余聚类算法本文不再介绍。关于冷启动、数据稀疏、可扩展性、可移植性、可解释性、多样性、推荐信息的价值等问题则待后续阐述。
6、分类算法
接下来,分类算法有很多,本文介绍决策树学习,与贝叶斯定理。
6.1、决策树学习
咱们直接切入正题。所谓决策树,顾名思义,是一种树,一种依托于策略抉择而建立起来的树。
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
从数据产生决策树的机器学习技术叫做决策树学习, 通俗说就是决策树。
来理论的太过抽象,下面举两个浅显易懂的例子:
第一个例子:通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑:
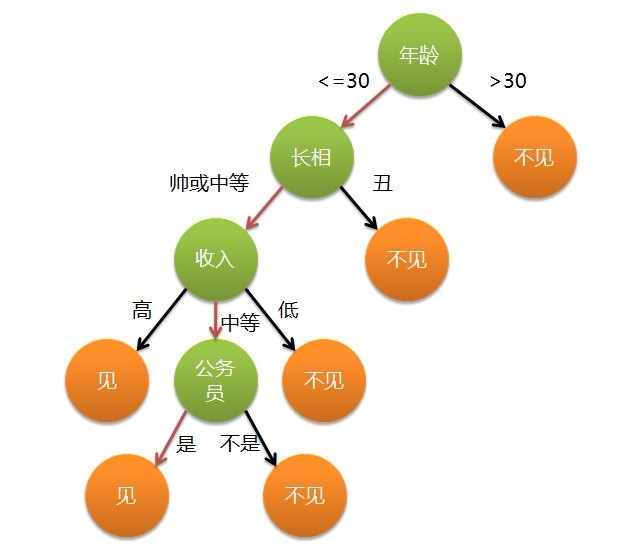
也就是说,决策树的简单策略就是,好比公司招聘面试过程中筛选一个人的简历,如果你的条件相当好比如说清华博士毕业,那么二话不说,直接叫过来面试,如果非重点大学毕业,但实际项目经验丰富,那么也要考虑叫过来面试一下,即所谓具体情况具体分析、决策。
第二个例子来自Tom M.Mitchell著的机器学习一书:
小王的目的是通过下周天气预报寻找什么时候人们会打高尔夫,他了解人们决定是否打球的原因最主要取决于天气情况。而天气状况有晴,云和雨;气温用华氏温度表示;相对湿度用百分比;还有有无风。如此,我们便可以构造一棵决策树,如下(根据天气这个分类决策这天是否合适打网球):
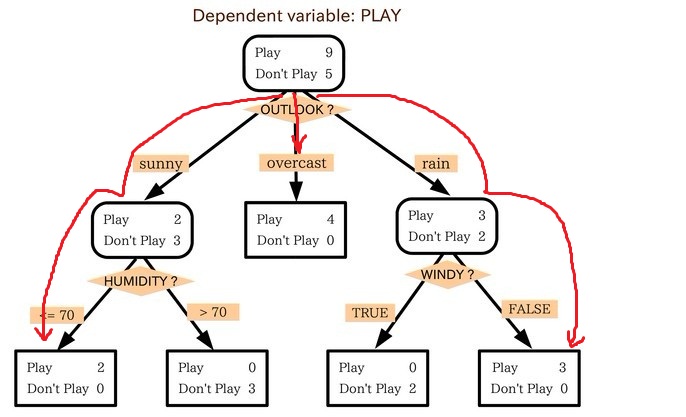
上述决策树对应于以下表达式:(Outlook=Sunny ^Humidity<=70)V (Outlook = Overcast)V (Outlook=Rain ^ Wind=Weak)。得到的最佳分类属性如下图所示:
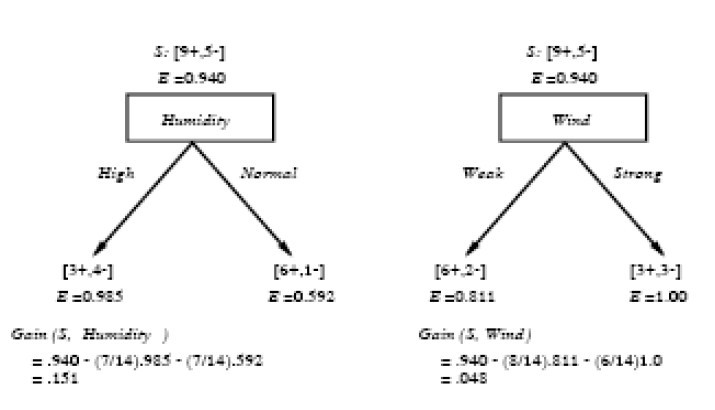
在上图中,计算了两个不同属性:湿度(humidity)和风力(wind)的信息增益,最终humidity这种分类的信息增益0.151>wind增益的0.048。说白了,就是在星期六上午是否适合打网球的问题诀策中,采取humidity较wind作为分类属性更佳,决策树由此而来。
ID3算法决策树的形成
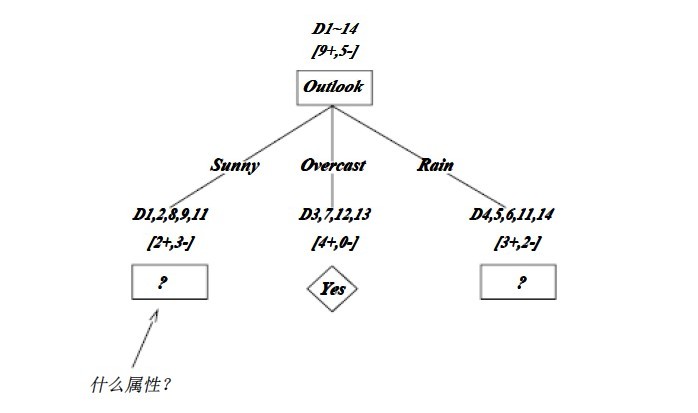
OK,下图为ID3算法第一步后形成的部分决策树。这样综合起来看,就容易理解多了。1、overcast样例必为正,所以为叶子结点,总为yes;2、ID3无回溯,局部最优,而非全局最优,还有另一种树后修剪决策树。下图是ID3算法第一步后形成的部分决策树:
贝叶斯定理:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
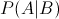 表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为: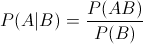 。
。
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理(公式被网友指出有问题,待后续验证改正):
”北京十分科技也非常看好阅读推荐类的应用,他们花了非常大的精力(一年60人团队),才在今天推出了iPhone 版“酷云阅读”。
为什么要投入这么多人去做这个阅读应用?CEO 李鹏告诉我,这个团队超过一半的人都在做后台相关的东西,包括语义分析、机器学习等算法。他们的目的是将互联网“语义化”以后,把人的兴趣明确,最后把每个人感兴趣的内容推荐给相关的人。在iPhone 上,酷云的大致做法和Zite iPad 版类似,用户的行为也是有“喜欢”、“不喜欢”,以及点击相应的媒体来源或者相关的标签来告诉酷云你希望以后看到更多这些内容。
这个目的是大部分阅读推荐应用都有的,但是酷云的做法似乎更加变态。他们除了每天要抓取来自互联网的超过10万篇文章之外,还对全国200个的电视台播出的视频内容进行了索引,以便用户也可以通过文字搜索出视频、以及对视频内容进行一样的推荐。大致做法是先把这些节目都录制下来,然后把声音转文字,最后建立摘要和索引。“
- 你喜欢一些歌曲,而我也喜欢一些歌曲,如果你我喜欢的歌曲中有很多是重复类似的,则系统会把你我定义为好友,即相似用户,基于用户的协同过滤推荐:朋友喜欢,你也可能喜欢 ;
- 还有一个就是针对歌曲的推荐,你喜欢一首歌曲A,而另一首歌曲B与歌曲A类似(如都是有关爱情、感伤一类的),所以系统猜测你也可能喜欢B,而把B推荐给你。这就是基于项目(物品)的协同过滤推荐。
- 应该是系统在背后扫描你的文章一遍,然后提取一些关键词作为tag,供你选择。取哪些关键词呢?当然是取高频词。扫描整篇文章,统计每个单词出现的频率。
- 然后取其前TOP K,如上面截图中的“算法”在那篇文章中出现了4次,“博客”出现了3次,所以系统为你自动匹配这些标签。
- 至于采取何种数据结构或方法来统计这些关键词的频率呢。一般的应用hash+堆(十一、从头到尾彻底解析Hash表算法),或trie树(从Trie树谈到后缀树)均可。但当trie树面对的是汉字中文的时候,就比较麻烦了。所以hash+堆是比较理想的选择。
8、参考文献
- 本人1月7日,1月21日的发表的微博(挂在本blog左侧边栏);
- 探索推荐引擎内部的秘密,作者:赵晨婷,马春娥;
- 集体智慧编程,TobySeganra著。
- 推荐系统之协同过滤概述。
- http://www.cnblogs.com/leoo2sk/。
- Mitchell, Tom M. Machine Learning. McGraw-Hill, 1997(机器学习领域的开山之作).
- http://zh.wikipedia.org/wiki/%E5%86%B3%E7%AD%96%E6%A0%91。
- http://www.36kr.com/p/75415.html。
- 智能web算法,第三章推荐系统(实现了用户及项目的相似度的计算,值得一看)。
后记
英雄召集令:如果哪位朋友以前搞过推荐或者检索的,或者机器学习,数据挖掘,海量数据处理,搜索与推荐引擎任一一个领域的的请一定联系我,可随时留言或评论,或微博私信,或Email:zhoulei0907@yahoo.cn。有过大型网站建设经验的,或者编程经验丰富老道的更欢迎随时联系我。和本blog相关的文件随时免费赠送技术知己。
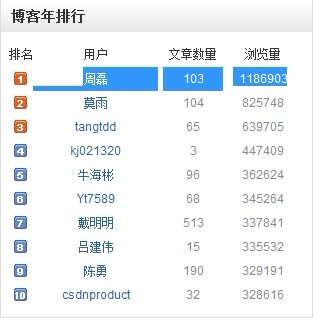
最后,本blog成为过去一年2011年csdn blog年排行榜第一位:http://blog.csdn.net/ranking.html,及csdn Feed订阅排行榜TOP100前十:http://www.feedsky.com/feeds/topsub_csdn.html,如下图左右部分所示:

感谢本blog的所有读者。为回馈读者,免积分下载本blog最新博文集锦第6期CHM文件:http://download.csdn.net/detail/v_july_v/4020172。
OK,本文只是初步成型,还看到了很多的问题、漏洞亟待完善。同时,一切还只是我的理解,尚未在实际工作中运用。所以,理解不深,未辨真知。一切还得在后续实践中检验。读者若发现本文或本blog中任何问题或错误,恳请随时不吝指正。万分感谢。完。July、2011.01.12。
(Recommend & Search交流群:172114338)
Updated:接下来,可能针对推荐系统写一个系列,分别叫做:推荐系统·入门篇,推荐系统·进阶篇,推荐系统·终结篇。在此过程中,我需要学习、参考、借鉴大量的资料和论文。如果各位有好的资料或论文推荐,欢迎随时告知我(先预留一个不错的资料链接:http://arxiv.org/pdf/1202.1112v1.pdf)。July、2012.02.09更新。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号