selenium浏览器自动化测试工具 进阶使用
相关资料
# selenium 支持谷歌,火狐驱动等,但一般使用谷歌的较多,这里我们主要介绍谷歌的相关配置及使用
# 谷歌驱动下载地址:
- http://npm.taobao.org/mirrors/chromedriver/
# 学习网站
- http://www.testclass.net/selenium_python
配置相关
from selenium import webdriver # 驱动
from selenium.webdriver.common.by import By # 定位by
from selenium.webdriver.common.keys import Keys # 键盘键操作
from selenium.webdriver.chrome.options import Options # 浏览器配置方法
from selenium.common.exceptions import TimeoutException # 加载超时异常
from selenium.webdriver.support.ui import WebDriverWait # 显式等待
from selenium.webdriver.support import expected_conditions as EC # 可以组合做一些判断
chrome_options = Options() # selenium配置参数
chrome_options.add_argument('--no-sandbox') # 解决DevToolsActivePort文件不存在的报错(目前没遇到过)
chrome_options.add_argument('--disable-dev-shm-usage') # 解决DevToolsActivePort文件不存在的报错(目前没遇到过)
chrome_options.add_argument('--headless') # 无头模式(没有可视页面)
chrome_options.add_argument('start-maximized') # 屏幕最大化
chrome_options.add_argument('--disable-gpu') # 禁用gpu加速 防止黑屏
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0'
chrome_options.add_argument('user-agent=' + ua) # 浏览器设置UA
chrome_options.add_argument("--proxy-server=http://110.73.2.248:8123")# 添加代理
chrome_options.add_argument("proxy-server=socks5://127.0.0.1:1080")# 加socks5代理(防止代理检测,未使用过)
chrome_options.add_experimental_option('w3c', False) # 设置已手机模式启动需要的配置
chrome_options.add_argument('--disable-infobars') # 禁用提示测试
chrome_options.add_experimental_option('useAutomationExtension', False) # 去掉开发者警告
chrome_options.add_experimental_option('excludeSwitches',
['enable-automation']) # 规避检测 window.navigator.webdriver
chrome_options.add_argument( r'--user-data-dir={}'.format('C:\\Users\\pc\\AppData\\Local\\Temp\\scoped_dir13604_1716910852\\Def')) # 加载本地用户目录,读取和加载的比较耗时
caps = {
'browserName': 'chrome',
'loggingPrefs': {
'browser': 'ALL',
'driver': 'ALL',
'performance': 'ALL',
},
'goog:chromeOptions': {
'perfLoggingPrefs': {
'enableNetwork': True,
},
'w3c': False,
},
} # 获取selenium日志相关配置
# from selenium.webdriver import DesiredCapabilities # 第二种配置方法
# caps = DesiredCapabilities.CHROME
# caps["goog:loggingPrefs"] = {'performance': "ALL", 'browser': 'ALL', 'driver': 'ALL'}
driver = webdriver.Chrome(desired_capabilities=caps, chrome_options=chrome_options) # 实例化selenium配置
driver.set_page_load_timeout(60) # 页面加载超时时间
driver.set_script_timeout(60) # 页面js加载超时时间
driver.set_window_size(1920, 1080) # 设置窗口分辨率大小
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
}) # 规避检测配合'excludeSwitches', ['enable-automation']使用 window.navigator.webdriver (浏览器控制台输出 undefined 说明设置成功)注意新开启窗口不生效
或者使用这个配置
chrome_options.add_argument("disable-blink-features=AutomationControlled")# 去掉了webdriver痕迹 (推荐,上边执行js操作替换掉就行,新开启窗口生效 )
基本操作
# 访问某个页面
driver.get('www.baidu.com')
# 也可以这也写
url = 'www.baidu.com'
driver.get(url)
# 等待加载时间 设置
- 强制等待 不论页面是否加载完成,都往下执行 (看情况使用)
import time
url = 'www.baidu.com'
driver.get(url)
time.sleep(10) # 等待页面加载时间
xxx后续操作
- 显式等待 (推荐)
driver.get('www.xxx.com')
try:
xp = '//*[@id="lg_loginbox"]' # 这里可以用别的定位表达式,我比较习惯使用xpath
WebDriverWait(driver, 30).until(EC.visibility_of_all_elements_located((By.XPATH, xp)))
# driver是浏览器句柄 30(单位秒)是等待时间 By.XPATH使用定位元素的方法 xp是定位表达式
# 30内 会轮询查看这个这个元素是否存在 如果30秒,这个元素还是没有,就会抛出TimeoutException异常
except TimeoutException:
mg = '登录("//*[@id="lg_loginbox"]")元素加载失败!'
print(mg)
xxx后续操作
- 隐式等待 相当于设置全局的等待,在定位元素时,对所有元素设置超时时间 (看情况使用)
driver.implicitly_wait(10) # 10为等待秒数
url = 'www.baidu.com'
driver.get(url)
# 定位页面元素
- xpath定位
xp = '//div[@id=gg]' # 注意尽量不要直接在浏览器复制,而且页面有的时候会改动容错性不高,定位也效率低
driver.find_element_by_xpath(xp)
- css属性定位
driver.find_element_by_css_selector("#su") # 找到id='su'的标签
- By定位 使用的前提是需要导入By类:
from selenium.webdriver.common.by import By
具体语法如下:
find_element(By.ID,"kw") # id
find_element(By.CLASS_NAME,"s_ipt") # 类名
find_element(By.TAG_NAME,"input") # 标签定位
find_element(By.LINK_TEXT,u" 新闻 ") # 超链接
find_element(By.PARTIAL_LINK_TEXT,u" 新 ") # 超链接
find_element(By.XPATH,"//*[@class='bg s_btn']") # xp
find_element(By.CSS_SELECTOR,"span.bg s_btn_wr>input#su") # css
# 点击操作 (首先定位到这个元素且这个元素必须是加载出来的情况下,在执行点击操作)
- 第一种 (某些情况下可能会报错,比如点击不在可视区域的元素)
driver.find_element_by_xpath('//div[@id=gg]').click()
- 第二种 使用js出发点击事件 (推荐)
element = driver.find_element_by_xpath("//div[@id=gg]")
driver.execute_script("arguments[0].click();", element)
- 第三种 使用动作链操作
element = driver.find_element_by_xpath("//div[@id=gg]")
webdriver.ActionChains(driver).move_to_element(element ).click(element ).perform()
# 输入值操作
- 第一种
driver.find_element_by_xpath('//input[@id=name]').send_keys('小胖妞')
- 第二种 调用js
js_code = """document.getElementById(id="mat-input-0").value = '123456'"""
driver.execute_script(js_code)
# 获取标签的 text
driver.find_element_by_xpath('//*[@id="page_3"]/div[5]/div/span[2]/span').text
# 获取标签的 属性值
driver.find_element_by_xpath('//*[@id="page_3"]/div[5]/div/span[2]/span').get_attribute('src')
# selenium 调用js代码
js_code = "console.log('爱你')"
driver.execute_script(js_code)
# 动作链操作 ActionChains (完成一系列操作,比如鼠标拖拽,选中后点击等)
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
例子:
"""
动作链:
- 一系列连续的动作
- 在实现标签定位时,如果发现定位的标签是存在于iframe标签之中的,则在定位时必须执行一个
"""
from selenium import webdriver
from time import sleep
from selenium.webdriver import ActionChains
driver = webdriver.Chrome(executable_path='chromedriver.exe')
driver.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
driver.switch_to.frame('iframeResult')
div_tag = driver.find_element_by_id('draggable')
# 拖动 = 点击+滑动
action = ActionChains(driver)
action.click_and_hold(div_tag)
for i in range(5):
# perform 让动作链立即执行
action.move_by_offset(17, 2).perform()
sleep(0.5)
action.release()
sleep(1.5)
driver.quit()
# 窗口切换
window = driver.current_window_handle # 获取当前操作的窗口
driver.switch_to.window() # 切换到某个窗口
- 两个窗口,切换操作
window = driver.current_window_handle # 获取当前操作的窗口
handles = driver.window_handles # 获取当前窗口句柄集合(列表类型)
next_window = None # 要切换的窗口
for handle in handles: # 循环找到与当前窗口不相等的 next_window 进行赋值
if handle != window:
next_window = handle
driver.switch_to.window(next_window) # 切换到 next_window 进行操作
...后续在next_window的操作
# 截图
- 截取窗口图片
driver.save_screenshot('./main.png') # 截取的是窗口大小的图片 ./main.png 是图片路径
- 截取元素图片 (验证码之类的)
driver.save_screenshot('./main.png') # 截取窗口图片
code_img_tag = driver.find_element_by_xpath('//*[@id="我是验证码"]')
location = code_img_tag.location # 图片坐标(左下,右上) {'x': 1442, 'y': 334}
size = code_img_tag.size # 图片的宽高 {'height':35,'width':65}
# 裁剪的区域范围 (获取验证码的图片)
coordinate = (int(location['x']), int(location['y']), int(location['x'] + size['width']),
int(location['y'] + size['height']))
# 使用Image裁剪出验证码图片 code.png
i = Image.open('./main.png')
frame = i.crop(coordinate)
frame.save('code.png') # 保存验证码图片
# 刷新浏览器
driver.refresh() # 跟F5效果差不多
# 定位frame标签
# frame标签有frameset、frame、iframe三种,frameset跟其他普通标签没有区别,不会影响到正常的定位,
# 而frame与iframe对selenium定位而言是一样的,selenium有一组方法对frame进行操作。
driver.switch_to.frame('tcaptcha_iframe') # 切换到frame标签 tcaptcha_iframe是frame标签的id 也可以传入标签对象元素
xp = '//div[@id="captcha_close"]' # 对frame标签里面的元素进行操作
ele = driver.find_element_by_xpath(xp)
driver.execute_script("arguments[0].click();", ele)
driver.switch_to.default_content() # 切换到主页面
# 获取当前url 有时候可以用它,来判断跳转的路由地址是否正确
driver.current_url
# 获取页面html
xp = '//body' # 要获取的html元素定位
html_text = driver.find_element_by_xpath(xp).get_attribute('innerHTML')
# 关闭窗口 driver.close() 关闭的是窗口,关闭浏览器请使用 driver.quit()
driver.close()
# 关闭浏览器
driver.quit()
使用技巧
# 判断某个元素是否加载出来
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
try:
xp = '//*[@id="lg_loginbox"]'
WebDriverWait(driver, 30).until(EC.visibility_of_all_elements_located((By.XPATH, xp)))
# driver是浏览器句柄 30(单位秒)是等待时间 By.XPATH使用定位元素的方法 xp是定位表达式
# 30内 会轮询查看这个这个元素是否存在 如果30秒,这个元素还是没有,就会报TimeoutException
except TimeoutException:
mg = '登录("//*[@id="lg_loginbox"]")元素加载失败!'
print(mg)
# 判断某个元素是否可见
def is_element_display(self, xp):
try:
element = self.driver.find_element_by_xpath(xp)
if element.is_displayed():
return True
except BaseException:
return None
"""
is_enable()、is_displayed()、isSelected() 区别
1、以下三个为布尔类型的函数
2、is_enable():用于存储input、select等元素的可编辑状态,可以编辑返回true,否则返回false
3、is_displayed():本身这个函数用于判断某个元素是否存在页面上(这里的存在不是肉眼看到的存在,而是html代码的存在。某些情况元素的visibility为hidden或者display属性为none,我们在页面看不到但是实际是存在页面的一些元素)
4、isSelected():很显然,这个是判断某个元素是否被选中。
"""
# 窗口大小设置相关
driver.maximize_window() # 窗口最大化 (频繁启动可能会报错,使用无头模式+pyinstalller打包运行,不生效,不知道为什么)
driver.set_window_size(1920, 1080) # 设置窗口分辨率大小 (频繁启动可能会报错,使用无头模式+pyinstalller打包运行,生效)
chrome_options.add_argument('start-maximized') # 窗口最大化 (使用无头模式+pyinstalller打包运行,不生效,不知道为什么)
webdriver.Chrome(r'chromedriver.exe', chrome_options=chrome_options) # 窗口
chrome_options.add_argument('start-maximized') # 窗口最大化 (使用无头模式+pyinstalller打包运行,不生效,不知道为什么)
webdriver.Chrome(r'chromedriver.exe', chrome_options=chrome_options) # 窗口
chrome_options.add_argument('--window-size=1920,1080') # 推荐设置浏览器窗口大小(使用无头模式+pyinstalller打包运行,生效)
webdriver.Chrome(r'chromedriver.exe', chrome_options=chrome_options) # 窗口
# 关于跳转页面是否符合预期
- 可以根据跳转url做判断
- 也可以根据期望页面元素是否加载出来做判断
# 关于关闭浏览器
- 注意关闭浏览器 要使用 driver.quit() / driver.close() 关闭的只是窗口(不会释放内存)
# 关于元素定位(xpath)
- 有的网站可能使用xpath 可以标签类名经常变动可以通过这种文本方式去定位
driver.find_element_by_xpath('//span[contains(text(),"已取消")]') # 标签文本包含 '已取消'
driver.find_element_by_xpath('//span[text()="已取消"]') # 标签文本等于 '已取消'
- 通过父类元素定位到兄弟元素
driver.find_element_by_xpath("//div[@class="bottom"]/../div[4]")
- 多条件限制 (and) 提高xpath的通用性
driver.find_element_by_xpath("//input[@type='name' and @name='kw1']")
- 多条件限制 (| 或) 提高xpath的通用性
driver.find_element_by_xpath('//div[@class="bottom"]/text() | //div[@class="bottom"]/ul/li/a/text()')
# 注意 driver.find_elements_by_xpath(xp) 是获取多个元素,得到的结果为列表
# 保持每次任务不重复打开多个浏览器可以使用 单例模式
class Spider(object):
# 记录第一个被创建对象的引用
instance = None
def __new__(cls, *args, **kwargs):
# 1. 判断类属性是否是空对象
if cls.instance is None:
# 2. 调用父类的方法,为第一个对象分配空间
cls.instance = super().__new__(cls)
# 3. 返回类属性保存的对象引用
return cls.instance
def __init__(self):
# 每次调用都是同一个浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(r'chromedriver.exe', chrome_options=chrome_options)
# 针对某些需要下拉/滑动的操作 可调用js的 scrollBy 方法
js_code = "window.scrollBy(0,100);" # 0为向右滚动的像素数 100为向下滚动的像素数
self.driver.execute_script(js_code)
# 从selenium日志获取 某个请求信息的具体操作
from selenium import webdriver
from selenium.webdriver import ActionChains, DesiredCapabilities
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('start-maximized')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu') # 防止黑屏
chrome_options.add_experimental_option('w3c', False)
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-infobars') # 禁用提示测试
chrome_options.add_experimental_option('excludeSwitches',
['enable-automation']) # 规避检测 window.navigator.webdriver
caps = {
'browserName': 'chrome',
'loggingPrefs': {
'browser': 'ALL',
'driver': 'ALL',
'performance': 'ALL',
},
'goog:chromeOptions': {
'perfLoggingPrefs': {
'enableNetwork': True,
},
'w3c': False,
},
}
# caps = DesiredCapabilities.CHROME # 第二种配置方法
# caps["goog:loggingPrefs"] = {'performance': "ALL", 'browser': 'ALL', 'driver': 'ALL'}
driver = webdriver.Chrome(desired_capabilities=caps, chrome_options=chrome_options)
driver.set_page_load_timeout(60) # 页面加载超时时间
driver.set_script_timeout(60) # 页面js加载超时时间
for log in self.driver.get_log('performance'):
x = json.loads(log['message'])['message']
if x["method"] == "Network.responseReceived":
# 获取某个链接的响应信息方法
if 'www.xxx.com' in x["params"]["response"]["url"]:
response_data = json.loads(
driver.execute_cdp_cmd('Network.getResponseBody',
{'requestId': x["params"]["requestId"]})[
'body'])
return response_data # 响应信息
if x["method"] == "Network.requestWillBeSent": # 获取某请求相关操作
if 'www.ooo.com' in x["params"]["response"]["url"]:
try:
ip = x["params"]["response"]["remoteIPAddress"]
except BaseException as p:
print(p)
ip = ""
try:
port = x["params"]["response"]["remotePort"]
except BaseException as f:
print(f)
port = ""
response.append(
{
'ip': ip,
'port': port,
'type': x["params"]["type"],
'url': x["params"]["response"]["url"],
'requestId': x["params"]["requestId"],
'status': x["params"]["response"]["status"],
'statusText': x["params"]["response"]["statusText"]
}
)
补充
# 在再发过程中,我们需要固定版本的chrome浏览器,但是chrome会自动升级为最新版本,这时我们就需要更换对应版本的chrome驱动才能让程序正常运行.
# 如何限制
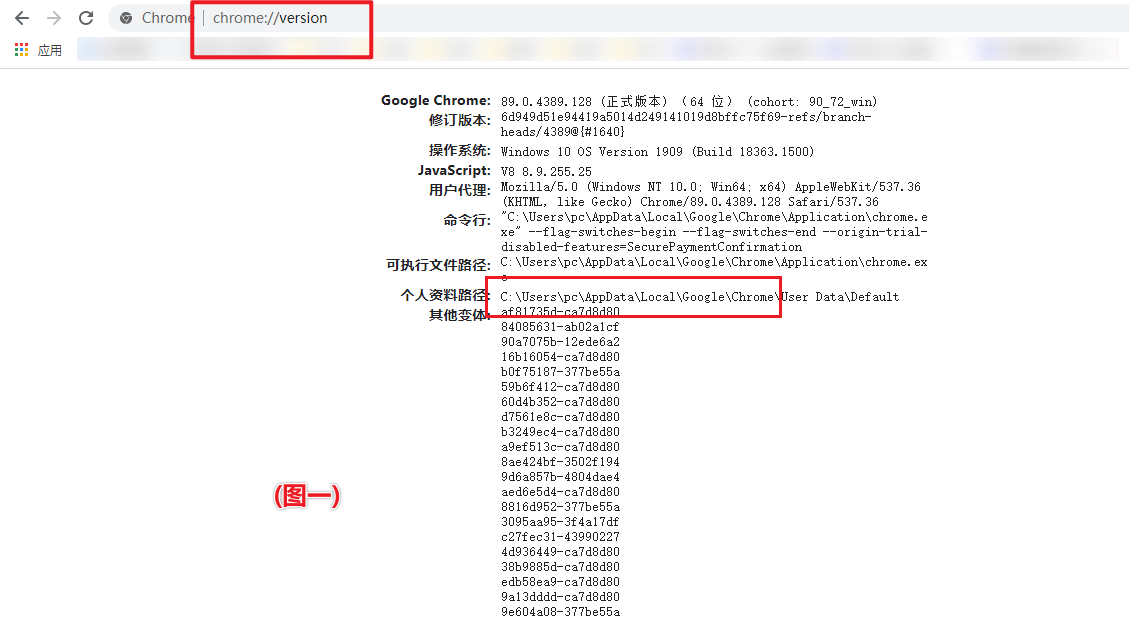
1.打开一个chrome窗口,在地址栏输入 : chrome://version/ 如图一
2.复制个人资料路径 C:\Users\pc\AppData\Local\Google 注意到Google结束
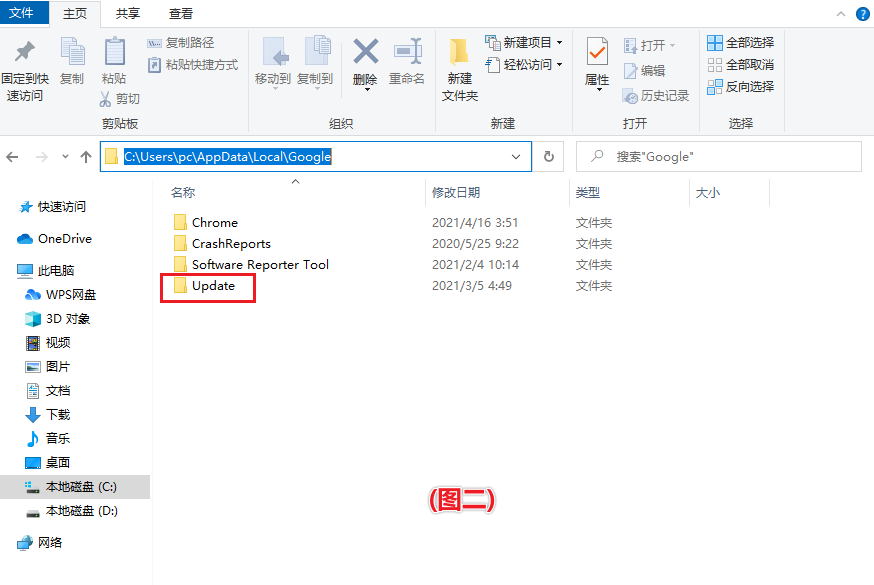
3.打开这个路径 如图二
4.如果没有Update 这个文件夹就新建一个名为Update的文件夹
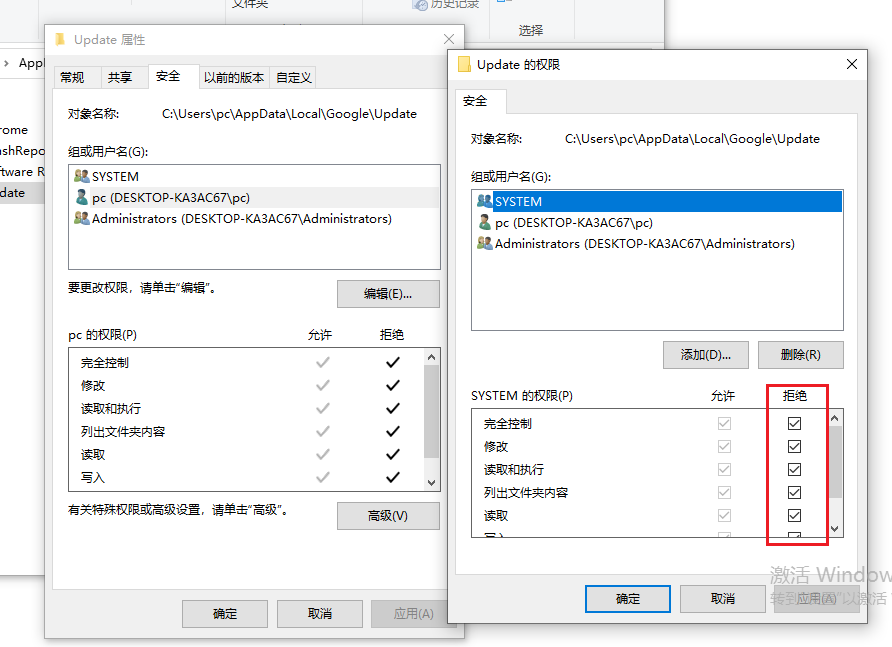
5.把Update文件夹权限限制掉
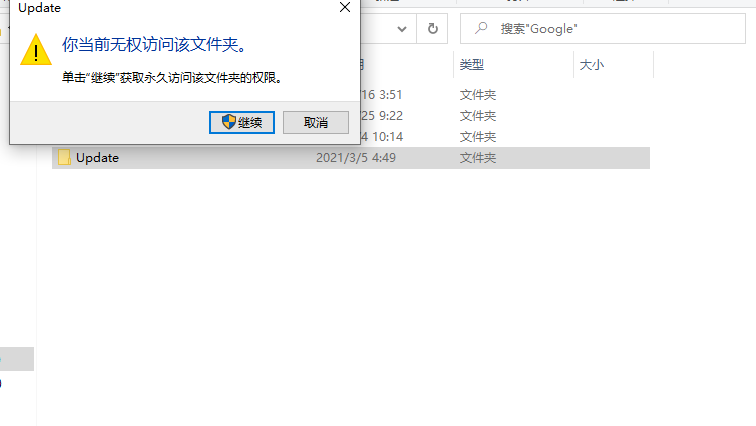
6.限制权限后点击访问该文件夹显示没有权限为设置成功
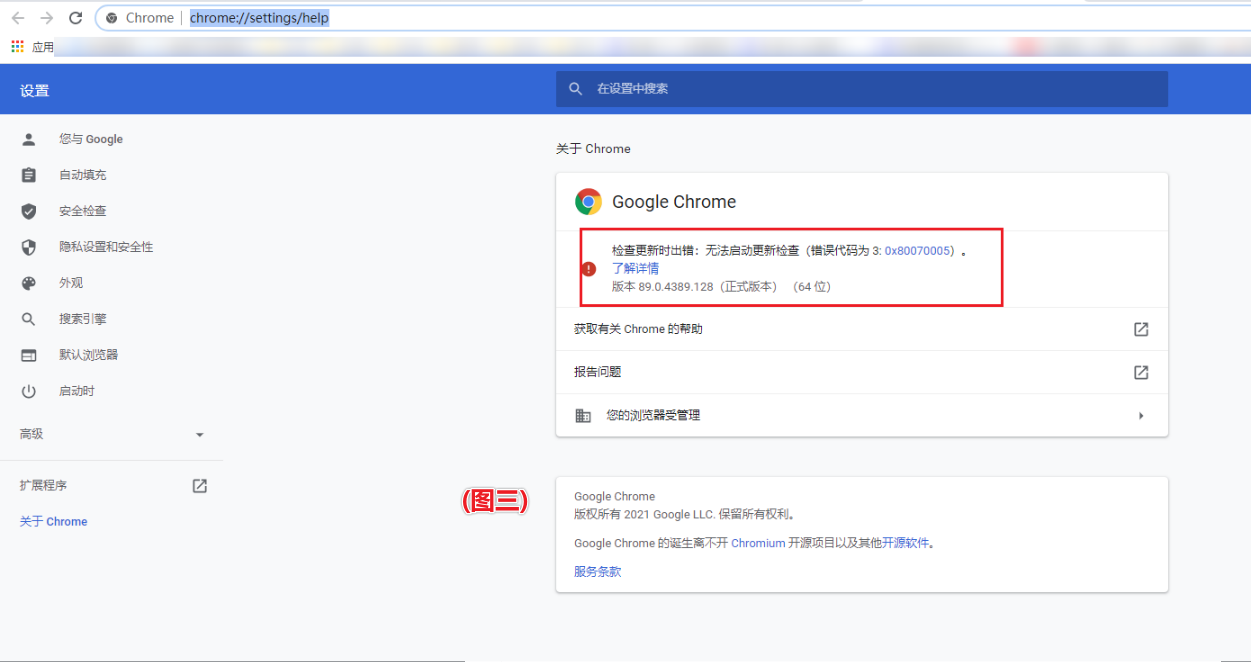
7.查看是否限制成功 chrome://settings/help 输入这个地址 如果如图三的显示效果表示限制自动升级成功
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角
【推荐】一下。您的鼓励是博主的最大动力!
自 勉:生活,需要追求;梦想,需要坚持;生命,需要珍惜;但人生的路上,更需要坚强。带着感恩的心启程,学会爱,爱父母,爱自己,爱朋友,爱他人。
