爬虫小技巧
爬虫小技巧
目录
利用pycharm给字符(请求头)加引号
- 复制需要加引号的请求头
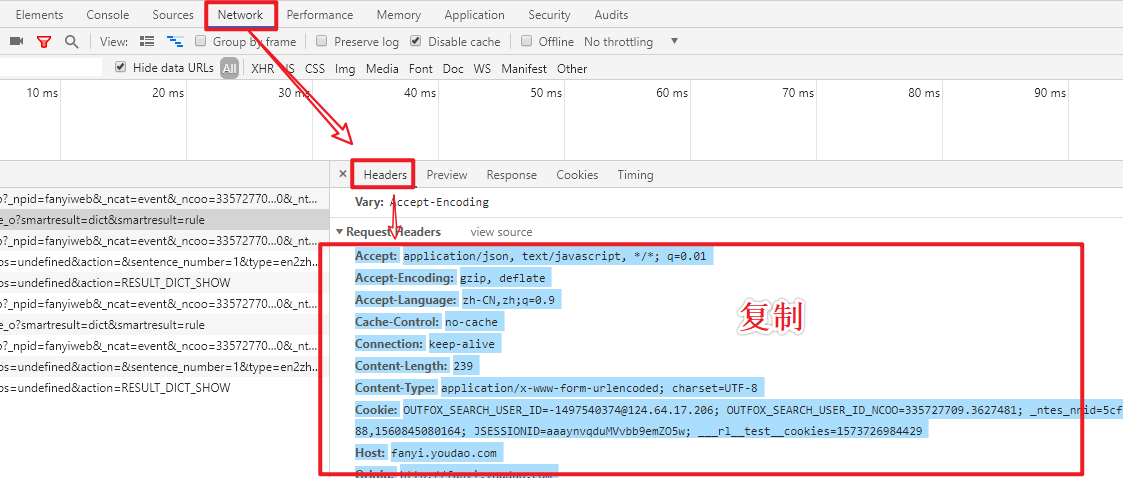
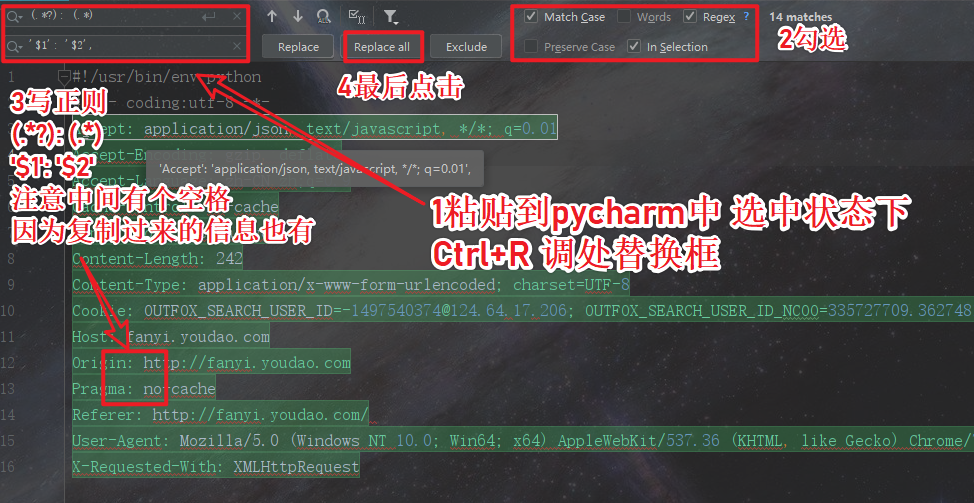
- 粘贴到pycharm中操作

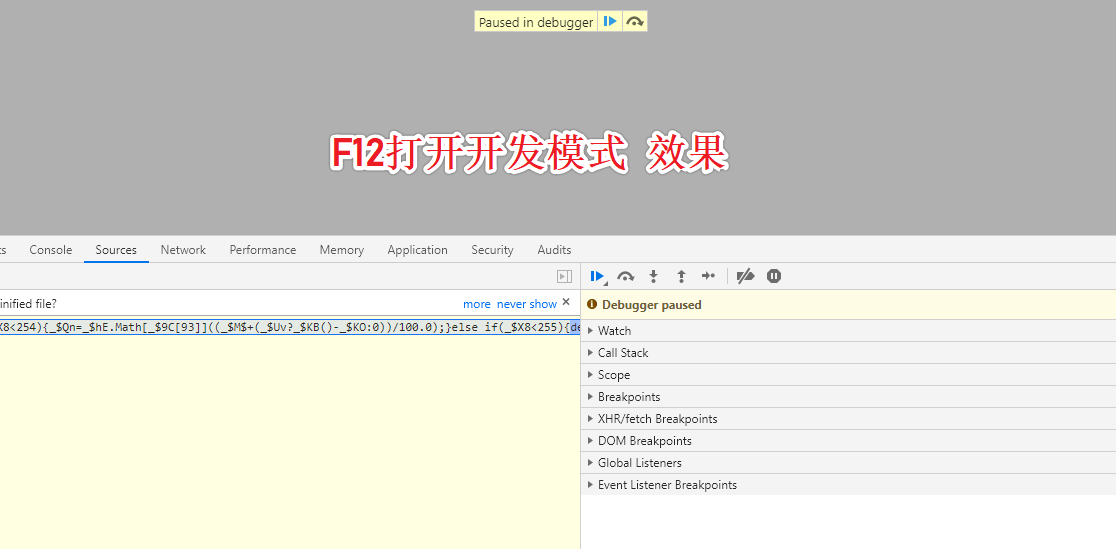
chrome F12调试网页出现Paused in debugger解决办法
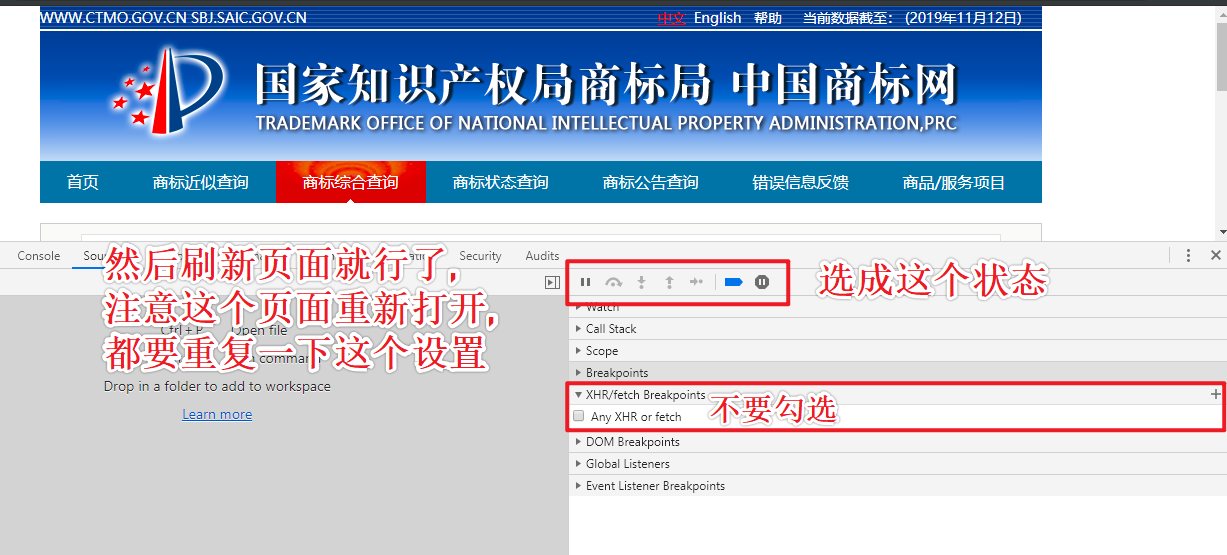
- 解决办法
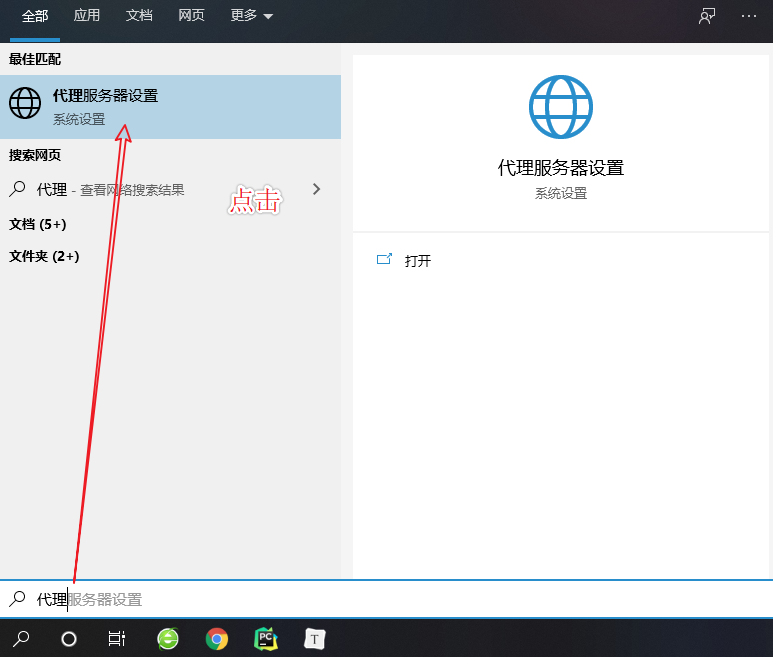
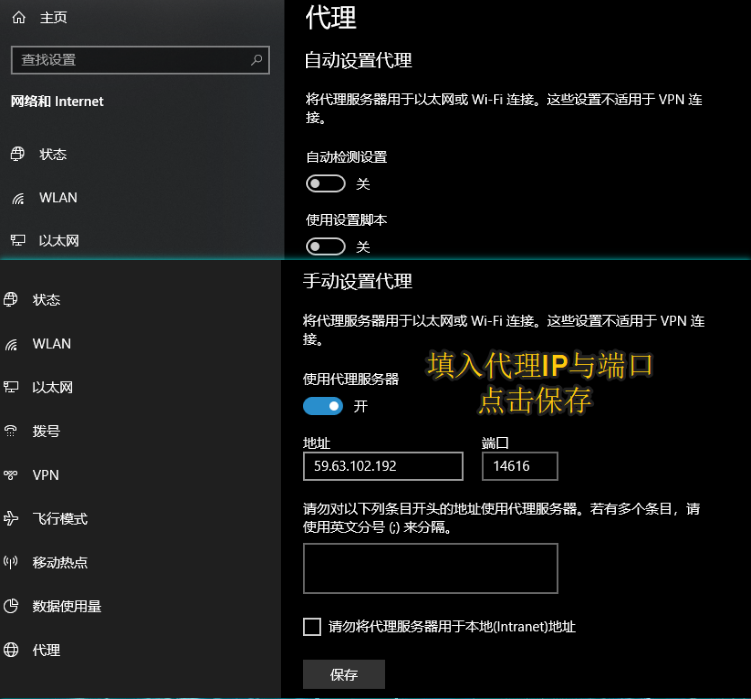
电脑手动更换代理
# 有时候写爬虫分析网页,对方网站可能对ip做封禁处理,导致在浏览器无法拿到网页数据去分析.
# 这种情况我们就可以手动更换代理,然后就可以继续分析网页
# 代理网站(自己搜,我这里推荐几个)
- 免费代理:
- 全网代理IP www.goubanjia.com
- 快代理 https://www.kuaidaili.com/
- 西祠代理 https://www.xicidaili.com/nn/
- 代理精灵 http://http.zhiliandaili.cn/
构建UA请求池 并使用
import random
class Spider(object):
def __init__(self):
self.user_agent = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
]
self.headers = {}
def run(self):
self.headers['User-Agent'] = random.choice(self.user_agent)
print(self.headers)
obj = Spider()
obj.run()
提示程序耗时
import time
import random
import datetime
def func():
time.sleep(random.randint(1, 5))
return None
if __name__ == '__main__':
st = datetime.datetime.now()
print('{}任务开始!!!!!!'.format(st.strftime('%Y-%m-%d %H:%M:%S')))
func()
et = datetime.datetime.now()
print('{}任务结束!!!!!!耗时{}'.format(et.strftime('%Y-%m-%d %H:%M:%S'), et - st))
爬虫请求重要参数
import requests
import traceback
session = requests.session()
# 请求头的ua
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
# 请求参数
data = {
"ajaxAction": True
}
# 代理
proxies = {'http': '127.0.0.1:7891', 'https': '127.0.0.1:7891'}
def spider():
try:
response = session.get(url='www.xxx.com', headers=headers, data=data, proxies=proxies,
timeout=8) # timeout=8请求超时时间 单位 秒
if response.status_code == '200':
return response
return None
except Exception as e:
msg = '响应异常,未获取数据!异常信息:{}'.format(traceback.format_exc())
print(msg)
return None
字符串日期加一天
import datetime
time_str = '2020-08-01'
time_str.split('-')[0].strip()
date = datetime.datetime(int(time_str.split('-')[0].strip()), int(time_str.split('-')[1].strip()),
int(time_str.split('-')[2].strip()))
# print(date) 2020-08-01 00:00:00
number = datetime.timedelta(days=1)
new_date = date + number
expect_time = new_date.strftime('%Y-%m-%d')
# print(expect_time) 2020-08-02
线程池与间隔固定时间执行程序
import time
import datetime
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from spider import MM # 爬虫类
from spider.proxy import get_proxyList # 代理
def get_task_information():
"""获取信息查询任务"""
try:
url = 'www.xxx.com'
rep = requests.get(url).json()
return rep
except Exception as e:
print(e)
return None
def save_function(data):
"""回调函数用于保存数据"""
try:
data = data.result()
if data:
url = 'www.xoo.com'
rep = requests.post(url, data=data).text
print(rep, '保存数据完成!!!!!!!!!!!!!!!!!')
else:
return None
except Exception as e:
print(e)
return None
def execute_function(task):
"""调用函数"""
try:
obj = MM() # 自己写的爬虫类
data = obj.run(obj.delay_info, task)
return data
except Exception as e:
print(e)
return None
def main_function():
"""主程序"""
try:
response = get_task_information()
if response.get('result'):
task_list = [{'task': i} for i in response.get('result')]
with ThreadPoolExecutor(max_workers=30) as tp:
for task in task_list:
tp.submit(execute_function, task).add_done_callback(save_function)
as_completed(tp)
return '任务处理完成!!!'
except Exception as e:
print(e)
return None
t = threading.Thread(target=get_proxyList)
t.start()
while True:
if not t.isAlive():
t.start()
try:
st = datetime.datetime.now()
print('{}任务开始!!!!!!'.format(st.strftime('%Y-%m-%d %H:%M:%S')))
main_function()
et = datetime.datetime.now()
print('{}任务结束!!!!!!耗时{}'.format(et.strftime('%Y-%m-%d %H:%M:%S'), et - st))
time.sleep(300)
except BaseException as e:
print(e)
url携带参数转字典
from urllib import parse
def qs(data):
# 解析URL携带参数,生成字典
query = parse.urlparse(data).query
return dict([(k, v[0] if len(v) == 1 else v) for k, v in parse.parse_qs(query).items()])
url_data = """?cc=1&ck=1&cl=24-bit&ds=1920x1080&vl=1041&et=0&ja=0&ln=zh-cn&lo=0<=1628728417&ck=2"""
print(qs(url_data))
# 运行结果
{'cc': '1', 'ck': ['1', '2'], 'cl': '24-bit', 'ds': '1920x1080', 'vl': '1041', 'et': '0', 'ja': '0', 'ln': 'zh-cn', 'lo': '0', 'lt': '1628728417'}
