
包的使用,json&pickle模块,hashlib模块
一、包的使用(****)
1、什么是包?
包是一个含有__init__.py文件的文件夹,本质就是一个模块,是用来被导入的
2、为何要有包?
首次导入包这种模块,发生两件事
(1)创建模块的名称空间,运行包下的__init__.py的文件,将运行过程中产生的名字都丢入模块的名称空间中
(2)在当前位置拿到一个名字aaa,该名字指向__init__.py的名称空间,即aaa.名字,名字是来自于__init__.py中
代码:略
3. 相对导入: 只能在包的目录下
绝对导入 :参照的是包的顶级目录,只要在sys.path里面就行
4.相对导入简单方法: .代表当前文件,..代表当前文件的上一级,...代表上一级的上一级,依次类推。
ps:环境变量参照执行文件路径,sys.path参照的是调用者的环境变量
二、json&pickle(*****)
1、什么是序列化与反序列化
内存中某一类的数据---------------》特殊的格式
内存中某一类的数据《---------------特殊的格式
2、为何要序列化
1、存档:把内存中的数据持久化到硬盘
2、跨平台交互数据
在python中:
存档=》推荐用pickle格式
跨平台交互=》推荐用json格式
3、如何序列化
3.1 low版本的序列化与反序列化方式
1.序列化 items=["圣剑","蝴蝶","BKB"] dic_str=str(items) with open('db.txt',mode='wt',encoding="utf-8") as f: f.write(dic_str) 2.反序列化 with open('db.txt',mode='rt',encoding='utf-8') as f: data=f.read() # "['圣剑', '蝴蝶', 'BKB']" items=eval(data) print(items[0])
3.2:json
优点:跨平台交互数据
缺点:无法识别所有的python数据类型(集合识别不了)
注意:json格式的字符串里的内容不能包含单引号
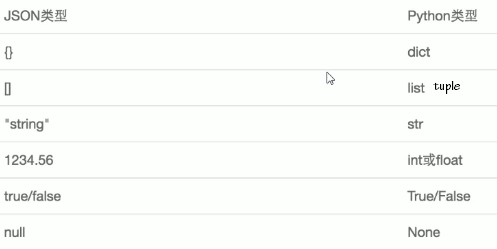
序列化:dump/dumps
反序列化:load/loads
import json # 序列化方式一: t={"a":1,"b":2} # 字典=======》json格式的字符串:"[1,2,3]" res=json.dumps(t) print(res,type(res)) with open("a.json",mode='wt',encoding='utf-8') as f: f.write(res) # json反序列化方式一: with open("a.json",mode='rt',encoding='utf-8') as f: data=f.read() dic=json.loads(data) print(dic,type(dic)) res=json.loads('{"k1":111}') print(res['k1']) # json序列化方式二: t={"a":1,"b":2} # 字典=======》json格式的字符串:"[1,2,3]" with open("b.json",mode='wt',encoding='utf-8') as f: json.dump(t,f) # json反序列化方式二: with open("b.json",mode='rt',encoding='utf-8') as f: dic=json.load(f) print(dic,type(dic))
3.3:pickle
优点:可以识别所有python类型
缺点:只能用于python中,无法跨平台交互
import pickle s = {1,2,3,4,5} #序列化: res=pickle.dumps(s) print(res,type(res)) with open('a.pkl',mode='wb') as f: f.write(res) #反序列化 with open('a.pkl',mode='rb') as f: data=f.read() s=pickle.loads(data) print(type(s))
也可用dump load
XML跟json差不多,比较笨重麻烦
三、hashlib
hash是一种算法(md5\sha256\sha512等),我们为该算法传入内容,该算法会计算得到一串hash值
hash值具备以下三个特点:
1、如果传入的内容一样,并且采用hash算法也一样,那么得到个hash值一定是一样的
2、hash值的长度取决于采用的算法,与传入的文本内容的大小无关
3、hash值不可逆
ps:文件校验要选取点去校验
=============md5===============
import hashlib #1 m=hashlib.md5() m.update("你好".encode('utf-8')) m.update("egon".encode('utf-8')) m.update("哈哈哈".encode('utf-8')) # "你好egon哈哈哈" res=m.hexdigest() print(res) #2 m1=hashlib.md5("你".encode('utf-8')) m1.update("好eg".encode('utf-8')) m1.update("on哈哈哈".encode('utf-8')) # "你好egon哈哈哈" res=m1.hexdigest() print(res) #总结:#1与#2的长度一样 m2=hashlib.md5() with open('aaa.png',mode='rb') as f: for line in f: m2.update(line) print(m2.hexdigest()) #再加密(加盐) pwd="123" m3=hashlib.md5() m3.update("天王盖地虎".encode('utf-8')) m3.update(pwd.encode('utf-8')) m3.update("小鸡炖蘑菇".encode('utf-8'))
==============sha256=============直接就加了盐
#以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密 import hashlib m= hashlib.sha256('898oaFs09f'.encode('utf8')) m.update('alvin'.encode('utf8')) print (m.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
模拟撞库造成密码泄露


import hashlib passwds=[ 'alex3714', 'alex1313', 'alex94139413', 'alex123456', '123456alex', 'a123lex', ] def make_passwd_dic(passwds): dic={} for passwd in passwds: m=hashlib.md5() m.update(passwd.encode('utf-8')) dic[passwd]=m.hexdigest() return dic def break_code(cryptograph,passwd_dic): for k,v in passwd_dic.items(): if v == cryptograph: print('密码是===>\033[46m%s\033[0m' %k) cryptograph='aee949757a2e698417463d47acac93df' break_code(cryptograph,make_passwd_dic(passwds))
==============hmac==============
hmac 模块,它内部对我们创建 key 和 内容 进行进一步的处理然后再加密
import hmac h1=hmac.new('hello'.encode('utf-8'),digestmod='md5') h1.update('world'.encode('utf-8')) print(h1.hexdigest())#0e2564b7e100f034341ea477c23f283b
注意:
#要想保证hmac最终结果一致,必须保证: #1:hmac.new括号内指定的初始key一样 #2:无论update多少次,校验的内容累加到一起是一样的内容 # 操作一 import hmac h1=hmac.new('hello'.encode('utf-8'),digestmod='md5') h1.update('world'.encode('utf-8')) print(h1.hexdigest()) # 0e2564b7e100f034341ea477c23f283b # 操作二 import hmac h2=hmac.new('hello'.encode('utf-8'),digestmod='md5') h2.update('w'.encode('utf-8')) h2.update('orld'.encode('utf-8')) print(h1.hexdigest()) # 0e2564b7e100f034341ea477c23f283b
---20---

