【Django杂记】定时任务框架APScheduler学习
1、APScheduler简介
- 在平常的工作中几乎有一半的功能模块都需要定时任务来推动,例如项目中有一个定时统计程序,定时爬出网站的URL程序,定时检测钓鱼网站的程序等等,都涉及到了关于定时任务的问题,第一时间想到的是利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,虽然这样也可以,但是总觉得不是那么专业,所以就找到了Python的定时任务模块APScheduler。
- APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个Python定时任务系统。
- APScheduler全称Advanced Python Scheduler;作用为在指定的时间规则执行指定的作业。
- 指定时间规则的方式可以是间隔多久执行,可以是指定日期时间的执行,也可以类似Linux系统中的Crontab中的方式执行任务
- 指定的任务就是一个Python函数
2、安装
pip install apscheduler3、APScheduler有四种组成部分:
- 触发器(trigger):包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置以外,触发器完全是无状态的
- 作业存储(job store):作业存储器指定了作业被存放的位置,默认情况下作业保存在内存,也可将作业保存在各种数据库中,当作业被存放在数据库中时,它会被序列化,当被重新加载时会被反序列化。作业存储器充当保存、加载、更新和查找作业的中间商。在调度器之前不能共享作业存储。
- 执行器(executors):执行器是将指定的作业(调用函数)提交到线程池或进程池中运行,当任务完成时,执行器通知调度器触发相应的事件。
- 调度器(schedulers):任务调度器,属于控制角色,通过它配置作业存储器、执行器和触发器,添加、修改和删除任务。调度器协调触发器、作业存储器、执行器的运行,通常只有一个调度程序运行在应用程序中,开发人员通常不需要直接处理作业存储器、执行器或触发器,配置作业存储器和执行器是通过调度器来完成的。
4、APScheduler中几个重要的概念
4.1、Job作业
- 作用:
- Job作为APScheduler最小执行单位。
- 创建Job时指定执行的函数,函数中所需参数,job执行时的一些设置信息
- 构建说明:
- id:指定作业的唯一ID
- name:指定作业的名字
- trigger:apscheduler定义的触发器,用于确定job的执行时间,根据设置的trigger规则,计算得到下次执行此job时间,满足时将会执行
- executor:apscheduler定义的执行器,job创建时设置执行器的名字,根据字符串名字到scheduler获取到执行此job的执行器,执行job指定的函数
- max_instances:执行此job的最大实例数,executor执行job时,根据job的id来计算执行次数,根据设置的最大实例数来确定是否可执行
- next_run_time:job下次的执行时间,创建job时可以指定一个时间[datetime],不执行的话则默认根据trigger获取触发时间
- misfire_grace_time:job的延迟执行时间,例如job的计划执行时间是21:00:00,但因服务重启或其他原因导致21:00:31才执行,如果设置此key为40,则该job会继续执行,否则将会丢弃此job
- coalesce:job是否合并执行,是一个bool值。例如scheduler停止20s后重启启动,而job的触发器设置为5s执行一次,因此此job错过了4个执行时间,如果设置为是,则会合并到一次执行,否则会逐个执行
- func:job执行的函数
- args:job执行函数需要的位置参数
- kwargs:job执行函数需要的关键字参数
- 操作job操作
- 添加job:
- 有两种添加方法,其中一种是add_job(),另外一种则是scheduled_job()修饰器来修饰函数
- 这个两种办法的区别是:第一种方法返回一个apscheduler.job.Job的实例,可以用来改变或移除job。第二种方法只适用于应用运行期间不会改变的job
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job_func():
print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
# 创建调度器,通过它配置作业存储器、执行器和触发器,添加、修改和删除任务
scheduler = BackgroundScheduler(timezone='Asia/Shanghai')
scheduler.add_job(
func=job_func, # 执行的函数
trigger="interval", # 触发器
seconds=2 # 2s执行一次
)
scheduler.start()# 创建调度器,通过它配置作业存储器、执行器和触发器,添加、修改和删除任务
scheduler = BlockingScheduler(timezone='Asia/Shanghai')
# 定义执行的函数
@scheduler.scheduled_job(
trigger='interval', # 选择触发器
seconds=2
)
def job_func():
print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler.start()- 移除job
- 移除job也有两种方法:remove_job()和job.remove()
- remove_job()是根据job的id来移除,所系要在job创建的时候指定一个id
- job.remove()则是对job执行remove方法即可
# 创建调度器,通过它配置作业存储器、触发器、执行器,添加、修改或删除任务
scheduler = BlockingScheduler(timezone='Asia/Shanghai')
# 定义执行的函数
def job_func():
print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
# 添加job
scheduler.add_job(
func=job_func, # 执行函数
trigger='interval', # 触发器
seconds=2,
id='job_one', # 指定作业的id
name='test_job_one' # 指定作业的名字
)
# 删除job, 需要传入创建job的id
scheduler.remove_job(job_id='job_one')
scheduler.start()# 创建调度器,通过它配置执行器、触发器和作业存储器,添加、修改或删除作业
scheduler = BlockingScheduler(timezone='Asia/Shanghai')
# 定义执行的函数
def job_func():
print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
job = scheduler.add_job(
func=job_func, # 执行函数
trigger='interval', # 触发器
seconds=2,
id='job_two', # 指定作业的id
name='test_job_two' # 指定作业的名称
)
# 移除job
job.remove()
scheduler.start()- 获得任务列表
- 可以通过get_jobs方法来获取当前的任务列表,也可以通过get_job()来根据job_id获得某个任务的信息。
- 并且aspcheduler还提供了一个print_jobs()方法来打印格式化的任务列表
# 创建调度器,通过它来配置作业的存储器、执行器和触发器,添加、修改和删除作业
scheduler = BlockingScheduler(timezone='Asia/Shanghai')
# 定义执行的函数
def job_func1(name):
print("我是:", name, "当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
# 添加任务
scheduler.add_job(
func=job_func1, # 执行的函数
trigger='interval', # 触发器
seconds=2,
id='job3', # 指定作业的id
name='test_job3', # 指定作业的名称
args=["小名"] # 执行函数的参数
)
scheduler.add_job(
func=job_func1, # 执行的函数
trigger='interval', # 触发器
seconds=2,
id='job4', # 指定作业的id
name='test_job4', # 指定作业的名称
args=["小红"] # 执行函数的参数
)
# 获取任务列表
jobs = scheduler.get_jobs()
print('jobs:', jobs)
# 根据job_id获取某个任务的详情
scheduler.get_job(job_id='job4')
# 打印格式化的任务列表
scheduler.print_jobs()
scheduler.start()- 修改job
- 如果你因计划改变要对job进行修改,可以使用job.modify()或者modify_job()方法来修改除id以外的任何作业属性
job.modify(max_instances=6, name="Alternate name")# 创建调度器,用来配置作业的存储器、触发器和执行器,可修改、删除、添加作业
scheduler = BlockingScheduler(timezone='Asia/Shanghai')
# 定义执行的函数
def job_func1(name):
print("我是:", name, "当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
job = scheduler.add_job(
func=job_func1, # 执行函数
trigger='interval', # 触发器
seconds=2,
args=['小兰'],
id="one1",
name="one11"
)
# 第一种方式:
# job.modify(name="one111", args=['小兰兰'])
# print(scheduler.get_jobs())
# 第二种方式:
temp_dict = {'seconds': 3}
temp_trigger = scheduler._create_trigger(trigger='interval', trigger_args=temp_dict)
scheduler.modify_job(job_id='one1', trigger=temp_trigger)
scheduler.start()
- 暂停与恢复任务
- 暂停与恢复任务可以直接操作任务实例或者调度器来实现。当任务暂停时,它的运行时间会被重置,暂停期间不会计算时间
- 暂停一个job,使用以下方法:
apscheduler.job.Job.pause()
apscheduler.schedulers.base.BaseScheduler.pause_job()- 而恢复一个job,使用以下方法:
apscheduler.job.Job.resume()
apscheduler.schedulers.base.BaseScheduler.resume_job()# 创建调度器,用来配置作业的存储器、触发器和执行器,创建、修改和删除作用
scheduler = BackgroundScheduler(timezone='Asia/Shanghai') # 非阻塞,后台运行
# 定义执行的函数
def job_func1():
print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
job = scheduler.add_job(
func=job_func1, # 执行函数
trigger='interval', # 触发器
seconds=1,
id="two", # 指定job的id
name="two2" # 指定job的名称
)
scheduler.start()
while True:
# 第一种方式:
time.sleep(3)
# 暂停
job.pause()
time.sleep(1)
# 恢复
job.resume()
# 第二种方式:
time.sleep(3)
scheduler.pause_job(job_id='two') # 暂停
time.sleep(1)
scheduler.resume_job(job_id='two') # 恢复- 启动调度器
- 可以使用start()方法启动调度器,BlockingScheduler需要在初始化之后才能执行start(),对于其他的Scheduler调用start()方法都会直接返回,然后可以继续执行后面的初始化操作
from apscheduler.schedulers.blocking import BlockingScheduler
def job_func():
print("hello world")
scheduler = BlockingScheduler()
scheduler.add_job(job_func, 'interval', seconds=1)
scheduler.start()- 关闭调度器:
- 使用下边方法关闭调度器
scheduler.shutdown()- 默认情况下调度器会关闭它的任务存储和执行器,并等待所有正在执行的任务完成,如果不想等待,可以进行如下操作:
schedulershutdown(wait=False)- Trigger触发器
- Trigger绑定到job,在scheduler调度筛选job时,根据触发器的规则计算出job的触发时间,然后与当前时间比较确定此job是否被执行,总之就是根据trigger规则计算出下一个执行时间
- Trigger有多种种类,指定之间的DateTrigger,指定间隔时间的IntervalTrigger,像Linux的crontab一样的CronTrigger
- 目前APScheduler支持触发器:
- DateTrigger:在某个日期时间只触发一次事件
- IntervalTrigger:想要在固定的时间间隔触发事件。
- weeks:周
- days:一个月中的第几天
- hours:小时
- minutes:分钟
- seconds:秒
- start_date:间隔触发的起始时间
- end_date:间隔触发的结束时间
- jitter:触发的时间误差
- CronTrigger:在某个确切的时间周期性的触发实践
- Executor执行器
- 作用:调度器的主循环其实就是反复检查是不是有到时需要执行的任务,分以下几步完成:
- 询问自己的每一个作业存储器,有没有到期需要执行的任务,如果有,计算这些作业中的每个作业需要运行的时间点,如果时间点有多个,做coalesce[合并执行]检查
- 提交给执行器按时间点运行
- Executor在scheduler中初始化,另外也可通过scheduler的add_executor动态添加Executor。每个executor都会绑定一个alias,这个作为唯一标识绑定到job,在实际执行时会根据job绑定的executor找到实际的执行器对象,然后根据执行器对象执行job
- Executor的种类会根据不同的调度来选择,如果选择AsynicIO作为调度的库,那么选择AsyncIOExecutor,如果选择tornado作为调度的库,选择TornadoExecutor,如果选择启动进程作为调度,可以选择ThreadPoolExecutor或者ProcessPoolExecutor都可以
- 执行器的选择也屈居于应用场景。通常默认的ThreadPoolExecutor已经足够好了。如果作业负载涉及CPU密集型操作,那么应该考虑使用ProcessPoolExecutor,甚至可以同时使用这两种执行器,将ProcessPoolExecutor执行器添加为二级执行器
- apscheduler提供了许多不同的方法来配置调度器。可以使用字典,也可以使用关键字参数传递。首先实例化调度程序,添加作业,配置调度器,获得最大的灵活性
- 目前APScheduler支持的executor:
- ThreadPoolExecutor:线程池执行器
- ProcessPoolExecutor:进程池执行器
- GeventExecutor:Gevent程序执行器
- TornadoExecutor:Tornado程序执行器
- TwistedExecutor:Twisted程序执行器
- AsyncIOExecutor:asyncio程序执行器
- 举例:
- 如果我们调度程序在应用程序的后台运行,选择BackgroundScheduler,并使用默认的jobstore和默认的executor,则配置如下:
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()- 如果我们想配置更多的信息,如设置两个执行器、两个作业存储器、调整新作为的默认值,并设置不同的时区;下面的三个方法是完全等同的。
- 配置需求:
- 配置名为mongo的MongoDBJobStore作业存储器
- 配置名为default的SQLAlchemyJobStore(使用SQLite)作业存储器
- 配置名为default的ThreadPoolExecutor,最大线程数为20
- 配置名为processpool的ProcessPoolExecutor,最大进程数为5
- UTC作为调度器的时区
- coalesce默认情况下关闭
- 作业的默认最大运行实例限制为3
# 方法一
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler, BlockingScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
# 存储器
jobstores = {
'mongo': MongoDBJobStore(),
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
# 执行器
executors = {
'default': ThreadPoolExecutor(max_workers=20),
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
# 创建调度器
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)# 方法二
from apscheduler.schedulers.background import BackgroundScheduler
# 创建调度器
scheduler = BackgroundScheduler({
'apscheduler.jobstores.mongo': {
'type': 'mongodb'
},
'apscheduler.jobstores.sqlalchemy': {
'type': 'sqlalchemy',
'url': 'sqlite:///jobs.sqlite'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool: ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false',
'apscheduler.job_defaults.max_instances': '3',
'apscheduler.timezone': 'UTC'
})# 方法三
# -*- coding: utf-8 -*-
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutor
jobstores = {
'mongo': {'type': 'mongodb'},
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': {'type': 'threadpool', 'max_workers': '20'},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)- 以上涵盖了大多数情况的调度器配置,在实际运行时可以试试不同的配置会有怎样不同的效果。
- Jobstore作业存储
- Jobstore在scheduler中初始化,另外也可通过scheduler的add_jobstrore动态添加jobstore。每个jobstore都会绑定一个alias,scheduler在Add Job时,根据指定的jobstore在scheduler中找到相应的jobstore,并将job添加到jobstore中。
- jobstore主要是通过pickle库的loads和dumps【实现核心是通过python的__getstate__和__setstate__实现】,每次变更时将job动态保存到存储中,使用时再动态的加载出来,作为存储的可以是redis,也可以是数据库[通过sqlarchemy这个库集成多种数据库],也可以是mongodb等
- 目前APScheduler支持的jobstrore:
- MemoryJobStore:没有序列化,任务存储在内存中,增删改查都是在内存中完成
- MongoDBJobStore:使用MongoDB作为存储器
- RedisJobStore:使用redis作为存储器
- RethinkDBStore
- SQLAlchemyJobStore:使用SQlAlchemy这个orm框架作为存储方式
- ZookeeperJobStore
- Event事件
- Event是APScheduler在进行某些操作时触发相应的事件,用户可以自定义一些函数来监听这些事件,当触发某些Event时,做一些具体的操作
- 常见的比如:job执行异常事件Event_JOB_ERROR。job执行时间错过事件EVENT_JOB_MISSED
- 目前APScheduler定义的Event:
EVENT_SCHEDULER_STARTED # 调度程序已启动
EVENT_SCHEDULER_START # 调度程序已启动
EVENT_SCHEDULER_SHUTDOWN # 调度程序已关闭
EVENT_SCHEDULER_PAUSED # 调度程序中的作业处理已暂停
EVENT_SCHEDULER_RESUMED # 调度程序中的作业处理已恢复
EVENT_EXECUTOR_ADDED # 将执行程序添加到调度程序中
EVENT_EXECUTOR_REMOVED # 遗属执行人被移交到调度员
EVENT_JOBSTORE_ADDED # 作业存储已添加到调度程序
EVENT_JOBSTORE_REMOVED # 作业存储已从调度程序中删除
EVENT_ALL_JOBS_REMOVED # 所有作业已从所有作业存储库或一个特定的作业存储库中删除
EVENT_JOB_ADDED # 作业已添加到作业存储中
EVENT_JOB_REMOVED # 从作业存储中删除了作业
EVENT_JOB_MODIFIED # 从计划程序外部修改了作业
EVENT_JOB_EXECUTED # 作业已成功执行
EVENT_JOB_ERROR # 作业在执行期间引发异常
EVENT_JOB_MISSED # 错过了工作执行
EVENT_JOB_SUBMITTED # 作业已提交给执行者运行
EVENT_JOB_MAX_INSTANCES # 提交给执行者的作业未必执行者接受,因此该作业已达到其最大并发执行实例数- Listener监听事件
- 可以给调度器添加实践监听器,调度器事件只有在某些情况下会被触发,并且可以携带某些有用的信息。通过给add_listener()传递合适的mask参数,可以只监听几种特定的事件类型,具体类型可看源码中的event.exception或者event.code值来识别判断
- 使用add_listener添加监听事件,其中callback为监听事件触发后的回调函数,mark为Event事件
- 举例:
import time
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR, EVENT_JOB_ADDED
def task_listener(event):
if event.code == EVENT_JOB_EXECUTED:
print('任务执行成功')
if event.code == EVENT_JOB_ERROR:
print('任务执行错误')
if event.code == EVENT_JOB_ADDED:
print('任务添加成功')
def my_job():
print('nihao')
print(1 / 0)
scheduler = BackgroundScheduler(timezone='Asia/Shanghai')
scheduler.add_listener(
callback=task_listener,
mask=EVENT_JOB_ERROR | EVENT_JOB_ADDED | EVENT_JOB_EXECUTED
)
job = scheduler.add_job(
func=my_job,
trigger='interval',
seconds=1
)
scheduler.start()
while True:
time.sleep(1)
scheduler.add_job(
func=my_job,
trigger='interval',
seconds=1
)
print('a:', scheduler.get_jobs())- 在生产环境中,可以把出错信息换成发送一封邮件或者发送一个短信,这样定时任务出错就可以立马就知道。
- Scheduler调度器
- Scheduler是APScheduler的核心,所有相关组件通过其定义。scheduler启动之后,将开始按照配置的任务进行调度。除了依据所有定义Job的trigger生成的将要调度时间唤醒调度之外。当发生Job信息变更时也会触发调度。
- scheduler可根据自身的需求选择不同的组件,如果是使用Asyncio则选择AsyncIOScheduler,使用tornado则选择TornadoScheduler
- 目前APScheduler支持的Scheduler:
- BlockingScheduler:调度器在当前进程的主线程中运行,也就是会阻塞当前线程。
- BackgroundScheduler:调度器在后台线程中运行,不会阻塞当前线程。
- AsyncIOScheduler:结合asyncio模块(一个异步框架)一起使用
- GeventScheduler:程序中使用gevent(高性能的Python并发框架)作为IO模型和GeventExecutor配合使用
- TornadoScheduler:程序中使用Tornado(一个web框架)的IO模型,用ioloop.add_timeout完成定时唤醒
- TwistedScheduler:配合TwistedExecutor,用reactor.callLater完成定时唤醒
- QtScheduler:你的应用是一个Qt应用,需使用QTimer完成定时唤醒
5、Scheduler工作流程图
- Scheduler添加job流程
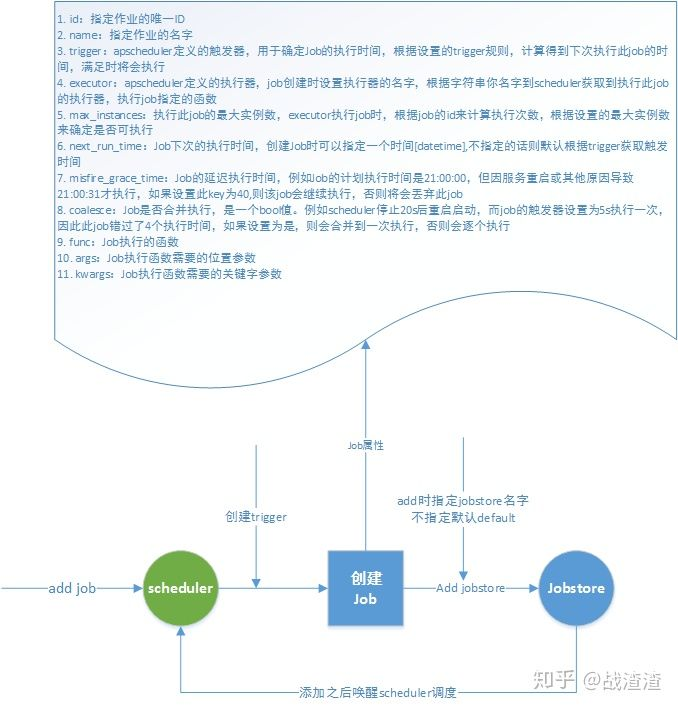
- scheduler调度流程

APScheduler使用示例
- AsyncIO调度示例
import asyncio
import datetime
from apscheduler.events import EVENT_JOB_EXECUTED
from apscheduler.executors.asyncio import AsyncIOExecutor
from apscheduler.jobstores.redis import RedisJobStore # 需要安装redis
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from apscheduler.triggers.interval import IntervalTrigger
from apscheduler.triggers.cron import CronTrigger
# 定义jobstore 使用redis 存储job信息
default_redis_jobstore = RedisJobStore(
db=2,
jobs_key="apschedulers.default_jobs",
run_times_key="apschedulers.default_run_times",
host="127.0.0.1",
port=6379,
password="test"
)
# 定义executor 使用asyncio是的调度执行规则
first_executor = AsyncIOExecutor()
# 初始化scheduler时,可以直接指定jobstore和executor
init_scheduler_options = {
"jobstores": {
# first 为 jobstore的名字,在创建Job时直接直接此名字即可
"default": default_redis_jobstore
},
"executors": {
# first 为 executor 的名字,在创建Job时直接直接此名字,执行时则会使用此executor执行
"first": first_executor
},
# 创建job时的默认参数
"job_defaults": {
'coalesce': False, # 是否合并执行
'max_instances': 1 # 最大实例数
}
}
# 创建scheduler
scheduler = AsyncIOScheduler(**init_scheduler_options)
# 启动调度
scheduler.start()
second_redis_jobstore = RedisJobStore(
db=2,
jobs_key="apschedulers.second_jobs",
run_times_key="apschedulers.second_run_times",
host="127.0.0.1",
port=6379,
password="test"
)
scheduler.add_jobstore(second_redis_jobstore, 'second')
# 定义executor 使用asyncio是的调度执行规则
second_executor = AsyncIOExecutor()
scheduler.add_executor(second_executor, "second")
# *********** 关于 APScheduler中有关Event相关使用示例 *************
# 定义函数监听事件
def job_execute(event):
"""
监听事件处理
:param event:
:return:
"""
print(
"job执行job:\ncode => {}\njob.id => {}\njobstore=>{}".format(
event.code,
event.job_id,
event.jobstore
))
# 给EVENT_JOB_EXECUTED[执行完成job事件]添加回调,这里就是每次Job执行完成了我们就输出一些信息
scheduler.add_listener(job_execute, EVENT_JOB_EXECUTED)
# *********** 关于 APScheduler中有关Job使用示例 *************
# 使用的是asyncio,所以job执行的函数可以是一个协程,也可以是一个普通函数,AsyncIOExecutor会根据配置的函数来进行调度,
# 如果是协程则会直接丢入到loop中,如果是普通函数则会启用线程处理
# 我们定义两个函数来看看执行的结果
def interval_func(message):
print("现在时间: {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
print("我是普通函数")
print(message)
async def async_func(message):
print("现在时间: {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
print("我是协程")
print(message)
# 将上述的两个函数按照不同的方式创造触发器来执行
# *********** 关于 APScheduler中有关Trigger使用示例 *************
# 使用Trigger有两种方式,一种是用类创建使用,另一个是使用字符串的方式
# 使用字符串指定别名, scheduler初始化时已将其定义的trigger加载,所以指定字符串可以直接使用
if scheduler.get_job("interval_func_test", "default"):
# 存在的话,先删除
scheduler.remove_job("interval_func_test", "default")
# 立马开始 2分钟后结束, 每10s执行一次 存储到first jobstore second执行
scheduler.add_job(interval_func, "interval",
args=["我是10s执行一次,存放在jobstore default, executor default"],
seconds=10,
id="interval_func_test",
jobstore="default",
executor="default",
start_date=datetime.datetime.now(),
end_date=datetime.datetime.now() + datetime.timedelta(seconds=240))
# 先创建tigger
trigger = IntervalTrigger(seconds=5)
if scheduler.get_job("interval_func_test_2", "second"):
# 存在的话,先删除
scheduler.remove_job("interval_func_test_2", "second")
# 每隔5s执行一次
scheduler.add_job(async_func, trigger, args=["我是每隔5s执行一次,存放在jobstore second, executor = second"],
id="interval_func_test_2",
jobstore="second",
executor="second")
# 使用协程的函数执行,且使用cron的方式配置触发器
if scheduler.get_job("cron_func_test", "default"):
# 存在的话,先删除
scheduler.remove_job("cron_func_test", "default")
# 立马开始 每10s执行一次
scheduler.add_job(async_func, "cron",
args=["我是 每分钟 30s 时执行一次,存放在jobstore default, executor default"],
second='30',
id="cron_func_test",
jobstore="default",
executor="default")
# 先创建tigger
trigger = CronTrigger(second='20,40')
if scheduler.get_job("cron_func_test_2", "second"):
# 存在的话,先删除
scheduler.remove_job("cron_func_test_2", "second")
# 每隔5s执行一次
scheduler.add_job(async_func, trigger, args=["我是每分钟 20s 40s时各执行一次,存放在jobstore second, executor = second"],
id="cron_func_test_2",
jobstore="second",
executor="second")
# 使用创建trigger对象直接创建
print("启动: {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
asyncio.get_event_loop().run_forever()常见问题
为什么scheduler不执行我的job
- 导致这种情况的原因很多,最常见的两种情况是:
- scheduler在uWSGI的工作进程中运行,但是uWSGI并没有启动多线程
- 运行了BackgroundScheduler,但是已经执行到了脚本的末尾
- 针对后一种情况,类似于这样的脚本是没有办法正常运行的:
from apscheduler.scheduler.background import BackgroundScheduler
def myjob():
print('hello')
scheduler = BackgroundScheduler()
scheduler.start()
scheduler.add_job(myjob, 'cron', hour=0)- 可见,以上脚本在运行完add_job()之后就直接退出了,因此scheduler根本没有机会去运行其调度好的job
该如何在uWSGI中使用APScheduler
- uWSGI使用了一些技巧来禁用掉GIL锁,但多线程的使用对于APScheduler的操作来说至关重要。为了修改这个问题,你需要使用--enable-threads选项来重新启用GIL
如何在一个或多个工作进程中共享独立的job store
- 答案就是不可以;在两个或更多的进程中共享一个持久化的job store会导致scheduler的行为不正常:如重复执行或作业丢失等等。这个是因为APScheduler目前没有任何进程间同步和信号量机制,因此当一个job被添加、修改或从scheduler中移除时scheduler无法得到通知
- 变通方案:在专用的进程中来运行scheduler,然后通过一些远程访问的途径--如RPyC、gRPC或一个HTTP服务器--来将其连接起来。
如何在web应用中使用APScheduler
- 如果你想在Django中运行,可以考虑django-apscheduler,不过要注意,这个是第三方库而APScheduler的开发者不能保证其质量
- 如果你想在Flask中使用APScheduler,这里也有一个非官方的插件Flask-APScheduler
- 对于Pyramid用户而言,pyramid_scheduler可能更有用
- 对于其他情况,你最好还是按照常理厂牌,使用BackgroundScheduler。如果你在一个异步的web框架如aiohttp中运行,你可能想使用别的scheduler以便充分利用框架的异步功能
APScheduler有图形用户界面吗?
- 简单来说,官方的没有,以下的第三方库有它们自己的实现:
- django_apscheduler
- apschedulerweb
- Nextdoor scheduler
本文来自博客园,作者:郭祺迦,转载请注明原文链接:https://www.cnblogs.com/guojie-guojie/p/16330165.html
