


机器学习基础——数据处理与特征工程
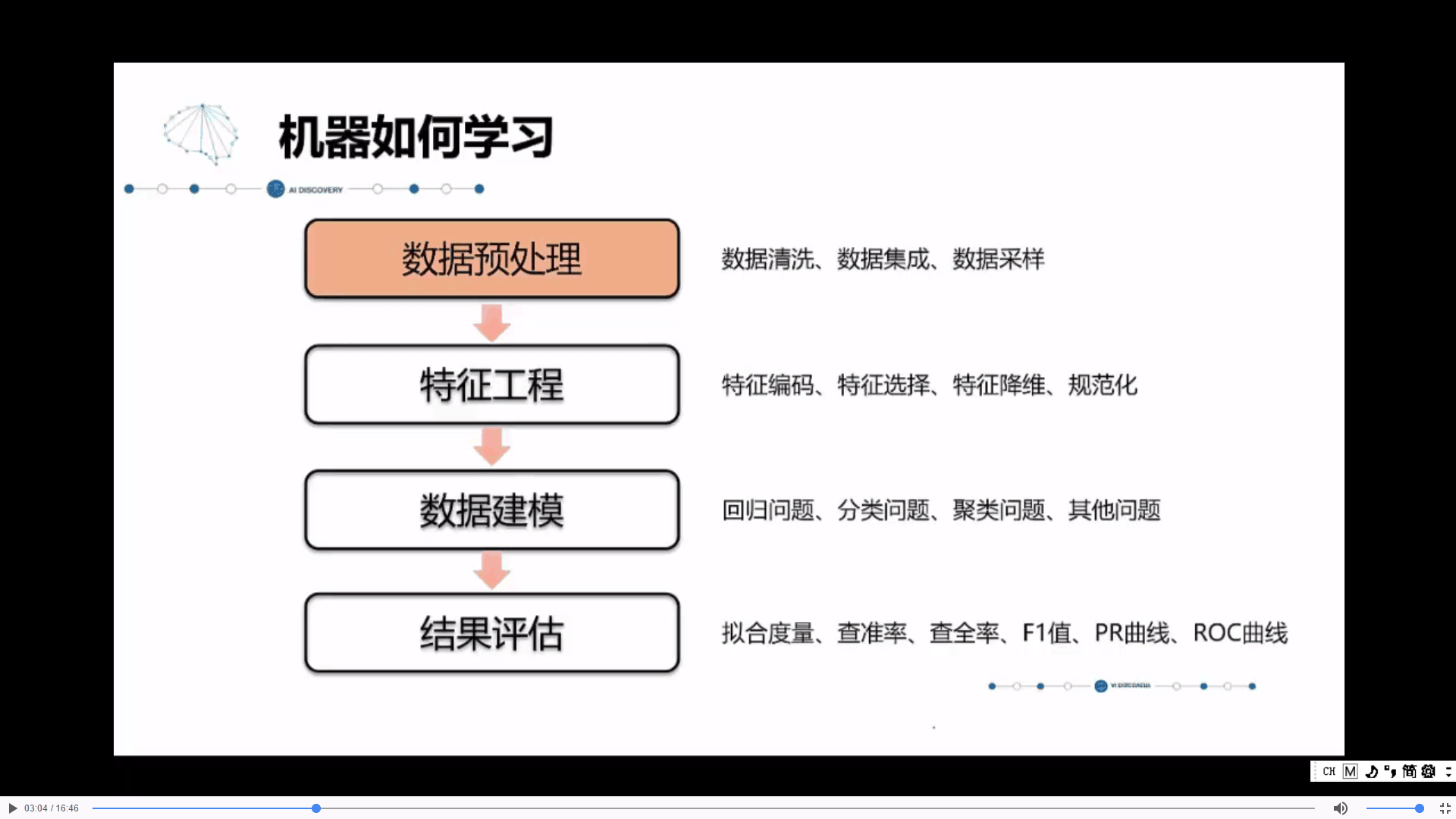
一. 数据预处理


数据不平衡时,无法体现模型好坏,就像让一群硕士去做小学题,并不能区分他们的能力,宁愿把题目设置成高考题。
· 过采样和欠采样可以同时采用。

留出法的缺点:可能会导致划分在测试集内的数据有一些特征没有在训练集内发现,会有误差。
k-折交叉验证法的优点:假如划分为10个互斥子集,我们就可以在第一次用前9个做训练,最后1个做测试,第二次可以用倒数第2个做测试,剩下的做训练,第三次用倒数第3个做测试,剩下的做训练....以此类推,每一个子集都可以被训练,测试到,总共做10次训练和测试,就弥补了留出法的缺陷。
二. 特征工程

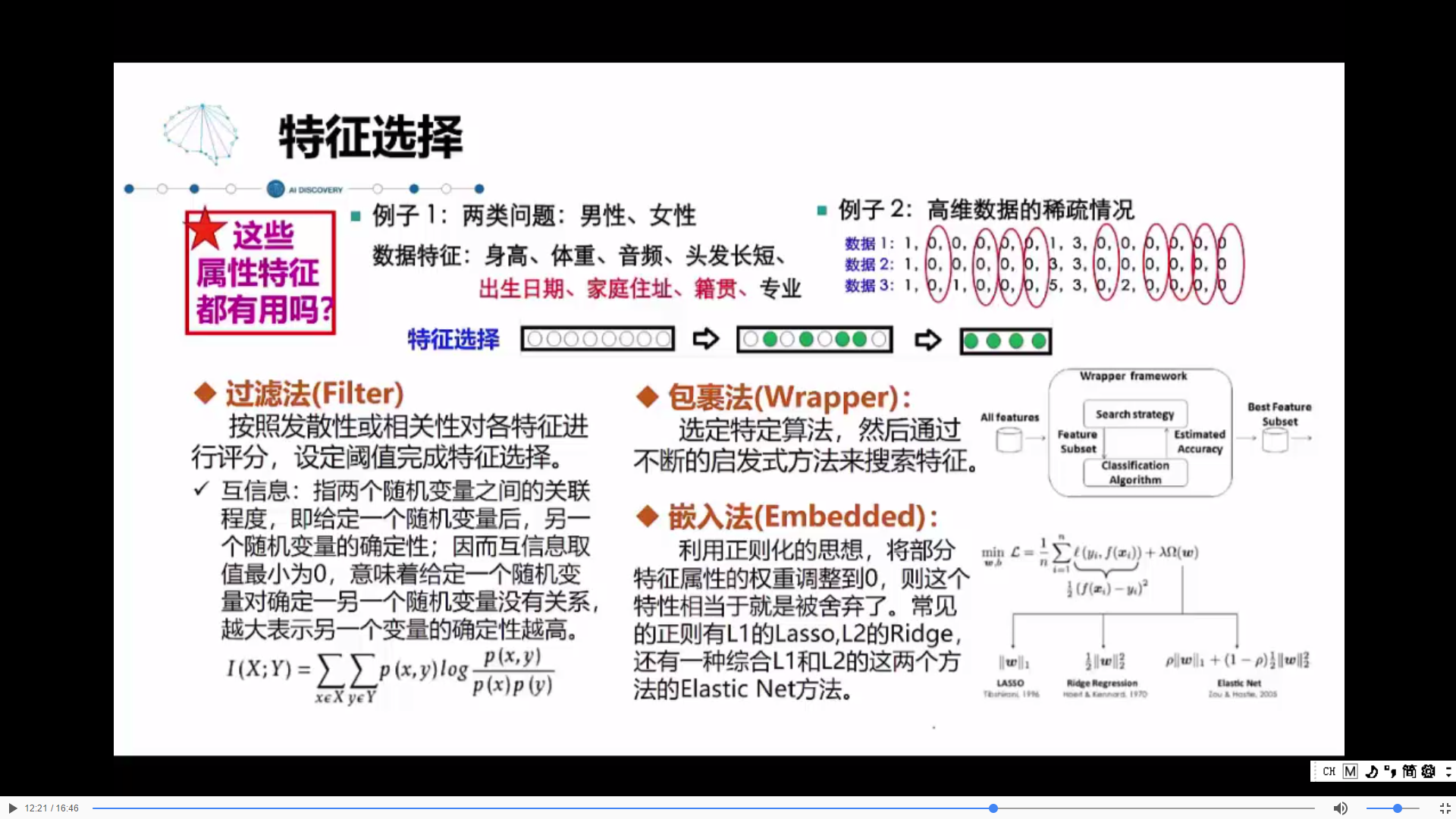
进行了特征的选择之后,将不需要的特征去掉,只留下需要的,但可能维度还是很大,就需要降维。
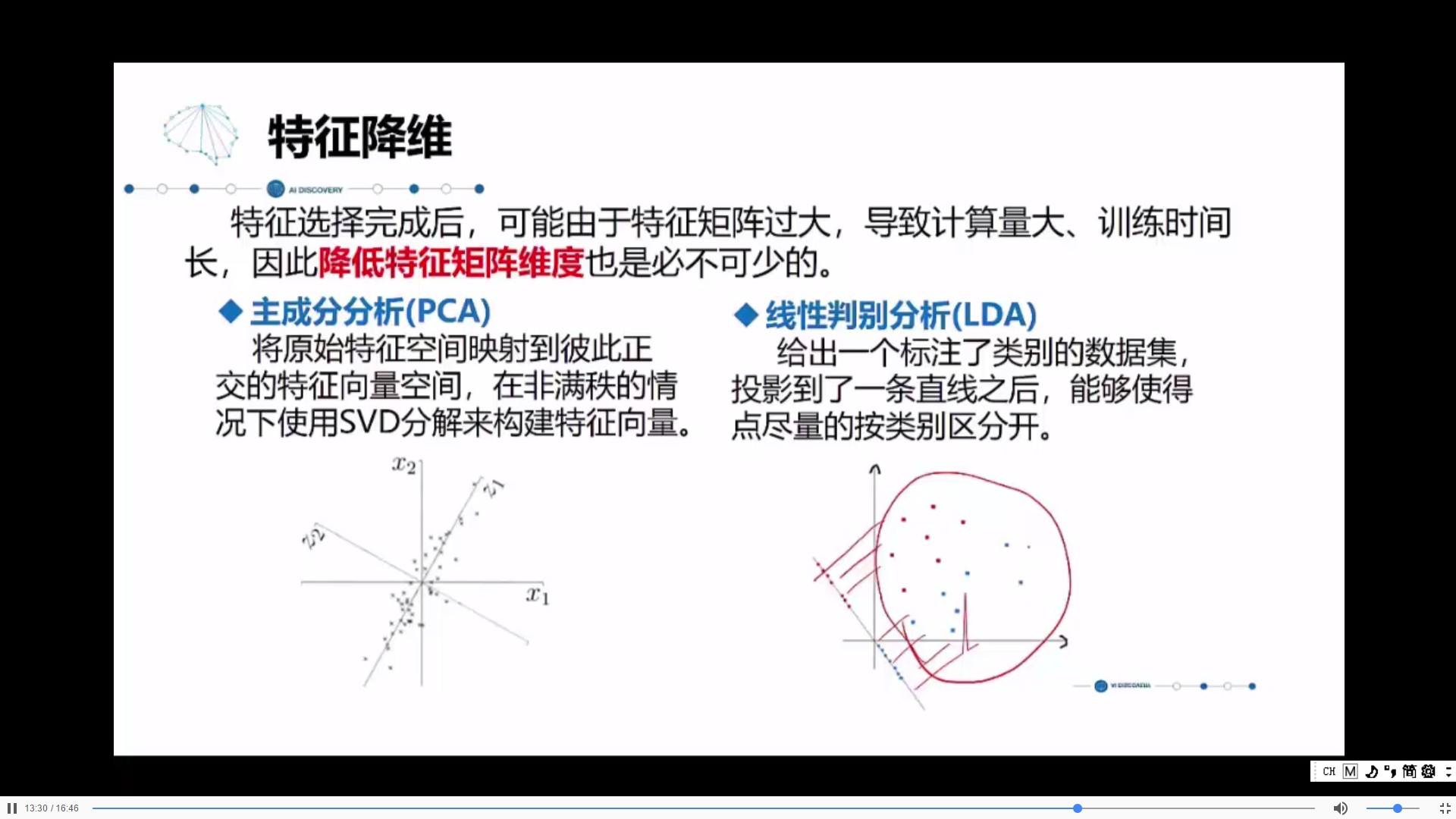
PCA:将高维度压缩到低维,把不需要的特征抹掉,只留下需要的;
LDA:比如图上将二维的点做投影,投影到一条直线上,也就是一维,还是能够按类别区分开,一类的一堆。

数据量级的不同,会导致数据之间无法比较,例如50m/s和500m/min,3km/小时机器不好判别
分类:
数据科学导论


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通