
容器类的入门知识
java容器类的用途就是用来保存多个对象,主要可以分为两类:
1)Collection:用来存储多个独立的元素(对象),继承它的子接口有三个:1)List必须按照插入的顺序保存元素2)Set不能存储重复的元素3)Queue按照元素的排队规则来决定元素的取出顺序(通常与元素的插入顺序有关)
2)Map:用来存储多个成对的键值对对象,可以通过键(对象)来查找对应的值(对象),其中List接口的实现类ArrayList可以通过数字(下标)来查找值,这在某种意义上有点类似Map中将键值用数字来与值关联起来
List
实现List接口的集合类对象可以存放多个重复的元素,List接口在Collection的基础上增加了大量的功能,使得我们能够在集合的中间插入或删除元素,主要的实现类有以下两种
- ArrayList:该集合类随机访问元素的效率较高,但在中间插入和移除元素的效率较低
- LinkedList:该集合在中间插入和移除元素的效率较高,但随机访问元素的效率较低
int length = 100000; Random random = new Random(); List<Integer> array = new ArrayList<>(); List<Integer> linked = new LinkedList<>(); for (int i = 0; i < length; i++) { array.add(i); linked.add(i); } Long time1 = System.currentTimeMillis(); for (int i = 0; i < length; i++) array.get(random.nextInt(length)); Long time2 = System.currentTimeMillis(); System.out.println("ArrayList的随机访问元素的时间:" + (time2 - time1) + "ms"); Long time3 = System.currentTimeMillis(); for (int i = 0; i < length; i++) linked.get(random.nextInt(length)); Long time4 = System.currentTimeMillis(); System.out.println("LinkedList随机访问元素的时间:" + (time4 - time3) + "ms"); Long time5 = System.currentTimeMillis(); while (!array.isEmpty()) array.remove(0); Long time6 = System.currentTimeMillis(); System.out.println("ArrayList移除对象的时间:" + (time6 - time5) + "ms"); Long time7 = System.currentTimeMillis(); while (!linked.isEmpty()) linked.remove(0); Long time8 = System.currentTimeMillis(); System.out.println("LinkedList移除对象的时间:" + (time8 - time7) + "ms"); /** output * ArrayList的随机访问元素的时间:14ms * LinkedList随机访问元素的时间:15600ms * ArrayList移除对象的时间:1098ms * LinkedList移除对象的时间:9ms */
1)从输出的前两行可以看出ArrayList的随机访问元素的效率明显高于LinkedList,ArrayList实际上是通过数组来存储对象,所以我们能够通过下标很快的查找到对应的元素,而LinkedList是链表式的存储结构,某个元素含有下一个与上一个元素的地址,而且访问元素的唯一入口是指向集合的第一个和最后一个元素的地址,例如我们若想访问第3个元素,就得通过第一个元素找到第二个元素,再通过第二个元素找到第三个元素,这就极大的降低了访问的效率,访问之前会先判断要访问的元素离起始元素的位置近还是结尾元素的位置近,再从离的较近的位置开始逐一访问,因此访问集合中间元素的效率是最低的
2)从输出的后两行可以看出ArrayList移除起始元素的效率明显低于LinkedList,这里我没有选择移除中间元素是因为移除中间元素必须要获取到这个元素,从1)中可以看出 LinkedList的获取中间元素的需要大量的时间,这会影响最终移除元素的时间,所以我选择移除访问时间相差不大的第一个元素,ArrayList移除第一个元素时必须将后面的每一个元素往前移动一个单位,这就需要大量的操作,而LinkedList只需将入口访问元素的地址指向第二个元素即可,其它元素不需要任何的改变
Set
Set具有与Collection相同的接口,即未在Collection的基础上增加额外的功能,Set集合中不能存放重复的元素,判断元素是否重复是通过调用元素的equals方法来于集合中的元素进行比较,Set中元素的存储位置是通过元素的值来确定的。Set接口的实现类有三个,如下:
- HashSet:为了提高查询效率,该集合中的元素排序使用的散列函数,使用的时候会发现元素的输出顺序是没有任何规律的
- TreeSet:将元素存储在红-黑树数据结构中,若想对输出结果进行排序可以使用该函数代替HashSet(大多数情况无需考虑元素的顺序所以HashSet的使用率最高)
- LinkedHashSet:为了提高查询效率也使用的散列函数,但是看起来它使用了链表来维护元素的插入顺序
int size = 10000; Random random = new Random(47); Set<Integer> hash = new HashSet<>(); System.out.print("插入的顺序 = ["); for (int i = 0; i < size; i++) { int num = random.nextInt(10) + 10; boolean flag = hash.add(num); if (flag) System.out.print(num + ", "); } System.out.println("]"); System.out.println("HashSet = " + hash); random = new Random(47); Set<Integer> tree = new TreeSet<>(); for (int i = 0; i < size; i++) tree.add(random.nextInt(10) + 10); System.out.println("TreeSet = " + tree); random = new Random(47); Set<Integer> linkedHash = new LinkedHashSet<>(); for (int i = 0; i < size; i++) linkedHash.add(random.nextInt(10) + 10); System.out.println("LinkedHashSet = " + linkedHash); /** output * 插入的顺序 = [18, 15, 13, 11, 19, 10, 12, 17, 16, 14, ] * HashSet = [16, 17, 18, 19, 10, 11, 12, 13, 14, 15] * TreeSet = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] * LinkedHashSet = [18, 15, 13, 11, 19, 10, 12, 17, 16, 14] */
以上代码中我选择了插入10-19的元素是因为jdk8中散列函数可能与jdk7中有所不同,若使用0-9的数字HashSet输出结果将与TreeSet一样好像对元素进行了排序,其中我为random重新赋值了两次是为了使三个集合的插入元素的顺序保持一致。从第二行的输出中可以看到元素的输出顺序与插入顺序无关,看起来毫无规则;从第三行的输出可以看出TreeSet集合中的元素存储在红-黑树数据结构中;从第三行的输出能看出LinkedHashSet中元素的存储与插入顺序有关
Queue
Queue(队列)是一个典型的先进先出的容器。即从容器的一端插入元素,从另一端获取元素,正是因为这个特性队列是一个可靠的传输对象的途径。队列在并发编程中非常重要。它的主要实现类有以下两种:
- LinkedList:不但实现了List接口还实现了Queue接口,所以该集合拥有许多ArrayList没有的功能,即一些对集合中首尾元素操作的方法
- PriorityQueue :即优先级队列,当插入元素时,会对这个元素进行排序,可以通过提供自己的比较器来对元素进行排序,每次获取的元素都是优先级最高的(最前面的)
Random random = new Random(47); System.out.print("元素插入的顺序 = ["); Queue<Integer> linkedList = new LinkedList<>(); for (int i = 0; i < 10; i++) { int num = random.nextInt(10); linkedList.offer(num); System.out.print(num + ", "); } System.out.println("]"); System.out.println("插入元素后的LinkedList = " + linkedList); for (int i = 0; i < 10; i++) linkedList.poll(); System.out.println("弹出元素后的LinkedList = " + linkedList); random = new Random(47); Queue<Integer> priority = new PriorityQueue<>(); for (int i = 0; i < 10; i++) priority.offer(random.nextInt(10)); System.out.println("插入元素后的PriorityQueue = " + priority); System.out.print("PriorityQueue中元素的弹出顺序 = ["); for (int i = 0; i < 10; i++) System.out.print(priority.poll() + ", "); System.out.println("]"); /** output * 元素插入的顺序 = [8, 5, 3, 1, 1, 9, 8, 0, 2, 7, ] * 插入元素后的LinkedList = [8, 5, 3, 1, 1, 9, 8, 0, 2, 7] * 弹出元素后的LinkedList = [] * 插入元素后的PriorityQueue = [0, 1, 5, 1, 3, 9, 8, 8, 2, 7] * PriorityQueue中元素的弹出顺序 = [0, 1, 1, 2, 3, 5, 7, 8, 8, 9, ] */
从上面的代码中可以看出LinkedList相比与ArrayList多了offer与poll方法对集合的首尾元素进行操作,LinkedList还有许多特有的方法这里就不列举出来了。从元素的插入顺序与插入元素后的PriorityQueue中可以看出元素插入的时候对元素进行了排序,而且在元素弹出的时候又对队列中的元素进行了排序
Map
将对象映射到其它的对象可以解决一些比较难实现的功能,Map中存放的就是以两个对象组成的键(key)值(value)对,Map中的key是不能重复的这就保证了每个键值对都是不同的,但是value值是可以相同的,我们可以通过key快速的获取value。Map的主要实现类有以下两种:
- HashMap:该Map中的元素通过key的散列码进行排序,可以存放key值为null的键值对,但不能有多个
- LinkedHashMap:该类在日常的编码中很少用到
Random random = new Random(47); Map<Integer, Integer> map = new HashMap<>(); for (int i = 0; i < 10000; i++) { int num = random.nextInt(20); Integer value = map.get(num); map.put(num, value == null ? 1 : value + 1); } System.out.println(map); /** output * {0=481, 1=502, 2=489, 3=508, 4=481, 5=503, 6=519, 7=471, 8=468, 9=549, 10=513, * 11=531, 12=521, 13=506, 14=477, 15=497, 16=533, 17=509, 18=478, 19=464} */
这段代码实现了对随机产生的10000个0-19数字进行统计各个数出现的次数,若我们想通过集合实现这个功能则需要将这10000个随机数进行多次遍历来逐一统计每个数出现的次数。这不仅增加了代码实现的难度,而且实现后的效率将会明显低于Map
最后附上一张java容器的简图。这里只包含了你在一般情况下会使用的接口和类,忽略了所有抽象类,另外还有一些过时的容器类,例如Vector、HashTable和Stack也没有出现在下面的图中
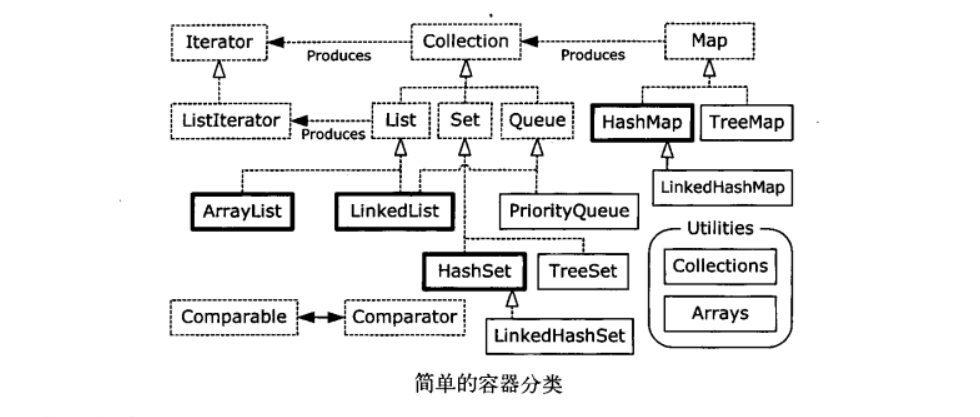
实现框表示类(加粗的是常用的);虚线框表示接口;带有空心箭头的虚线表示实现了某个接口;带有空心箭头的实线表示继承某个类;带有实心箭头的虚线表示可以产生它

