
哈希算法及其拓展
本篇是iOS逆向开发的递进篇-关于哈希算法、数字签名及对称加密等,下面我们着重讲解此内容,希望对大家有所帮助!!!
一、哈希
1.1 基本内容
哈希表也称为散列表(Hash table),是根据关键码值(key,value),直接进行访问的数据结构。通过把关键码映射到表中的一个位置来进行访问记录,用来加快查找速度。映射函数也称之为散列函数,存放记录数组称为散列表。
假设没有内存限制,直接可以将键作为数组的索引,那么所有的查找仅仅需要一次即可完成。但是这种理想的情况也不会一直出现,因为牵扯到内存问题。从另一个角度来说,如果没有时间来限制,我们也可以使用无序数组并进行顺序查找,这样也会使用较少的内存。
使用哈希查找算法分为两个步骤:
- 使用Hash函数将被要查找的键转化为数组中的一个索引。理想情况下,不同的键都可以转为不同的索引值。但这仅仅是理想情况下,在实际的开发运算中,我们还是要处理两个或者多个键值散列到同个索引值的情况。
- 要处理碰撞冲突的过程。
目前本人博客关于讲述哈希思想查找元素的博客有:https://www.cnblogs.com/guohai-stronger/p/11506990.html,还会持续更新此类算法思想有关的题目。
1.2 哈希函数的两种解决碰撞的方式
1.2.1 拉链法(separate chaining)
拉链法简单说就是链表+数组。将键来通过Hash函数映射为大小为M的数组下标索引,数组的每个元素指向链表,链表的每个节点存储着哈希出来的索引值为节点下标的键对值。
举一个例子:
给定一组数据为{45,27,55,24,10,53,32,14,23,01,42,20},假设散列表长度为13,用拉链法解决构造的哈希表。拉链法表示如下:
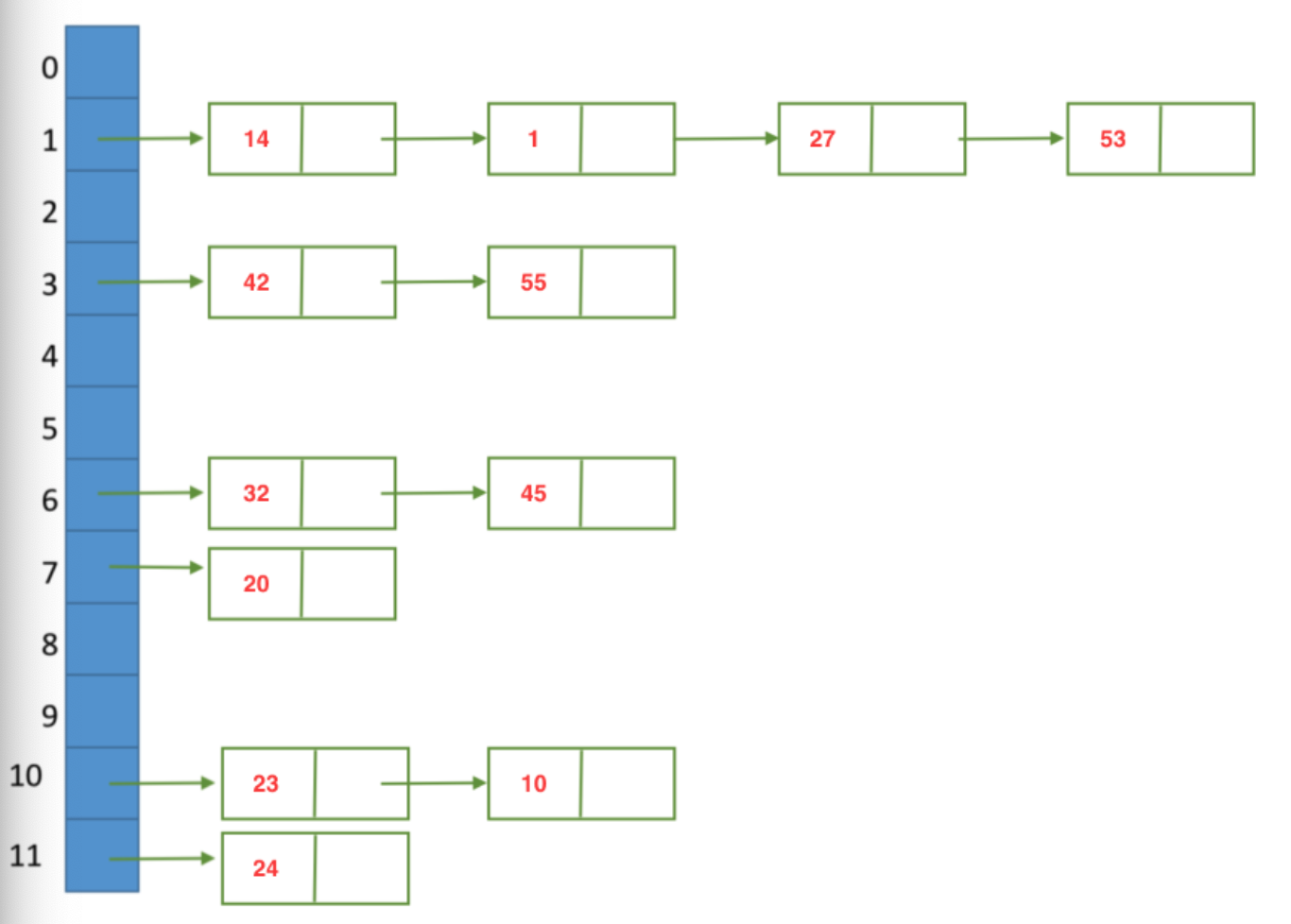
上面就是拉链法的图示,下面我们讲解拉链法的代码实现:
public class SeparateChainingHashST<Key, Value> { //SequetialSearchST private int N;//键值对总数 private int M;//散列表的大小 private SequentialSearchST<Key, Value>[] st;//存放链表对象的数组 public SeparateChainingHashST() {//默认的构造函数会使用997条链表 this(997); } public SeparateChainingHashST(int M) { //创建M条链表 this.M = M; //创造一个(SequentialSearchST<Key, Value>[])类型的,长度为M的数组 st = (SequentialSearchST<Key, Value>[]) new SequentialSearchST[M]; for(int i = 0; i < M; i++) { //为每一个数组元素申请一个空间 st[i] = new SequentialSearchST(); } } private int hash(Key key) { return (key.hashCode() & 0x7fffffff) % M; } public Value get(Key key) { return (Value)st[hash(key)].get(key); } public void put(Key key, Value val) { st[hash(key)].put(key, val); } public void delete(Key key) { st[hash(key)].delete(key); } public Iterable<Key> keys(){ Queue<Key> queue = new Queue<Key>(); for(int i = 0; i < M; i++) { System.out.println("第" + i +"个元素的链表"); for(Key key : st[i].keys()) { queue.enqueue(key); System.out.print(key + " " + get(key) + " ,"); } System.out.println(); } return queue; } public static void main(String[] args) { SeparateChainingHashST<String, Integer> st = new SeparateChainingHashST<String, Integer>(5); for (int i = 0; i < 13; i++) { String key = StdIn.readString(); st.put(key, i); } for (String s : st.keys()) StdOut.println(s + " " + st.get(s)); st.delete("M"); StdOut.println("*************************************"); for (String s : st.keys()) { StdOut.println(s + " " + st.get(s)); } } }
上面就是拉链表的基本内容,如果想进一步了解,可以查看数据结构相关书籍。
1.2.2 开放定址法
开放定址法包括线性探测法和平方探测法。
开放定址法是由关键码得到的哈希地址一旦发生了冲突,假如已经存在了元素,就会去寻找下一个空的哈希地址,只需要哈希表足够的大,空的哈希地址总能找到,并将元素存入进去。
1.3 哈希的特点
- 算法是公开的
- 对相同的数据运算,得到的结果是一样的
- 对不同的数据运算,如用MD5得到的结果默认为128位,32个字符(16进制)
- 这玩意没办法进行逆运算
- 信息摘要,信息的指纹,都是用来数据识别的
1.4 哈希用途加密方式
1.4.1 用户密码的加密
1.4.1.1 直接使用MD5加密
//密码 NSString * pwd = @"123456"; //MD5 直接加密 e10adc3949ba59abbe56e057f20f883e //不足:不够安全了。可以反查询! pwd = pwd.md5String;
我们也可以通过终端,通过输入md5 -s "内容",如下得到md5,32个字符
![]()
1.4.1.2 加盐
//足够复杂! static NSString * salt = @"(*(*(DS*YFHIUYF(*&DSFHUS(*AD&"; pwd = [pwd stringByAppendingString:salt].md5String;
运用加盐方式弊端: 盐都是是固定的,把它写死在程序里面,一旦泄露就会不安全了!
1.4.1.3 HMAC
/** HMAC * 使用一个密钥加密,并且做两次散列! * 在实际开发中,密钥(KEY)来自于服务器(动态的)! * 一个账号,对应一个KEY,而且还可以跟新! */ pwd = [pwd hmacMD5StringWithKey:@"hank"];
在我们日常开发中,如果一个是有非常好的后台开发素质,会在登录注册接口返回来一个时间戳,对于这个时间戳可以很好地运用到HMAC中

通过上面:
假如将时间戳运用到里面中,和HMAC哈希值拼接此时的时间戳(直到分,不到秒)发给服务器,然后服务器根据客户端发来的字符,进行解析;如果此时这个过程到了下一分钟(201812032050 58s发,服务器收到已经201812032051 20s ),服务器会做一个分钟-1进行验证
1.4.2 搜索引擎
我们在搜索几个词语时,假如在数据库检索“国孩”,“真的”,“很帅”,对于我们搜索其中的任何一个词,都可以通过哈希检索出来,哈希内部是怎么做到的呢?
下面是三个词在md5下的32位字符值:
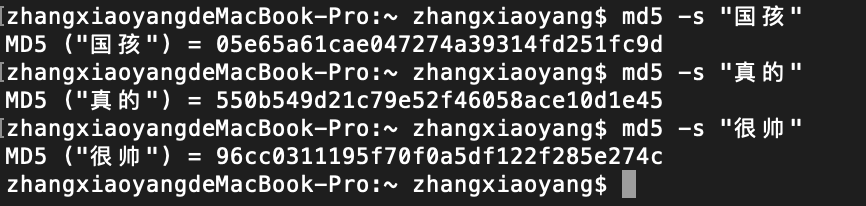
哈希通过将“国孩”,“真的”,“很帅”的哈希值进行想加,得到了也是一个32位字符串
1.4.3 版权
对于很多源文件上传至某个平台上时,该平台会给源文件设置唯一一个哈希值,如果有盗版上传至该平台,会被拒绝
二、数字签名
数字签名是对原始数据的HASH值,用非对称RSA加密
明文数据和HASH值如果通过直接传递就会有篡改的风险,因此我们要对数据加密。但是明文数据是比较大的,不太适合运用RSA非对称加密,那么数据的HASH值是比较小,这个数据如果用来校验,这样就完全可以使用RSA进行加密。当我们在数据传递的时候,可以通过将明文数据+RSA加密的校验数据一起发送给对方,RSA加密的校验数据,称之为签名。
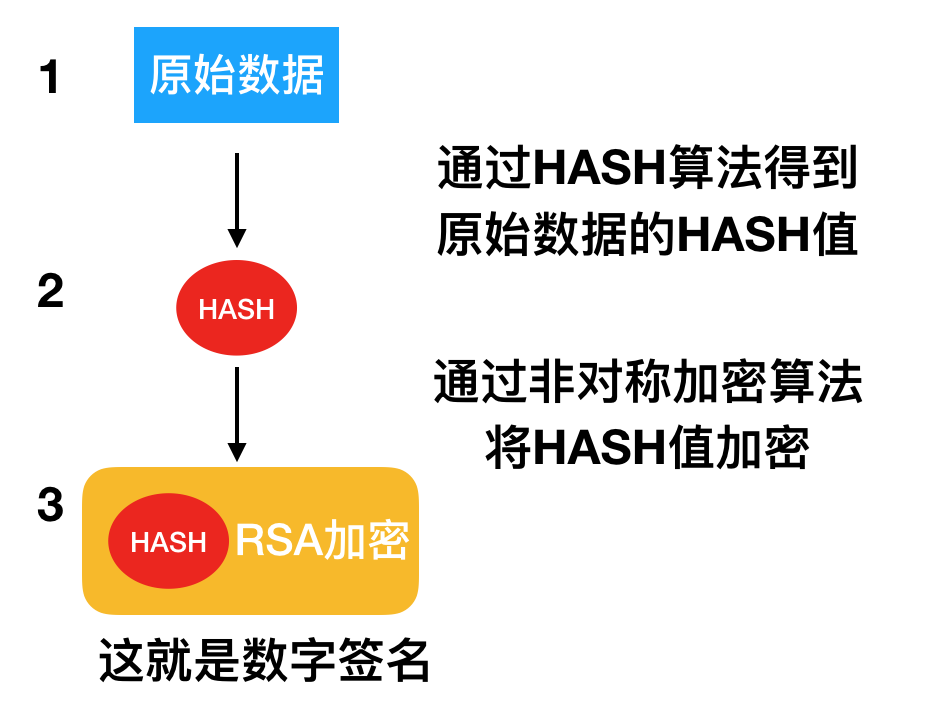
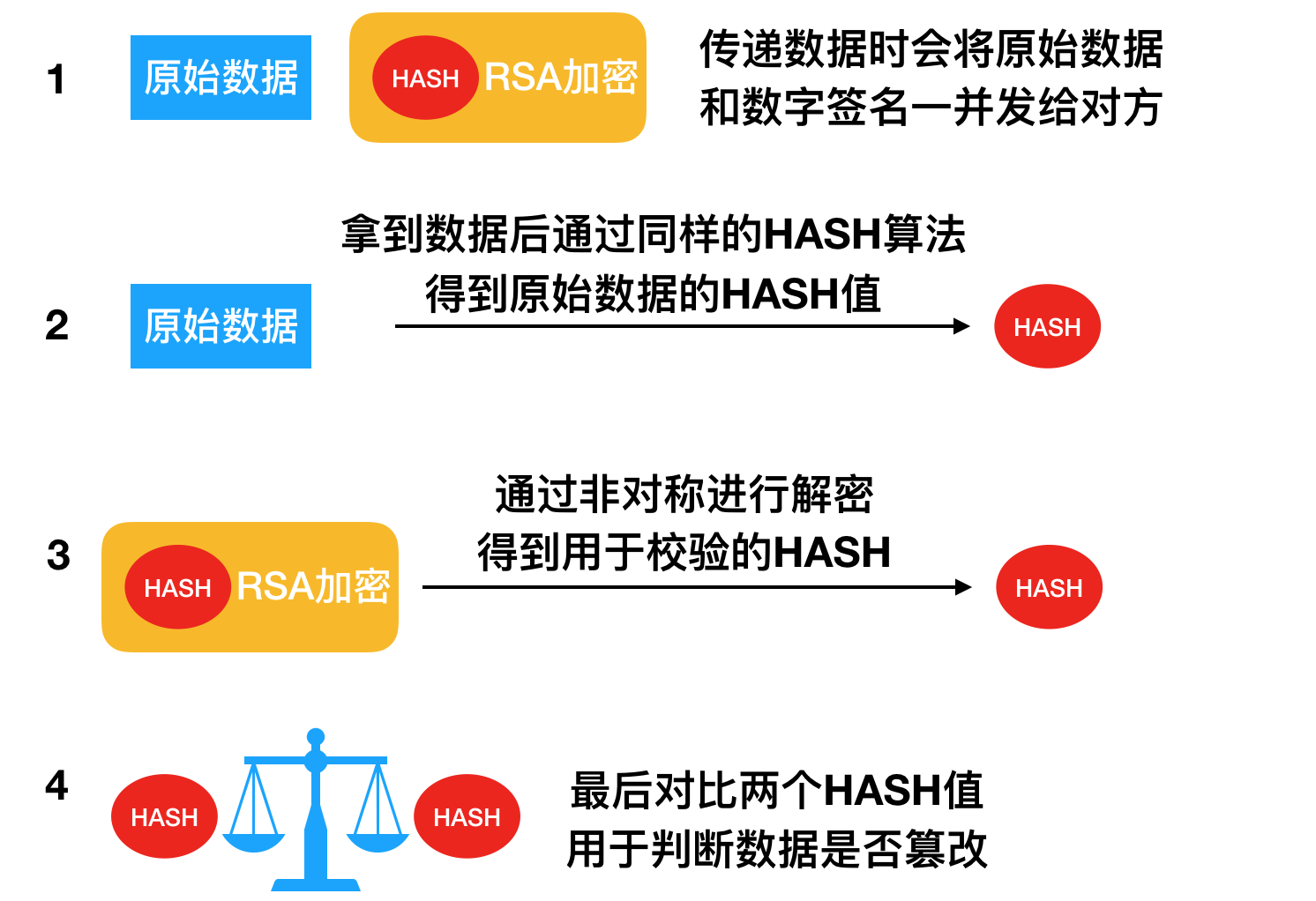
下面我们来讲述一下数字签名验证的过程:当对方拿到数据之后,如何验证呢?
- 首先传递数据时会将原始的数据和数字签名共同发送
- 对方拿到数据之后,先进行校验,拿到了原始数据,经过同样的HASH算法得到数据的HASH值
- 紧接着通过非对称加密,将数字签名中的校验HASH解密出来
- 对比两个HASH值是否是一致的,这样就可以很好地判断数据是否被人篡改啦
上面是过程,下面有一份图解:
三、对称加密
对称加密就是明文通过密钥得到密文,然后密文通过密钥解密得到明文。
常见算法:
- DES:数据加密的标准(用的比较少)
- 3DES:(数据三次DES加密,强度增强了)
- AES:(高级密码标准)--钥匙串访问用到了
应用模式如下图解:
总结,上面就是关于哈希的基本内容和拓展,希望对大家对关于理解哈希有更深的感触!!!下一篇我们将继续讲述iOS逆向开发的另一篇----应用签名和重签名。

