

🔥5分钟入门大模型,就5分钟
这个是大模型系列课程的第一节。
接下来我带着大家一起拥抱新技术,分享的进展不会很快,大概一周一次,有空可以直播讲解或实操。
为了照顾那些工程出身,甚至非技术同学,我这个系列会从小白开始,从基础概念入门逐步展开。
我不会研究基础大模型,而是会关注应用层,当然也会涉及预训练、知识库、多智能化跟模型最终效果息息相关的部分。
废话不多说,赶快上车。
我们先理解一下什么是大模型,先从 ChatGPT 来学习大模型。
ChatGPT(Generative Pre-trained Transformer)从名字上已经表明了它的特点,
“Chat” - 聊天,
G:“Generative” - 生成式,
P:“Pre-trained” - 预训练,
T:“Transformer” - 大模型推理架构
Chat-聊天
聊天大家基本都理解,你说一句,它回你一句,所以叫“Chat”-GPT。
Generative-生成式
乍一听啥玩意?
我们跟之前模型的玩法做个对比,就理解了。
比如你在百度/Google 上搜索,它都是把一堆文章和链接返给你,但是GPT 是什么样的,用过的都知道,尤其是网络不好的时候更明显,GPT 就像有口吃,讲话是一个词一个词往外蹦。
为什么呢?
来到了大家最爱的原理剖析了,面试官即视感,来,请讲讲底层原理😄!!
容我先举个🌰,你让 ChatGPT 写一句话描述打工人周一上班的状态。
大模型生成了一句:“周一上班真的很—— 爽(0.2)/ 丧(0.8)
爽和丧都是模型产出的词,每个词都有对应被选中的概率,大模型在选择下一个词的时候就是根据括号里面的概率来定的,那这个词和概率是怎么来的呢?
这个就是根据前期喂给它的语料训练有关系,这个比较深奥,一般二面面试官才问这个,你先记住这个题要考。
这篇文章是第一篇,有些地方不宜讲太深【其实是因为我也还没学到】。
虽然我知道你们对知识如饥似渴,但是这次我们选择浅尝辄止。
当你给大模型一段输入,接下来大模型会做4 件事:
- 将文本编码:模型首先将输入的文本串分词,然后将文字转换为向量(embedding),向量这个词可能有读者会陌生,没关系,你先知道有这个东西,后面会讲的;
- 预测下一个词:基于当前用户的输入以及所有前面的上下文,GPT 会计算接下来每一个可能的单词或标记的概率,这个概率表明了在当前上下文中每一个单词接下来出现的可能性,就是上面的爽(0.2)和丧(0.8)。
- 选择单词:从概率最高的单词中选择一个作为输出(常规做法);
- 重复上述过程:接着,模型会将新生成的单词加入到已有的文本序列中,并基于这个更新后的序列重复上述预测和生成过程,直到达到某个停止条件(如生成特定数量的单词、达到句子结束标记等)。
“生成” 简单来说就是根据给定内容,预测和输出接下来的对应内容。
跟生成式模型相对应的是判别式模型,判别式模型通常用于处理分类任务,也先不纠结这个,先记住这次词,后面我在讲传统机器学习训练,西瓜保不保熟的例子会讲到。
要记的词好多,对吧。
前面讲了这么多,大白话讲一下重点:
其实大模型的核心机制就是生成一堆候选词,每个候选词都带个概率值,每次选概率高的输出(常规做法),循环往复。
Pre-trained 预训练
再来说预训练,啥又是预训练?
不要虚,看拉哥砍瓜切菜,三二下就给你整明白了。
“预训练”是相对“训练”而言的,所以我们先得知道什么是训练。
训练是机器学习的概念,我以西瓜书里面的经典例子来讲“训练”的概念。
比如我们要训练一个模型,用来根据西瓜的外型判断西瓜是否熟?
这个强子比较有发言权。
我们来看下训练的过程,比如西瓜熟,一般从色泽、根蒂、敲声三方面来看
在机器学习的概念里面,色泽、根蒂、敲声 这三个叫做特征,是否熟是结果
从数据中学得模型的过程称为“训练”
比如我买10 个瓜,记录每个瓜的色泽、根蒂、敲声,然后把每个瓜都切开,看是不是都熟了。
从特征和结果找规律就是学习或者叫训练的过程,这10个瓜就是我用来学习的“样本”,或者叫“数据集”。
形式化表达 Y = f(x1) + f(x2) + f(x3);
Y 只有二种结果,熟 或者 不熟,训练的参数有三个,样本量有10个,最后能学习到色泽青绿、根蒂蜷缩、敲声浑浊的瓜熟的概率最大,这就是“训练”。
这个例子也是上面说的传统机器学习中的可以用来处理分类任务的判别式模型。
再加个餐,机器学习里面除了分类,还有另外一类任务,叫做回归(regression),分类的模型结果是离散值,比如这里瓜熟不熟,只有二种值,回归任务模型结果是连续值,比如预测瓜的含糖量,一般是一个范围内的连续值。
好了,大家现在应该对训练有了大概的认知,接下来我们来说说预训练。
大模型之所以被称为“预训练”模型,是因为模型在有监督训练和微调之前,先进行了一波大规模的无监督预训练阶段。
很多同学可能之前没学过机器学习,这里有个概念要讲解下:无监督和有监督是什么意思?
比如前面那个瓜熟不熟,是每个瓜都会被切开看,有个明确的结果值:熟还是不熟,这就是有监督。
而无监督学习,代表数据集中没有标签,算法需要从数据本身中发现结构或模式。
还是以瓜为例子,如果是无监督,我学习的目标可能不是区分瓜是不是熟,而是算法自己从这些瓜里面找规律,最后算法发现要把颜色相近、根蒂卷曲程度差不多的瓜放在一起,这个叫聚类,这么说大家明白了吗?
那在ChatGPT 里面也是类似,预训练的时候不涉及带有标签的训练,直接把互联网大量的咨询、文章等丢给模型,让模型学习词汇、语法、语义以及上下文信息。通过这个过程,模型能够学习到丰富的语言知识和表示能力。
在预训练完成后,这些模型可以进一步进行有监督的微调或特定任务的训练。通过微调,模型可以根据特定任务的数据进行具体的训练和调整,使其更适应特定任务,提高性能。
总结起来,预训练模型通过在大规模无监督数据上进行训练,为模型提供了基础的语言理解和表达能力。其后,通过特定任务的微调,将模型应用到具体的任务上,并提升其性能和适应性。这种两阶段训练的方式使得预训练模型相比传统NLP 自然语言处理任务中取得了更显著的突破。
好,能学到这的人我觉得稳了,加餐加餐。
大模型为什么叫大模型,其中一个大的体现就是参数非常大,刚才我们看判断瓜是否熟的模型参数只有三个,一般大模型的参数都是十亿起步,比如GPT3 的参数规模是175B,1B(1 Billion)等于10亿(即(10^9)),所以GPT3 有1750 亿个参数,属于千亿级的参数,GPT4 参数更夸张,是1.8万亿参数,训练一次就得 6300万美元!
其实大模型所用到的技术跟传统NLP 本质上没有区别,但是由于参数量级巨大,带来了一个关键的变化,就是模型具备了“涌现”能力,下面这个图就是一个说明,当模型参数达到一定量级,就好像出现了人工智能,机器有了“自主意识”,能“生成”了。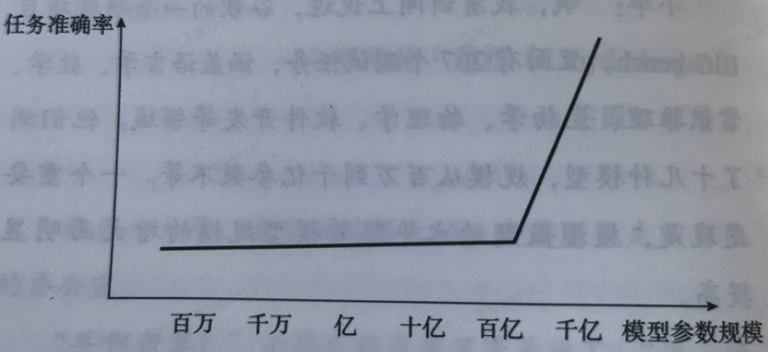
我很喜欢“涌现”这个词,这个词就好像武侠小说里的主人公,当内力达到一个临界值之后,全身经脉打通,武力值爆表。
希望我的读者在大模型技术上都能“涌现”,嗯嗯嗯~~~。
这篇文章就到这里,下篇讲大模型核心训练框架-Transformer,也就是ChatGPT 的最后一个单词T。
公众号推送机制变了,大家可以右上角“精选”,不怕错过拉哥的推送,如果看完觉得有收获,别忘了一键三连(点赞、转发、在看),你的支持是拉哥创作最大的动力。
如果大家对大模型感兴趣,可以添加拉哥微信,备注“大模型”,已经添加的发送“大模型”,拉你进大模型-学习机器群,大家共同进步。
本文由mdnice多平台发布
