

[JVM]一次线上频繁GC的问题解决
起因:周末测试发现线上mq消息积压了十几万的消息,如下图所示
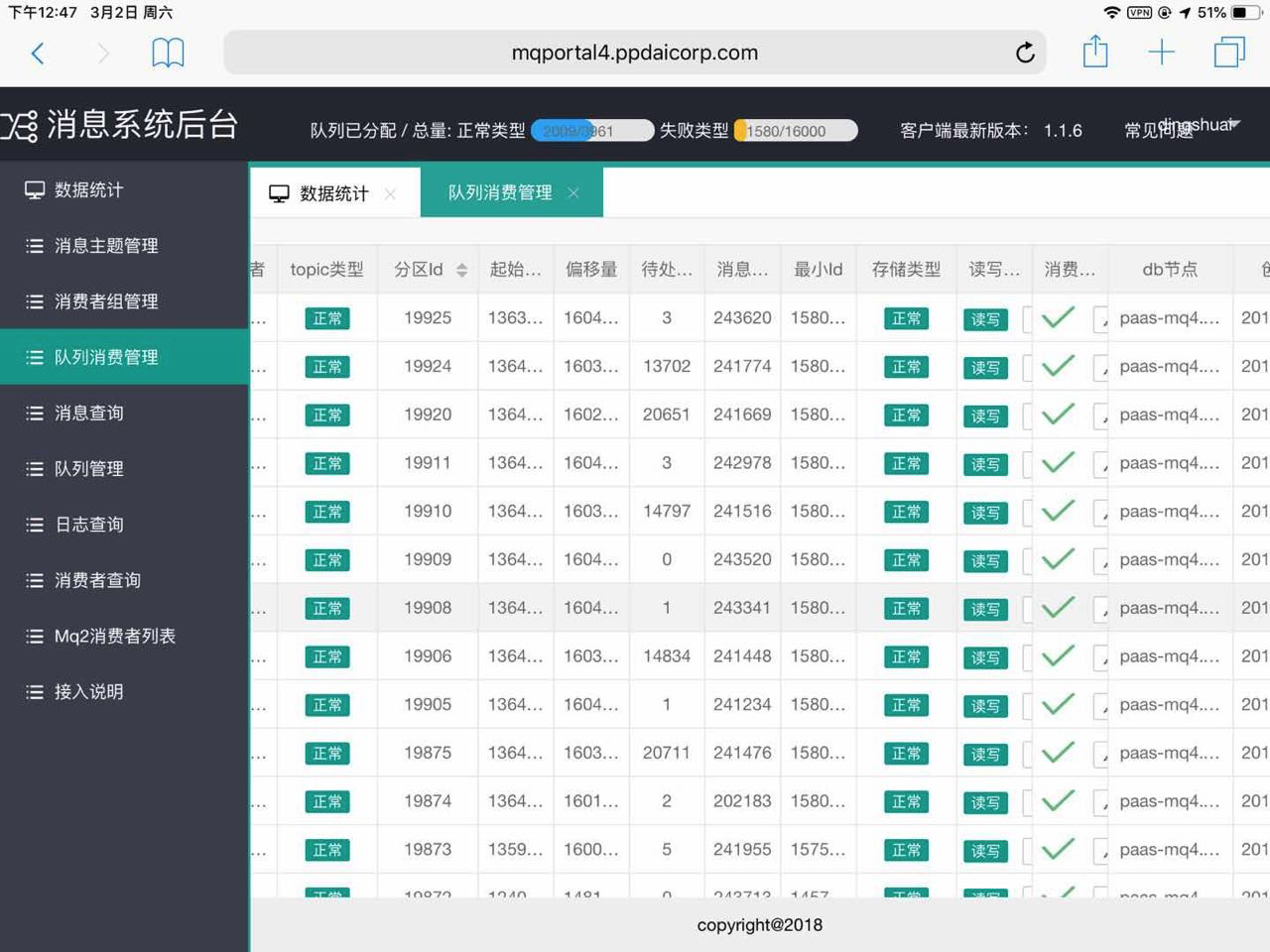
每个队列几万的消息,立即采取紧急措施,将队列下线重新上线。
处理积压消息的量,调用量起来了,很快消息积压解决了。开始事件复盘。
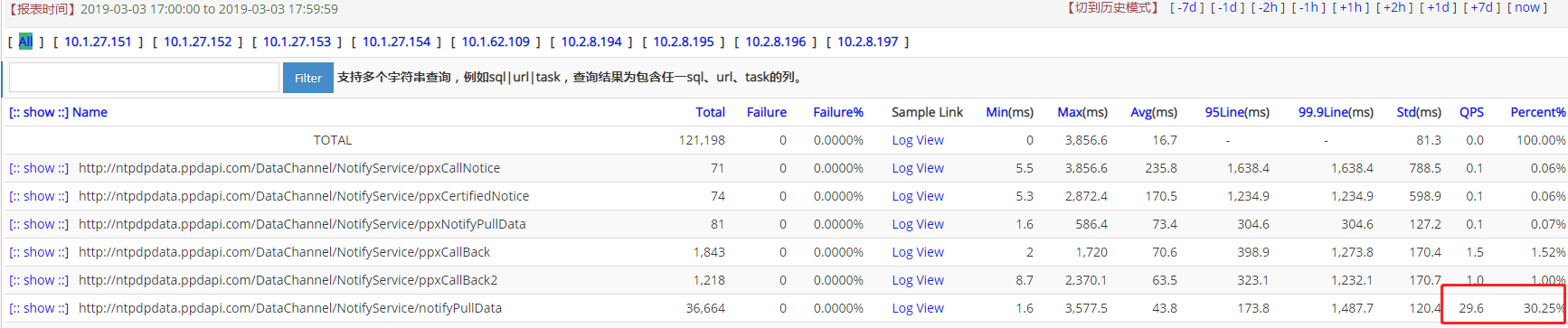
首先分析是否是消息消费能力跟不上消息产生原因,看入口消息,QPS是29.6
消息消费QPS如下

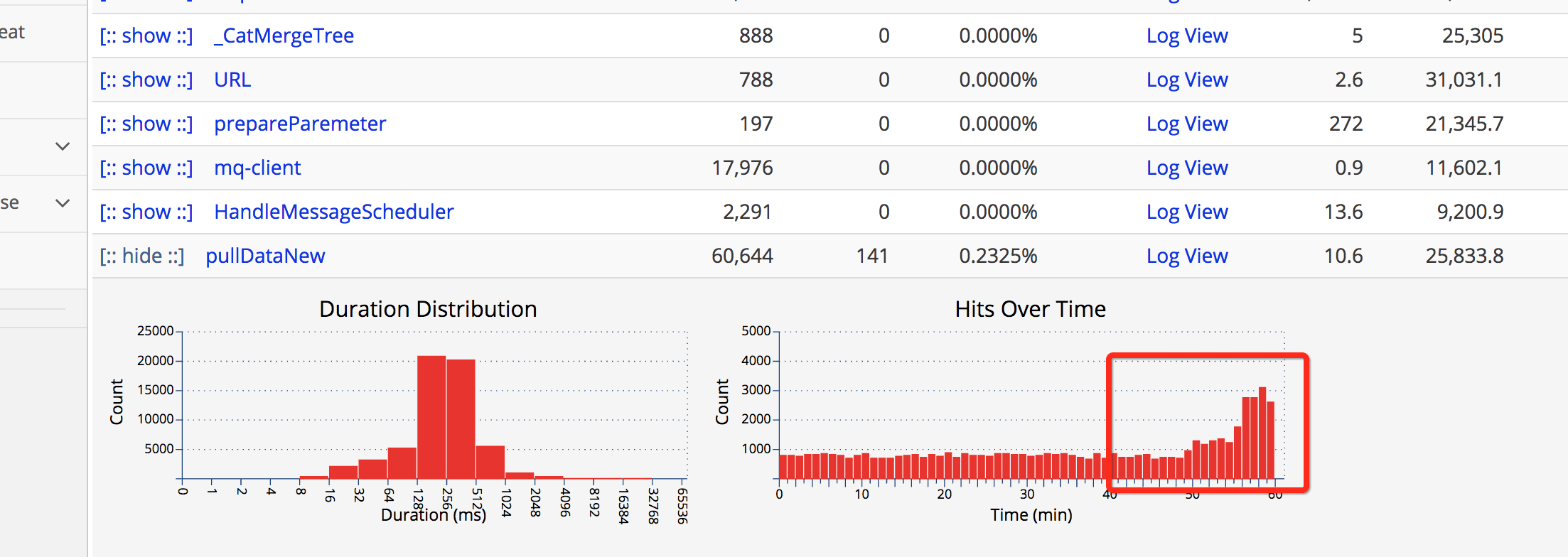
事后开始分析原因,发现队列积压有如下异常:

超时时间设置的很长,大致分析出消息处理线程等待下游接口超时,连接下游接口设置的超时时间很长,为什么下游接口如此多SocketTimeOut呢?
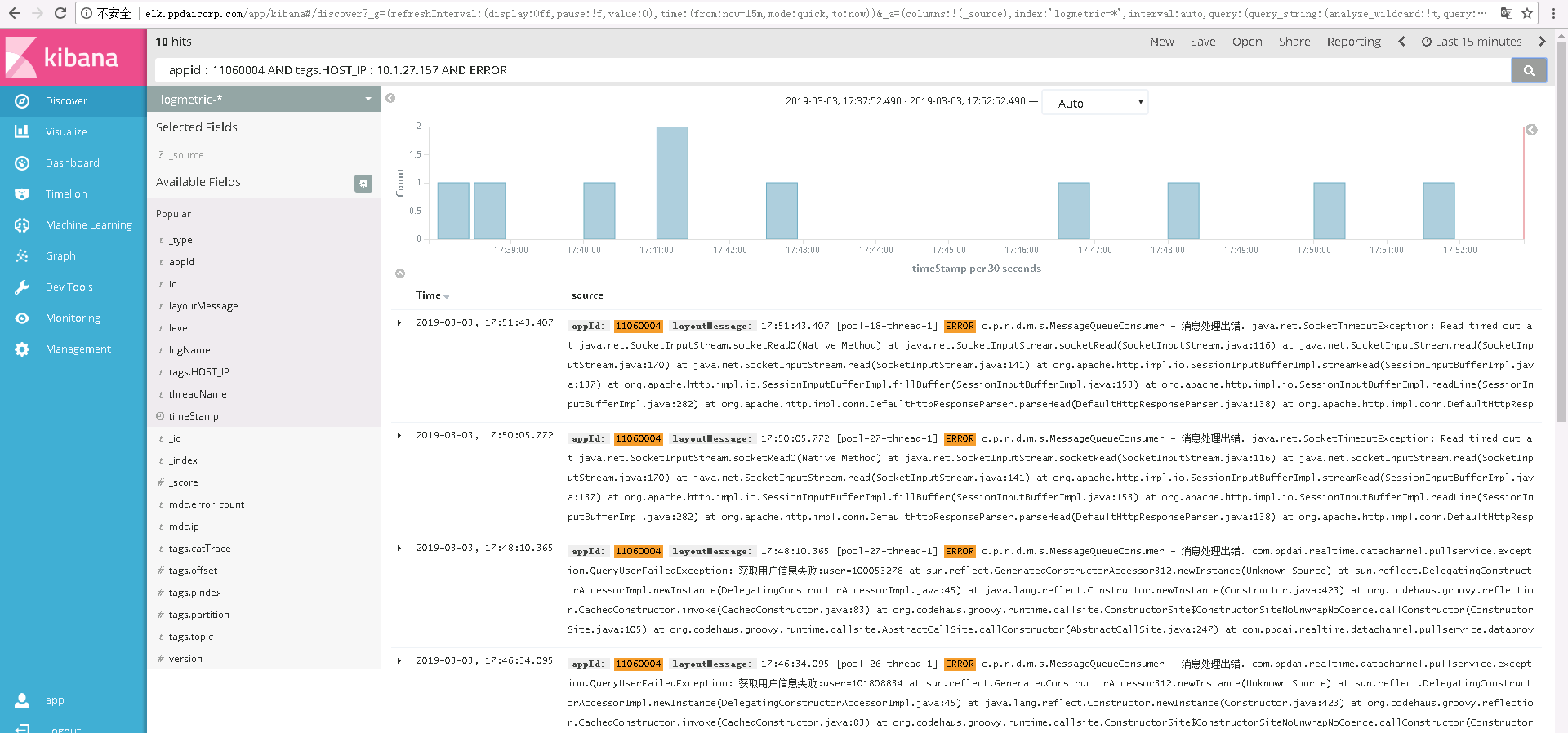
然后查看具体的超时接口,调用的下游站点发生SocketTimeout

查看下游站点接口的Cat,发现调用时间极不规律,如下图所示
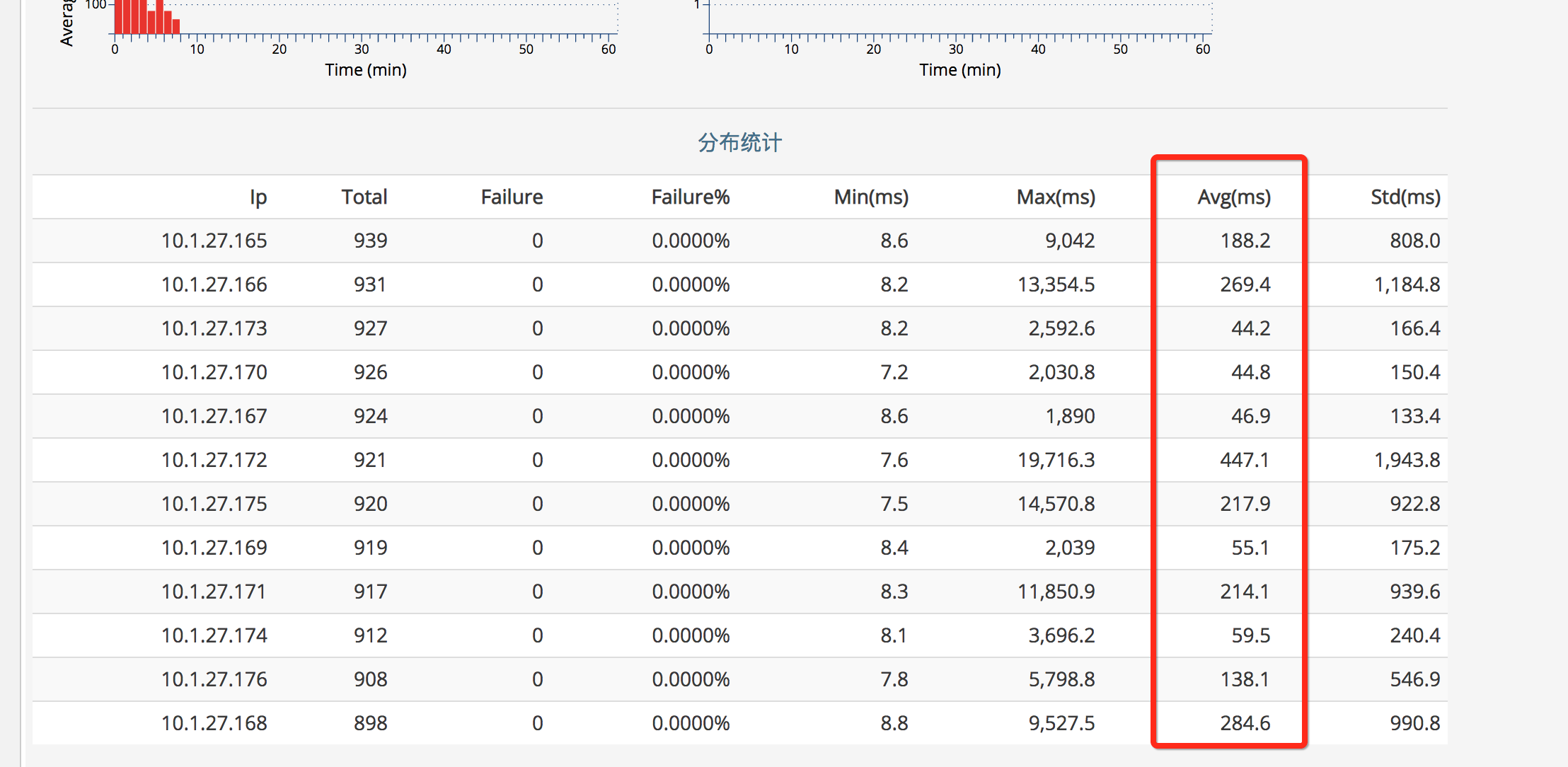
看日常的调用时间如下图所示,都不超过100ms的:
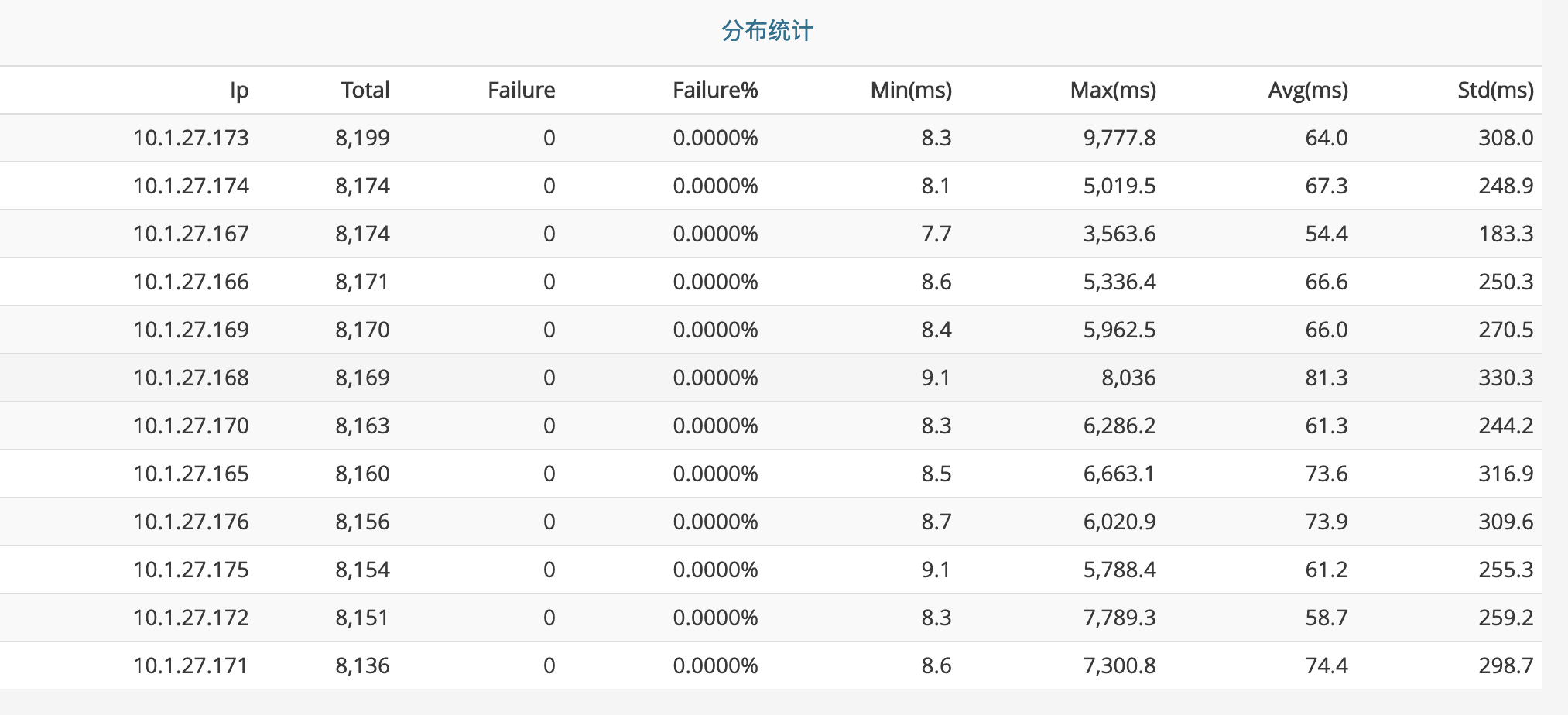
再看部分机器的GC内存回收,惊呆了,因为这个站点有几个月没有重新发过版本,发现GC如下图,压根没有年轻代的事,新申请的对象都需要在老年代申请,所以导致老年代一直回收。
找一台机器,把GC回收dump下来分析,使用mat查看,如下图所示:
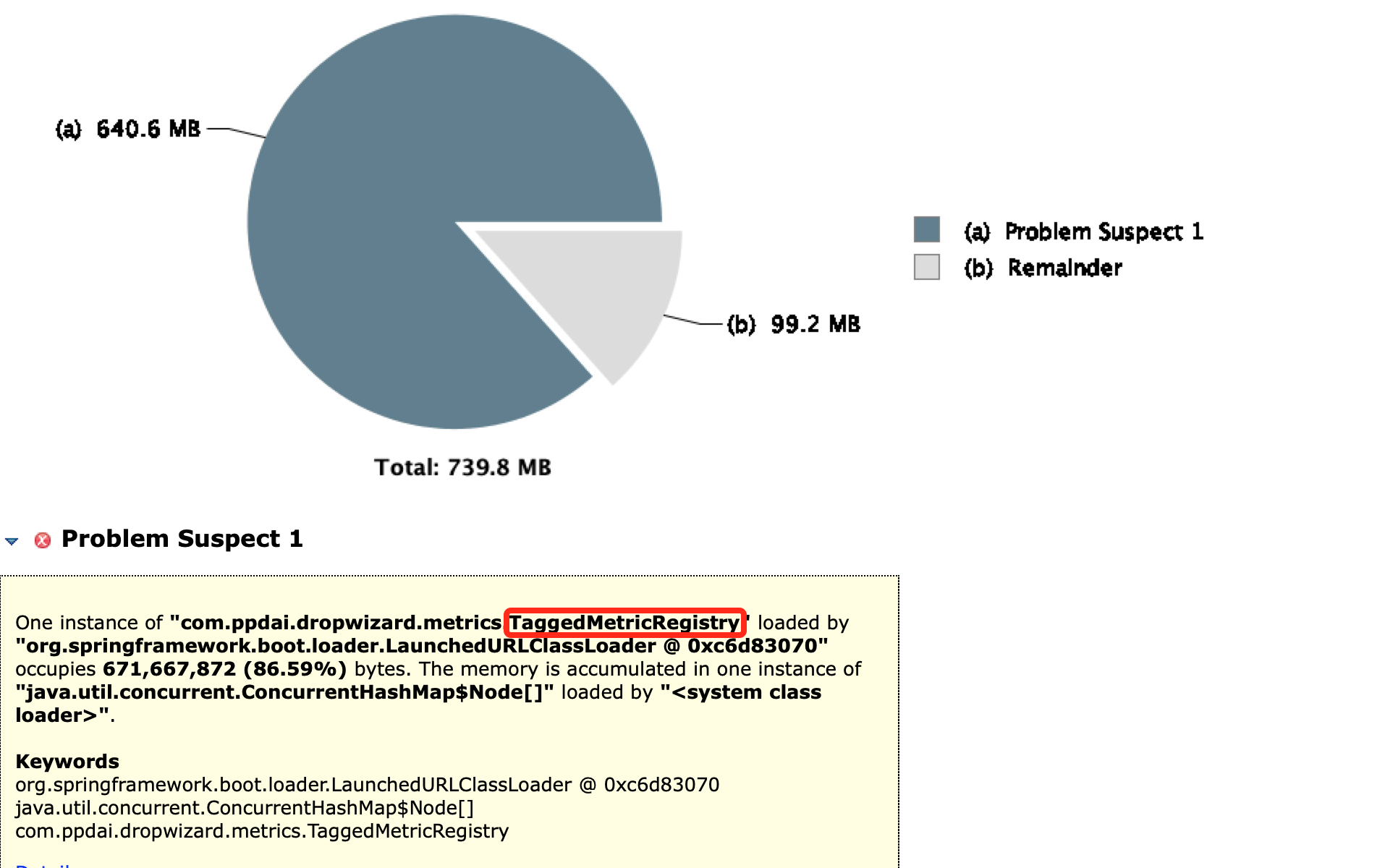
一共七百多M空间,一个对象就占了640M空间,找到原因了,继续往下,看这个对象为什么会这么大,从GC Roots最短路径如下,解释下
Shallow Heap指的是对象本身占据的内存大小 Retained Heap = 本身本身占据内存大小 + 当前对象可直接或间接引用到的对象的大小总和,
换句话说,就是当前对象如果被回收,能够回收的内存大小。
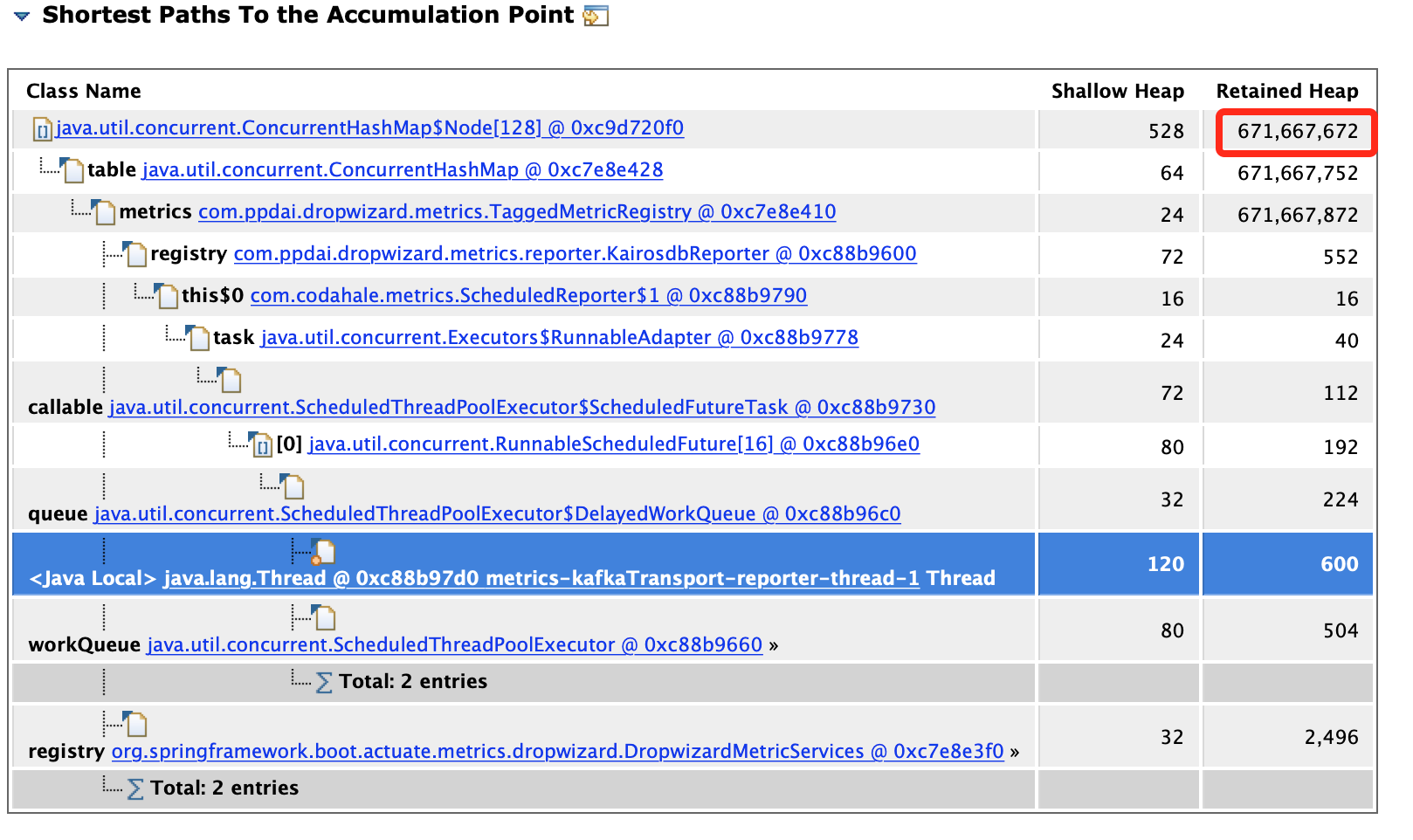
继续看,第一步,查看谁引用了这个对象,找到自己代码中的类,
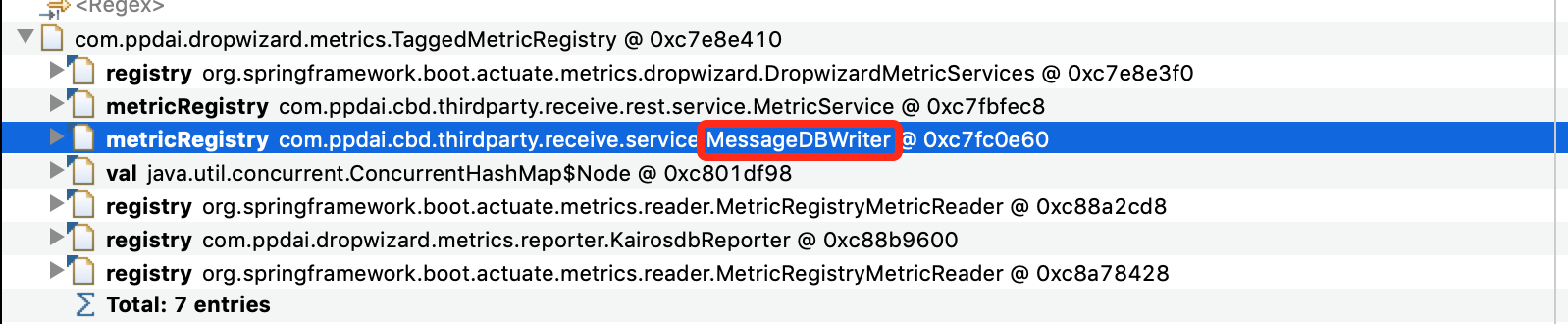
第二步,查看这个对象TaggedMetricRegistry都引用了谁,为什么会占用这么大的内存空间,如下图所示,

找到罪魁祸首了, 现在开始可以看下代码,如下所示:

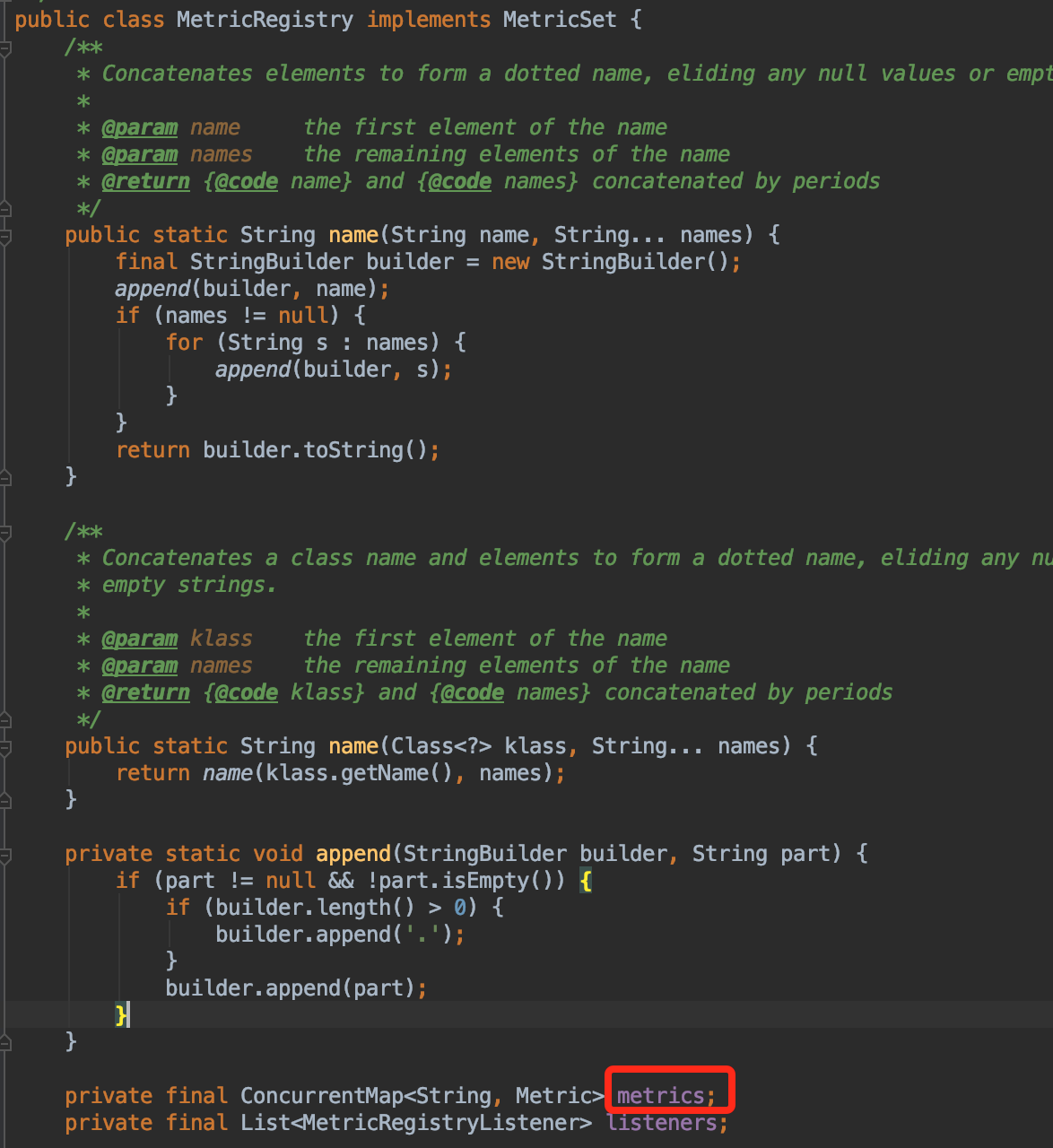
发现 TaggedMetricRegistry继承自MetricRegistry,如下图
metrics是个Map,MetricRegistry的成员变量,继续回来看mat,看内部内存占用
如下图所示,发现Map的有几个Node节点尤其大,
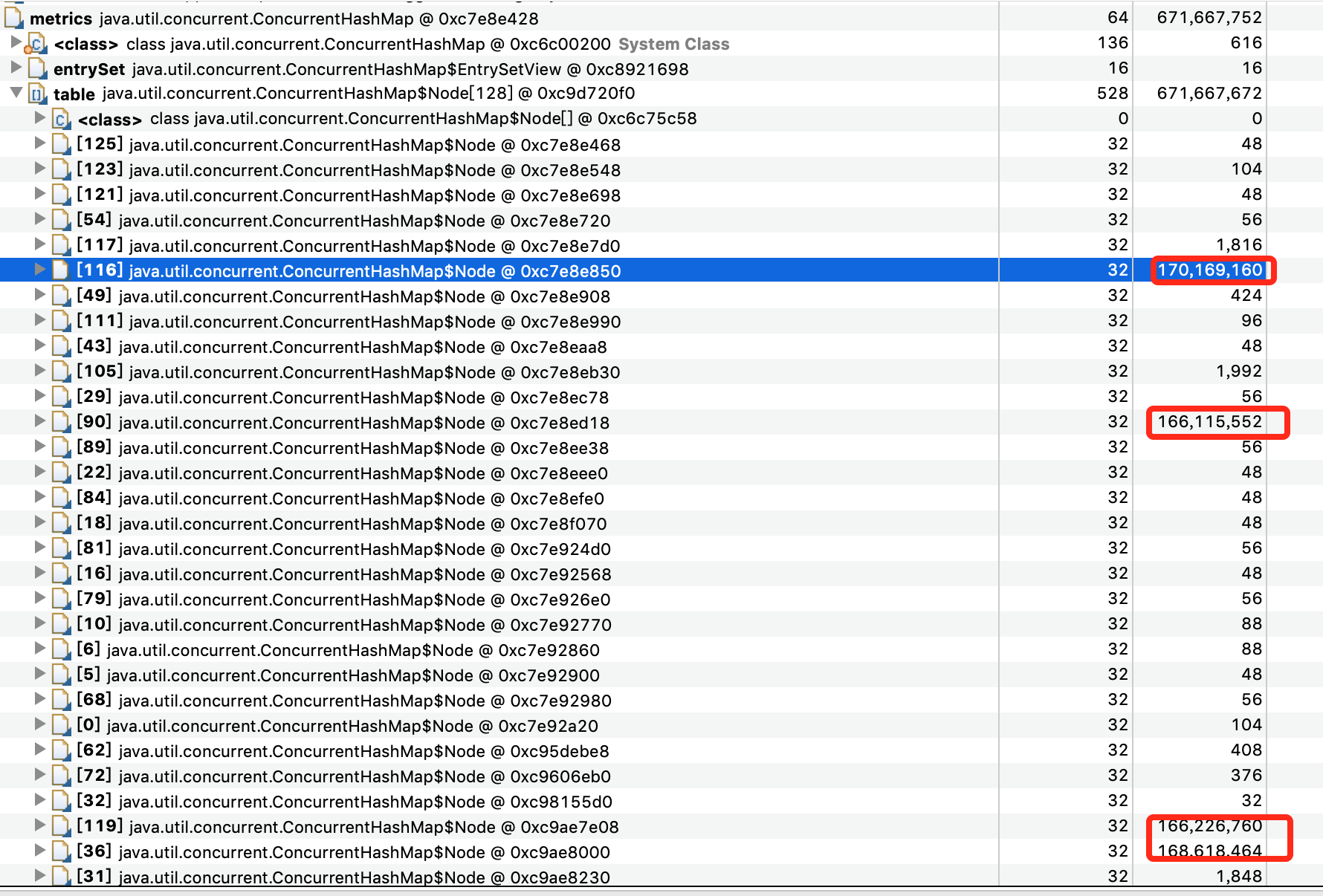
追下去,继续
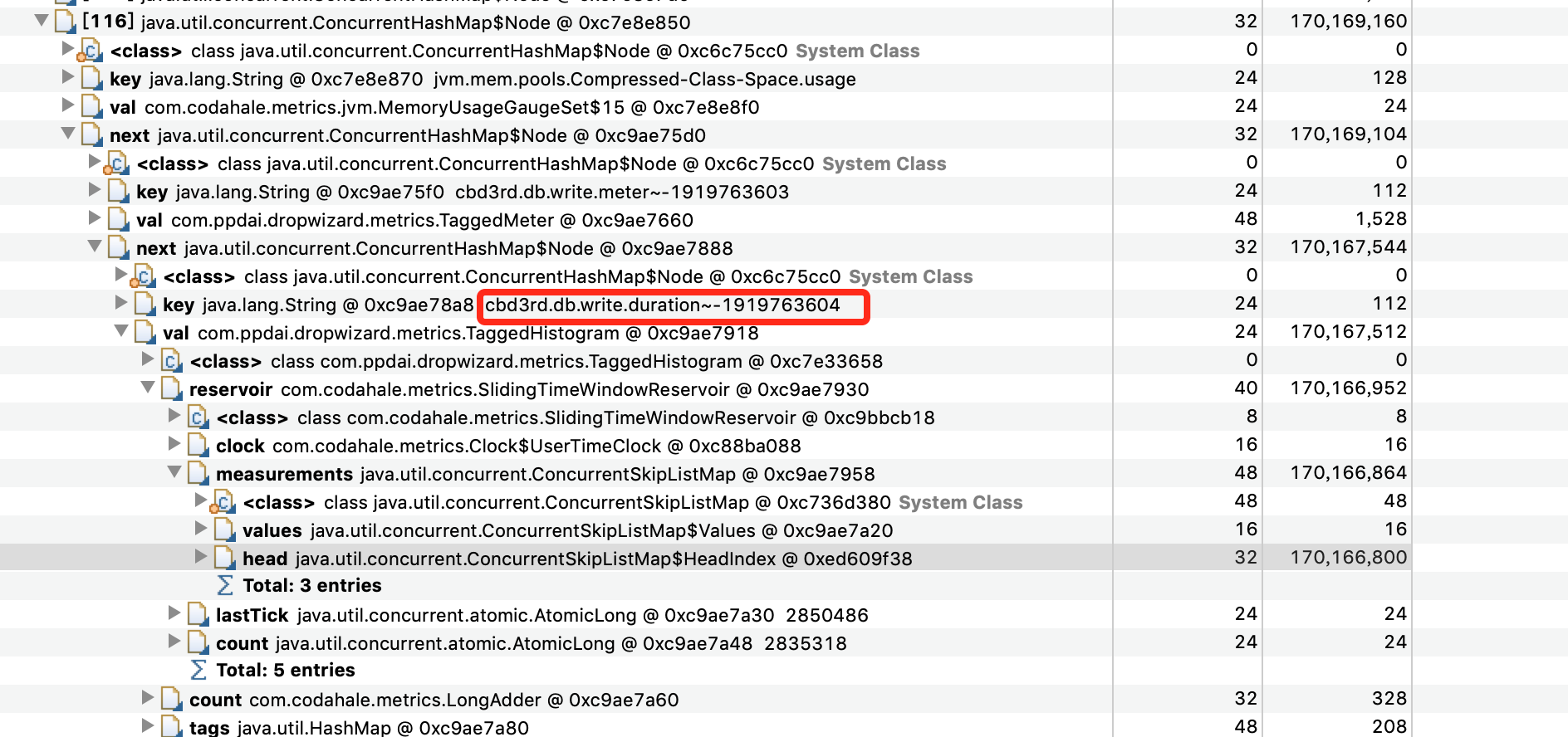
看到这个key,对应在代码中的位置,

开始代码分析,这个代码的作用是统计接口每次的执行时间,统计窗口是1分钟,问题就出现在这,因为这个函数的QPS非常高,在update的源码如下:
private final ConcurrentSkipListMap<Long, Long> measurements;
@Override public void update(long value) { if (count.incrementAndGet() % TRIM_THRESHOLD == 0) { trim(); } measurements.put(getTick(), value); }
private long getTick() {
for (; ; ) {
final long oldTick = lastTick.get();
final long tick = clock.getTick() * COLLISION_BUFFER;
// ensure the tick is strictly incrementing even if there are duplicate ticks
final long newTick = tick > oldTick ? tick : oldTick + 1;
if (lastTick.compareAndSet(oldTick, newTick)) {
return newTick;
}
}
private void trim() {
measurements.headMap(getTick() - window).clear();
}
measurements是一个跳跃表,在1分钟有数据频繁产生的时候,会导致在一个时间窗口(1分钟)measurements极速增长,导致内存快速增长,所以产生频繁Yong GC,把这个Metric统计取消,问题Fixed。
