import pandas as pd
import numpy as np
import time
import sqlite3
data_home = 'E:/python学习/项目/python推荐系统/Python实现音乐推荐系统/'
读取数据
triplet_dataset = pd.read_csv(filepath_or_buffer=data_home+'train_triplets.txt' ,
sep='\t' , header=None ,
names=['user' ,'song' ,'play_count' ])
triplet_dataset.shape
(48373586 , 3 )
triplet_dataset.info()
<class
RangeIndex: 48373586 entries, 0 to 48373585
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 user object
1 song object
2 play_count int64
dtypes: int64(1 ), object (2 )
memory usage: 1.1 + GB
triplet_dataset.head(10 )
user
song
play_count
0
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOAKIMP12A8C130995
1
1
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOAPDEY12A81C210A9
1
2
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBBMDR12A8C13253B
2
3
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBFNSP12AF72A0E22
1
4
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBFOVM12A58A7D494
1
5
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBNZDC12A6D4FC103
1
6
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBSUJE12A6D4F8CF5
2
7
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBVFZR12A6D4F8AE3
1
8
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBXALG12A8C13C108
1
9
b80344d063b5ccb3212f76538f3d9e43d87dca9e
SOBXHDL12A81C204C0
1
对每一个用户,分别统计他的播放总量
output_dict = {}
with open (data_home+'train_triplets.txt' ) as f:
for line_number, line in enumerate (f):
user = line.split('\t' )[0 ]
play_count = int (line.split('\t' )[2 ])
if user in output_dict:
play_count +=output_dict[user]
output_dict.update({user:play_count})
output_dict.update({user:play_count})
output_list = [{'user' :k,'play_count' :v} for k,v in output_dict.items()]
play_count_df = pd.DataFrame(output_list)
play_count_df = play_count_df.sort_values(by = 'play_count' , ascending = False )
play_count_df.to_csv(path_or_buf='user_playcount_df.csv' , index = False )
对于每一首歌,分别统计它的播放总量
output_dict = {}
with open (data_home+'train_triplets.txt' ) as f:
for line_number, line in enumerate (f):
song = line.split('\t' )[1 ]
play_count = int (line.split('\t' )[2 ])
if song in output_dict:
play_count +=output_dict[song]
output_dict.update({song:play_count})
output_dict.update({song:play_count})
output_list = [{'song' :k,'play_count' :v} for k,v in output_dict.items()]
song_count_df = pd.DataFrame(output_list)
song_count_df = song_count_df.sort_values(by = 'play_count' , ascending = False )
song_count_df.to_csv(path_or_buf='song_playcount_df.csv' , index = False )
看看目前的排行情况
play_count_df = pd.read_csv(filepath_or_buffer='user_playcount_df.csv' )
play_count_df.head(n =10 )
user
play_count
0
093cb74eb3c517c5179ae24caf0ebec51b24d2a2
13132
1
119b7c88d58d0c6eb051365c103da5caf817bea6
9884
2
3fa44653315697f42410a30cb766a4eb102080bb
8210
3
a2679496cd0af9779a92a13ff7c6af5c81ea8c7b
7015
4
d7d2d888ae04d16e994d6964214a1de81392ee04
6494
5
4ae01afa8f2430ea0704d502bc7b57fb52164882
6472
6
b7c24f770be6b802805ac0e2106624a517643c17
6150
7
113255a012b2affeab62607563d03fbdf31b08e7
5656
8
6d625c6557df84b60d90426c0116138b617b9449
5620
9
99ac3d883681e21ea68071019dba828ce76fe94d
5602
song_count_df = pd.read_csv(filepath_or_buffer='song_playcount_df.csv' )
song_count_df.head(10 )
song
play_count
0
SOBONKR12A58A7A7E0
726885
1
SOAUWYT12A81C206F1
648239
2
SOSXLTC12AF72A7F54
527893
3
SOFRQTD12A81C233C0
425463
4
SOEGIYH12A6D4FC0E3
389880
5
SOAXGDH12A8C13F8A1
356533
6
SONYKOW12AB01849C9
292642
7
SOPUCYA12A8C13A694
274627
8
SOUFTBI12AB0183F65
268353
9
SOVDSJC12A58A7A271
244730
最受欢迎的一首歌曲有726885次播放。 刚才大家也看到了,这个音乐数据量集十分庞大,考虑到执行过程的时间消耗以及矩阵稀疏性问题,我们依据播放量指标对数据集进行了截取。因为有些注册用户可能只是关注了一下之后就不再登录平台,这些用户对我们建模不会起促进作用,反而增大了矩阵的稀疏性。对于歌曲也是同理,可能有些歌曲根本无人问津。由于之前已经对用户与歌曲播放情况进行了排序,所以我们分别选择了其中的10W名用户和3W首歌曲,关于截取的合适比例大家也可以通过观察选择数据的播放量占总体的比例来设置。
取其中一部分数(按大小排好序的了,这些应该是比较重要的数据),作为我们的实验数据
total_play_count = sum (song_count_df.play_count)
print ((float (play_count_df.head(n=100000 ).play_count.sum ())/total_play_count)*100 )
play_count_subset = play_count_df.head(n=100000 )
40.8807280500655
(float (song_count_df.head(n=30000 ).play_count.sum ())/total_play_count)*100
78.39315366645269
song_count_subset = song_count_df.head(n=30000 )
取10W个用户,3W首歌
user_subset = list (play_count_subset.user)
song_subset = list (song_count_subset.song)
过滤掉其他用户数据
triplet_dataset = pd.read_csv(filepath_or_buffer=data_home+'train_triplets.txt' ,sep='\t' ,
header=None , names=['user' ,'song' ,'play_count' ])
triplet_dataset_sub = triplet_dataset[triplet_dataset.user.isin(user_subset) ]
del (triplet_dataset)
triplet_dataset_sub_song = triplet_dataset_sub[triplet_dataset_sub.song.isin(song_subset)]
del (triplet_dataset_sub)
triplet_dataset_sub_song.to_csv(path_or_buf=data_home+'triplet_dataset_sub_song.csv' , index=False )
triplet_dataset_sub_song.shape
(10774558 , 3 )
数据样本个数此时只有原来的1/4不到,但是我们过滤掉的样本都是稀疏数据不利于建模,所以当拿到了数据之后对数据进行清洗和预处理工作还是非常有必要的,不单单提升计算的速度,还会影响最终的结果。
triplet_dataset_sub_song.head(n=10 )
user
song
play_count
498
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOADQPP12A67020C82
12
499
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAFTRR12AF72A8D4D
1
500
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOANQFY12AB0183239
1
501
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAYATB12A6701FD50
1
502
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBOAFP12A8C131F36
7
503
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBONKR12A58A7A7E0
26
504
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBZZDU12A6310D8A3
7
505
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOCAHRT12A8C13A1A4
5
506
d6589314c0a9bcbca4fee0c93b14bc402363afea
SODASIJ12A6D4F5D89
1
507
d6589314c0a9bcbca4fee0c93b14bc402363afea
SODEAWL12AB0187032
8
加入音乐详细信息
conn = sqlite3.connect(data_home+'track_metadata.db' )
cur = conn.cursor()
cur.execute("SELECT name FROM sqlite_master WHERE type='table'" )
cur.fetchall()
[('songs' ,)]
track_metadata_df = pd.read_sql(con=conn, sql='select * from songs' )
track_metadata_df_sub = track_metadata_df[track_metadata_df.song_id.isin(song_subset)]
track_metadata_df_sub.to_csv(path_or_buf=data_home+'track_metadata_df_sub.csv' , index=False )
track_metadata_df_sub.shape
(30447 , 14 )
我们现有的数据
triplet_dataset_sub_song = pd.read_csv(filepath_or_buffer=data_home+'triplet_dataset_sub_song.csv' ,encoding = "ISO-8859-1" )
track_metadata_df_sub = pd.read_csv(filepath_or_buffer=data_home+'track_metadata_df_sub.csv' ,encoding = "ISO-8859-1" )
triplet_dataset_sub_song.head()
user
song
play_count
0
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOADQPP12A67020C82
12
1
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAFTRR12AF72A8D4D
1
2
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOANQFY12AB0183239
1
3
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAYATB12A6701FD50
1
4
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBOAFP12A8C131F36
7
track_metadata_df_sub.head()
track_id
title
song_id
release
artist_id
artist_mbid
artist_name
duration
artist_familiarity
artist_hotttnesss
year
track_7digitalid
shs_perf
shs_work
0
TRMMGCB128E079651D
Get Along (Feat: Pace Won) (Instrumental)
SOHNWIM12A67ADF7D9
Charango
ARU3C671187FB3F71B
067102ea-9519-4622-9077-57ca4164cfbb
Morcheeba
227.47383
0.819087
0.533117
2002
185967
-1
0
1
TRMMGTX128F92FB4D9
Viejo
SOECFIW12A8C144546
Caraluna
ARPAAPH1187FB3601B
f69d655c-ffd6-4bee-8c2a-3086b2be2fc6
Bacilos
307.51302
0.595554
0.400705
0
6825058
-1
0
2
TRMMGDP128F933E59A
I Say A Little Prayer
SOGWEOB12AB018A4D0
The Legendary Hi Records Albums_ Volume 3: Ful...
ARNNRN31187B9AE7B7
fb7272ba-f130-4f0a-934d-6eeea4c18c9a
Al Green
133.58975
0.779490
0.599210
1978
5211723
-1
11898
3
TRMMHBF12903CF6E59
At the Ball_ That's All
SOJGCRL12A8C144187
Best of Laurel & Hardy - The Lonesome Pine
AR1FEUF1187B9AF3E3
4a8ae4fd-ad6f-4912-851f-093f12ee3572
Laurel & Hardy
123.71546
0.438709
0.307120
0
8645877
-1
0
4
TRMMHKG12903CDB1B5
Black Gold
SOHNFBA12AB018CD1D
Total Life Forever
ARVXV1J1187FB5BF88
6a65d878-fcd0-42cf-aff9-ca1d636a8bcc
Foals
386.32444
0.842578
0.514523
2010
9007438
-1
0
清洗数据集
del (track_metadata_df_sub['track_id' ])
del (track_metadata_df_sub['artist_mbid' ])
track_metadata_df_sub = track_metadata_df_sub.drop_duplicates(['song_id' ])
triplet_dataset_sub_song_merged = pd.merge(triplet_dataset_sub_song, track_metadata_df_sub, how='left' , left_on='song' , right_on='song_id' )
triplet_dataset_sub_song_merged.rename(columns={'play_count' :'listen_count' },inplace=True )
del (triplet_dataset_sub_song_merged['song_id' ])
del (triplet_dataset_sub_song_merged['artist_id' ])
del (triplet_dataset_sub_song_merged['duration' ])
del (triplet_dataset_sub_song_merged['artist_familiarity' ])
del (triplet_dataset_sub_song_merged['artist_hotttnesss' ])
del (triplet_dataset_sub_song_merged['track_7digitalid' ])
del (triplet_dataset_sub_song_merged['shs_perf' ])
del (triplet_dataset_sub_song_merged['shs_work' ])
triplet_dataset_sub_song_merged.head(n=10 )
user
song
listen_count
title
release
artist_name
year
0
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOADQPP12A67020C82
12
You And Me Jesus
Tribute To Jake Hess
Jake Hess
2004
1
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAFTRR12AF72A8D4D
1
Harder Better Faster Stronger
Discovery
Daft Punk
2007
2
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOANQFY12AB0183239
1
Uprising
Uprising
Muse
0
3
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAYATB12A6701FD50
1
Breakfast At Tiffany's
Home
Deep Blue Something
1993
4
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBOAFP12A8C131F36
7
Lucky (Album Version)
We Sing. We Dance. We Steal Things.
Jason Mraz & Colbie Caillat
0
5
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBONKR12A58A7A7E0
26
You're The One
If There Was A Way
Dwight Yoakam
1990
6
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBZZDU12A6310D8A3
7
Don't Dream It's Over
Recurring Dream_ Best Of Crowded House (Domest...
Crowded House
1986
7
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOCAHRT12A8C13A1A4
5
S.O.S.
SOS
Jonas Brothers
2007
8
d6589314c0a9bcbca4fee0c93b14bc402363afea
SODASIJ12A6D4F5D89
1
The Invisible Man
The Invisible Man
Michael Cretu
1985
9
d6589314c0a9bcbca4fee0c93b14bc402363afea
SODEAWL12AB0187032
8
American Idiot [feat. Green Day & The Cast Of ...
The Original Broadway Cast Recording 'American...
Green Day
0
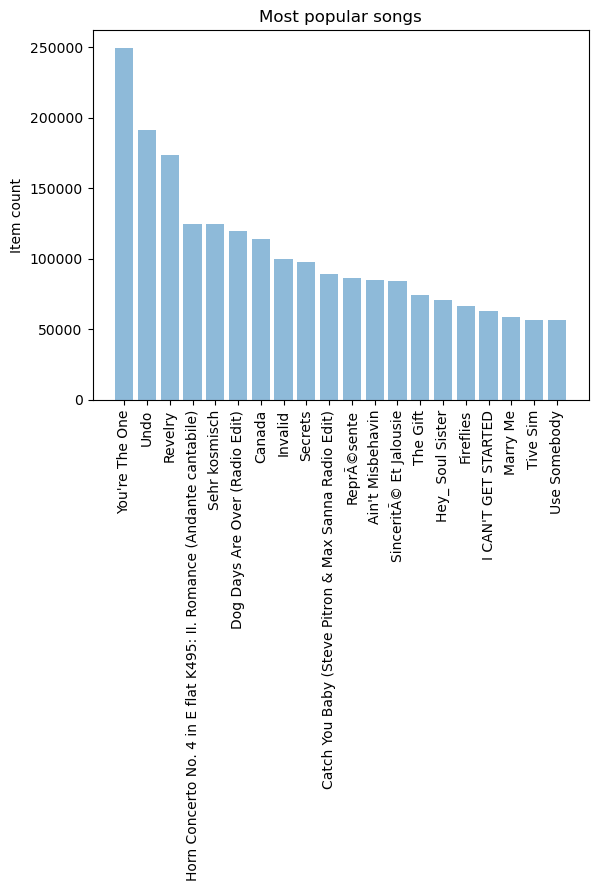
展示最流行的歌曲
import matplotlib.pyplot as plt; plt.rcdefaults()
import numpy as np
import matplotlib.pyplot as plt
popular_songs = triplet_dataset_sub_song_merged[['title' ,'listen_count' ]].groupby('title' ).sum ().reset_index()
popular_songs_top_20 = popular_songs.sort_values('listen_count' , ascending=False ).head(n=20 )
objects = (list (popular_songs_top_20['title' ]))
y_pos = np.arange(len (objects))
performance = list (popular_songs_top_20['listen_count' ])
plt.bar(y_pos, performance, align='center' , alpha=0.5 )
plt.xticks(y_pos, objects, rotation='vertical' )
plt.ylabel('Item count' )
plt.title('Most popular songs' )
plt.show()
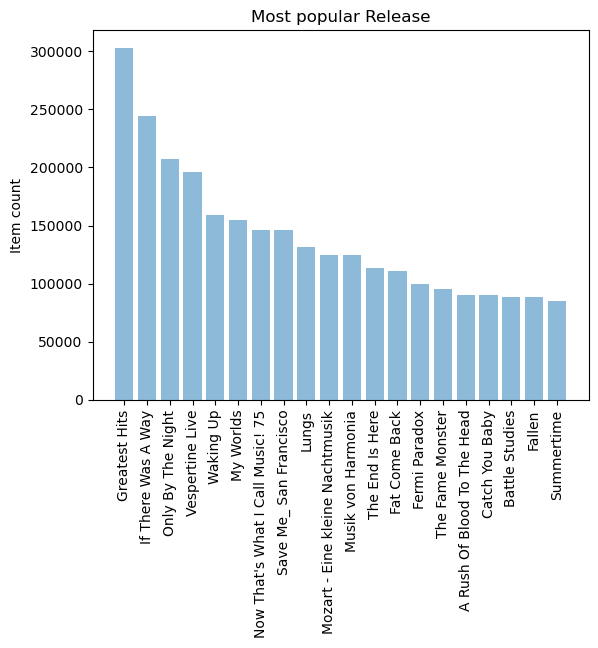
最受欢迎的releases
popular_release = triplet_dataset_sub_song_merged[['release' ,'listen_count' ]].groupby('release' ).sum ().reset_index()
popular_release_top_20 = popular_release.sort_values('listen_count' , ascending=False ).head(n=20 )
objects = (list (popular_release_top_20['release' ]))
y_pos = np.arange(len (objects))
performance = list (popular_release_top_20['listen_count' ])
plt.bar(y_pos, performance, align='center' , alpha=0.5 )
plt.xticks(y_pos, objects, rotation='vertical' )
plt.ylabel('Item count' )
plt.title('Most popular Release' )
plt.show()
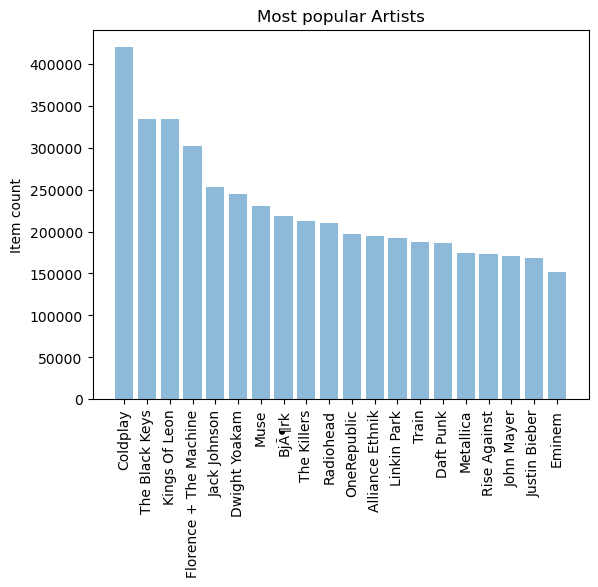
最受欢迎的歌手
popular_artist = triplet_dataset_sub_song_merged[['artist_name' ,'listen_count' ]].groupby('artist_name' ).sum ().reset_index()
popular_artist_top_20 = popular_artist.sort_values('listen_count' , ascending=False ).head(n=20 )
objects = (list (popular_artist_top_20['artist_name' ]))
y_pos = np.arange(len (objects))
performance = list (popular_artist_top_20['listen_count' ])
plt.bar(y_pos, performance, align='center' , alpha=0.5 )
plt.xticks(y_pos, objects, rotation='vertical' )
plt.ylabel('Item count' )
plt.title('Most popular Artists' )
plt.show()
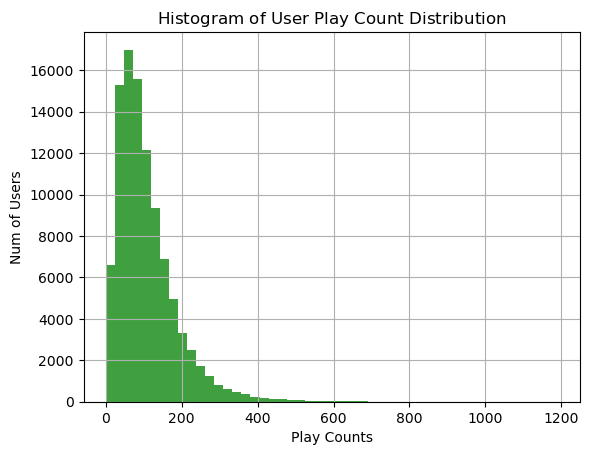
用户播放过歌曲量的分布
user_song_count_distribution = triplet_dataset_sub_song_merged[['user' ,'title' ]].groupby('user' ).count().reset_index().sort_values(
by='title' ,ascending = False )
user_song_count_distribution.title.describe()
count 99996.000000
mean 107.749890
std 79.742561
min 1.000000
25
50
75
max 1189.000000
Name: title, dtype: float64
x = user_song_count_distribution.title
n, bins, patches = plt.hist(x, 50 , facecolor='green' , alpha=0.75 )
plt.xlabel('Play Counts' )
plt.ylabel('Num of Users' )
plt.title(r'$\mathrm{Histogram\ of\ User\ Play\ Count\ Distribution}\ $' )
plt.grid(True )
plt.show()
绝大多数用户播放歌曲的数量在100左右,关于数据的处理和介绍已经给大家都分析过了,接下来我们要做的就是构建一个能实际进行推荐的程序了。
开始构建推荐系统
import Recommenders as Recommenders
from sklearn.model_selection import train_test_split
triplet_dataset_sub_song_merged_set = triplet_dataset_sub_song_merged
train_data, test_data = train_test_split(triplet_dataset_sub_song_merged_set, test_size = 0.40 , random_state=0 )
train_data.head()
user
song
listen_count
title
release
artist_name
year
1901799
28866ea8a809d5d46273cd0989c5515c660ef8c7
SOEYVHS12AB0181D31
1
Monster
The Fame Monster
Lady GaGa
2009
4815185
c9608a24a2a40e0ec38993a70532e7bb56eff22b
SOKIYKQ12A8AE464FC
2
Fight For Your Life
Made In NYC
The Casualties
2000
10513026
24f0b09c133a6a0fe42f097734215dceb468d449
SOETFVO12AB018DFF3
1
Free Style (feat. Kevo_ Mussilini & Lyrical 187)
A Bad Azz Mix Tape
Z-RO
0
2659073
4da3c59a0af73245cea000fd5efa30384182bfcb
SOAXJOU12A6D4F6685
1
Littlest Things
Alright_ Still
Lily Allen
2006
5506263
b46c5ed385cad7ecea8af6214f440d19de6eb6c2
SOXBCAY12AB0189EE0
1
La trama y el desenlace
Amar la trama
Jorge Drexler
2010
def create_popularity_recommendation (train_data, user_id, item_id ):
train_data_grouped = train_data.groupby([item_id]).agg({user_id: 'count' }).reset_index()
train_data_grouped.rename(columns = {user_id: 'score' },inplace=True )
train_data_sort = train_data_grouped.sort_values(['score' , item_id], ascending = [0 ,1 ])
train_data_sort['Rank' ] = train_data_sort['score' ].rank(ascending=0 , method='first' )
popularity_recommendations = train_data_sort.head(20 )
return popularity_recommendations
recommendations = create_popularity_recommendation(triplet_dataset_sub_song_merged,'user' ,'title' )
recommendations
title
score
Rank
19580
Sehr kosmisch
18626
1.0
5780
Dog Days Are Over (Radio Edit)
17635
2.0
27314
You're The One
16085
3.0
19542
Secrets
15138
4.0
18636
Revelry
14945
5.0
25070
Undo
14687
6.0
7530
Fireflies
13085
7.0
9640
Hey_ Soul Sister
12993
8.0
25216
Use Somebody
12793
9.0
9921
Horn Concerto No. 4 in E flat K495: II. Romanc...
12346
10.0
24291
Tive Sim
11831
11.0
3629
Canada
11598
12.0
23468
The Scientist
11529
13.0
4194
Clocks
11357
14.0
12135
Just Dance
11058
15.0
26974
Yellow
10919
16.0
16438
OMG
10818
17.0
9844
Home
10512
18.0
3295
Bulletproof
10383
19.0
4760
Creep (Explicit)
10246
20.0
基于歌曲相似度的推荐
song_count_subset = song_count_df.head(n=5000 )
user_subset = list (play_count_subset.user)
song_subset = list (song_count_subset.song)
triplet_dataset_sub_song_merged_sub = triplet_dataset_sub_song_merged[triplet_dataset_sub_song_merged.song.isin(song_subset)]
triplet_dataset_sub_song_merged_sub.head()
user
song
listen_count
title
release
artist_name
year
0
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOADQPP12A67020C82
12
You And Me Jesus
Tribute To Jake Hess
Jake Hess
2004
1
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAFTRR12AF72A8D4D
1
Harder Better Faster Stronger
Discovery
Daft Punk
2007
2
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOANQFY12AB0183239
1
Uprising
Uprising
Muse
0
3
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAYATB12A6701FD50
1
Breakfast At Tiffany's
Home
Deep Blue Something
1993
4
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBOAFP12A8C131F36
7
Lucky (Album Version)
We Sing. We Dance. We Steal Things.
Jason Mraz & Colbie Caillat
0
计算相似度得到推荐结果
import Recommenders as Recommenders
train_data, test_data = train_test_split(triplet_dataset_sub_song_merged_sub, test_size = 0.30 , random_state=0 )
is_model = Recommenders.item_similarity_recommender_py()
is_model.create(train_data, 'user' , 'title' )
user_id = list (train_data.user)[7 ]
user_items = is_model.get_user_items(user_id)
is_model.recommend(user_id)
No. of unique songs for the user : 66
no. of unique songs in the training set : 4879
Non zero values in cooccurence_matrix :290327
user_id
song
score
rank
0
a974fc428825ed071281302d6976f59bfa95fe7e
Put Your Head On My Shoulder (Album Version)
0.026334
1
1
a974fc428825ed071281302d6976f59bfa95fe7e
The Strength To Go On
0.025176
2
2
a974fc428825ed071281302d6976f59bfa95fe7e
Come Fly With Me (Album Version)
0.024447
3
3
a974fc428825ed071281302d6976f59bfa95fe7e
Moondance (Album Version)
0.024118
4
4
a974fc428825ed071281302d6976f59bfa95fe7e
Kotov Syndrome
0.023311
5
5
a974fc428825ed071281302d6976f59bfa95fe7e
Use Somebody
0.023104
6
6
a974fc428825ed071281302d6976f59bfa95fe7e
Lucky (Album Version)
0.022930
7
7
a974fc428825ed071281302d6976f59bfa95fe7e
Secrets
0.022889
8
8
a974fc428825ed071281302d6976f59bfa95fe7e
Clocks
0.022562
9
9
a974fc428825ed071281302d6976f59bfa95fe7e
Sway (Album Version)
0.022359
10
基于矩阵分解(SVD)的推荐
triplet_dataset_sub_song_merged_sum_df = triplet_dataset_sub_song_merged[['user' ,'listen_count' ]].groupby('user' ).sum ().reset_index()
triplet_dataset_sub_song_merged_sum_df.rename(columns={'listen_count' :'total_listen_count' },inplace=True )
triplet_dataset_sub_song_merged = pd.merge(triplet_dataset_sub_song_merged,triplet_dataset_sub_song_merged_sum_df)
triplet_dataset_sub_song_merged.head()
user
song
listen_count
title
release
artist_name
year
total_listen_count
0
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOADQPP12A67020C82
12
You And Me Jesus
Tribute To Jake Hess
Jake Hess
2004
329
1
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAFTRR12AF72A8D4D
1
Harder Better Faster Stronger
Discovery
Daft Punk
2007
329
2
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOANQFY12AB0183239
1
Uprising
Uprising
Muse
0
329
3
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAYATB12A6701FD50
1
Breakfast At Tiffany's
Home
Deep Blue Something
1993
329
4
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBOAFP12A8C131F36
7
Lucky (Album Version)
We Sing. We Dance. We Steal Things.
Jason Mraz & Colbie Caillat
0
329
triplet_dataset_sub_song_merged['fractional_play_count' ] = triplet_dataset_sub_song_merged['listen_count' ]/triplet_dataset_sub_song_merged['total_listen_count' ]
triplet_dataset_sub_song_merged[triplet_dataset_sub_song_merged.user =='d6589314c0a9bcbca4fee0c93b14bc402363afea' ][['user' ,'song' ,'listen_count' ,'fractional_play_count' ]].head()
user
song
listen_count
fractional_play_count
0
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOADQPP12A67020C82
12
0.036474
1
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAFTRR12AF72A8D4D
1
0.003040
2
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOANQFY12AB0183239
1
0.003040
3
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOAYATB12A6701FD50
1
0.003040
4
d6589314c0a9bcbca4fee0c93b14bc402363afea
SOBOAFP12A8C131F36
7
0.021277
from scipy.sparse import coo_matrix
small_set = triplet_dataset_sub_song_merged
user_codes = small_set.user.drop_duplicates().reset_index()
song_codes = small_set.song.drop_duplicates().reset_index()
user_codes.rename(columns={'index' :'user_index' }, inplace=True )
song_codes.rename(columns={'index' :'song_index' }, inplace=True )
song_codes['so_index_value' ] = list (song_codes.index)
user_codes['us_index_value' ] = list (user_codes.index)
small_set = pd.merge(small_set,song_codes,how='left' )
small_set = pd.merge(small_set,user_codes,how='left' )
mat_candidate = small_set[['us_index_value' ,'so_index_value' ,'fractional_play_count' ]]
data_array = mat_candidate.fractional_play_count.values
row_array = mat_candidate.us_index_value.values
col_array = mat_candidate.so_index_value.values
data_sparse = coo_matrix((data_array, (row_array, col_array)),dtype=float )
data_sparse
<99996x30000 sparse matrix of type '<class ' numpy.float64'>'
with 10774558 stored elements in COOrdinate format >
user_codes[user_codes.user =='2a2f776cbac6df64d6cb505e7e834e01684673b6' ]
user_index
user
us_index_value
27516
2981434
2a2f776cbac6df64d6cb505e7e834e01684673b6
27516
使用SVD方法来进行矩阵分解
import math as mt
from scipy.sparse.linalg import *
from scipy.sparse.linalg import svds
from scipy.sparse import csc_matrix
def compute_svd (urm, K ):
U, s, Vt = svds(urm, K)
dim = (len (s), len (s))
S = np.zeros(dim, dtype=np.float32)
for i in range (0 , len (s)):
S[i,i] = mt.sqrt(s[i])
U = csc_matrix(U, dtype=np.float32)
S = csc_matrix(S, dtype=np.float32)
Vt = csc_matrix(Vt, dtype=np.float32)
return U, S, Vt
def compute_estimated_matrix (urm, U, S, Vt, uTest, K, test ):
rightTerm = S*Vt
max_recommendation = 250
estimatedRatings = np.zeros(shape=(MAX_UID, MAX_PID), dtype=np.float16)
recomendRatings = np.zeros(shape=(MAX_UID,max_recommendation ), dtype=np.float16)
for userTest in uTest:
prod = U[userTest, :]*rightTerm
estimatedRatings[userTest, :] = prod.todense()
recomendRatings[userTest, :] = (-estimatedRatings[userTest, :]).argsort()[:max_recommendation]
return recomendRatings
K=50
urm = data_sparse
MAX_PID = urm.shape[1 ]
MAX_UID = urm.shape[0 ]
U, S, Vt = compute_svd(urm, K)
uTest = [4 ,5 ,6 ,7 ,8 ,873 ,23 ]
uTest_recommended_items = compute_estimated_matrix(urm, U, S, Vt, uTest, K, True )
for user in uTest:
print ("当前待推荐用户编号 {}" . format (user))
rank_value = 1
for i in uTest_recommended_items[user,0 :10 ]:
song_details = small_set[small_set.so_index_value == i].drop_duplicates('so_index_value' )[['title' ,'artist_name' ]]
print ("推荐编号: {} 推荐歌曲: {} 作者: {}" .format (rank_value, list (song_details['title' ])[0 ],list (song_details['artist_name' ])[0 ]))
rank_value+=1
当前待推荐用户编号 4
推荐编号: 1 推荐歌曲: Fireflies 作者: Charttraxx Karaoke
推荐编号: 2 推荐歌曲: Hey_ Soul Sister 作者: Train
推荐编号: 3 推荐歌曲: OMG 作者: Usher featuring will.i.am
推荐编号: 4 推荐歌曲: Lucky (Album Version) 作者: Jason Mraz & Colbie Caillat
推荐编号: 5 推荐歌曲: Vanilla Twilight 作者: Owl City
推荐编号: 6 推荐歌曲: Crumpshit 作者: Philippe Rochard
推荐编号: 7 推荐歌曲: Billionaire [feat. Bruno Mars] (Explicit Album Version) 作者: Travie McCoy
推荐编号: 8 推荐歌曲: Love Story 作者: Taylor Swift
推荐编号: 9 推荐歌曲: TULENLIEKKI 作者: M.A. Numminen
推荐编号: 10 推荐歌曲: Use Somebody 作者: Kings Of Leon
当前待推荐用户编号 5
推荐编号: 1 推荐歌曲: Sehr kosmisch 作者: Harmonia
推荐编号: 2 推荐歌曲: Ain
推荐编号: 3 推荐歌曲: Dog Days Are Over (Radio Edit) 作者: Florence + The Machine
推荐编号: 4 推荐歌曲: Revelry 作者: Kings Of Leon
推荐编号: 5 推荐歌曲: Undo 作者: Björk
推荐编号: 6 推荐歌曲: Cosmic Love 作者: Florence + The Machine
推荐编号: 7 推荐歌曲: Home 作者: Edward Sharpe & The Magnetic Zeros
推荐编号: 8 推荐歌曲: You
推荐编号: 9 推荐歌曲: Bring Me To Life 作者: Evanescence
推荐编号: 10 推荐歌曲: Tighten Up 作者: The Black Keys
当前待推荐用户编号 6
推荐编号: 1 推荐歌曲: Crumpshit 作者: Philippe Rochard
推荐编号: 2 推荐歌曲: Marry Me 作者: Train
推荐编号: 3 推荐歌曲: Hey_ Soul Sister 作者: Train
推荐编号: 4 推荐歌曲: Lucky (Album Version) 作者: Jason Mraz & Colbie Caillat
推荐编号: 5 推荐歌曲: One On One 作者: the bird and the bee
推荐编号: 6 推荐歌曲: I Never Told You 作者: Colbie Caillat
推荐编号: 7 推荐歌曲: Canada 作者: Five Iron Frenzy
推荐编号: 8 推荐歌曲: Fireflies 作者: Charttraxx Karaoke
推荐编号: 9 推荐歌曲: TULENLIEKKI 作者: M.A. Numminen
推荐编号: 10 推荐歌曲: Bring Me To Life 作者: Evanescence
当前待推荐用户编号 7
推荐编号: 1 推荐歌曲: Behind The Sea [Live In Chicago] 作者: Panic At The Disco
推荐编号: 2 推荐歌曲: The City Is At War (Album Version) 作者: Cobra Starship
推荐编号: 3 推荐歌曲: Dead Souls 作者: Nine Inch Nails
推荐编号: 4 推荐歌曲: Una Confusion 作者: LU
推荐编号: 5 推荐歌曲: Home 作者: Edward Sharpe & The Magnetic Zeros
推荐编号: 6 推荐歌曲: Climbing Up The Walls 作者: Radiohead
推荐编号: 7 推荐歌曲: Tighten Up 作者: The Black Keys
推荐编号: 8 推荐歌曲: Tive Sim 作者: Cartola
推荐编号: 9 推荐歌曲: West One (Shine On Me ) 作者: The Ruts
推荐编号: 10 推荐歌曲: Cosmic Love 作者: Florence + The Machine
当前待推荐用户编号 8
推荐编号: 1 推荐歌曲: Undo 作者: Björk
推荐编号: 2 推荐歌曲: Canada 作者: Five Iron Frenzy
推荐编号: 3 推荐歌曲: Better To Reign In Hell 作者: Cradle Of Filth
推荐编号: 4 推荐歌曲: Unite (2009 Digital Remaster) 作者: Beastie Boys
推荐编号: 5 推荐歌曲: Behind The Sea [Live In Chicago] 作者: Panic At The Disco
推荐编号: 6 推荐歌曲: Rockin
推荐编号: 7 推荐歌曲: Devil
推荐编号: 8 推荐歌曲: Revelry 作者: Kings Of Leon
推荐编号: 9 推荐歌曲: 16 Candles 作者: The Crests
推荐编号: 10 推荐歌曲: Catch You Baby (Steve Pitron & Max Sanna Radio Edit) 作者: Lonnie Gordon
当前待推荐用户编号 873
推荐编号: 1 推荐歌曲: The Scientist 作者: Coldplay
推荐编号: 2 推荐歌曲: Yellow 作者: Coldplay
推荐编号: 3 推荐歌曲: Clocks 作者: Coldplay
推荐编号: 4 推荐歌曲: Fix You 作者: Coldplay
推荐编号: 5 推荐歌曲: In My Place 作者: Coldplay
推荐编号: 6 推荐歌曲: Shiver 作者: Coldplay
推荐编号: 7 推荐歌曲: Speed Of Sound 作者: Coldplay
推荐编号: 8 推荐歌曲: Creep (Explicit ) 作者: Radiohead
推荐编号: 9 推荐歌曲: Sparks 作者: Coldplay
推荐编号: 10 推荐歌曲: Use Somebody 作者: Kings Of Leon
当前待推荐用户编号 23
推荐编号: 1 推荐歌曲: Garden Of Eden 作者: Guns N
推荐编号: 2 推荐歌曲: Don
推荐编号: 3 推荐歌曲: Master Of Puppets 作者: Metallica
推荐编号: 4 推荐歌曲: TULENLIEKKI 作者: M.A. Numminen
推荐编号: 5 推荐歌曲: Bring Me To Life 作者: Evanescence
推荐编号: 6 推荐歌曲: Kryptonite 作者: 3 Doors Down
推荐编号: 7 推荐歌曲: Make Her Say 作者: Kid Cudi / Kanye West / Common
推荐编号: 8 推荐歌曲: Night Village 作者: Deep Forest
推荐编号: 9 推荐歌曲: Better To Reign In Hell 作者: Cradle Of Filth
推荐编号: 10 推荐歌曲: Xanadu 作者: Olivia Newton-John;Electric Light Orchestra
uTest = [27513 ]
print ("Predictied ratings:" )
uTest_recommended_items = compute_estimated_matrix(urm, U, S, Vt, uTest, K, True )
Predictied ratings:
for user in uTest:
print ("当前待推荐用户编号 {}" . format (user))
rank_value = 1
for i in uTest_recommended_items[user,0 :10 ]:
song_details = small_set[small_set.so_index_value == i].drop_duplicates('so_index_value' )[['title' ,'artist_name' ]]
print ("推荐编号: {} 推荐歌曲: {} 作者: {}" .format (rank_value, list (song_details['title' ])[0 ],list (song_details['artist_name' ])[0 ]))
rank_value+=1
当前待推荐用户编号 27513
推荐编号: 1 推荐歌曲: Master Of Puppets 作者: Metallica
推荐编号: 2 推荐歌曲: Garden Of Eden 作者: Guns N
推荐编号: 3 推荐歌曲: Bring Me To Life 作者: Evanescence
推荐编号: 4 推荐歌曲: Kryptonite 作者: 3 Doors Down
推荐编号: 5 推荐歌曲: Make Her Say 作者: Kid Cudi / Kanye West / Common
推荐编号: 6 推荐歌曲: Night Village 作者: Deep Forest
推荐编号: 7 推荐歌曲: Savior 作者: Rise Against
推荐编号: 8 推荐歌曲: Good Things 作者: Rich Boy / Polow Da Don / Keri Hilson
推荐编号: 9 推荐歌曲: Bleed It Out [Live At Milton Keynes] 作者: Linkin Park
推荐编号: 10 推荐歌曲: Uprising 作者: Muse



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)