shell基础
18 Linux-shell基础
18.1 Shell概述
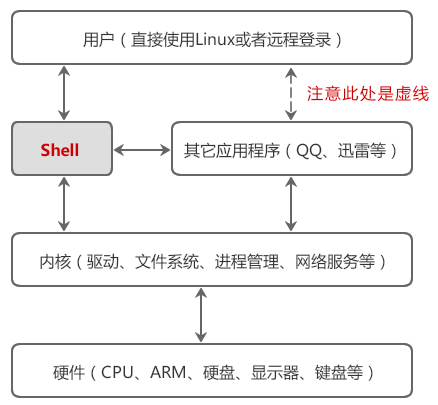
18.1.1 什么是Shell
现在我们使用的操作系统(Windows、Mac OS、Android、iOS 等)都是带图形界面的,简单直观,容易上手,对专业用户(程序员、网管等)和普通用户(家庭主妇、老年人等)都非常适用;计算机的普及离不开图形界面。
然而在计算机的早期并没有图形界面,我们只能通过一个一个地命令来控制计算机,这些命令有成百上千之多,且不说记住这些命令非常困难,每天面对没有任何色彩的“黑屏”本身就是一件枯燥的事情;这个时候的计算机还远远谈不上炫酷和普及,只有专业人员才能使用。
对于图形界面,用户点击某个图标就能启动某个程序;对于命令行,用户输入某个程序的名字(可以看做一个命令)就能启动某个程序。这两者的基本过程都是类似的,都需要查找程序在硬盘上的安装位置,然后将它们加载到内存运行。
然而,真正能够控制计算机硬件(CPU、内存、显示器等)的只有操作系统内核(Kernel),图形界面和命令行只是架设在用户和内核之间的一座桥梁。
由于安全、复杂、繁琐等原因,用户不能直接接触内核(也没有必要),需要另外再开发一个程序,让用户直接使用这个程序;该程序的作用就是接收用户的操作(点击图标、输入命令),并进行简单的处理,然后再传递给内核,这样用户就能间接地使用操作系统内核了。你看,在用户和内核之间增加一层“代理”,既能简化用户的操作,又能保障内核的安全,何乐不为呢?
用户界面和命令行就是这个另外开发的程序,就是这层“代理”。在Linux下,这个命令行程序叫做 Shell。
18.1.2 shell的分类
| Shell类别 | 易学性 | 可移植性 | 编辑性 | 快捷性 |
|---|---|---|---|---|
| Bourne Shell (sh) | 容易 | 好 | 较差 | 较差 |
| Korn Shell (ksh) | 较难 | 较好 | 好 | 较好 |
| Bourne Again (Bash) | 难 | 较好 | 好 | 好 |
| POSIX Shell (psh) | 较难 | 好 | 好 | 较好 |
| C Shell (csh) | 较难 | 差 | 较好 | 较好 |
| TC Shell (tcsh) | 难 | 差 | 好 | 好 |
Shell的两种主要语法类型有Bourne和C,这两种语法彼此不兼容。Bourne家族主要包括sh、ksh、Bash、psh、zsh;C家族主要包括:csh、tcsh (Bash和zsh在不同程度上支持csh 的语法)。
可以通过/etc/shells文件来查询Linux支持的Shell。命令如下:
[root@localhost ~]# vim /etc/shells
/bin/sh
/bin/Bash
/sbin/nologin
/bin/tcsh
/bin/csh
18.2 Shell脚本的执行方式
18.2.1 echo命令
[root@localhost ~]# echo [选项] [输出内容]
选项:
-e: 支持反斜线控制的字符转
-n: 取消输出后行末的换行符号(就是内容输出后不换行)
示例:
例1:
[root@localhost ~]# echo "Mr. Shen Chao is the most honest man!"
#echo的内容就会打印到屏幕上。
Mr. Shen Chao is the most honest man!
[root@localhost ~]#
例2:
[root@localhost ~]# echo -n "Mr. Shen Chao is the most honest man!"
Mr. Shen Chao is the most honest man![root@localhost ~]#
#如果加入了“-n”选项,输出内容结束后,不会换行直接显示新行的提示符。
在echo命令中如果使用了“-e”选项,则可以支持控制字符,如表所示:
| 控制字符 | 作用 |
|---|---|
| \ | 输出\本身 |
| \a | 输出警告音 |
| \b | 退格键,也就是向左删除键 |
| \c | 取消输出行末的换行符。和“-n”选项一致 |
| \e | ESCAPE键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车键 |
| \t | 制表符,也就是Tab键 |
| \v | 垂直制表符 |
| \0nnn | 按照八进制ASCII码表输出字符。其中0为数字零,nnn是三位八进制数 |
| \xhh | 按照十六进制ASCII码表输出字符。其中hh是两位十六进制数 |
例3:
[root@localhost ~]# echo -e "\\ \a"
\
#这个输出会输出\,同时会在系统音响中输出一声提示音
例4:
[root@localhost ~]# echo -e "ab\bc"
ac
#这个输出中,在b键左侧有“\b”,所以输出时只有ac
例5:
[root@localhost ~]# echo -e "a\tb\tc\nd\te\tf"
a b c
d e f
#我们加入了制表符“\t”和换行符“\n”,所以会按照格式输出
例6:
[root@localhost ~]# echo -e "\0141\t\0142\t\0143\n\0144\t\0145\t\0146"
a b c
d e f
#还是会输出上面的内容,不过是按照八进制ASCII码输出的。
也就是说141这个八进制,在ASCII码中代表小写的“a”,其他的以此类推。
例7:
[root@localhost ~]# echo -e "\x61\t\x62\t\x63\n\x64\t\x65\t\x66"
a b c
d e f
#如果按照十六进制ASCII码也同样可以输出
echo命令还可以进行一些比较有意思的东西,比如:
例8:
[root@localhost ~]# echo -e "\e[1;31m abcd \e[0m"
这条命令会把abcd按照红色输出。解释下这个命令\e[1是标准格式,代表颜色输出开始,\e[0m代表颜色输出结束,31m定义字体颜色是红色。echo能够识别的颜色如下:
30m=黑色,31m=红色,32m=绿色,33m=黄色,34m=蓝色,35m=洋红,36m=青色,37m=白色。
例9:
[root@localhost ~]# echo -e "\e[1;42m abcd \e[0m"
这条命令会给abcd加入一个绿色的背景。echo可以使用的背景颜色如下:
40m=黑色,41m=红色,42m=绿色,43m=黄色,44m=蓝色,45m=洋红,46m=青色,47m=白色。
18.2.2 Shell脚本的执行
[root@localhost sh]# vi hello.sh
#!/bin/Bash
#The first program
# Author: shenchao (E-mail: shenchao@atguigu.com)
echo -e "Mr. Shen Chao is the most honest man. "
Shell脚本写好了,那么这个脚本该如何运行呢?在Linux中脚本的执行主要有这样两种种方法:
-
赋予执行权限,直接运行
这种方法是最常用的Shell脚本运行方法,也最为直接简单。就是赋予执行权限之后,直接运行。当然运行时可以使用绝对路径,也可以使用相对路径运行。命令如下:
[root@localhost sh]# chmod 755 hello.sh #赋予执行权限 [root@localhost sh]# /root/sh/hello.sh Mr. Shen Chao is the most honest man. #使用绝对路径运行 [root@localhost sh]# ./hello.sh Mr. Shen Chao is the most honest man. #因为我们已经在/root/sh目录当中,所以也可以使用相对路径运行 -
通过Bash调用执行脚本
[root@localhost sh]# bash hello.sh Mr. Shen Chao is the most honest man.
18.3 Bash的基本功能
18.3.1 历史命令
1)历史命令的查看
[root@localhost ~]# history [选项] [历史命令保存文件]
选项:
-c: 清空历史命令
-w: 把缓存中的历史命令写入历史命令保存文件。如果不手工指定历史命令保存文件,则放入默认历史命令保存文件~/.bash_history中
# 修改历史命令输出的记录数
[root@localhost ~]# vi /etc/profile
…省略部分输出…
HISTSIZE=1000
…省略部分输出…
# 这是history 只会保存1000条
使用history命令查看的历史命令和/.bash_history文件中保存的历史命令是不同的。那是因为当前登录操作的命令并没有直接写入/.bash_history文件,而是保存在缓存当中的。需要等当前用户注销之后,缓存中的命令才会写入~/.bash_history文件。
如果需要把内存中的命令直接写入~/.bash_history文件,而不等用户注销时再写入,就需要使用“-w”选项了。命令如下:
[root@localhost ~]# history -w
#把缓存中的历史命令直接写入~/.bash_history
这时再去查询~/.bash_history文件,历史命令就和history命令查询的一致了。 如果需要清空历史命令,只需要执行:
[root@localhost ~]# history -c
#清空历史命令
2)历史命令的调用
如果想要使用原先的历史命令有这样几种方法:
- 使用上、下箭头调用以前的历史命令
- 使用“!n”重复执行第n条历史命令
- 使用“!!”重复执行上一条命令
- 使用“!字串”重复执行最后一条以该字串开头的命令
- 使用“!$”重复上一条命令的最后一个参数
18.3.2 命令与文件的补全
输入命令或文件名前几位后,使用tab键可以将其补全
18.3.3 命令别名
命令格式:
[root@localhost ~]# alias
#查询命令别名
[root@localhost ~]# alias 别名='原命令'
示例:
[root@localhost ~]# alias
#查询系统中已经定义好的别名
alias cp='cp -i'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
[root@localhost ~]# alias vi='vim'
#定义vim命令的别名是vi
既然说别名的优先级比命令高,那么命令执行时具体的顺序是什么呢?命令执行时的顺序是这样的:
-
第一顺位执行用绝对路径或相对路径执行的命令。
-
第二顺位执行别名。
-
第三顺位执行Bash的内部命令。
-
第四顺位执行按照$PATH环境变量定义的目录查找顺序找到的第一个命令。
为了让这个别名永久生效,可以把别名写入环境变量配置文件“~/.bashrc”。命令如下:
[root@localhost ~]# vi /root/.bashrc
18.3.4 Bash常用快捷键
| 快捷键 | 作用 |
|---|---|
| ctrl+A | 把光标移动到命令行开头。如果我们输入的命令过长,想要把光标移动到命令行开头时使用。 |
| ctrl+E | 把光标移动到命令行结尾。 |
| ctrl+C | 强制终止当前的命令。 |
| ctrl+L | 清屏,相当于clear命令。 |
| ctrl+U | 删除或剪切光标之前的命令。我输入了一行很长的命令,不用使用退格键一个一个字符的删除,使用这个快捷键会更加方便 |
| ctrl+K | 删除或剪切光标之后的内容。 |
| ctrl+Y | 粘贴ctrl+U或ctrl+K剪切的内容。 |
| ctrl+R | 在历史命令中搜索,按下ctrl+R之后,就会出现搜索界面,只要输入搜索内容,就会从历史命令中搜索。 |
| ctrl+D | 退出当前终端。 |
| ctrl+Z | 暂停,并放入后台。 |
| ctrl+S | 暂停屏幕输出。 |
| ctrl+Q | 恢复屏幕输出。 |
18.3.5 输入输出重定向
1)Bash的标准输入输出
| 设备 | 设备文件名 | 文件描述符 | 类型 |
|---|---|---|---|
| 键盘 | /dev/stdin | 0 | 标准输入 |
| 显示器 | /dev/stdout | 1 | 标准输出 |
| 显示器 | /dev/stderr | 2 | 标准错误输出 |
2)输出重定向
| 类型 | 符号 | 作用 |
|---|---|---|
| 标准输出重定向 | 命令 > 文件 | 以覆盖的方式,把命令的正确输出输出到指定的文件或设备当中。 |
| 标准输出重定向 | 命令 >> 文件 | 以追加的方式,把命令的正确输出输出到指定的文件或设备当中。 |
| 标准错误输出重定向 | 错误命令 2>文件 | 以覆盖的方式,把命令的错误输出输出到指定的文件或设备当中。 |
| 标准错误输出重定向 | 错误命令 2>>文件 | 以追加的方式,把命令的错误输出输出到指定的文件或设备当中。 |
| 正确输出和错误输出同时保存 | 命令 > 文件 2>&1 | 以覆盖的方式,把正确输出和错误输出都保存到同一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令 >> 文件 2>&1 | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令 &>文件 | 以覆盖的方式,把正确输出和错误输出都保存到同一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令 &>>文件 | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中。 |
| 正确输出和错误输出同时保存 | 命令>>文件1 2>>文件2 | 把正确的输出追加到文件1中,把错误的输出追加到文件2中。 |
3)输入重定向
[root@localhost ~]# wc [选项] [文件名]
选项:
-c 统计字节数
-w 统计单词数
-l 统计行数
18.3.6 多命令顺序执行
| 多命令执行符 | 格式 | 作用 |
|---|---|---|
| ; | 命令1 ;命令2 | 多个命令顺序执行,命令之间没有任何逻辑联系 |
| && | 命令1 && 命令2 | 当命令1正确执行($?=0),则命令2才会执行 当命令1执行不正确($?≠0),则命令2不会执行 |
| || | 命令1 ||命令2 | 当命令1 执行不正确($?≠0),则命令2才会执行 当命令1正确执行($?=0),则命令2不会执行 |
18.3.7 管道符
1)行提取命令grep
[root@localhost ~]# grep [选项] "搜索内容" 文件名
选项:
-A 数字: 列出符合条件的行,并列出后续的n行
-B 数字: 列出符合条件的行,并列出前面的n行
-c: 统计找到的符合条件的字符串的次数
-i: 忽略大小写
-n: 输出行号
-v: 反向查找
--color=auto 搜索出的关键字用颜色显示
示例:
[root@localhost ~]# grep "/bin/bash" /etc/passwd
#查找用户信息文件/etc/passwd中,有多少可以登录的用户
[root@localhost ~]# grep -A 3 "root" /etc/passwd
#查找包含有“root”的行,并列出后续的3行
[root@localhost ~]# grep -n "/bin/bash" /etc/passwd
#查找可以登录的用户,并显示行号
[root@localhost ~]# grep -v "/bin/bash" /etc/passwd
#查找不含有“/bin/bash”的行,其实就是列出所有的伪用户
2)find和grep的区别
find命令是在系统当中搜索符合条件的文件名,如果需要模糊查询,使用通配符进行匹配,搜索时文件名是完全匹配。
[root@localhost ~]# touch abc
#建立文件abc
[root@localhost ~]# touch abcd
#建立文件abcd
[root@localhost ~]# find . -name "abc"
./abc
#搜索文件名是abc的文件,只会找到abc文件,而不会找到文件abcd
#虽然abcd文件名中包含abc,但是find是完全匹配,只能和要搜索的数据完全一样,才能找到
注意:find命令是可以通过-regex选项识别正则表达式规则的,也就是说find命令可以按照正则表达式规则匹配,而正则表达式是模糊匹配。但是对于初学者而言,find命令和grep命令本身就不好理解,所以我们这里只按照通配符规则来进行find查询。
grep命令是在文件当中搜索符合条件的字符串,如果需要模糊查询,使用正则表达式进行匹配,搜索时字符串是包含匹配。
[root@localhost ~]# echo abc > test
#在test文件中写入abc数据
[root@localhost ~]# echo abcd >> test
#在test文件中再追加abcd数据
[root@localhost ~]# grep "abc" test
abc
abcd
#grep命令查找时,只要数据行中包含有abc,就会都列出
#所以abc和abcd都可以查询到
3)管道符
[root@localhost ~]# ll -a /etc/ | more
[root@localhost ~]# netstat -an | grep "ESTABLISHED"
#查询下本地所有网络连接,提取包含ESTABLISHED(已建立连接)的行
#就可以知道我们的服务器上有多少已经成功连接的网络连接
[root@localhost ~]# netstat -an | grep "ESTABLISHED" | wc -l
#如果想知道具体的网络连接数量,就可以再使用wc命令统计行数
[root@localhost ~]# rpm -qa | grep httpd
18.3.8 通配符
| 通配符 | 作用 |
|---|---|
| ? | 匹配一个任意字符 |
| * | 匹配0个或任意多个任意字符,也就是可以匹配任何内容 |
| [] | 匹配中括号中任意一个字符。例如:[abc]代表一定匹配一个字符,或者是a,或者是b,或者是c。 |
| [-] | 匹配中括号中任意一个字符,-代表一个范围。例如:[a-z]代表匹配一个小写字母。 |
| [^] | 逻辑非,表示匹配不是中括号内的一个字符。例如:0-9代表匹配一个不是数字的字符。 |
[root@localhost tmp]# touch abc
[root@localhost tmp]# touch abcd
[root@localhost tmp]# touch 012
[root@localhost tmp]# touch 0abc
#建立几个测试文件
[root@localhost tmp]# ls *
012 0abc abc abcd
#“*”代表所有的文件
[root@localhost tmp]# ls ?abc
0abc
#“?”匹配任意一个字符,所以会匹配0abc
#但是不能匹配abc,因为“?”不能匹配空
[root@localhost tmp]# ls [0-9]*
012 0abc
#匹配任何以数字开头的文件
[root@localhost tmp]# ls [^0-9]*
abc abcd
#匹配不已数字开头的文件
18.3.9 Bash中其他特殊符号*
| 符号 | 作用 |
|---|---|
| '' | 单引号。在单引号中所有的特殊符号,如“$”和“`”(反引号)都没有特殊含义。 |
| "" | 双引号。在双引号中特殊符号都没有特殊含义,但是“$”、“`”和“\”是例外,拥有“调用变量的值”、“引用命令”和“转义符”的特殊含义。 |
| `` | 反引号。反引号括起来的内容是系统命令,在Bash中会先执行它。和$()作用一样,不过推荐使用$(),因为反引号非常容易看错。 |
| $() | 和反引号作用一样,用来引用系统命令。 |
| () | 用于一串命令执行时,()中的命令会在子Shell中运行 |
| {} | 用于一串命令执行时,{}中的命令会在当前Shell中执行。也可以用于变量变形与替换。 |
| [] | 用于变量的测试。 |
| # | 在Shell脚本中,#开头的行代表注释。 |
| $ | 用于调用变量的值,如需要调用变量name的值时,需要用$name的方式得到变量的值。 |
| \ | 转义符,跟在\之后的特殊符号将失去特殊含义,变为普通字符。如$将输出“$”符号,而不当做是变量引用。 |
1)单引号和双引号
[root@localhost ~]# name=sc
#定义变量name的值是sc
[root@localhost ~]# echo '$name'
$name
#如果输出时使用单引号,则$name原封不动的输出
[root@localhost ~]# echo "$name"
sc
#如果输出时使用双引号,则会输出变量name的值sc
[root@localhost ~]# echo `date`
2021年 8月 5日 星期四 18:16:33 CST
#反引号括起来的命令会正常执行
[root@localhost ~]# echo '`date`'
`date`
#但是如果反引号命令被单引号括起来,那么这个命令不会执行,`date`会被当成普通字符输出
[root@localhost ~]# echo "`date`"
2021年 8月 5日 星期四 18:14:21 CST
#如果是双引号括起来,那么这个命令又会正常执行
2)反引号
[root@localhost ~]# echo ls
ls
#如果命令不用反引号包含,命令不会执行,而是直接输出
[root@localhost ~]# echo `ls`
anaconda-ks.cfg install.log install.log.syslog sh test testfile
#只有用反引号包括命令,这个命令才会执行
[root@localhost ~]# echo $(date)
2021年 8月 5日 星期四 18:25:09 CST
#使用$(命令)的方式也是可以的
3)小括号、中括号和大括号
在介绍小括号和大括号的区别之前,我们先要解释一个概念,那就是父Shell和子Shell。在我们的Bash中,是可以调用新的Bash的,比如:
[root@localhost ~]# bash
[root@localhost ~]#
这时,我们通过pstree命令查看一下进程数:
[root@localhost ~]# pstree
init─┬─abrt-dump-oops
…省略部分输出
├─sshd─┬─sshd───bash───bash───pstree
知道了父Shell和子Shell,我们接着解释小括号和大括号的区别。如果是用于一串命令的执行,那么小括号和大括号的主要区别在于:
-
()执行一串命令时,需要重新开一个子shell进行执行
-
{}执行一串命令时,是在当前shell执行;
-
()和{}都是把一串的命令放在括号里面,并且命令之间用;号隔开;
-
()最后一个命令可以不用分号;
-
{}最后一个命令要用分号;
-
{}的第一个命令和左括号之间必须要有一个空格;
-
()里的各命令不必和括号有空格;
-
()和{}中括号里面的某个命令的重定向只影响该命令,但括号外的重定向则影响到括号里的所有命令。
还是举几个例子来看看吧,这样写实在是太抽象了:
[root@localhost ~]# name=sc
#在父Shell中定义变量name的值是sc
[root@localhost ~]# (name=liming;echo $name)
liming
#如果用()括起来一串命令,这些命令都可以执行
#给name变量重新赋值,但是这个值只在子Shell中生效
[root@localhost ~]# echo $name
sc
#父Shell中name的值还是sc,而不是liming
[root@localhost ~]# { name=liming;echo $name; }
liming
#但是用大括号来进行一串命令的执行时,name变量的修改是直接在父Shell当中的
#注意大括号的格式
[root@localhost ~]# echo $name
liming
#所以name变量的值已经被修改了
18.4 Bash的变量和运算符*
18.4.1 什么是变量
在定义变量时,有一些规则需要遵守:
-
变量名称可以由字母、数字和下划线组成,但是不能以数字开头。如果变量名是“2name”则是错误的。
-
在Bash中,变量的默认类型都是字符串型,如果要进行数值运算,则必修指定变量类型为数值型。
-
变量用等号连接值,等号左右两侧不能有空格。
-
变量的值如果有空格,需要使用单引号或双引号包括。如:“test="hello world!"”。其中双引号括起来的内容“$”、“\”和反引号都拥有特殊含义,而单引号括起来的内容都是普通字符。
-
在变量的值中,可以使用“\”转义符。
-
如果需要增加变量的值,那么可以进行变量值的叠加。不过变量需要用双引号包含"$变量名"或用${变量名}包含变量名。例如:
[root@localhost ~]# test=123 [root@localhost ~]# test="$test"456 [root@localhost ~]# echo $test 123456 #叠加变量test,变量值变成了123456 [root@localhost ~]# test=${test}789 [root@localhost ~]# echo $test 123456789 #再叠加变量test,变量值编程了123456789变量值的叠加可以使用两种格式:“$变量名”或$
-
如果是把命令的结果作为变量值赋予变量,则需要使用反引号或$()包含命令。例如:
[root@localhost ~]# test=$(date) [root@localhost ~]# echo $test 2018年 10月 21日 星期一 20:27:50 CST -
环境变量名建议大写,便于区分。
18.4.2 变量的分类*
- 用户自定义变量:这种变量是最常见的变量,由用户自由定义变量名和变量的值。
- 环境变量:这种变量中主要保存的是和系统操作环境相关的数据,比如当前登录用户,用户的家目录,命令的提示符等。不是太好理解吧,那么大家还记得在Windows中,同一台电脑可以有多个用户登录,而且每个用户都可以定义自己的桌面样式和分辨率,这些其实就是Windows的操作环境,可以当做是Windows的环境变量来理解。环境变量的变量名可以自由定义,但是一般对系统起作用的环境变量的变量名是系统预先设定好的。
- 位置参数变量:这种变量主要是用来向脚本当中传递参数或数据的,变量名不能自定义,变量作用是固定的。
- 预定义变量:是Bash中已经定义好的变量,变量名不能自定义,变量作用也是固定的。
18.4.3 用户自定义变量
1)变量定义
[root@localhost ~]# 2name="shen chao"
-bash: 2name=shen chao: command not found
#变量名不能用数字开头
[root@localhost ~]# name = "shenchao"
-bash: name: command not found
#等号左右两侧不能有空格
[root@localhost ~]# name=shen chao
-bash: chao: command not found
#变量的值如果有空格,必须用引号包含
2)变量调用
[root@localhost ~]# name="shen chao"
#定义变量name
[root@localhost ~]# echo $name
shen chao
#输出变量name的值
3)变量查看
[root@localhost ~]# set [选项]
选项:
-u: 如果设定此选项,调用未声明变量时会报错(默认无任何提示)
-x: 如果设定此选项,在命令执行之前,会把命令先输出一次
[root@localhost ~]# set
BASH=/bin/bash
…省略部分输出…
name='shen chao'
#直接使用set命令,会查询系统中所有的变量,包含用户自定义变量和环境变量
[root@localhost ~]# set -u
[root@localhost ~]# echo $file
-bash: file: unbound variable
#当设置了-u选项后,如果调用没有设定的变量会有报错。默认是没有任何输出的。
[root@localhost ~]# set -x
[root@localhost ~]# ls
+ ls --color=auto
anaconda-ks.cfg install.log install.log.syslog sh tdir test testfile
#如果设定了-x选项,会在每个命令执行之前,先把命令输出一次
4)变量删除
[root@localhost ~]# unset 变量名
18.4.4 环境变量
1)环境变量设置
[root@localhost ~]# export age="18"
#使用export声明的变量即是环境变量
2)环境变量查询和删除
env命令和set命令的区别是,set命令可以查看所有变量,而env命令只能查看环境变量。
[root@localhost ~]# unset gender
[root@localhost ~]# env | grep gender
#删除环境变量gender
3)系统默认环境变量
18.4.5 位置参数变量
| 位置参数变量 | 作 用 |
|---|---|
| $n | n为数字,$0代表命令本身,$1-$9代表第一到第九个参数,十以上的参数需要用大括号包含,如${10}. |
| $* | 这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体 |
| $@ | 这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待 |
| $# | 这个变量代表命令行中所有参数的个数 |
[root@localhost sh]# vi count.sh
#!/bin/bash
# Author: shenchao (E-mail: shenchao@atguigu.com)
num1=$1
#给num1变量赋值是第一个参数
num2=$2
#给num2变量赋值是第二个参数
sum=$(( $num1 + $num2))
#变量sum的和是num1加num2
#Shell当中的运算还是不太一样的,我们Shell运算符小节中详细介绍
echo $sum
#打印变量sum的值
那么还有几个位置参数变量是干嘛的呢?我们在写个脚本来说明下:
[root@localhost sh]# vi parameter.sh
#!/bin/bash
# Author: shenchao (E-mail: shenchao@atguigu.com)
echo "A total of $# parameters"
#使用$#代表所有参数的个数
echo "The parameters is: $*"
#使用$*代表所有的参数
echo "The parameters is: $@"
#使用$@也代表所有参数
那么“$”和“$@”有区别吗?还是有区别的,$会把接收的所有参数当成一个整体对待,而$@则会区分对待接收到的所有参数。还是举个例子:
[root@localhost sh]# vi parameter2.sh
#!/bin/bash
# Author: shenchao (E-mail: shenchao@atguigu.com)
for i in "$*"
#定义for循环,in后面有几个值,for会循环多少次,注意“$*”要用双引号括起来
#每次循环会把in后面的值赋予变量i
#Shell把$*中的所有参数看成是一个整体,所以这个for循环只会循环一次
do
echo "The parameters is: $i"
#打印变量$i的值
done
x=1
#定义变量x的值为1
for y in "$@"
#同样in后面的有几个值,for循环几次,每次都把值赋予变量y
#可是Shell中把“$@”中的每个参数都看成是独立的,所以“$@”中有几个参数,就会循环几次
do
echo "The parameter$x is: $y"
#输出变量y的值
x=$(( $x +1 ))
#然变量x每次循环都加1,为了输出时看的更清楚
done
18.4.6 预定义变量
| 预定义变量 | 作 用 |
|---|---|
| $? | 最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。 |
| $$ | 当前进程的进程号(PID) |
| $! | 后台运行的最后一个进程的进程号(PID) |
我们先来看看“$?”这个变量,看起来不好理解,我们还是举个例子:
[root@localhost sh]# ls
count.sh hello.sh parameter2.sh parameter.sh
#ls命令正确执行
[root@localhost sh]# echo $?
0
#预定义变量“$?”的值是0,证明上一个命令执行正确
[root@localhost sh]# ls install.log
ls: 无法访问install.log: 没有那个文件或目录
#当前目录中没有install.log文件,所以ls命令报错了
[root@localhost sh]# echo $?
2
#变量“$?”返回一个非0的值,证明上一个命令没有正确执行
#至于错误的返回值到底是多少,是在编写ls命令时定义好的,如果碰到文件不存在就返回数值2
接下来我们来说明下“$$”和“$!”这两个预定义变量,我们写个脚本吧:
[root@localhost sh]# vi variable.sh
#!/bin/bash
# Author: shenchao (E-mail: shenchao@atguigu.com)
echo "The current process is $$"
#输出当前进程的PID。
#这个PID就是variable.sh这个脚本执行时,生成的进程的PID
find /root -name hello.sh &
#使用find命令在root目录下查找hello.sh文件
#符号&的意思是把命令放入后台执行,工作管理我们在系统管理章节会详细介绍
echo "The last one Daemon process is $!"
#输出这个后台执行命令的进程的PID,也就是输出find命令的PID号
18.4.7 交互式输入
接收键盘输入
[root@localhost ~]# read [选项] [变量名]
选项:
-p “提示信息”: 在等待read输入时,输出提示信息
-t 秒数: read命令会一直等待用户输入,使用此选项可以指定等待时间
-n 字符数: read命令只接受指定的字符数,就会执行
-s: 隐藏输入的数据,适用于机密信息的输入
变量名:
变量名可以自定义,如果不指定变量名,会把输入保存入默认变量REPLY
如果只提供了一个变量名,则整个输入行赋予该变量
如果提供了一个以上的变量名,则输入行分为若干字,一个接一个地赋予各个变量,而命令行上的最后一个变量取得剩余的所有字
还是写个例子来解释下read命令:
[root@localhost sh]# vi read.sh
#!/bin/bash
# Author: shenchao (E-mail: shenchao@atguigu.com)
read -t 30 -p "Please input your name: " name
#提示“请输入姓名”并等待30秒,把用户的输入保存入变量name中
echo "Name is $name"
#看看变量“$name”中是否保存了你的输入
read -s -t 30 -p "Please enter your age: " age
#提示“请输入年龄”并等待30秒,把用户的输入保存入变量age中
#年龄是隐私,所以我们用“-s”选项隐藏输入
echo -e "\n"
#调整输出格式,如果不输出换行,一会的年龄输出不会换行
echo "Age is $age"
read -n 1 -t 30 -p "Please select your gender[M/F]: " gender
#提示“请选择性别”并等待30秒,把用户的输入保存入变量gender
#使用“-n 1”选项只接收一个输入字符就会执行(都不用输入回车)
echo -e "\n"
echo "Sex is $gender"
18.4.8 Shell的运算符
1)数值运算的方法
那如果我需要进行数值运算,可以采用以下三种方法中的任意一种:
-
使用declare声明变量类型
既然所有变量的默认类型是字符串型,那么只要我们把变量声明为整数型不就可以运算了吗?使用declare命令就可以实现声明变量的类型。命令如下:
[root@localhost ~]# declare [+/-][选项] 变量名 选项: -: 给变量设定类型属性 +: 取消变量的类型属性 -a: 将变量声明为数组型 -i: 将变量声明为整数型(integer) -r: 讲变量声明为只读变量。注意,一旦设置为只读变量,既不能修改变量的值,也不能删除变量,甚至不能通过+r取消只读属性 -x: 将变量声明为环境变量 -p: 显示指定变量的被声明的类型示例:数值运算
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和bb赋值 [root@localhost ~]# declare -i cc=$aa+$bb #声明变量cc的类型是整数型,它的值是aa和bb的和 [root@localhost ~]# echo $cc 33 #这下终于可以相加了示例:数组变量类型
数组这个东东只有写一些较为复杂的程序才会用到,大家可以先不用着急学习数组,当有需要的时候再回来详细学习。那么数组是什么呢?所谓数组,就是相同数据类型的元素按一定顺序排列的集合,就是把有限个类型相同的变量用一个名字命名,然后用编号区分他们的变量的集合,这个名字称为数组名,编号称为下标。组成数组的各个变量成为数组的分量,也称为数组的元素,有时也称为下标变量。
一看定义就一头雾水,更加不明白数组是什么了。那么换个说法,变量和数组都是用来保存数据的,只是变量只能赋予一个数据值,一旦重复复制,后一个值就会覆盖前一个值。而数组是可以赋予一组相同类型的数据值。大家可以把变量想象成一个小办公室,这个办公室只能容纳一个人办公,办公室名就是变量名。而数组是一个大办公室,可以容纳很多人同时办公,在这个大办公室办公的每个人是通过不同的座位号来区分的,这个座位号就是数组的下标,而大办公室的名字就是数组名。
[root@localhost ~]# name[0]="shen chao" #数组中第一个变量是沈超(大办公室第一个办公桌坐最高大威猛帅气的人) [root@localhost ~]# name[1]="li ming" #数组第二个变量是李明(大办公室第二个办公桌坐头发锃亮的人) [root@localhost ~]# name[2]="tong gang" #数组第三个变量是佟刚(大办公室第三个办公桌坐眼睛比超哥还小的老师) [root@localhost ~]# echo ${name} shen chao #输出数组的内容,如果只写数组名,那么只会输出第一个下标变量 [root@localhost ~]# echo ${name[*]} shen chao li ming tong gang #输出数组所有的内容注意数组的下标是从0开始的,在调用数组值时,需要使用${数组[下标]}的方式来读取。
不过好像在刚刚的例子中,我们并没有把name变量声明为数组型啊,其实只要我们在定义变量时采用了“变量名[下标]”的格式,这个变量就会被系统认为是数组型了,不用强制声明。
示例: 环境变量
我们其实也可以使用declare命令把变量声明为环境变量,和export命令的作用是一样的:
[root@localhost ~]# declare -x test=123 #把变量test声明为环境变量示例:只读属性
注意一旦给变量设定了只读属性,那么这个变量既不能修改变量的值,也不能删除变量,甚至不能使用“+r”选项取消只读属性。命令如下:
[root@localhost ~]# declare -r test #给test赋予只读属性 [root@localhost ~]# test=456 -bash: test: readonly variable #test变量的值就不能修改了 [root@localhost ~]# declare +r test -bash: declare: test: readonly variable #也不能取消只读属性 [root@localhost ~]# unset test -bash: unset: test: cannot unset: readonly variable #也不能删除变量不过还好这个变量只是命令行声明的,所以只要重新登录或重启,这个变量就会消失了。
示例:查询变量属性和取消变量属性
变量属性的查询使用“-p”选项,变量属性的取消使用“+”选项。命令如下:
[root@localhost ~]# declare -p cc declare -i cc="33" #cc变量是int型 [root@localhost ~]# declare -p name declare -a name='([0]="shen chao" [1]="li ming" [2]="tong gang")' #name变量是数组型 [root@localhost ~]# declare -p test declare -rx test="123" #test变量是环境变量和只读变量 [root@localhost ~]# declare +x test #取消test变量的环境变量属性 [root@localhost ~]# declare -p test declare -r test="123" #注意,只读变量属性是不能取消的 -
使用expr或let数值运算工具
要想进行数值运算的第二种方法是使用expr命令,这种命令就没有declare命令复杂了。命令如下:
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和变量bb赋值 [root@localhost ~]# dd=$(expr $aa + $bb) #dd的值是aa和bb的和。注意“+”号左右两侧必须有空格 [root@localhost ~]# echo $dd 33使用expr命令进行运算时,要注意“+”号左右两侧必须有空格,否则运算不执行。
至于let命令和expr命令基本类似,都是Linux中的运算命令,命令格式如下:
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和变量bb赋值 [root@localhost ~]# let ee=$aa+$bb [root@localhost ~]# echo $ee 33 #变量ee的值是aa和bb的和 [root@localhost ~]# n=20 #定义变量n [root@localhost ~]# let n+=1 #变量n的值等于变量本身再加1 [root@localhost ~]# echo $n 21expr命令和let命令大家可以按照习惯使用,不过let命令对格式要求要比expr命令宽松,所以推荐使用let命令进行数值运算。
-
使用“$((运算式))”或“$[运算式]”方式运算
其实这是一种方式“$(())”和“$[]”这两种括号按照个人习惯使用即可。命令如下:
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 [root@localhost ~]# ff=$(( $aa+$bb )) [root@localhost ~]# echo $ff 33 #变量ff的值是aa和bb的和 [root@localhost ~]# gg=$[ $aa+$bb ] [root@localhost ~]# echo $gg 33 #变量gg的值是aa和bb的和这三种数值运算方式,大家可以按照自己的习惯来进行使用。不过我们推荐使用“$((运算式))”的方式
2)Shell常用运算符
| 优先级 | 运算符 | 说明 |
|---|---|---|
| 1 | =,+=,-=,*=,/=,%=,&=, ^=, |=, <<=, >>= | 赋值、运算且赋值 |
| 2 | || | 逻辑或 |
| 3 | && | 逻辑与 |
| 4 | | | 按位或 |
| 5 | ^ | 按位异或 |
| 6 | & | 按位与 |
| 7 | ==,!= | 等于、不等于 |
| 8 | < =, > =, < , > | 小于或等于、大于或等于、小于、大于 |
| 9 | << , >> | 按位左移、按位右移 |
| 10 | +, - | 加、减 |
| 11 | * , / , % | 乘、除、取模 |
| 12 | !, ~ | 逻辑非、按位取反或补码 |
| 13 | -, + | 单目负、单目正 |
运算符优先级表明在每个表达式或子表达式中哪一个运算对象首先被求值,数值越大优先级越高,具有较高优先级级别的运算符先于较低级别的运算符进行求值运算。
示例: 加减乘除
[root@localhost ~]# aa=$(( (11+3)*3/2 ))
#虽然乘和除的优先级高于加,但是通过小括号可以调整运算优先级
[root@localhost ~]# echo $aa
21
示例:取模运算
[root@localhost ~]# bb=$(( 14%3 ))
[root@localhost ~]# echo $bb
2
#14不能被3整除,余数是2
示例:逻辑与
[root@localhost ~]# cc=$(( 1 && 0 ))
[root@localhost ~]# echo $cc
0
#逻辑与运算只有想与的两边都是1,与的结果才是1,否则与的结果是0
18.4.9 变量的测试与内容置换
| 变量置换方式 | 变量y没有设置 | 变量y为空值 | 变量y设置值 |
|---|---|---|---|
| x=$ | x=新值 | x为空 | x=$y |
| x=$ | x=新值 | x=新值 | x=$y |
| x=$ | x为空 | x=新值 | x=新值 |
| x=$ | x为空 | x为空 | x=新值 |
| x=$ | x=新值 y=新值 | x为空 y值不变 | x=$y y值不变 |
| x=$ | x=新值 y=新值 | x=新值 y=新值 | x=$y y值不变 |
| x=$ | 新值输出到标准错误输出(就是屏幕) | x为空 | x=$y |
| x=$ | 新值输出到标准错误输出 | 新值输出到标准错误输出 | x=$y |
如果大括号内没有“:”,则变量y是为空,还是没有设置,处理方法是不同的;如果大括号内有“:”,则变量 y不论是为空,还是没有没有设置,处理方法是一样的。 如果大括号内是“-”或“+”,则在改变变量x值的时候,变量y是不改变的;如果大括号内是“=”,则在改变变量x值的同时,变量y的值也会改变。 如果大括号内是“?”,则当变量y不存在或为空时,会把“新值”当成报错输出到屏幕上。 示例:
[root@localhost ~]# unset y
#删除变量y
[root@localhost ~]# x=${y-new}
#进行测试
[root@localhost ~]# echo $x
new
#因为变量y不存在,所以x=new
[root@localhost ~]# echo $y
#但是变量y还是不存在的
和上表对比下,这个表是不是可以看懂了。这是变量y不存在的情况,那如果变量y的值是空呢?
[root@localhost ~]# y=""
#给变量y赋值为空
[root@localhost ~]# x=${y-new}
#进行测试
[root@localhost ~]# echo $x
[root@localhost ~]# echo $y
#变量x和变量y值都是空
那如果变量y有值呢?
[root@localhost ~]# y=old
#给变量y赋值
[root@localhost ~]# x=${y-new}
#进行测试
[root@localhost ~]# echo $x
old
[root@localhost ~]# echo $y
old
#变量x和变量y的值都是old
示例:
那如果大括号内是“=”号,又该是什么情况呢?先测试下变量y没有设置的情况:
[root@localhost ~]# unset y
#删除变量y
[root@localhost ~]# x=${y:=new}
#进行测试
[root@localhost ~]# echo $x
new
[root@localhost ~]# echo $y
new
#变量x和变量y的值都是new
一旦使用“=”号,那么变量y和变量x都会同时进行处理,而不像例子1中只改变变量x的值。那如果变量y为空又是什么情况呢?
[root@localhost ~]# y=""
#设定变量y为空
[root@localhost ~]# x=${y:=new}
#进程测试
[root@localhost ~]# echo $x
new
[root@localhost ~]# echo $y
new
#变量x和变量y的值都是new
一旦在大括号中使用“:”,那么变量y为空或者不设定,处理方式都是一样的了。那如果y已经赋值了,又是什么情况:
[root@localhost ~]# y=old #给y赋值
[root@localhost ~]# x=${y:=new}
#进行测试
[root@localhost ~]# echo $x
old
[root@localhost ~]# echo $y
old
#原来变量x和变量y的值都是old
示例:
再测试下大括号中是“?”的情况吧:
[root@localhost ~]# unset y
#删除变量y
[root@localhost ~]# x=${y?new}
-bash: y: new
#会把值“new”输出到屏幕上
那如果变量y已经赋值了呢:
[root@localhost ~]# y=old
#给变量y赋值
[root@localhost ~]# x=${y?new}
#进行测试
[root@localhost ~]# echo $x
old
[root@localhost ~]# echo $y
old
#变量x和变量y的值都是old
18.5 环境变量配置文件
18.5.1 source命令
[root@localhost ~]# source 配置文件
或
[root@localhost ~]# . 配置文件
18.5.2 环境变量配置文件
1)登录时生效的环境变量配置文件
在Linux系统登录时主要生效的环境变量配置文件有以下五个:
-
/etc/profile
-
/etc/profile.d/*.sh
-
~/.bash_profile
-
~/.bashrc
-
/etc/bashrc
环境变量配置文件调用过程
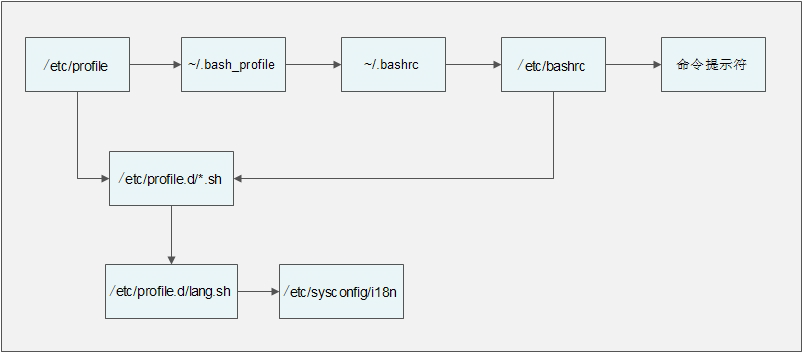
-
在用户登录过程先调用/etc/profile文件
在这个环境变量配置文件中会定义这些默认环境变量:
- USER变量:根据登录的用户,给这个变量赋值(就是让USER变量的值是当前用户)。
- LOGNAME变量:根据USER变量的值,给这个变量赋值。
- MAIL变量:根据登录的用户,定义用户的邮箱为/var/spool/mail/用户名。
- PATH变量:根据登录用户的UID是否为0,判断PATH变量是否包含/sbin、/usr/sbin和/usr/local/sbin这三个系统命令目录。
- HOSTNAME变量:更加主机名,给这个变量赋值。
- HISTSIZE变量:定义历史命令的保存条数。
- umask:定义umask默认权限。注意/etc/profile文件中的umask权限是在“有用户登录过程(也就是输入了用户名和密码)”时才会生效。
- 调用/etc/profile.d/*.sh文件,也就是调用/etc/profile.d/目录下所有以.sh结尾的文件。
-
由/etc/profile文件调用/etc/profile.d/*.sh文件
这个目录中所有以.sh结尾的文件都会被/etc/profile文件调用,这里最常用的就是lang.sh文件,而这个文件又会调用/etc/sysconfig/i18n文件。
-
由/etc/profile文件调用~/.bash_profile文件
~/.bash_profile文件就没有那么复杂了,这个文件主要实现了两个功能:
- 调用了~/.bashrc文件。
- 在PATH变量后面加入了“:$HOME/bin”这个目录。那也就是说,如果我们在自己的家目录中建立bin目录,然后把自己的脚本放入“~/bin”目录,就可以直接执行脚本,而不用通过目录执行了。
-
由/.bash_profile文件调用/.bashrc文件
在~/.bashrc文件中主要实现了:
- 定义默认别名,所以超哥把自己定义的别名也放入了这个文件。
- 调用/etc/bashrc
-
由~/.bashrc调用了/etc/bashrc文件
在/etc/bashrc文件中主要定义了这些内容:.
- PS1变量:也就是用户的提示符,如果我们想要永久修改提示符,就要在这个文件中修改
- umask:定义umask默认权限。这个文件中定义的umask是针对“没有登录过程(也就是不需要输入用户名和密码时,比如从一个终端切换到另一个终端,或进入子Shell)”时生效的。如果是“有用户登录过程”,则是/etc/profile文件中的umask生效。
- PATH变量:会给PATH变量追加值,当然也是在“没有登录过程”时才生效。
- 调用/etc/profile.d/.sh文件,这也是在“没有用户登录过程”是才调用。在“有用户登录过程”时,/etc/profile.d/.sh文件已经被/etc/profile文件调用过了。
这样这五个环境变量配置文件会被依次调用,那么如果是我们自己定义的环境变量应该放入哪个文件呢?如果你的修改是打算对所有用户生效的,那么可以放入/etc/profile环境变量配置文件;如果你的修改只是给自己使用的,那么可以放入/.bash_profile或/.bashrc这两个配置文件中的任一个。
可是如果我们误删除了这些环境变量,比如删除了/etc/bashrc文件,或删除了/.bashrc文件,那么这些文件中配置就会失效(/.bashrc文件会调用/etc/bashrc文件)。那么我们的提示符就会变成:
-bash-4.1#
2)注销时生效的环境变量配置文件
在用户退出登录时,只会调用一个环境变量配置文件,就是~/.bash_logout。这个文件默认没有写入任何内容,可是如果我们希望再退出登录时执行一些操作,比如清除历史命令,备份某些数据,就可以把命令写入这个文件。
3)其他配置文件
还有一些环节变量配置文件,最常见的就是~/bash_history文件,也就是历史命令保存文件
18.5.3 Shell登录信息
1)/etc/issue
我们在登录tty1-tty6这六个本地终端时,会有几行的欢迎界面。这些欢迎信息是保存在哪里的?可以修改吗?当然可以修改,这些欢迎信息是保存在/etc/issue文件中,我们查看下这个文件:
[root@localhost ~]# cat /etc/issue
CentOS release 7.6 (Final)
Kernel \r on an \m
可以支持的转义符我们可以通过man agetty命令查询,在表中我们列出常见的转义符作用:
| 转义符 | 作用 |
|---|---|
| \d | 显示当前系统日期 |
| \s | 显示操作系统名称 |
| \l | 显示登录的终端号,这个比较常用。 |
| \m | 显示硬件体系结构,如i386、i686等 |
| \n | 显示主机名 |
| \o | 显示域名 |
| \r | 显示内核版本 |
| \t | 显示当前系统时间 |
| \u | 显示当前登录用户的序列号 |
2)/etc/issue.net
/etc/issue是在本地终端登录是显示欢迎信息的,如果是远程登录(如ssh远程登录,或telnet远程登录)需要显示欢迎信息,则需要配置/etc/issue.net这个文件了。使用这个文件时由两点需要注意:
- 首先,在/etc/issue文件中支持的转义符,在/etc/issue.net文件中不能使用。
- 其次,ssh远程登录是否显示/etc/issue.net文件中的欢迎信息,是由ssh的配置文件决定的。
如果我们需要ssh远程登录可以查看/etc/issue.net的欢迎信息,那么首先需要修改ssh的配置文件/etc/ssh/sshd_config,加入如下内容:
[root@localhost ~]# cat /etc/ssh/sshd_config
…省略部分输出…
# no default banner path
#Banner none
Banner /etc/issue.net
…省略部分输出…
这样在ssh远程登录时,也可以显示欢迎信息,只是不再可以识别“\d”和“\l”等信息了
3)/etc/motd
/etc/motd文件中也是显示欢迎信息的,这个文件和/etc/issue及/etc/issue.net文件的区别是:/etc/issue及/etc/issue.net是在用户登录之前显示欢迎信息,而/etc/motd是在用户输入用户名和密码,正确登录之后显示欢迎信息。在/etc/motd文件中的欢迎信息,不论是本地登录,还是远程登录都可以显示。
18.5.4 定义Bash快捷键
[root@localhost ~]# stty -a
#查询所有的快捷键
那么这些快捷键可以更改吗?可以啊,只要执行:
[root@localhost ~]# stty 关键字 快捷键
例如:
[root@localhost ~]# stty intr ^p
#定义ctrl+p快捷键为强制终止,“^”字符只要手工输入即可
[root@localhost ~]# stty -a
speed 38400 baud; rows 21; columns 104; line = 0;
intr = ^P; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = <undef>; eol2 = <undef>; swtch = <undef>;
start = ^Q; stop = ^S; susp = ^Z; rprnt = ^R; werase = ^W; lnext = ^V; flush = ^O; min = 1; time = 0;
#强制终止变成了ctrl+p快捷键
+++

 浙公网安备 33010602011771号
浙公网安备 33010602011771号