代码
代码:https://zhuanlan.zhihu.com/p/102176365

#include <stdio.h> char varChar1 = 0x11; int varInt1 = 0x12345678; short varShort1 = 0x2323; long long var64Int1 = 0xF1AAAAAAAAAAAAF2; long long main(int argc, char **argv) { long long var64Int2; var64Int2 = var64Int1 + varShort1 + varChar1; for(int i = 0; i < argc; i++){ printf("%s\n", *(argv + i)); } return var64Int2; } #include <stdlib.h> int var1; int var2 = 100; int var3; int var4 = 200; int func(int inVar1, int inVar2){ var3 = inVar1 + var4; int tmp = var3 * inVar2; return tmp; } int main(int argc, char **argv) { int *buffer; int var1 = func(var2, 5); buffer = (int *)malloc(1024); return var1; } #include <stdio.h> int arr[8] = {0, 1, 2, 3, 4, 5, 6, 7}; typedef struct _myStruct{ char ch1; double dou1; int i1; } MyStruct; typedef union _myUnion{ char ch1; double dou1; int i1; } MyUnion; int main(int argc, char **argv) { MyStruct myStruct; myStruct.ch1 = 'a'; myStruct.dou1 = 1.0; myStruct.i1 = 2; MyUnion myUnion; myUnion.ch1 = 'a'; myUnion.dou1 = 1.0; myUnion.i1 = 2; printf("arr size: %d\n", sizeof(arr)); printf("struct size: %d\n", sizeof(MyStruct)); printf("union size: %d\n", sizeof(MyUnion)); return 0; } #include <stdio.h> int funSum(int num){ int sum = 0; for(int i = 0; i < num; i++){ sum += i; } return sum; } int main(int argc, char **argv) { long result = 0; for(int i = 0; i <= 100; i++){ result += i; } char arr[10] = {'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'}; printf("result[1-100] = %d\n", result); printf("result[1-200] = %d\n", funSum(200)); return 0; }
C 语言内存管理指对系统内存的分配、创建、使用这一系列操作。在内存管理中,由于是操作系统内存,使用不当会造成毕竟麻烦的结果。本文将从系统内存的分配、创建出发,并且使用例子来举例说明内存管理不当会出现的情况及解决办法。
一、内存
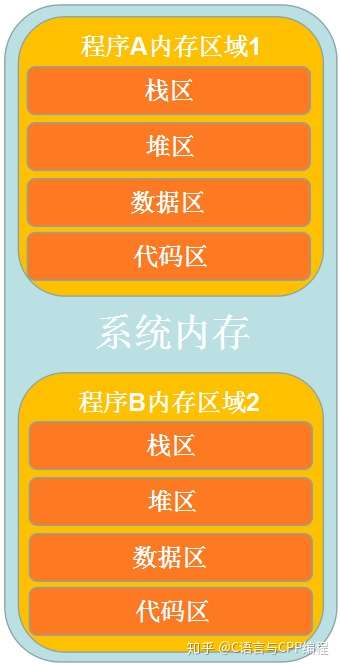
在计算机中,每个应用程序之间的内存是相互独立的,通常情况下应用程序 A 并不能访问应用程序 B,当然一些特殊技巧可以访问,但此文并不详细进行说明。例如在计算机中,一个视频播放程序与一个浏览器程序,它们的内存并不能访问,每个程序所拥有的内存是分区进行管理的。
在计算机系统中,运行程序 A 将会在内存中开辟程序 A 的内存区域 1,运行程序 B 将会在内存中开辟程序 B 的内存区域 2,内存区域 1 与内存区域 2 之间逻辑分隔。

1.1 内存四区
在程序 A 开辟的内存区域 1 会被分为几个区域,这就是内存四区,内存四区分为栈区、堆区、数据区与代码区。
栈区指的是存储一些临时变量的区域,临时变量包括了局部变量、返回值、参数、返回地址等,当这些变量超出了当前作用域时将会自动弹出。该栈的最大存储是有大小的,该值固定,超过该大小将会造成栈溢出。
堆区指的是一个比较大的内存空间,主要用于对动态内存的分配;在程序开发中一般是开发人员进行分配与释放,若在程序结束时都未释放,系统将会自动进行回收。
数据区指的是主要存放全局变量、常量和静态变量的区域,数据区又可以进行划分,分为全局区与静态区。全局变量与静态变量将会存放至该区域。
代码区就比较好理解了,主要是存储可执行代码,该区域的属性是只读的。
1.2 使用代码证实内存四区的底层结构
由于栈区与堆区的底层结构比较直观的表现,在此使用代码只演示这两个概念。 首先查看代码观察栈区的内存地址分配情况:
#include<stdio.h>
int main()
{
int a = 0;
int b = 0;
char c='0';
printf("变量a的地址是:%d\n变量b的地址是:%d\n变量c的地址是:%d\n", &a, &b, &c);
}
运行结果为:
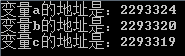
我们可以观察到变量 a 的地址是 2293324 变量 b 的地址是 2293320,由于 int 的数据大小为 4 所以两者之间间隔为 4;再查看变量 c,我们发现变量 c 的地址为 2293319,与变量 b 的地址 2293324 间隔 1,因为 c 的数据类型为 char,类型大小为 1。在此我们观察发现,明明我创建变量的时候顺序是 a 到 b 再到 c,为什么它们之间的地址不是增加而是减少呢?那是因为栈区的一种数据存储结构为先进后出,如图:
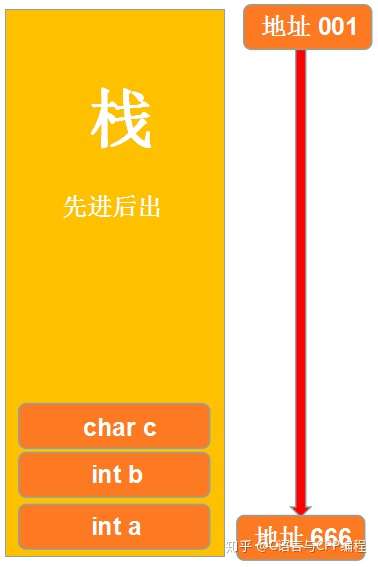
首先栈的顶部为地址的“最小”索引,随后往下依次增大,但是由于堆栈的特殊存储结构,我们将变量 a 先进行存储,那么它的一个索引地址将会是最大的,随后依次减少;第二次存储的值是 b,该值的地址索引比 a 小,由于 int 的数据大小为 4,所以在 a 地址为 2293324 的基础上往上减少 4 为 2293320,在存储 c 的时候为 char,大小为 1,则地址为 2293319。由于 a、b、c 三个变量同属于一个栈内,所以它们地址的索引是连续性的,那如果我创建一个静态变量将会如何?在以上内容中说明了静态变量存储在静态区内,我们现在就来证实一下:
#include<stdio.h>
int main()
{
int a = 0;
int b = 0;
char c='0';
static int d = 0;
printf("变量a的地址是:%d\n变量b的地址是:%d\n变量c的地址是:%d\n", &a, &b, &c);
printf("静态变量d的地址是:%d\n", &d);
}
运行结果如下:
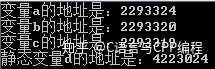
以上代码中创建了一个变量 d,变量 d 为静态变量,运行代码后从结果上得知,静态变量 d 的地址与一般变量 a、b、c 的地址并不存在连续,他们两个的内存地址是分开的。那接下来在此建一个全局变量,通过上述内容得知,全局变量与静态变量都应该存储在静态区,代码如下:
#include<stdio.h>
int e = 0;
int main()
{
int a = 0;
int b = 0;
char c='0';
static int d = 0;
printf("变量a的地址是:%d\n变量b的地址是:%d\n变量c的地址是:%d\n", &a, &b, &c);
printf("静态变量d的地址是:%d\n", &d);
printf("全局变量e的地址是:%d\n", &e);
}
运行结果如下:
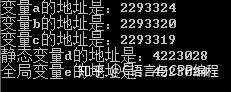
从以上运行结果中证实了上述内容的真实性,并且也得到了一个知识点,栈区、数据区都是使用栈结构对数据进行存储。
在以上内容中还说明了一点栈的特性,就是容量具有固定大小,超过最大容量将会造成栈溢出。查看如下代码:
#include<stdio.h>
int main()
{
char arr_char[1024*1000000];
arr_char[0] = '0';
}
以上代码定义了一个字符数组 arr_char,并且设置了大小为 1024*1000000,设置该数据是方便查看大小;随后在数组头部进行赋值。运行结果如下:
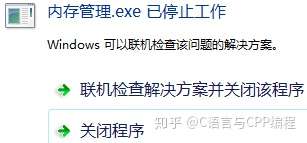
这是程序运行出错,原因是造成了栈的溢出。在平常开发中若需要大容量的内存,需要使用堆。
堆并没有栈一样的结构,也没有栈一样的先进后出。需要人为的对内存进行分配使用。代码如下:
#include<stdio.h>
#include<string.h>
#include <malloc.h>
int main()
{
char *p1 = (char *)malloc(1024*1000000);
strcpy(p1, "这里是堆区");
printf("%s\n", p1);
}
以上代码中使用了strcpy 往手动开辟的内存空间 p1 中传数据“这里是堆区”,手动开辟空间使用 malloc,传入申请开辟的空间大小 1024*1000000,在栈中那么大的空间必定会造成栈溢出,而堆本身就是大容量,则不会出现该情况。随后输出开辟的内存中内容,运行结果如下:
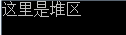
在此要注意p1是表示开辟的内存空间地址。
二、malloc 和 free
在 C 语言(不是 C++)中,malloc 和 free 是系统提供的函数,成对使用,用于从堆中分配和释放内存。malloc 的全称是 memory allocation 译为“动态内存分配”。
2.1 malloc 和 free 的使用
在开辟堆空间时我们使用的函数为 malloc,malloc 在 C 语言中是用于申请内存空间,malloc 函数的原型如下:
void *malloc(size_t size);
在 malloc 函数中,size 是表示需要申请的内存空间大小,申请成功将会返回该内存空间的地址;申请失败则会返回 NULL,并且申请成功也不会自动进行初始化。
细心的同学可能会发现,该函数的返回值说明为 void *,在这里 void * 并不指代某一种特定的类型,而是说明该类型不确定,通过接收的指针变量从而进行类型的转换。在分配内存时需要注意,即时在程序关闭时系统会自动回收该手动申请的内存 ,但也要进行手动的释放,保证内存能够在不需要时返回至堆空间,使内存能够合理的分配使用。
释放空间使用 free 函数,函数原型如下:
void free(void *ptr);
free 函数的返回值为 void,没有返回值,接收的参数为使用 malloc 分配的内存空间指针。 一个完整的堆内存申请与释放的例子如下:
#include<stdio.h>
#include<string.h>
#include <malloc.h>
int main() {
int n, *p, i;
printf("请输入一个任意长度的数字来分配空间:");
scanf("%d", &n);
p = (int *)malloc(n * sizeof(int));
if(p==NULL){
printf("申请失败\n");
return 0;
}else{
printf("申请成功\n");
}
memset(p, 0, n * sizeof(int));//填充0
//查看
for (i = 0; i < n; i++)
printf("%d ", p[i]);
printf("\n");
free(p);
p = NULL;
return 0;
}
以上代码中使用了 malloc 创建了一个由用户输入创建指定大小的内存,判断了内存地址是否创建成功,且使用了 memset 函数对该内存空间进行了填充值,随后使用 for 循环进行了查看。最后使用了 free 释放了内存,并且将 p 赋值 NULL,这点需要主要,不能使指针指向未知的地址,要置于 NULL;否则在之后的开发者会误以为是个正常的指针,就有可能再通过指针去访问一些操作,但是在这时该指针已经无用,指向的内存也不知此时被如何使用,这时若出现意外将会造成无法预估的后果,甚至导致系统崩溃,在 malloc 的使用中更需要需要。
2.2 内存泄漏与安全使用实例与讲解
内存泄漏是指在动态分配的内存中,并没有释放内存或者一些原因造成了内存无法释放,轻度则造成系统的内存资源浪费,严重的导致整个系统崩溃等情况的发生。内存泄漏通常比较隐蔽,且少量的内存泄漏发生不一定会发生无法承受的后果,但由于该错误的积累将会造成整体系统的性能下降或系统崩溃。特别是在较为大型的系统中,如何有效的防止内存泄漏等问题的出现变得尤为重要。例如一些长时间的程序,若在运行之初有少量的内存泄漏的问题产生可能并未呈现,但随着运行时间的增长、系统业务处理的增加将会累积出现内存泄漏这种情况;这时极大的会造成不可预知的后果,如整个系统的崩溃,造成的损失将会难以承受。由此防止内存泄漏对于底层开发人员来说尤为重要。
C 程序员在开发过程中,不可避免的面对内存操作的问题,特别是频繁的申请动态内存时会及其容易造成内存泄漏事故的发生。如申请了一块内存空间后,未初始化便读其中的内容、间接申请动态内存但并没有进行释放、释放完一块动态申请的内存后继续引用该内存内容;如上所述这种问题都是出现内存泄漏的原因,往往这些原因由于过于隐蔽在测试时不一定会完全清楚,将会导致在项目上线后的长时间运行下,导致灾难性的后果发生。
如下是一个在子函数中进行了内存空间的申请,但是并未对其进行释放:
#include<stdio.h>
#include<string.h>
#include <malloc.h>
void m() {
char *p1;
p1 = malloc(100);
printf("开始对内存进行泄漏...");
}
int main() {
m();
return 0;
}
如上代码中,使用 malloc 申请了 100 个单位的内存空间后,并没有进行释放。假设该 m 函数在当前系统中调用频繁,那将会每次使用都将会造成 100 个单位的内存空间不会释放,久而久之就会造成严重的后果。理应在 p1 使用完毕后添加 free 进行释放:
free(p1);
以下示范一个读取文件时不规范的操作:
#include<stdio.h>
#include<string.h>
#include <malloc.h>
int m(char *filename) {
FILE* f;
int key;
f = fopen(filename, "r");
fscanf(f, "%d", &key);
return key;
}
int main() {
m("number.txt");
return 0;
}
以上文件在读取时并没有进行 fclose,这时将会产生多余的内存,可能一次还好,多次会增加成倍的内存,可以使用循环进行调用,之后在任务管理器中可查看该程序运行时所占的内存大小,代码为:
#include<stdio.h>
#include<string.h>
#include <malloc.h>
int m(char *filename) {
FILE* f;
int key;
f = fopen(filename, "r");
fscanf(f, "%d", &key);
return key;
}
int main() {
int i;
for(i=0;i<500;i++) {
m("number.txt");
}
return 0;
}
可查看添加循环后的程序与添加循环前的程序做内存占用的对比,就可以发现两者之间添加了循环的代码将会成本增加占用容量。
未被初始化的指针也会有可能造成内存泄漏的情况,因为指针未初始化所指向不可控,如:
int *p;
*p = val;
包括错误的释放内存空间:
pp=p;
free(p);
free(pp);
释放后使用,产生悬空指针。在申请了动态内存后,使用指针指向了该内存,使用完毕后我们通过 free 函数释放了申请的内存,该内存将会允许其它程序进行申请;但是我们使用过后的动态内存指针依旧指向着该地址,假设其它程序下一秒申请了该区域内的内存地址,并且进行了操作。当我依旧使用已 free 释放后的指针进行下一步的操作时,或者所进行了一个计算,那么将会造成的结果天差地别,或者是其它灾难性后果。所以对于这些指针在生存期结束之后也要置为 null。 查看一个示例,由于 free 释放后依旧使用该指针,造成的计算结果天差地别:
#include<stdio.h>
#include<string.h>
#include <malloc.h>
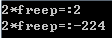
int m(char *freep) {
int val=freep[0];
printf("2*freep=:%d\n",val*2);
free(freep);
val=freep[0];
printf("2*freep=:%d\n",val*2);
}
int main() {
int *freep = (int *) malloc(sizeof (int));
freep[0]=1;
m(freep);
return 0;
}
以上代码使用 malloc 申请了一个内存后,传值为 1;在函数中首先使用 val 值接收 freep 的值,将 val 乘 2,之后释放 free,重新赋值给 val,最后使用 val 再次乘 2,此时造成的结果出现了极大的改变,而且最恐怖的是该错误很难发现,隐蔽性很强,但是造成的后顾难以承受。 运行结果如下:
三、 new 和 delete
C++ 中使用 new 和 delete 从堆中分配和释放内存,new 和 delete 是运算符,不是函数,两者成对使用(后面说明为什么成对使用)。
new/delete 除了分配内存和释放内存(与 malloc/free),还做更多的事情,所有在 C++ 中不再使用 malloc/free 而使用 new/delete。
3.1 new 和 delete 使用
new 一般使用格式如下:
- 指针变量名 = new 类型标识符;
- 指针变量名 = new 类型标识符(初始值);
- 指针变量名 = new 类型标识符[内存单元个数];
注意:free/delete 不要重复调用,被系统立即回收后再利用,再一次 free/delete 很可能把不是自己的内存释放掉,导致异常甚至崩溃。
上面提到 new/delete 比 malloc/free 多做了一些事情,new 相对于 malloc 会额外的做一些初始化工作,delete 相对于 free 多做一些清理工作。
class A
{
public:
A()
{
cont<<"A()构造函数被调用"<<endl;
}
~A()
{
cont<<"~A()构造函数被调用"<<endl;
}
}
在 main 主函数中,加入如下代码:
A* pa = new A(); //类 A 的构造函数被调用
delete pa; //类 A 的析构函数被调用
可以看出:使用 new 生成一个类对象时系统会调用该类的构造函数,使用 delete 删除一个类对象时,系统会调用该类的析构函数。可以调用构造函数/析构函数就意味着 new 和 delete 具备针对堆所分配的内存进行初始化和释放的能力,而 malloc 和 free 不具备。
2.2 delete 与 delete[] 的区别
c++ 中对 new 申请的内存的释放方式有 delete 和 delete[] 两种方式,到底这两者有什么区别呢?
我们通常从教科书上看到这样的说明:
- delete 释放 new 分配的单个对象指针指向的内存
- delete[] 释放 new 分配的对象数组指针指向的内存 那么,按照教科书的理解,我们看下下面的代码:
int *a = new int[10];
delete a; //方式1
delete[] a; //方式2
- 针对简单类型 使用 new 分配后的不管是数组还是非数组形式内存空间用两种方式均可 如:
int *a = new int[10];
delete a;
delete[] a;
此种情况中的释放效果相同,原因在于:分配简单类型内存时,内存大小已经确定,系统可以记忆并且进行管理,在析构时,系统并不会调用析构函数。
它直接通过指针可以获取实际分配的内存空间,哪怕是一个数组内存空间(在分配过程中 系统会记录分配内存的大小等信息,此信息保存在结构体 _CrtMemBlockHeader 中,具体情况可参看 VC 安装目录下 CRTSRCDBGDEL.cpp)。
- 针对类 Class,两种方式体现出具体差异
当你通过下列方式分配一个类对象数组:
class A
{
private:
char *m_cBuffer;
int m_nLen;
`` public:
A(){ m_cBuffer = new char[m_nLen]; }
~A() { delete [] m_cBuffer; }
};
A *a = new A[10];
delete a; //仅释放了a指针指向的全部内存空间 但是只调用了a[0]对象的析构函数 剩下的从a[1]到a[9]这9个用户自行分配的m_cBuffer对应内存空间将不能释放 从而造成内存泄漏
delete[] a; //调用使用类对象的析构函数释放用户自己分配内存空间并且 释放了a指针指向的全部内存空间
所以总结下就是,如果 ptr 代表一个用new申请的内存返回的内存空间地址,即所谓的指针,那么:
delete ptr 代表用来释放内存,且只用来释放 ptr 指向的内存。delete[] rg 用来释放rg指向的内存,!!还逐一调用数组中每个对象的destructor!!
对于像 int/char/long/int*/struct 等等简单数据类型,由于对象没有 destructor ,所以用 delete 和 delete []是一样的!但是如果是 C++ 对象数组就不同了!
关于 new[] 和 delete[],其中又分为两种情况:
- (1) 为基本数据类型分配和回收空间;
- (2) 为自定义类型分配和回收空间;
对于 (1),上面提供的程序已经证明了 delete[] 和 delete 是等同的。但是对于 (2),情况就发生了变化。
我们来看下面的例子,通过例子的学习了解 C++ 中的 delete 和 delete[] 的使用方法
#include <iostream>
using namespace std;
class Babe
{
public:
Babe()
{
cout << \"Create a Babe to talk with me\" << endl;
}
~Babe()
{
cout << \"Babe don\'t Go away,listen to me\" << endl;
}
};
int main()
{
Babe* pbabe = new Babe[3];
delete pbabe;
pbabe = new Babe[3];
delete[] pbabe;
return 0;
}
结果是:
Create a babe to talk with me
Create a babe to talk with me
Create a babe to talk with me
Babe don\'t go away,listen to me
Create a babe to talk with me
Create a babe to talk with me
Create a babe to talk with me
Babe don\'t go away,listen to me
Babe don\'t go away,listen to me
Babe don\'t go away,listen to me
大家都看到了,只使用 delete 的时候只出现一个 Babe don’t go away,listen to me,而使用 delete[] 的时候出现 3 个 Babe don’t go away,listen to me。不过不管使用 delete 还是 delete[] 那三个对象的在内存中都被删除,既存储位置都标记为可写,但是使用 delete 的时候只调用了 pbabe[0] 的析构函数,而使用了 delete[] 则调用了 3 个 Babe 对象的析构函数。
你一定会问,反正不管怎样都是把存储空间释放了,有什么区别。
答:关键在于调用析构函数上。此程序的类没有使用操作系统的系统资源(比如:Socket、File、Thread等),所以不会造成明显恶果。如果你的类使用了操作系统资源,单纯把类的对象从内存中删除是不妥当的,因为没有调用对象的析构函数会导致系统资源不被释放,这些资源的释放必须依靠这些类的析构函数。所以,在用这些类生成对象数组的时候,用 delete[] 来释放它们才是王道。而用 delete 来释放也许不会出问题,也许后果很严重,具体要看类的代码了。
掌握Shell编程,一篇就够了
没想到收藏数这么高,文末更新一波福利,友情提示:很干,错过就真是你的问题了。
本文首先介绍了 Shell 编程是什么,并带大家快速入门,随后讲解 Shell 的基本语法并结合案例重点分析用法。包括 Shell 流程控制和自定义函数等。建议收藏。
谁需要学习 Shell 编程?
- Linux运维工程师:编写Shell程序进行服务集群管理。
- Python和JavaEE程序员:编写Shell脚本程序或者是服务器的维护,比如编写一个定时备份数据库的脚本。
- 大数据程序员:编写Shell程序来管理集群。
Shell 是什么?
Shell 是一个命令解释权,它为用户提供了一个向 Linux 内核发送请求以便运行程序界面系统级程序,用户可以用 Shell 来启动、挂起、停止甚至是编写一些程序。

Shell 编程快速入门
进入 Linux 终端,编写一个 Shell 脚本 hello.sh :
#!/bin/bash
echo 'hello world!'
运行:
# 方法1
sh hello.sh
# 方法2
chmod +x hello.sh
./hello.sh
终端打印出 hello world! 。
说明:
#!告诉系统这个脚本需要什么解释器来执行。- 文件扩展名
.sh不是强制要求的。 - 方法1 直接运行解释器,
hello.sh作为 Shell 解释器的参数。此时 Shell 脚本就不需要指定解释器信息,第一行可以去掉。 - 方法2 hello.sh 作为可执行程序运行,Shell 脚本第一行一定要指定解释器。
Shell 变量
定义
Shell 变量分为系统变量和自定义变量。系统变量有PWD、$USER等,显示当前 Shell 中所有变量:set 。
变量名可以由字母、数字、下划线组成,不能以数字开头。
基本语法
- 定义变量:变量名=变量值,等号两侧不能有空格,变量名一般习惯用大写。
- 删除变量:unset 变量名 。
- 声明静态变量:readonly 变量名,静态变量不能unset。
- 使用变量:$变量名
将命令返回值赋给变量(重点)
- A=`ls` 反引号,执行里面的命令
- A=$(ls) 等价于反引号
Shell 环境变量
定义
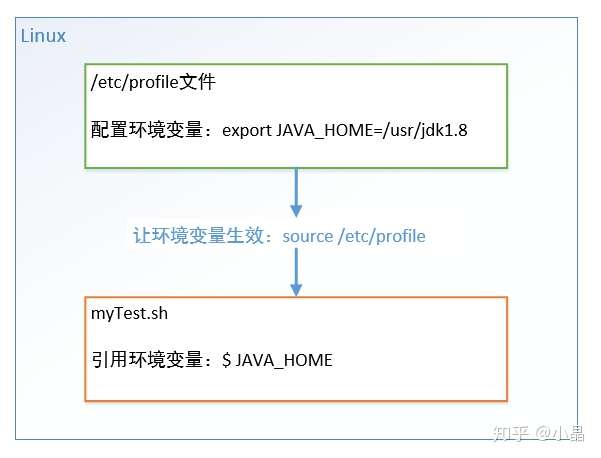
基本语法
- export 变量名=变量值,将 Shell 变量输出为环境变量。
- source 配置文件路径,让修改后的配置信息立即生效。
- echo $变量名,检查环境变量是否生效
位置参数变量
基本语法
- 0 代表命令本身、9 代表第1到9个参数,10以上参数用花括号,如 ${10}。
- $* :命令行中所有参数,且把所有参数看成一个整体。
- $@ :命令行中所有参数,且把每个参数区分对待。
- $# :所有参数个数。
实例:
编写 Shell 脚本 positionPara.sh ,输出命令行输入的各个参数信息。
#!/bin/bash
# 输出各个参数
echo $0 $1 $2
echo $*
echo $@
echo 参数个数=$#
运行:
chmod +x positionPara.sh
./positionPara.sh 10 20
运行结果:
./positionPara.sh 10 20
10 20
10 20
参数个数=2
预定义变量
定义
在赋值定义之前,事先在 Shell 脚本中直接引用的变量。
基本语法
- $$ :当前进程的 PID 进程号。
- $! :后台运行的最后一个进程的 PID 进程号。
- $? :最后一次执行的命令的返回状态,0为执行正确,非0执行失败。
实例:
编写 Shell 脚本 prePara.sh ,输出命令行输入的各个参数信息。
#!/bin/bash
echo 当前的进程号=$$
# &:以后台的方式运行程序
./hello.sh &
echo 最后一个进程的进程号=$!
echo 最后执行的命令结果=$?
运行结果:
当前的进程号=41752
最后一个进程的进程号=41753
最后执行的命令结果=0 # hello world!
运算符
基本语法
- [运算式]
- expr m + n 注意 expr 运算符间要有空格
- expr m - n
- expr \*,/,% 分别代表乘,除,取余
实例
# 第1种方式 $(())
echo $(((2+3)*4))
# 第2种方式 $[],推荐
echo $[(2+3)*4]
# 使用 expr
TEMP=`expr 2 + 3`
echo `expr $TEMP \* 4`
条件判断
基本语法
[ condition ] 注意condition前后要有空格。非空返回0,0为 true,否则为 false 。
实例
#!/bin/bash
if [ 'test01' = 'test' ]
then
echo '等于'
fi
# 20是否大于10
if [ 20 -gt 10]
then
echo '大于'
fi
# 是否存在文件/root/shell/a.txt
if [ -e /root/shell/a.txt ]
then
echo '存在'
fi
if [ 'test02' = 'test02' ] && echo 'hello' || echo 'world'
then
echo '条件满足,执行后面的语句'
fi
运行结果:
流程控制
if 判断
基本语法
if [ 条件判断式 ];then
程序
fi
# 或者(推荐)
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
fi实例
编写 Shell 程序:如果输入的参数大于60,输出“及格”,否则输出“不及格”。
#!/bin/bash
if [ $1 -ge 60 ]
then
echo 及格
elif [ $1 -lt 60 ]
then
echo "不及格"
ficase 分支
基本语法
case $变量名 in
"值1")
如果变量值等于值1,则执行此处程序1
;;
"值2")
如果变量值等于值2,则执行此处程序2
;;
...省略其它分支...
*)
如果变量值不等于以上列出的值,则执行此处程序
;;
esac实例
当命令行参数为1时输出“周一”,2时输出“周二”,其他情况输出“其它”。
case $1 in
"1")
echo 周一
;;
"2")
echo 周二
;;
*)
echo 其它
;;
esacfor 循环
基本语法
# 语法1
for 变量名 in 值1 值2 值3...
do
程序
done
# 语法2
for ((初始值;循环控制条件;变量变化))
do
程序
done实例
- 打印命令行输入的参数。
#!/bin/bash
# 使用$*
for i in "$*"
do
echo "the arg is $i"
done
echo "=================="
# 使用$@
for j in "$@"
do
echo "the arg is $j"
done运行结果(回顾一下 @ 的区别):
the arg is 1 2 3
==================
the arg is 1
the arg is 2
the arg is 32. 输出从1加到100的值。
#!/bin/bash
SUM=0
for ((i=1;i<=100;i++))
do
SUM=$[$SUM+$i]
done
echo $SUMwhile 循环
基本语法
while [ 条件判断式 ]
do
程序
done 实例
输出从1加到100的值。
#!/bin/bash
SUM=0
i=0
while [ $i -le $1 ]
do
SUM=$[$SUM+$i]
i=$[$i+1]
done
echo $SUM读取控制台输入
基本语法
read(选项)(参数)
选项
- -p:指定读取值时的提示符
- -t:指定读取值时等待的时间(秒),如果没有在指定时间内输入,就不再等待了。
参数
- 变量名:读取值的变量名
实例
读取控制台输入一个num值。
#!/bin/bash
read -p "请输入一个数num1=" NUM1
echo "你输入num1的值是:$NUM1"
read -t 10 -p "请在10秒内输入一个数num2=" NUM2
echo "你输入num2的值是:$NUM2"运行结果:
请输入一个数num1=10
你输入num1的值是:10
请在10秒内输入一个数num2=20
你输入num2的值是:20函数
和其它编程语言一样,Shell 编程有系统函数和自定义函数,本文只举两个常用系统函数。
系统函数
- basename,删掉路径最后一个 / 前的所有部分(包括/),常用于获取文件名。
基本语法 - basename [pathname] [suffix]
- basename [string] [suffix]
- 如果指定 suffix,也会删掉pathname或string的后缀部分。
实例
# basename /usr/bin/sort
sort
# basename include/stdio.h
stdio.h
# basename include/stdio.h .h
stdio- dirname,删掉路径最后一个 / 后的所有部分(包括/),常用于获取文件路径。
基本语法 - dirname pathname
- 如果路径中不含 / ,则返回 '.' (当前路径)。
实例
# dirname /usr/bin/
/usr
# dirname dir1/str dir2/str
dir1
dir2
# dirname stdio.h
.自定义函数
基本语法
[ function ] funname[()]
{
Action;
[return int;]
}
# 调用
funname 参数1 参数2...实例
计算输入两个参数的和。
#!/bin/bash
function getSum(){
SUM=$[$n1+$n2]
echo "sum=$SUM"
}
read -p "请输入第一个参数n1:" n1
read -p "请输入第二个参数n2:" n2
# 调用 getSum 函数
getSum $n1 $n2恭喜!你已经掌握了 Shell 的基本语法,入门很简单。想要更系统的探索Shell编程,可以和我一起深入学习接下来的高级篇。老样子,向大家推荐一本最值得购入和收藏的程序员必读好书:

《深入理解计算机系统》属于圣经级别的众多国内外名校教材(北大清华上海交大,国外简直更多了),罕见的豆瓣评分9.5,也是我最喜欢的专业书。读过好几遍了,不管是学生还是开发老手,这绝对是程序员最值得投资并且之后不会后悔的书,有点难,但很有用,想要电子版的也可以私信我,免费送你。
如果本文对你有帮助,收藏完了也点个赞互相鼓励一下吧~另外欢迎大家关注我的主页,会不定期输出有价值的内容。
更多干货
不看后悔系列:
Linux针对很多常用命令增加了很多新的更加有用高效的新命令,这些命令不但可以大大提高工作效率和体验,让你在同事面前装那啥的利器,如果能在面试新工作时提起这类命令,更是能给面试官眼前一亮的加分项,下面展示了几个在工作中最常用的命令。
- 如果你想要有语法高亮的
cat,可以试试 ccat 命令。 - exa 增强了
ls命令,如果你需要在很多目录上浏览各种文件 ,ranger 命令可以比cd和cat更有效率,甚至可以在你的终端预览图片。 - fd 是一个比
find更简单更快的命令,他还会自动地忽略掉一些你配置在.gitignore中的文件,以及.git下的文件。 - fzf 会是一个很好用的文件搜索神器,其主要是搜索当前目录以下的文件,还可以使用
fzf --preview 'cat {}'边搜索文件边浏览内容。 grep是一个上古神器,然而,ack、ag 和 rg 是更好的grep,和上面的fd一样,在递归目录匹配的时候,会使用你配置在.gitignore中的规则。rm是一个危险的命令,尤其是各种rm -rf …,所以,trash 是一个更好的删除命令。man命令是好读文档的命令,但是man的文档有时候太长了,所以,你可以试试 tldr 命令,把文档上的一些示例整出来给你看。- 如果你想要一个图示化的
ping,你可以试试 prettyping 。 - 如果你想搜索以前打过的命令,不要再用 Ctrl +R 了,你可以使用加强版的 hstr 。
- htop 是 top 的一个加强版。然而,还有很多的各式各样的top,比如:用于看IO负载的 iotop,网络负载的 iftop, 以及把这些top都集成在一起的 atop。
- ncdu 比 du 好用多了。另一个选择是 nnn。
- 如果你想把你的命令行操作录制成一个 SVG 动图,那么你可以尝试使用 asciinema 和 svg-trem 。
- httpie 是一个可以用来替代
curl和wget的 http 客户端,httpie支持 json 和语法高亮,可以使用简单的语法进行 http 访问:http -v github.com。 - tmux 在需要经常登录远程服务器工作的时候会很有用,可以保持远程登录的会话,还可以在一个窗口中查看多个 shell 的状态。
- sshrc 是个神器,在你登录远程服务器的时候也能使用本机的 shell 的 rc 文件中的配置。
- goaccess 这个是一个轻量级的分析统计日志文件的工具,主要是分析各种各样的 access log。
往期高收藏:
zhuanlan.zhihu.com 小晶:从原理到实战,彻底搞懂 Nginx!(高级篇)zhuanlan.zhihu.com小晶:Kafka 概述:深入理解架构
小晶:从原理到实战,彻底搞懂 Nginx!(高级篇)zhuanlan.zhihu.com小晶:Kafka 概述:深入理解架构


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具