使用webmagic爬虫对百度百科进行简单的爬取
一、分析要爬取的网页源码:
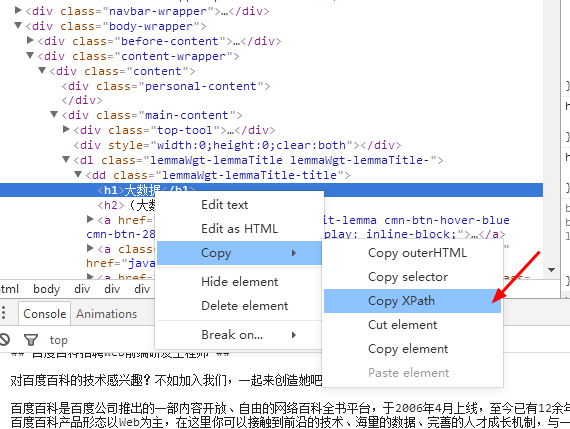
1、打开要分析的网页,查看源代码,找到要爬取的内容:
(选择网页里的一部分右击审查元素也行)

2、导入jar包,这个就直接去网上下吧;
3、写爬虫:
1 package com.gb.pachong;
2 import java.sql.SQLException;
3 import com.gb.util.AddNum;
4 import us.codecraft.webmagic.Page;
5 import us.codecraft.webmagic.Site;
6 import us.codecraft.webmagic.Spider;
7 import us.codecraft.webmagic.processor.PageProcessor;
8 public class BaikePaChong implements PageProcessor
9 {
10 private static String key;
11 public static String res=null;
12 // 抓取网站的相关配置,包括编码、重试次数、抓取间隔
13 private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
14 public void run(String key)
15 {
16 this.key = key;
17 //addUrl就是种子url,Page对象就是当前获取的页面,getUrl()可以获得当前url,addTargetRequests()就是把链接放入等待爬取,getHtml()获得页面的html元素
18 //启动爬虫
19 Spider.create(new BaikePaChong()).addUrl("https://baike.baidu.com/item/" + key).thread(5).run();
20 }
21 @Override
22 public Site getSite()
23 {
24 return site;
25 }
26 @Override
27 public void process(Page page)
28 {
29 //获取页面内容
30 res = page.getHtml().xpath("//meta[@name='description']/@content").toString();
31 //把包含数据添加到数据库的方法的类实例化成对象
32 AddNum addNum=new AddNum();
33 try
34 {
35 //数据添加进数据库
36 addNum.store(key, res);
37 }
38 catch (SQLException e)
39 {
40 e.printStackTrace();
41 }
42 }
43 public void search(String string)
44 {
45 BaikePaChong baikePaChong = new BaikePaChong();
46 baikePaChong.run(string);
47 }
48 public String getRes()
49 {
50 return res;
51 }
52 }
4、上面只是简单的爬取,可以仿照这样的方法进行一些别样的扩展使用。
5、Xpath可以在这里直接复制:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号