万恶之源 - Python基础知识补充
编码转换#
编码回顾:
1. ASCII : 最早的编码. ⾥⾯有英⽂⼤写字⺟, ⼩写字⺟, 数字, ⼀些特殊字符.
没有中⽂, 8个01代码, 8个bit, 1个byte
2. GBK: 中⽂国标码, ⾥⾯包含了ASCII编码和中⽂常⽤编码. 16个bit, 2个byte
3. UNICODE: 万国码, ⾥⾯包含了全世界所有国家⽂字的编码. 32个bit, 4个byte, 包含了 ASCII
4. UTF-8: 可变⻓度的万国码. 是unicode的⼀种实现. 最⼩字符占8位
1.英⽂: 8bit 1byte
2.欧洲⽂字:16bit 2byte
3.中⽂:24bit 3byte
综上, 除了ASCII码以外, 其他信息不能直接转换.
在python3的内存中. 在程序运⾏阶段. 使⽤的是unicode编码.
因为unicode是万国码. 什么内容都可以进⾏显⽰. 那么在数据传输和存储的时候由于unicode比较浪费空间和资源.
需要把 unicode转存成UTF-8或者GBK进⾏存储. 怎么转换呢.
在python中可以把⽂字信息进⾏编码. 编码之后的内容就可以进⾏传输了.
编码之后的数据是bytes类型的数据.其实啊. 还是原来的 数据只是经过编码之后表现形式发⽣了改变⽽已.
bytes的表现形式:
1. 英⽂ b'alex' 英⽂的表现形式和字符串没什么两样
2. 中⽂ b'\xe4\xb8\xad' 这是⼀个汉字的UTF-8的bytes表现形式
1 2 3 4 5 6 7 8 9 10 11 12 | s = "alex"print(s.encode("utf-8")) # 将字符串编码成UTF-8print(s.encode("GBK")) # 将字符串编码成GBK结果:b'alex'b'alex's = "中"print(s.encode("UTF-8")) # 中⽂编码成UTF-8print(s.encode("GBK")) # 中⽂编码成GBK结果:b'\xe4\xb8\xad'b'\xd6\xd0' |
记住: 英⽂编码之后的结果和源字符串⼀致. 中⽂编码之后的结果根据编码的不同. 编码结果也不同.
我们能看到. ⼀个中⽂的UTF-8编码是3个字节. ⼀个GBK的中⽂编码是2个字节.
编码之后的类型就是bytes类型. 在⽹络传输和存储的时候我们python是保存和存储的bytes 类型.
那么在对⽅接收的时候. 也是接收的bytes类型的数据. 我们可以使⽤decode()来进⾏解 码操作.
把bytes类型的数据还原回我们熟悉的字符串:
1 2 3 4 5 | s = "我叫李嘉诚"print(s.encode("utf-8")) #b'\xe6\x88\x91\xe5\x8f\xab\xe6\x9d\x8e\xe5\x98\x89\xe8\xaf\x9a'print(b'\xe6\x88\x91\xe5\x8f\xab\xe6\x9d\x8e\xe5\x98\x89\xe8\xaf\x9a'.decode("utf-8")) # 解码 |
编码和解码的时候都需要制定编码格式.
1 2 3 4 5 6 7 8 | s = "我是⽂字" bs = s.encode("GBK") # 我们这样可以获取到GBK的⽂字 # 把GBK转换成UTF-8 # ⾸先要把GBK转换成unicode. 也就是需要解码 s = bs.decode("GBK") # 解码 # 然后需要进⾏重新编码成UTF-8 bss = s.encode("UTF-8") # 重新编码 print(bss) |
基础补充#
我们补充给几个数据类型的操作
1 2 3 4 5 6 | lst = [1,2,3,4,5,6]for i in lst: lst.append(7) # 这样写法就会一直持续添加7 print(lst)print(lst) |
列表: 循环删除列表中的每⼀个元素
1 2 3 4 5 6 | li = [11, 22, 33, 44]for e in li: li.remove(e)print(li)结果:[22, 44] |
分析原因: for的运⾏过程. 会有⼀个指针来记录当前循环的元素是哪⼀个, ⼀开始这个指针指向第0 个.
然后获取到第0个元素. 紧接着删除第0个. 这个时候. 原来是第⼀个的元素会⾃动的变成 第0个.
然后指针向后移动⼀次, 指向1元素. 这时原来的1已经变成了0, 也就不会被删除了.
⽤pop删除试试看:
1 2 3 4 5 6 7 | li = [11, 22, 33, 44]for i in range(0, len(li)): del li[i]print(li)结果: 报错# i= 0, 1, 2 删除的时候li[0] 被删除之后. 后⾯⼀个就变成了第0个.# 以此类推. 当i = 2的时候. list中只有⼀个元素. 但是这个时候删除的是第2个 肯定报错啊 |
经过分析发现. 循环删除都不⾏. 不论是⽤del还是⽤remove. 都不能实现. 那么pop呢?
1 2 3 4 5 | for el in li: li.pop() # pop也不⾏print(li)结果:[11, 22] |
只有这样才是可以的:
1 2 3 | for i in range(0, len(li)): # 循环len(li)次, 然后从后往前删除 li.pop()print(li) |
或者. ⽤另⼀个列表来记录你要删除的内容. 然后循环删除
1 2 3 4 5 6 7 8 | li = [11, 22, 33, 44]del_li = []for e in li: del_li.append(e)for e in del_li: li.remove(e)print(li) |
注意: 由于删除元素会导致元素的索引改变, 所以容易出现问题. 尽量不要再循环中直接去删 除元素. 可以把要删除的元素添加到另⼀个集合中然后再批量删除.
dict中的fromkey(),可以帮我们通过list来创建⼀个dict
1 2 3 4 | dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"])print(dic)结果:{'jay': ['周杰伦', '麻花藤'], 'JJ': ['周杰伦', '麻花藤']} |
代码中只是更改了jay那个列表. 但是由于jay和JJ⽤的是同⼀个列表. 所以. 前⾯那个改了. 后面那个也会跟着改
dict中的元素在迭代过程中是不允许进⾏删除的
1 2 3 4 5 6 7 | dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦⽼板'}# 删除key中带有'k'的元素for k in dic: if 'k' in k: del dic[k] # dictionary changed size during iteration, 在循环迭代的时候不允许进⾏删除操作print(dic) |
那怎么办呢? 把要删除的元素暂时先保存在⼀个list中, 然后循环list, 再删除
1 2 3 4 5 6 7 8 9 | dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦⽼板'}dic_del_list = []# 删除key中带有'k'的元素for k in dic: if 'k' in k: dic_del_list.append(k)for el in dic_del_list: del dic[el]print(dic) |
类型转换:
元组 => 列表 list(tuple)
列表 => 元组 tuple(list)
list=>str str.join(list)
str=>list str.split()
转换成False的数据:
0,'',None,[],(),{},set() ==> False
深浅拷贝#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | lst1 = ["⾦⽑狮王", "紫衫⻰王", "⽩眉鹰王", "⻘翼蝠王"]lst2 = lst1print(lst1)print(lst2)lst1.append("杨逍")print(lst1)print(lst2)结果:['⾦⽑狮王', '紫衫⻰王', '⽩眉鹰王', '⻘翼蝠王', '杨逍']['⾦⽑狮王', '紫衫⻰王', '⽩眉鹰王', '⻘翼蝠王', '杨逍']dic1 = {"id": 123, "name": "谢逊"}dic2 = dic1print(dic1)print(dic2)dic1['name'] = "范瑶"print(dic1)print(dic2)结果:{'id': 123, 'name': '谢逊'}{'id': 123, 'name': '谢逊'}{'id': 123, 'name': '范瑶'}{'id': 123, 'name': '范瑶'} |
对于list, set, dict来说, 直接赋值. 其实是把内存地址交给变量. 并不是复制⼀份内容. 所以. lst1的内存指向和lst2是⼀样的. lst1改变了, lst2也发⽣了改变
浅拷⻉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | lst1 = ["何炅", "杜海涛","周渝⺠"]lst2 = lst1.copy()lst1.append("李嘉诚")print(lst1)print(lst2)print(id(lst1), id(lst2))结果:两个lst完全不⼀样. 内存地址和内容也不⼀样. 发现实现了内存的拷⻉lst1 = ["何炅", "杜海涛","周渝⺠", ["麻花藤", "⻢芸", "周笔畅"]]lst2 = lst1.copy()lst1[3].append("⽆敌是多磨寂寞")print(lst1)print(lst2)print(id(lst1[3]), id(lst2[3]))结果:['何炅', '杜海涛', '周渝⺠', ['麻花藤', '⻢芸', '周笔畅', '⽆敌是多磨寂寞']]['何炅', '杜海涛', '周渝⺠', ['麻花藤', '⻢芸', '周笔畅', '⽆敌是多磨寂寞']]4417248328 4417248328 |
浅拷⻉. 只会拷⻉第⼀层. 第⼆层的内容不会拷⻉. 所以被称为浅拷⻉
深拷⻉
1 2 3 4 5 6 7 8 9 10 11 | import copylst1 = ["何炅", "杜海涛","周渝⺠", ["麻花藤", "⻢芸", "周笔畅"]]lst2 = copy.deepcopy(lst1)lst1[3].append("⽆敌是多磨寂寞")print(lst1)print(lst2)print(id(lst1[3]), id(lst2[3]))结果:['何炅', '杜海涛', '周渝⺠', ['麻花藤', '⻢芸', '周笔畅', '⽆敌是多磨寂寞']]['何炅', '杜海涛', '周渝⺠', ['麻花藤', '⻢芸', '周笔畅']]4447221448 4447233800 |
都不⼀样了.
深度拷贝. 把元素内部的元素完全进行拷贝复制. 不会产⽣⼀个改变另⼀个跟着 改变的问题 补充⼀个知识点:
最后我们来看⼀个⾯试题:
1 2 3 | a = [1, 2]a[1] = aprint(a[1]) |
id is ==#
在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址:
1 2 3 | name = 'meet's_id = id(name) # 通过内置方法获取name变量对应的值在内存中的编号print(s_id) # 2055782908568 这就是name在内存中的编号 |
那么 is 是什么? == 又是什么?
== 是比较的两边的数值是否相等,而 is 是比较的两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址。
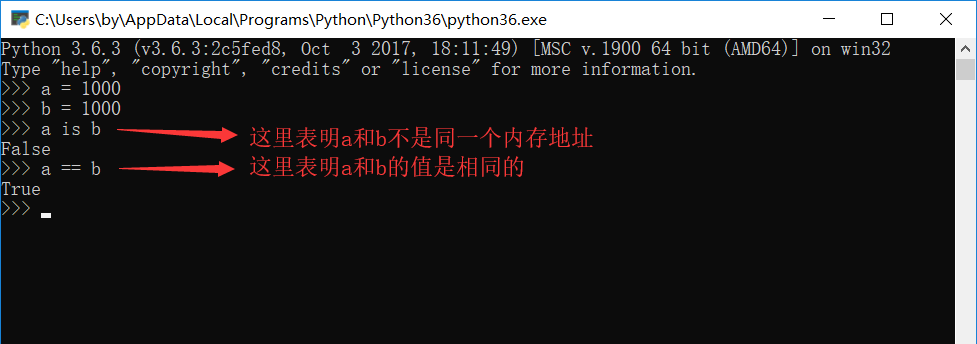
可以说如果内存地址相同,那么值肯定相同,但是如果值相同,内存地址不一定相同,如图:
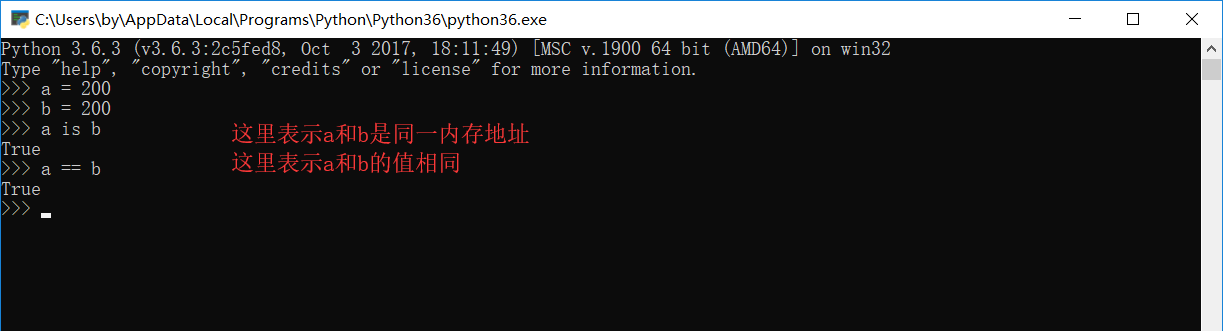
这就很神奇了,刚刚还不是一个内存地址呢,现在怎么又是一个内存地址了,其中神奇之处就是我们的小数据池
小数据池,也称为小整数缓存机制,或者称为驻留机制等等. 那么到底什么是小数据池?他有什么作用呢?
代码块(了解)#
接下来我们学习下小数据池,在学小数据池之前我们来看下代码块
根据提示我们从官方文档找到了这样的说法:
A Python program is constructed from code blocks. A block is a piece of Python program text that is executed as a unit. The following are blocks: a module, a function body, and a class definition. Each command typed interactively is a block. A script file (a file given as standard input to the interpreter or specified as a command line argument to the interpreter) is a code block. A script command (a command specified on the interpreter command line with the ‘-c‘ option) is a code block. The string argument passed to the built-in functions eval() and exec() is a code block.
A code block is executed in an execution frame. A frame contains some administrative information (used for debugging) and determines where and how execution continues after the code block’s execution has completed.
上面的主要意思是:
Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
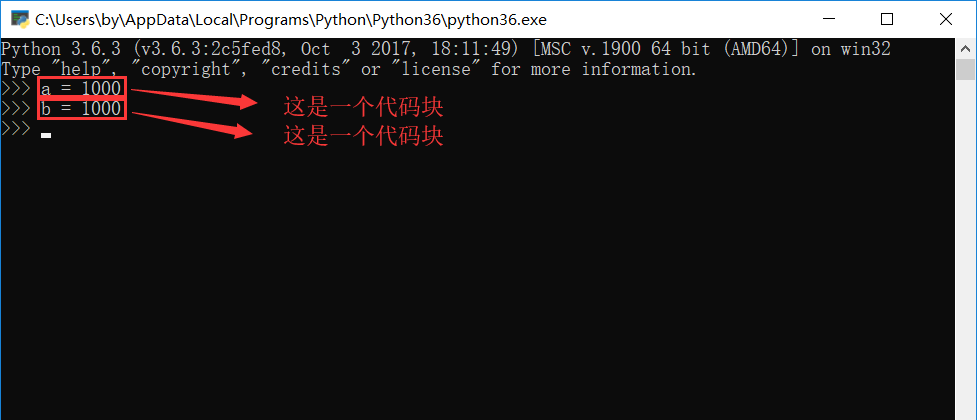
什么叫交互方式?就是咱们在cmd中进入Python解释器里面,每一行代码都是一个代码块,例如:
而对于一个文件中的两个函数,也分别是两个不同的代码块:

OK,那么现在我们了解了代码块,这和小数据池有什么关系呢?且听下面分析。
代码块的缓存机制#
Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。
代码块的缓存机制的适用范围: int(float),str,bool
int(float):任何数字在同一代码块下都会复用。
bool:True和False在字典中会以1,0方式存在,并且复用。
str:几乎所有的字符串都会符合缓存机制,具体规定如下(了解即可!):
1,非乘法得到的字符串都满足代码块的缓存机制:
1 2 3 | s1 = '宝元@!#*ewq's2 = '宝元@!#*ewq'print(s1 is s2) # True |
2,乘法得到的字符串分两种情况:
2.1 乘数小于等于1的时候,任何字符串满足代码块的缓存机制:
1 2 3 | s1 = '好嗨啊,感觉自己身体要到了.932023756QQ932023756'*1s2 = '好嗨啊,感觉自己身体要到了.932023756QQ932023756'*1print(s1 is s2) |
2.2 乘数>=2时:仅含大小写字母,数字,下划线,总长度<=20,满足代码块的缓存机制:
s1 = 'old_' * 5 s2 = 'old_' * 5 print(s1 is s2) # True
优点:能够提高一些字符串,整数处理人物在时间和空间上的性能;需要值相同的字符串,整数的时候,直接从‘字典’中取出复用,避免频繁的创建和销毁,提升效率,节约内存。
小数据池(了解)#
小数据池,也称为小整数缓存机制,或者称为驻留机制等等,博主认为,只要你在网上查到的这些名字其实说的都是一个意思,叫什么因人而异。
那么到底什么是小数据池?他有什么作用呢?
大前提:小数据池也是只针对 int(float),str,bool
小数据池是针对不同代码块之间的缓存机制!!!
官方对于整数,字符串的小数据池是这么说的:
对于整数,Python官方文档中这么说: The current implementation keeps an array of integer objects for all integers between -5 and 256, when you create an int in that range you actually just get back a reference to the existing object. So it should be possible to change the value of 1. I suspect the behaviour of Python in this case is undefined. 对于字符串: Incomputer science, string interning is a method of storing only onecopy of each distinct string value, which must be immutable. Interning strings makes some stringprocessing tasks more time- or space-efficient at the cost of requiring moretime when the string is created or interned. The distinct values are stored ina string intern pool. –引自维基百科
来,我给你们翻译并汇总一下,这个表达的意思就是:
Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个。
优点:能够提高一些字符串,整数处理人物在时间和空间上的性能;需要值相同的字符串,整数的时候,直接从‘池’里拿来用,避免频繁的创建和销毁,提升效率,节约内存。
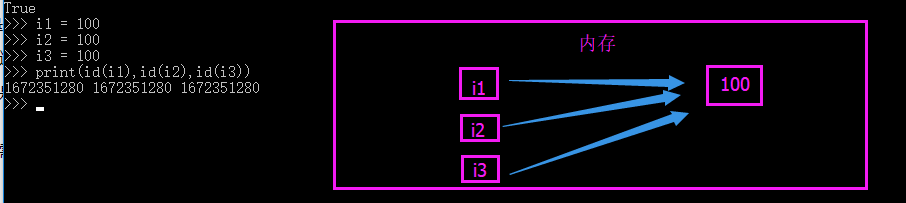
int:那么大家都知道对于整数来说,小数据池的范围是-5~256 ,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。
那么对于字符串的规定呢?
str:字符串要从下面这几个大方向讨论(了解即可!):
1,字符串的长度为0或者1,默认都采用了驻留机制(小数据池)。


2,字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。

3,用乘法得到的字符串,分两种情况。
3.1 乘数小于等于1时:
仅含大小写字母,数字,下划线,默认驻留。

含其他字符,长度<=1,默认驻留。

3.2 乘数>=2时:
仅含大小写字母,数字,下划线,总长度<=20,默认驻留。

4,指定驻留。
from sys import intern
a = intern('hello!@'*20)
b = intern('hello!@'*20)
print(a is b)
#指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
满足以上字符串的规则时,就符合小数据池的概念。
bool值就是True,False,无论你创建多少个变量指向True,False,那么他在内存中只存在一个。
看一下用了小数据池(驻留机制)的效率有多高:
显而易见,节省大量内存在字符串比较时,非驻留比较效率o(n),驻留时比较效率o(1)。

小结#
如果在同一代码块下,则采用同一代码块下的换缓存机制。
如果是不同代码块,则采用小数据池的驻留机制。
# pycharm 通过运行文件的方式执行下列代码: 这是在同一个文件下也就是同一代码块下,采用同一代码块下的缓存机制。 i1 = 1000 i2 = 1000 print(i1 is i2) # 结果为True 因为代码块下的缓存机制适用于所有数字
通过交互方式中执行下面代码: # 这是不同代码块下,则采用小数据池的驻留机制。 >>> i1 = 1000 >>> i2 = 1000 >>> print(i1 is i2) False # 不同代码块下的小数据池驻留机制 数字的范围只是-5~256.
更多验证:
1 2 3 4 5 6 7 8 9 10 11 | # 虽然在同一个文件中,但是函数本身就是代码块,所以这是在两个不同的代码块下,不满足小数据池(驻存机制),则指向两个不同的地址。def func(): i1 = 1000 print(id(i1)) # 2288555806672def func2(): i1 = 1000 print(id(i1)) # 2288557317392func()func2() |




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· 一文掌握DeepSeek本地部署+Page Assist浏览器插件+C#接口调用+局域网访问!全攻略