Python自定义模块
Python 自定义模块
一.自定义模块
我们今天来学习一下自定义模块(也就是私人订制),我们要自定义模块,首先就要知道什么是模块啊
一个函数封装一个功能,比如现在有一个软件,不可能将所有程序都写入一个文件,所以咱们应该分文件,组织结构要好,代码不冗余,所以要分文件,但是分文件,分了5个文件,每个文件里面可能都有相同的功能(函数),怎么办?所以将这些相同的功能封装到一个文件中.
模块就是文件,存放一堆函数,谁用谁拿。怎么拿?
比如:我要策马奔腾共享人世繁华,应该怎么样?我应该骑马,你也要去浪,你是不是也要骑马。
模块是一系列常用功能的集合体,一个py文件就是一个模块
为什么要使用模块?
1、从文件级别组织程序,更方便管理
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用
2、拿来主义,提升开发效率
同样的原理,我们也可以下载别人写好的模块然后导入到自己的项目中使用,这种拿来主义,可以极大地提升我们的开发效率,避免重复造轮子。
print('from the meet.py')
name = '太白金星'
def read1():
print('meet模块:',name)
def read2():
print('meet模块')
read1()
def change():
global name
name = 'barry'
1.1 import
import 翻译过来是一个导入的意思
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句),如下
import spam #只在第一次导入时才执行spam.py内代码,此处的显式效果是只打印一次'from the spam.py',当然其他的顶级代码也都被执行了,只不过没有显示效果.
代码示例:
import meet
import meet
import meet
import meet
import meet
执行结果:只是打印一次:
from the meet.py
1.2 第一次导入模块执行事件
1.为源文件(meet模块)创建新的名称空间,在meet中定义的函数和方法若是使用到了global时访问的就是这个名称空间。
2.创建名字meet来引用该命名空间
这个名字和变量名没什么区别,都是‘第一类的’,且使用meet.名字的方式
可以访问meet.py文件中定义的名字,meet.名字与test.py中的名字来自
两个完全不同的地方。
ps:重复导入会直接引用内存中已经加载好的结果
1.3 被导入模块有独立的名称空间
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
示例:
当前是meet.py
import meet.py
name = 'alex'
print(name)
print(meet.name)
'''
from the meet.py
alex
太白金星
'''
def read1():
print(666)
meet.read1()
'''
from the meet.py
meet模块: 太白金星
'''
name = '日天'
meet.change()
print(name)
print(meet.name)
'''
from the meet.py
日天
barry
'''
1.4 为模块起别名
别名其实就是一个绰号,好处可以将很长的模块名改成很短,方便使用.
import meet.py as t
t.read1()
有利于代码的扩展和优化
#mysql.py
def sqlparse():
print('from mysql sqlparse')
#oracle.py
def sqlparse():
print('from oracle sqlparse')
#test.py
db_type=input('>>: ')
if db_type == 'mysql':
import mysql as db
elif db_type == 'oracle':
import oracle as db
db.sqlparse()
1.5 导入多个模块
import os,sys,json 这样写可以但是不推荐
推荐写法
import os
import sys
import json
多行导入 易于阅读 易于编辑 易于搜索 易于维护
1.6 from ... import ...
from...import...使用
from meet import name, read1
print(name)
read1()
'''
执行结果:
from the meet.py
太白金星
meet模块: 太白金星
'''
1.7 from...import... 与import对比
唯一的区别就是:使用from...import...则是将spam中的名字直接导入到当前的名称空间中,所以在当前名称空间中,直接使用名字就可以了、无需加前缀:meet.
from...import...的方式有好处也有坏处
好处:使用起来方便了
坏处:容易与当前执行文件中的名字冲突
示例演示:
1.7.1 执行文件有与模块同名的变量或者函数名,会有覆盖效果。
name = 'oldboy'
from meet import name, read1, read2
print(name)
'''
执行结果:
太白金星
'''
----------------------------------------
from meet import name, read1, read2
name = 'oldboy'
print(name)
'''
执行结果:
oldboy
'''
----------------------------------------
def read1():
print(666)
from meet import name, read1, read2
read1()
'''
执行结果:
meet模块: 太白金星
'''
----------------------------------------
from meet import name, read1, read2
def read1():
print(666)
read1()
'''
执行结果:
meet模块: 666
'''
1.7.2 当前位置直接使用read1和read2就好了 执行时,仍然以spam.py文件全局名称空间
#测试一:导入的函数read1,执行时仍然回到meet.py中寻找全局变量money
#test.py
from meet import read1
name = 'alex'
read1()
'''
执行结果:
from the spam.py
spam->read1->name = '太白金星'
'''
#测试二:导入的函数read2,执行时需要调用read1(),仍然回到meet.py中找read1()
#test.py
from meet import read2
def read1():
print('==========')
read2()
'''
执行结果:
from the meet.py
meet->read2 calling read
meet->read1->meet 'barry'
'''
1.8 也支持as
from meet import read1 as read
read()
1.9 一行导入多个
from meet import read1,read2,name
1.10 from ... import *
#from spam import * 把spam中所有的不是以下划线(_)开头的名字都导入到当前位置
#大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
可以使用__all__来控制*(用来发布新版本),在meet.py中新增一行
__all__=['money','read1'] #这样在另外一个文件中用from spam import *就这能导入列表中规定的两个名字
二.模块的搜索路径
模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
#模块的查找顺序
1、在第一次导入某个模块时(比如spam),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用
ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看
2、如果没有,解释器则会查找同名的内置模块
3、如果还没有找到就从sys.path给出的目录列表中依次寻找spam.py文件。
#需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。虽然每次都说,但是仍然会有人不停的犯错。
#在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。
>>> import sys
>>> sys.path.append('/a/b/c/d')
>>> sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索
注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理,
#首先制作归档文件:zip module.zip foo.py bar.py
import sys
sys.path.append('module.zip')
# sys.path获取到的是一个列表.所以我们可以执行列表的操作
import foo
import bar
#也可以使用zip中目录结构的具体位置
sys.path.append('module.zip/lib/python')
#windows下的路径不加r开头,会语法错误
sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\a')
三. time模块
time翻译过来就是时间,有我们其实在之前编程的时候有用到过.
#常用方法
1.time.sleep(secs)
(线程)推迟指定的时间运行。单位为秒。
2.time.time()
获取当前时间戳
在计算中时间共有三种方式:
1.时间戳: 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型
2.格式化字符串时间: 格式化的时间字符串(Format String): ‘1999-12-06’
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
3.结构化时间:元组(struct_time) struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)

首先,我们先导入time模块,来认识一下python中表示时间的几种格式:
#导入时间模块
>>>import time
#时间戳
>>>time.time()
1500875844.800804
#时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04'
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24,
tm_hour=13, tm_min=59, tm_sec=37,
tm_wday=0, tm_yday=205, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
时间格式转换:
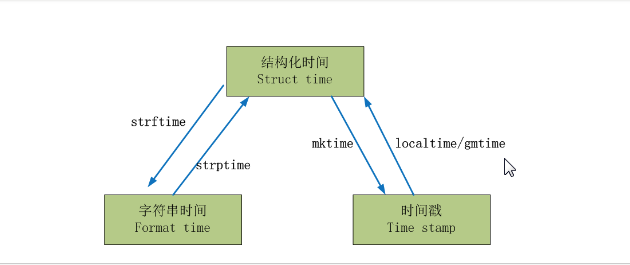
#时间戳-->结构化时间
#time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致
#time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
>>>time.gmtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
>>>time.localtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
#结构化时间-->时间戳
#time.mktime(结构化时间)
>>>time_tuple = time.localtime(1500000000)
>>>time.mktime(time_tuple)
1500000000.0
#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime(1500000000))
'2017-07-14'
#字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
>>>time.strptime("07/24/2017","%m/%d/%Y")
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
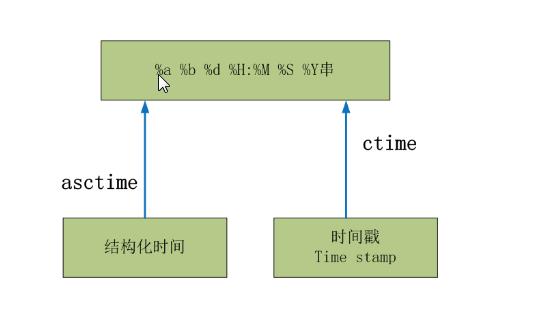
#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
>>>time.asctime(time.localtime(1500000000))
'Fri Jul 14 10:40:00 2017'
>>>time.asctime()
'Mon Jul 24 15:18:33 2017'
#时间戳 --> %a %b %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
>>>time.ctime()
'Mon Jul 24 15:19:07 2017'
>>>time.ctime(1500000000)
'Fri Jul 14 10:40:00 2017'
计算时间差:
import time
true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S'))
time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S'))
dif_time=time_now-true_time
struct_time=time.gmtime(dif_time)
print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1,
struct_time.tm_mday-1,struct_time.tm_hour,
struct_time.tm_min,struct_time.tm_sec))
我们看完了time在来看一个Python处理日期和时间的标准库
四. 获取当前日期和时间
from datetime import datetime
print(datetime.now())
'''
结果:2018-12-04 21:07:48.734886
'''
注意:datetime是模块,datetime模块还包含一个datetime的类,通过from datetime import datetime导入的才是datetime这个类。
如果仅导入import datetime,则必须引用全名datetime.datetime。
datetime.now()返回当前日期和时间,其类型是datetime。
7.1 获取指定日期和时间
要指定某个日期和时间,我们直接用参数构造一个datetime:
from datetime import datetime
dt = datetime(2018,5,20,13,14)
print(dt)
'''
结果:2018-05-20 13:14:00
'''
7.2 datetime转换为timestamp(时间戳)
from datetime import datetime
dt = datetime.now()
new_timestamp = dt.timestamp()
print(new_timestamp)
'''
结果:1543931750.415896
'''
7.3 timestamp转换为datetime
import time
from datetime import datetime
new_timestamp = time.time()
print(datetime.fromtimestamp(new_timestamp))
7.4 str转换为datetime
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
from datetime import datetime
t = datetime.strptime('2018-4-1 00:00','%Y-%m-%d %H:%M')
print(t)
'''
结果: 2018-04-01 00:00:00
'''
7.5 datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:
from datetime import datetime
now = datetime.now()
print(now.strftime('%a, %b %d %H:%M'))
Mon, May 05 16:28
7.6 datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
from datetime import datetime, timedelta
now = datetime.now()
now
datetime.datetime(2015, 5, 18, 16, 57, 3, 540997)
now + timedelta(hours=10)
datetime.datetime(2015, 5, 19, 2, 57, 3, 540997)
now - timedelta(days=1)
datetime.datetime(2015, 5, 17, 16, 57, 3, 540997)
now + timedelta(days=2, hours=12)
datetime.datetime(2015, 5, 21, 4, 57, 3, 540997)
可见,使用timedelta你可以很容易地算出前几天和后几天的时刻。
7.7 小结
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。
如果要存储datetime,最佳方法是将其转换为timestamp再存储,因为timestamp的值与时区完全无关。

