Python运算符
Python 运算符
一、while循环
while 循环
在生活中,我们遇到过循环的事情吧?比如循环听歌。在程序中,也是存才的,这就是流程控制语句 while
基本循环
while 条件:
# 循环体
# 如果条件为真,那么循环则执行
# 如果条件为假,那么循环不执行
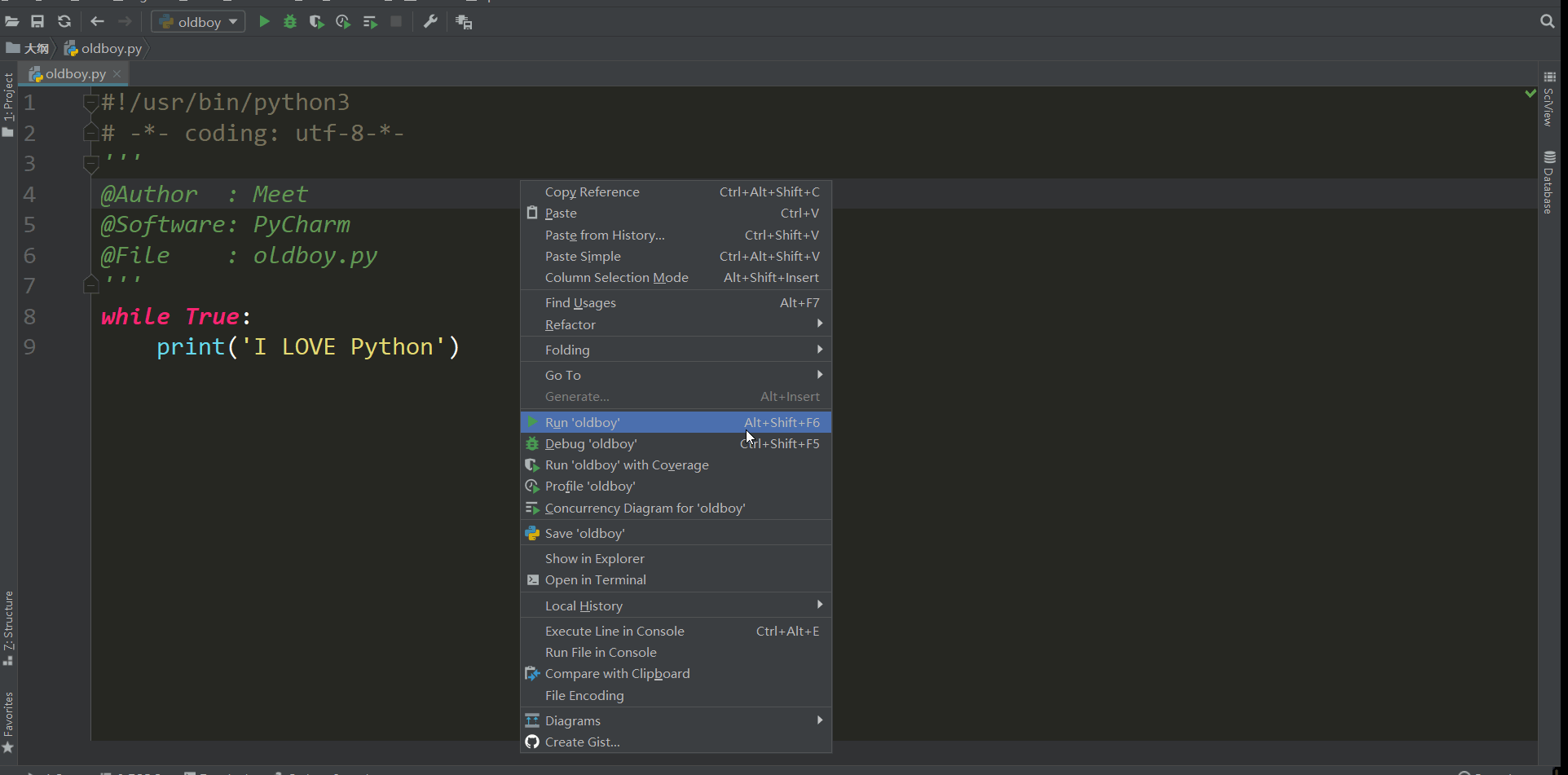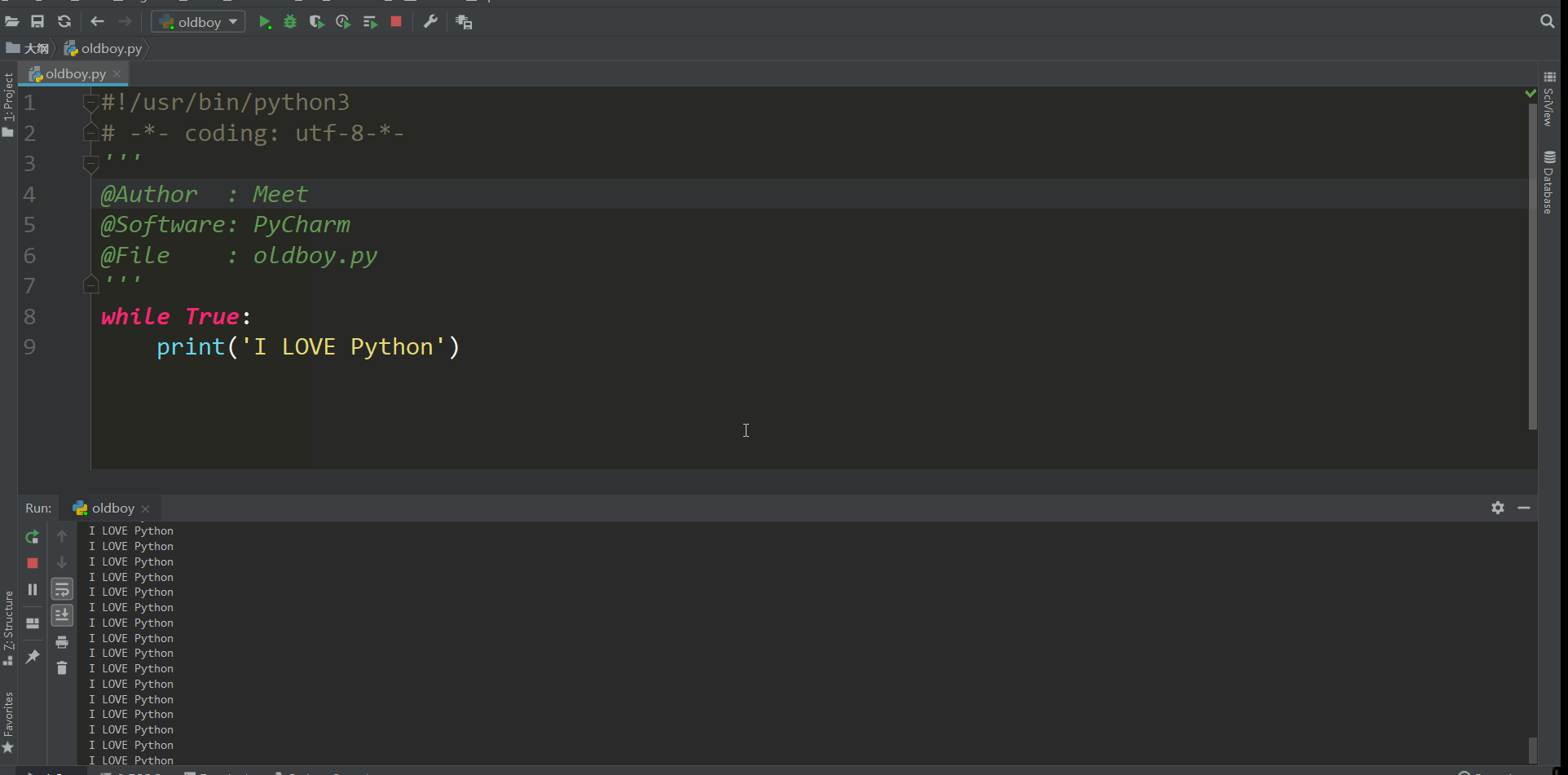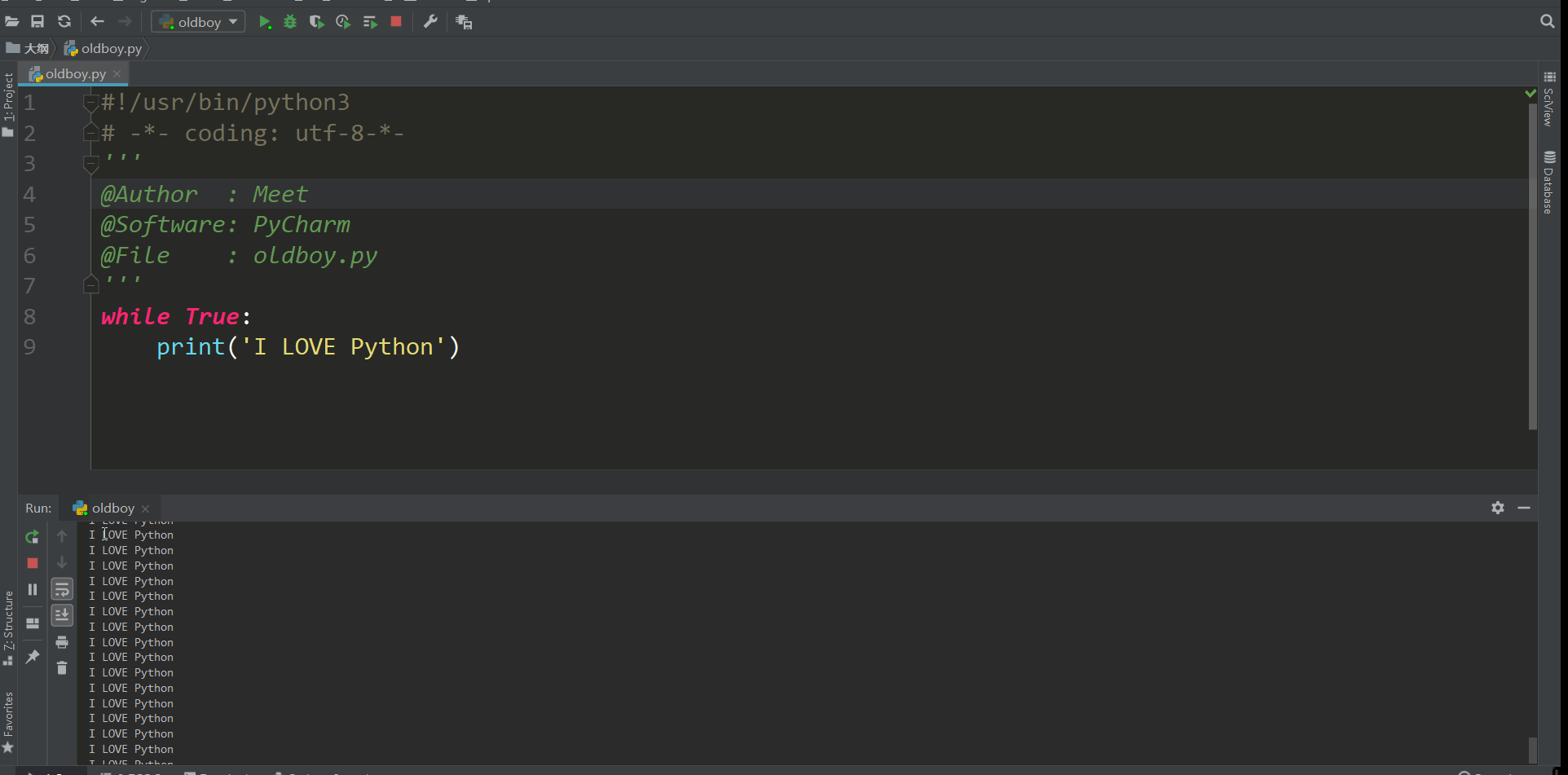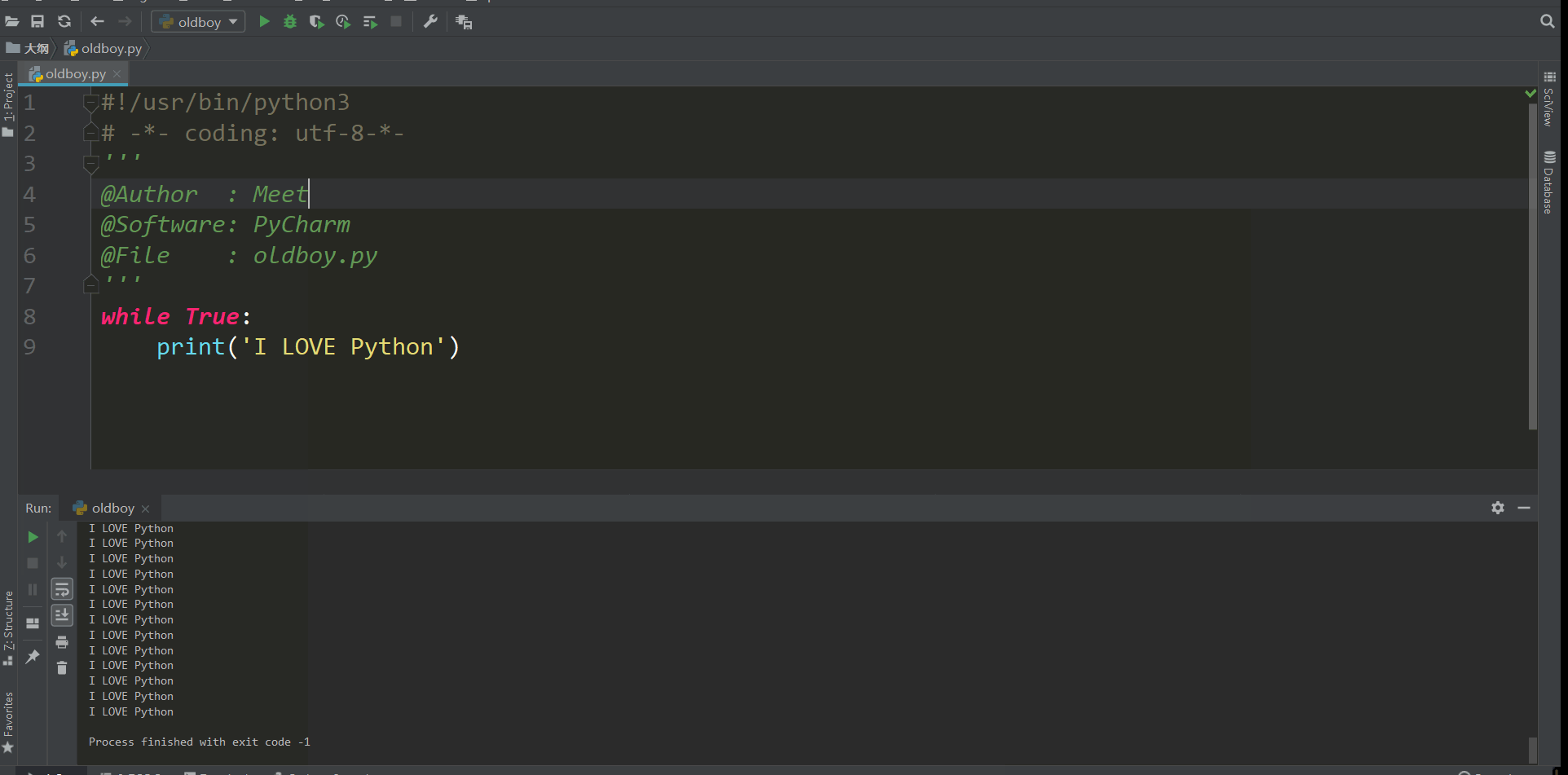
条件如果为真就会一直执行下去 也就人们常说的死循环,我们想要停止就点那个红色的方块
我们可以使用while循环进行内容循环,我们可以尝试使用while循环来计数
使用while计数
count = 0
while True:
count = count + 1
print(count)
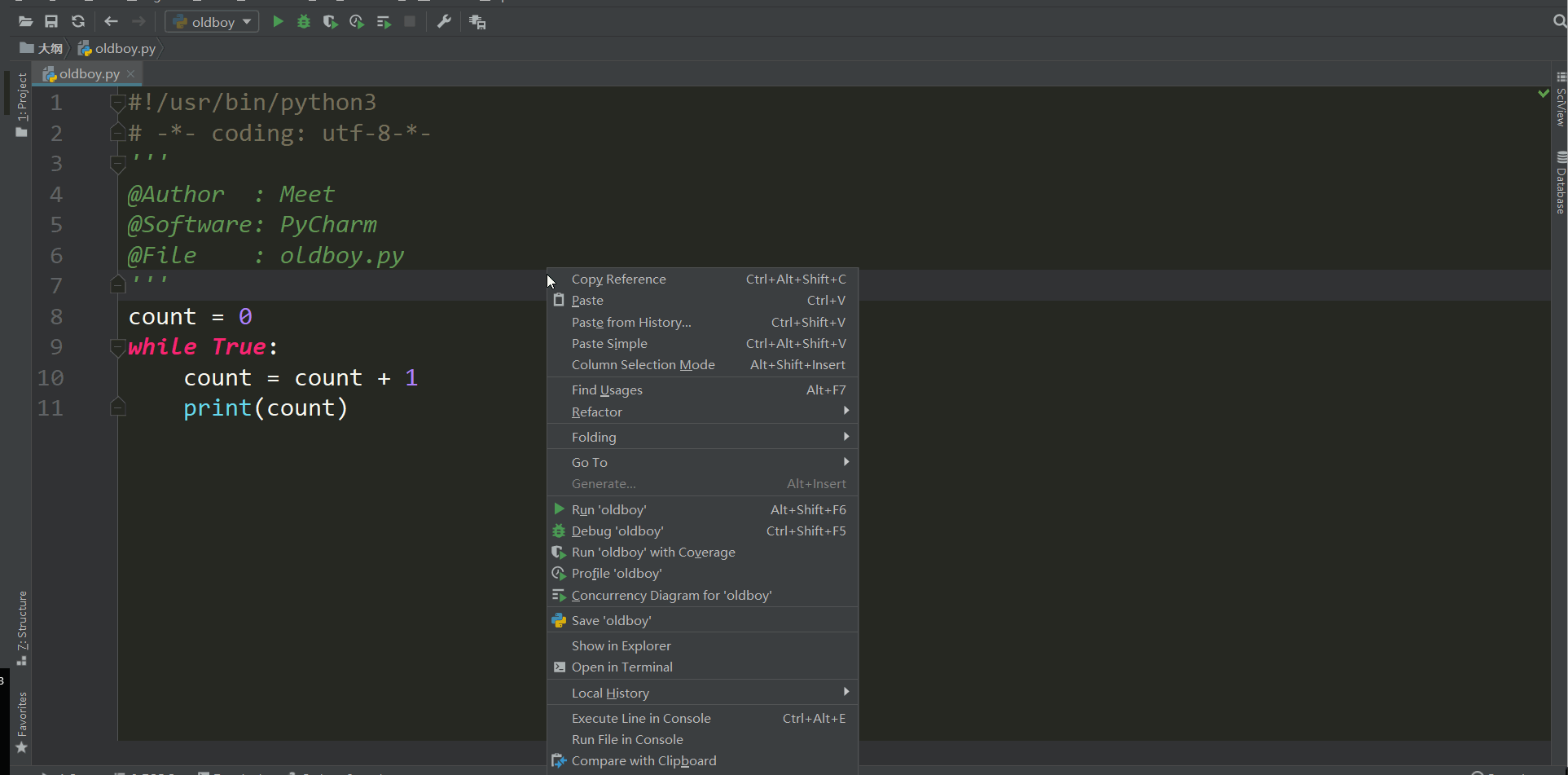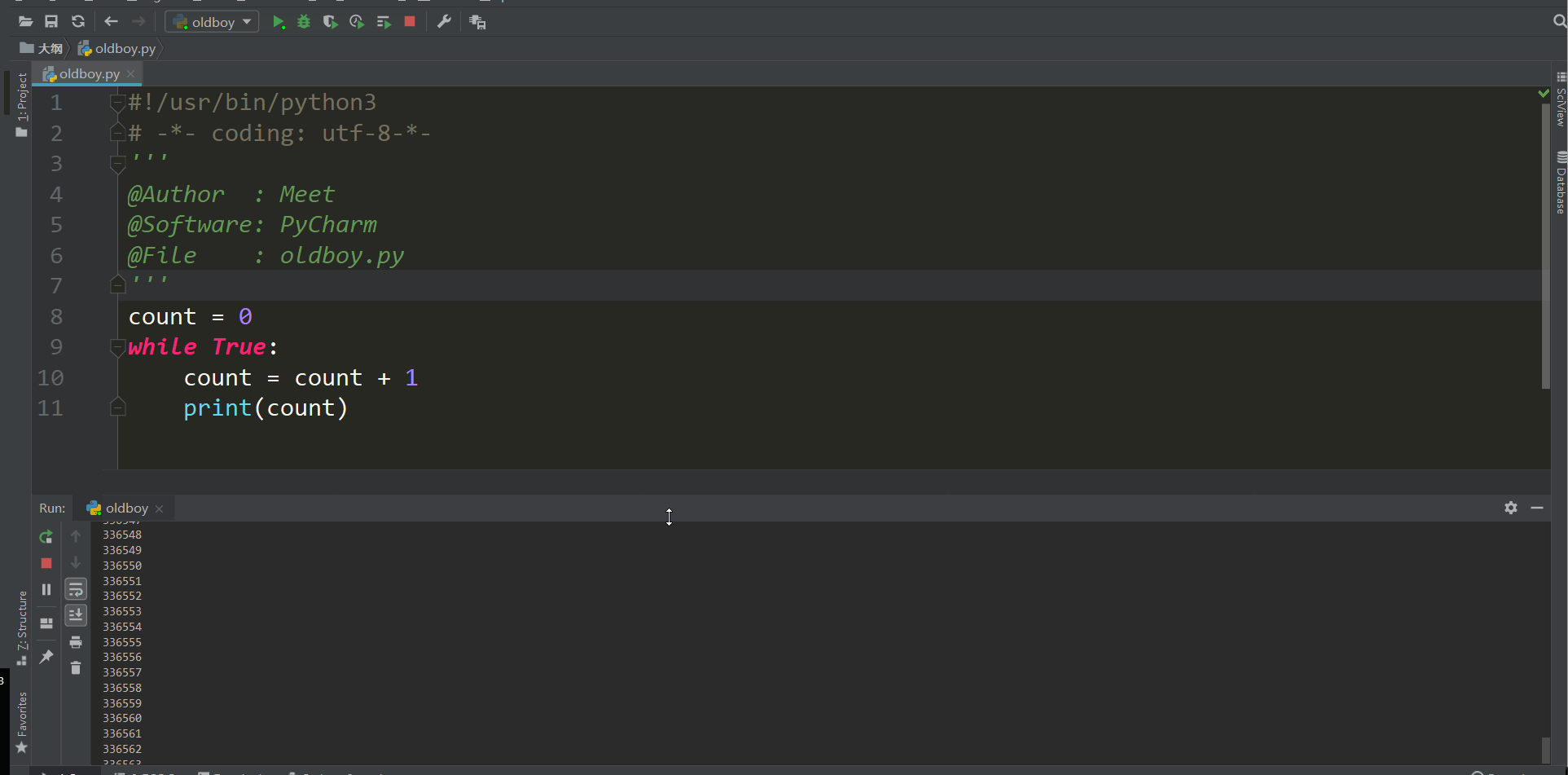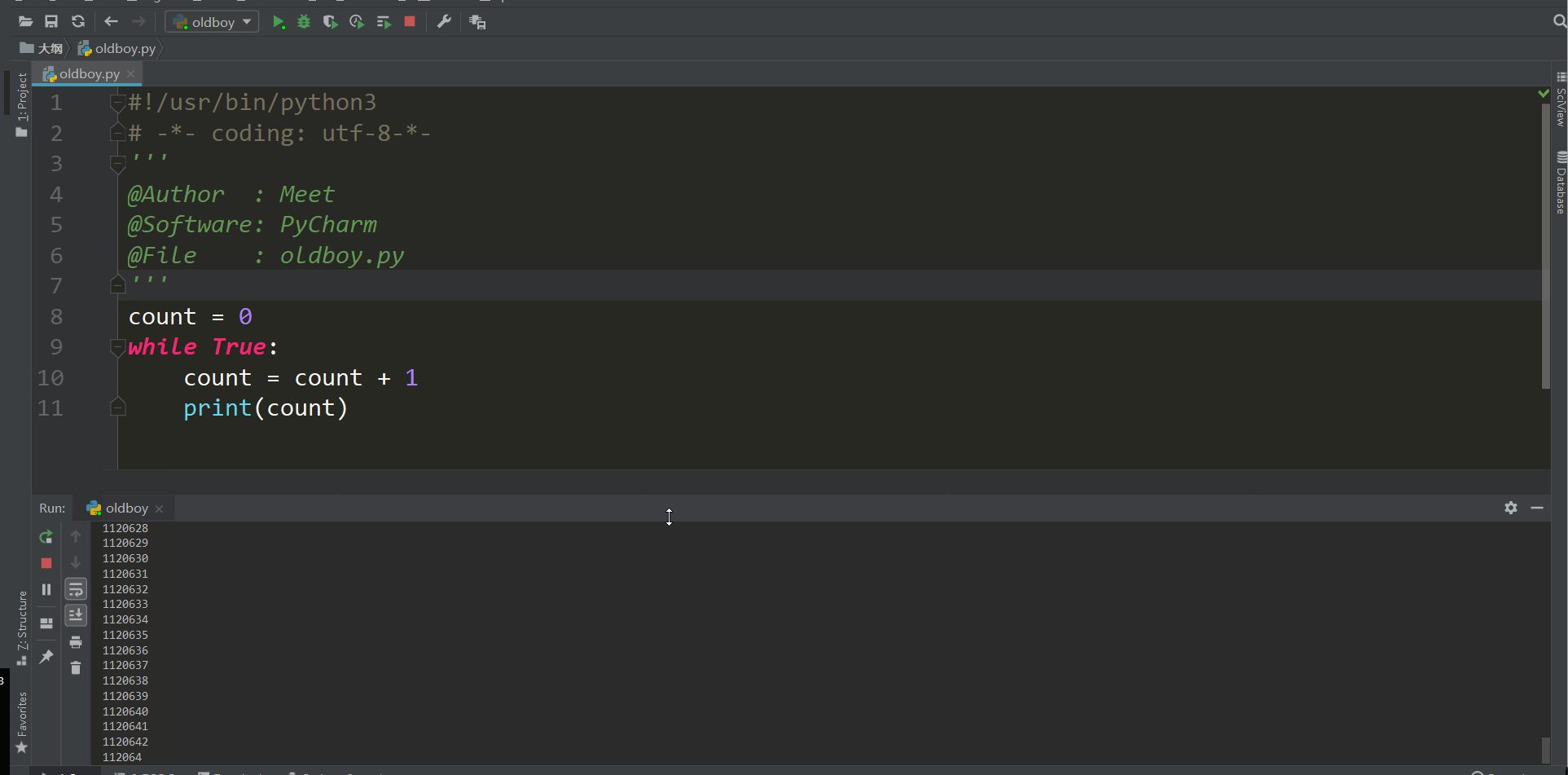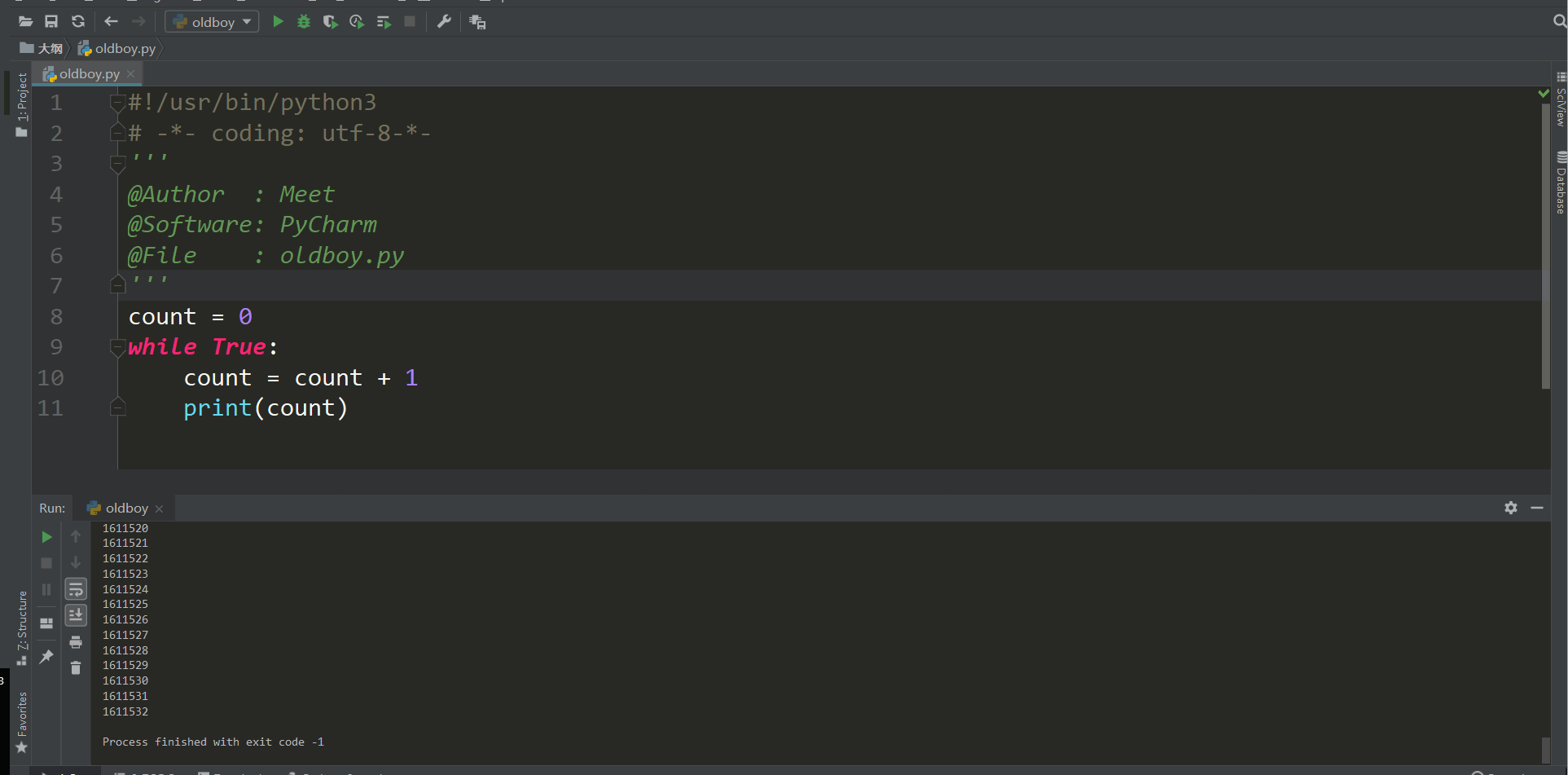
这样下去我就会执行下去,但是我想到100就停了
控制while循环的次数
count = 0
while count < 100:
count = count + 1
print(count)

while 关键后边的是条件,这样就可以通过条件成功的控制住循环的次数
break关键字
我们除了可以使用条件能够让循环停止,其实Python还给我们提供了一个break关键字来停止循环
num = 1
while num <6:
print(num)
num+=1
break
print("end")
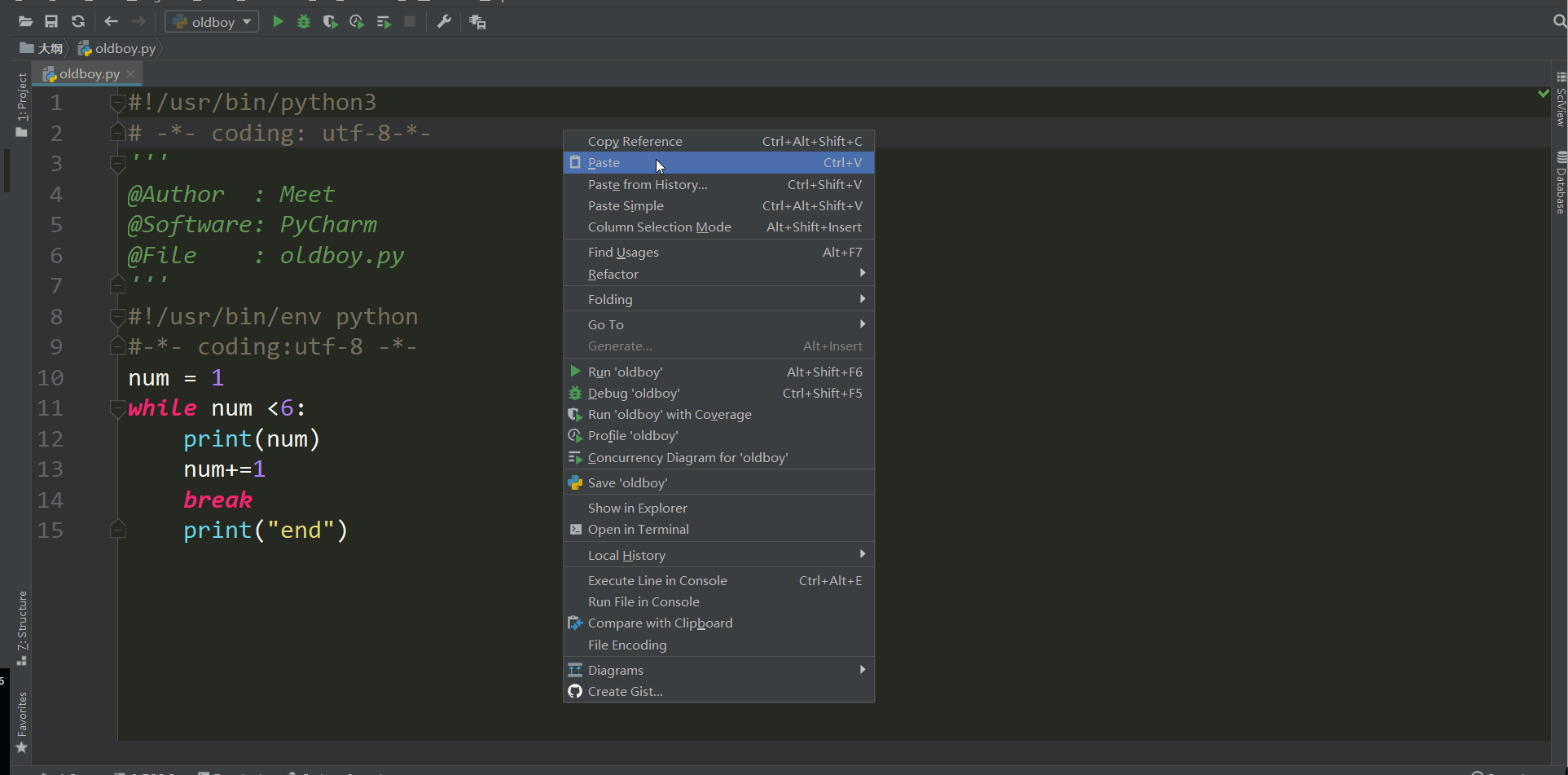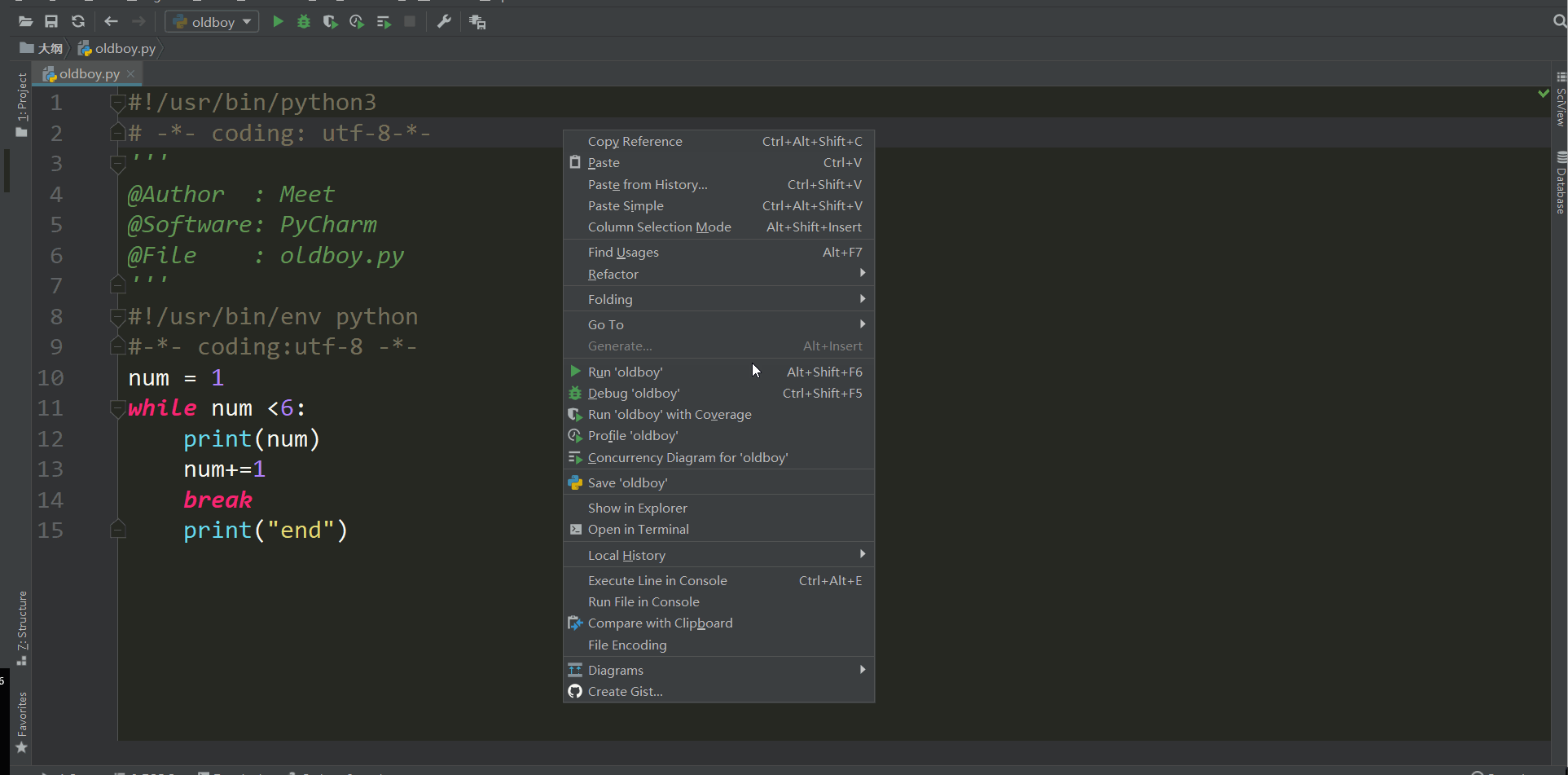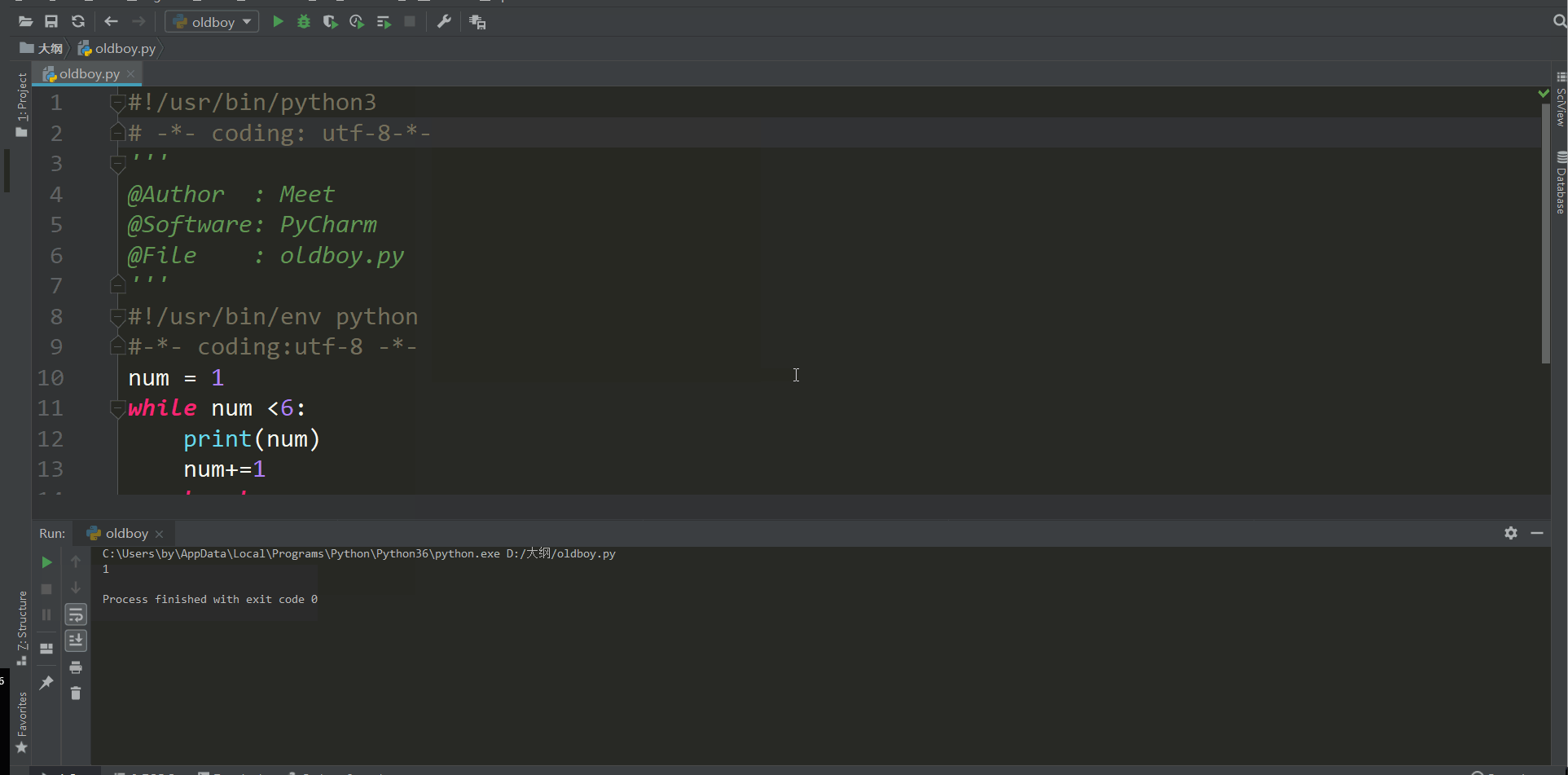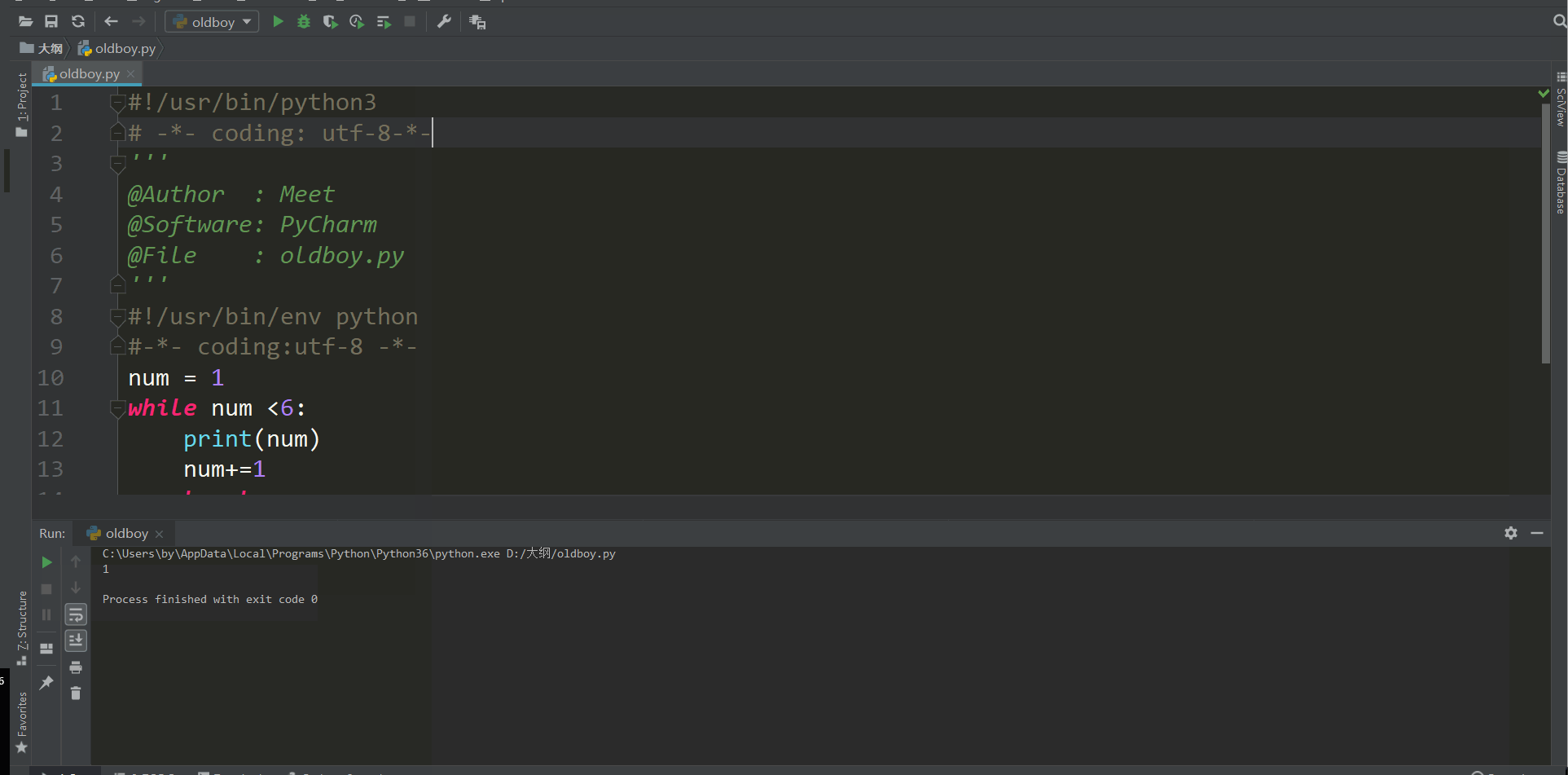
当程序执行到break的时候就结束了.break就是结束当前这个while循环的 break以下的代码都不执行
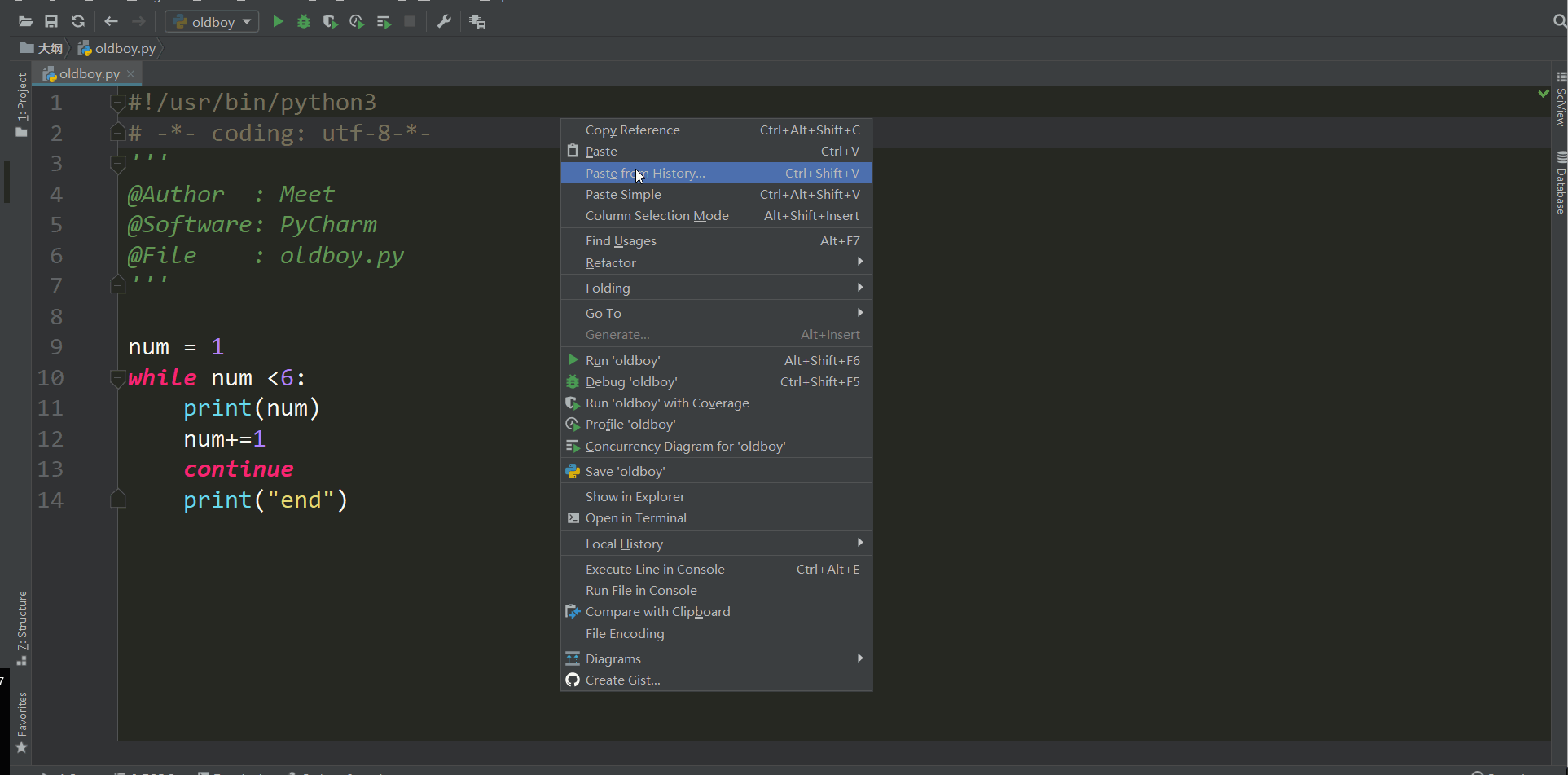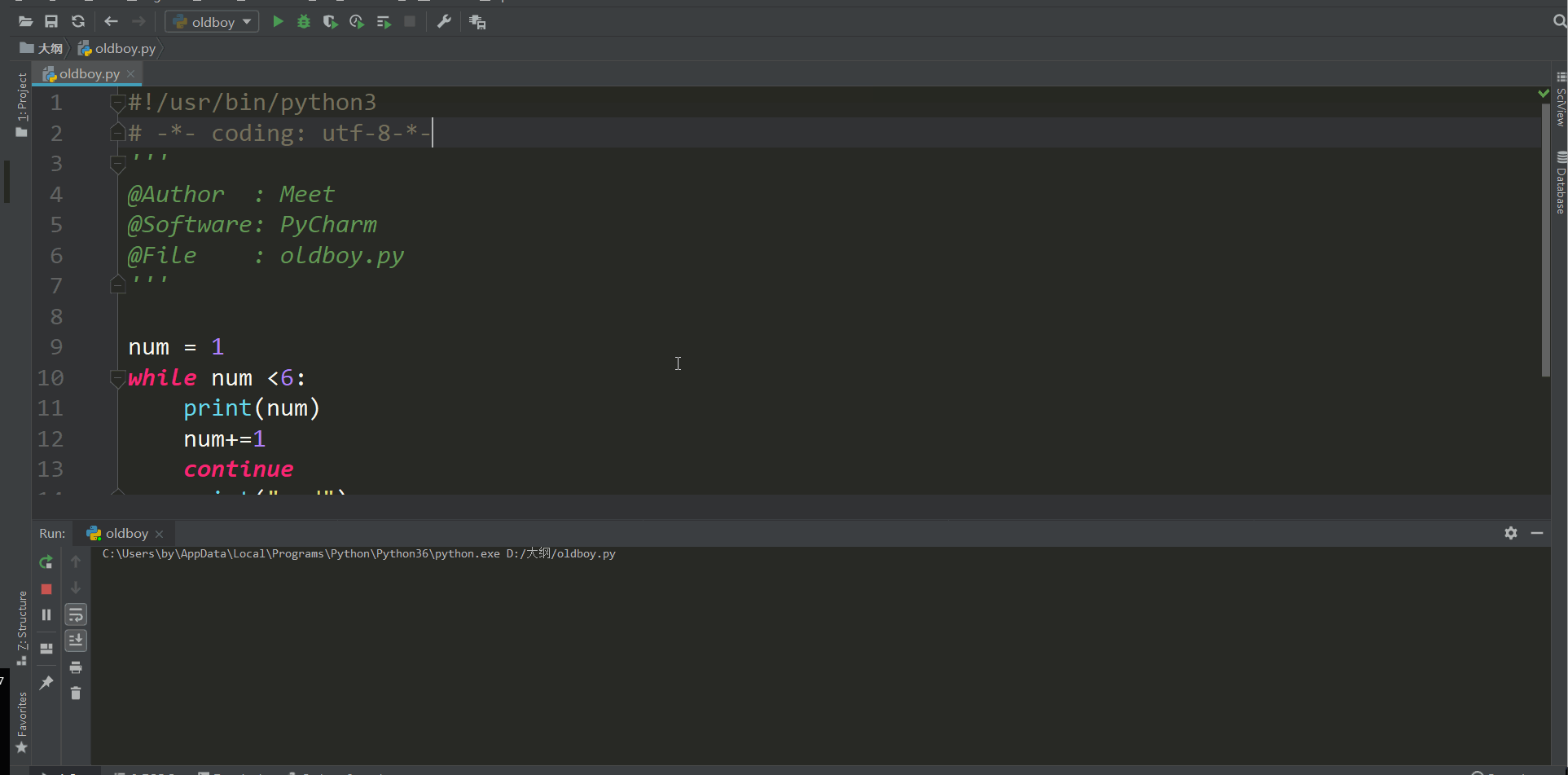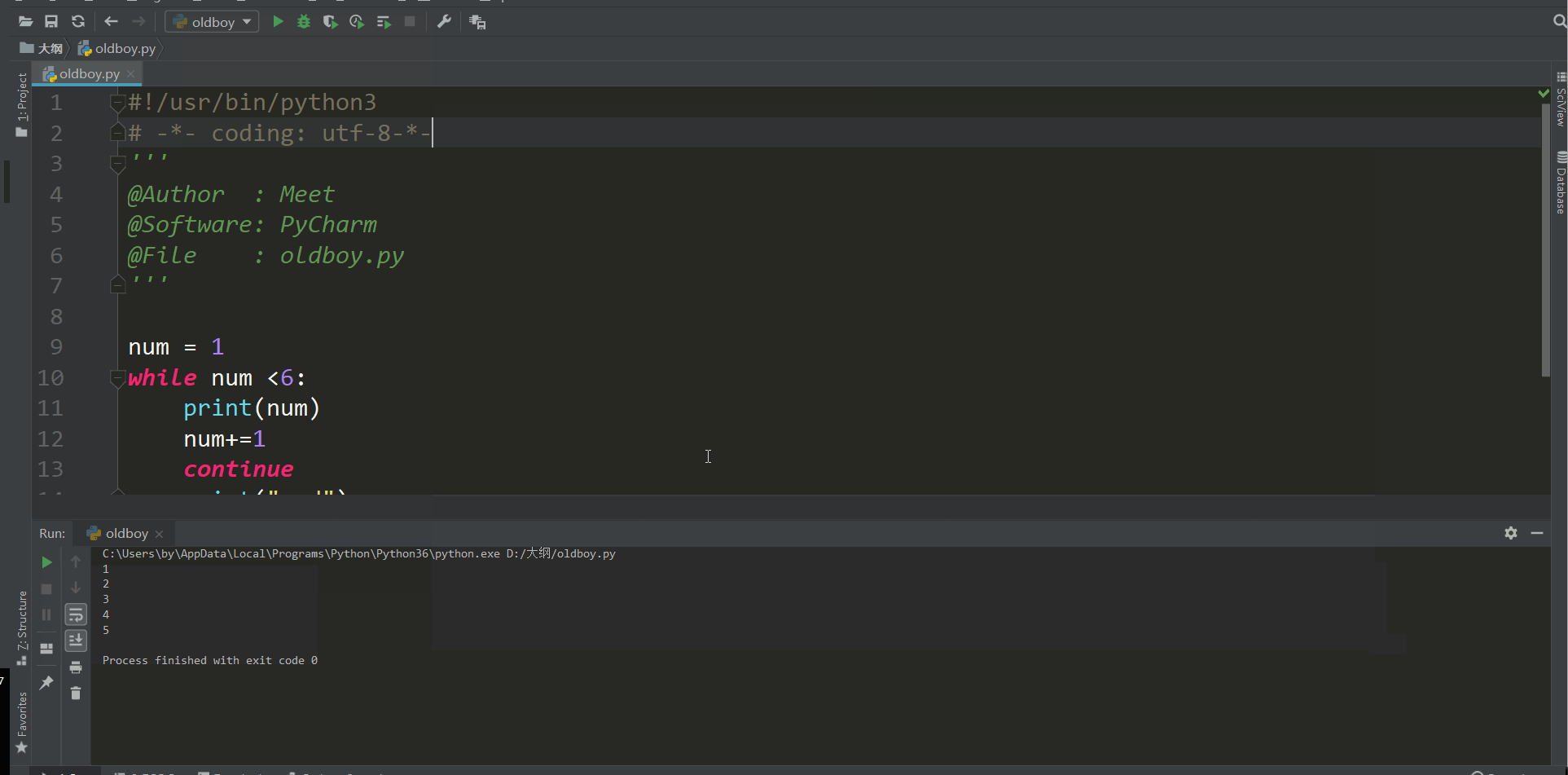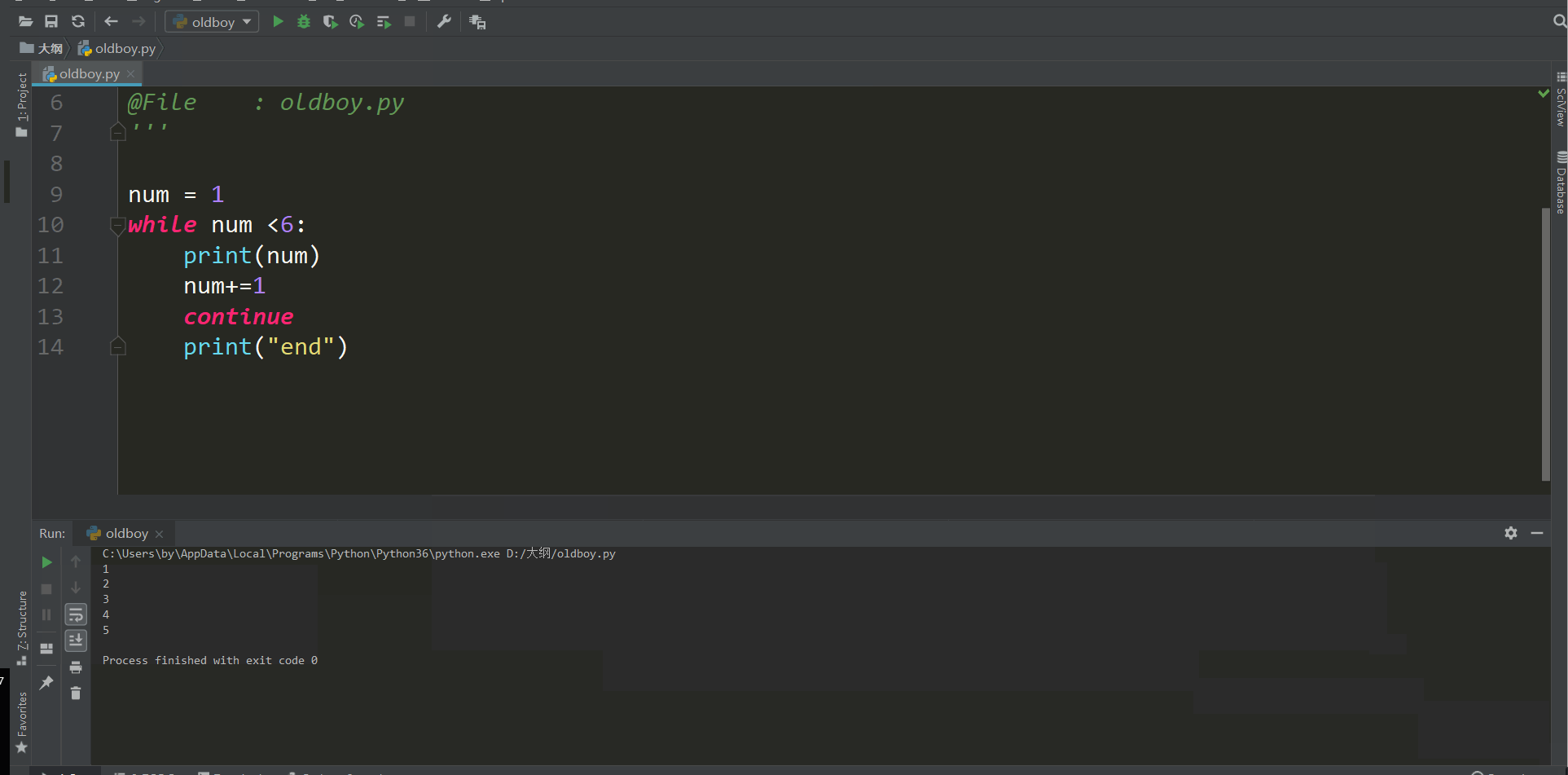
continue关键字
continue 用于退出当前循环,继续下一次循环
num = 1
while num <6:
print(num)
num+=1
continue
print("end")
while else使用
# 循环一
while True:
if 3 > 2:
print('你好')
break
else:
print('不好')
# 循环二
while True:
if 3 > 2:
print('你好')
print('不好')
# 大家看到的这个是不是感觉效果是一样的啊,其实不然
# 当上边的代码执行到break的时候else缩进后的内容不会执行
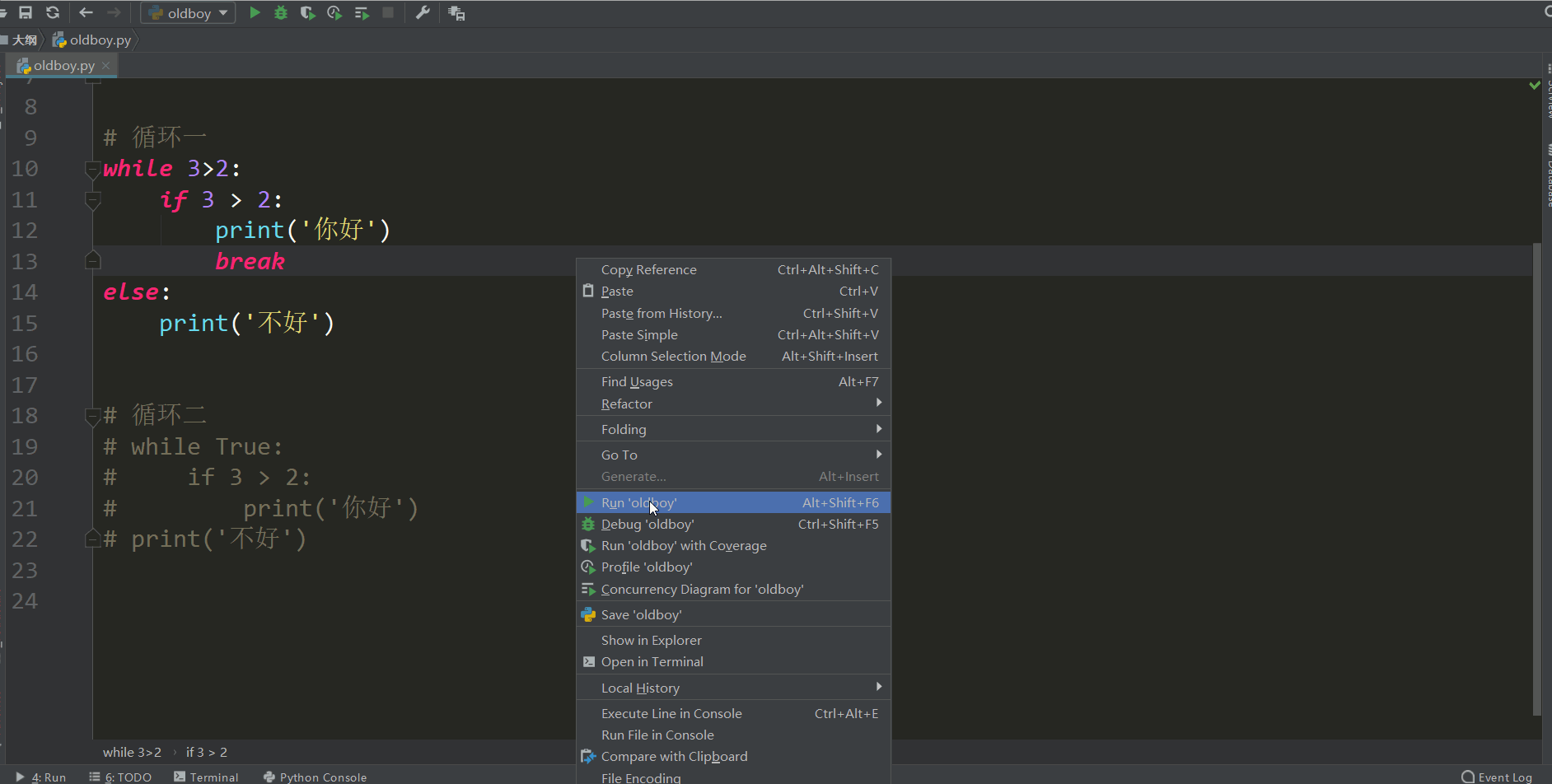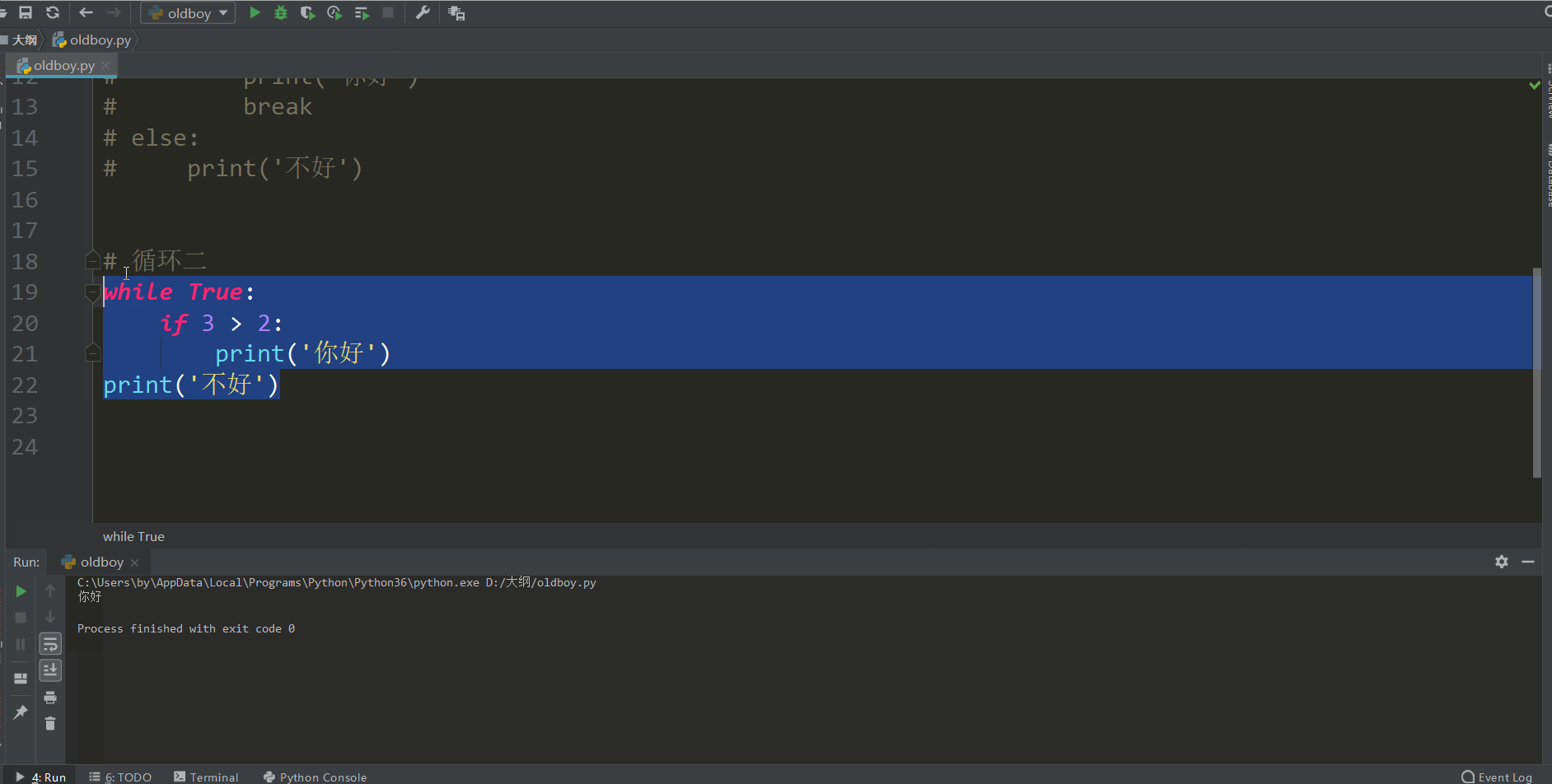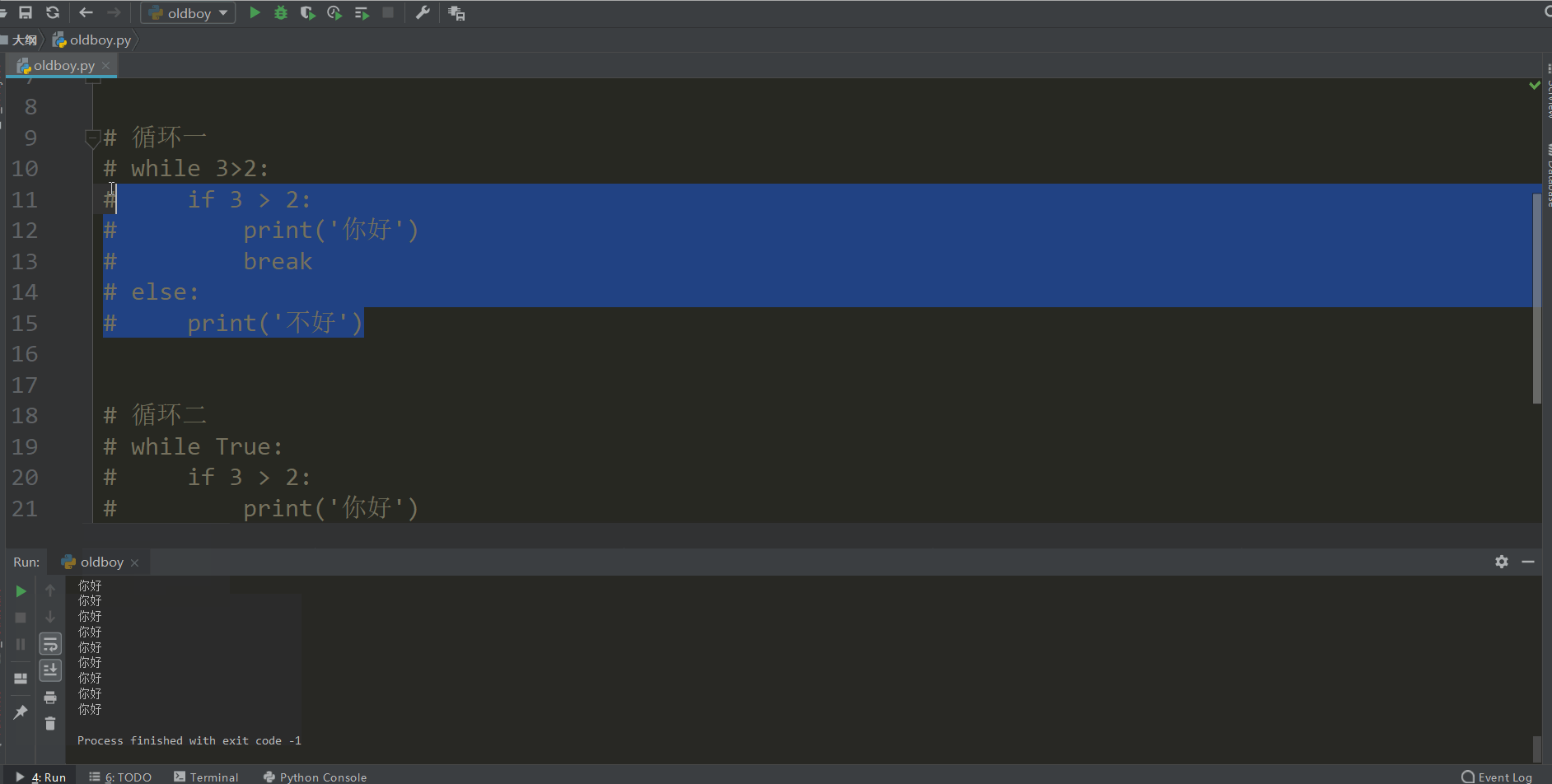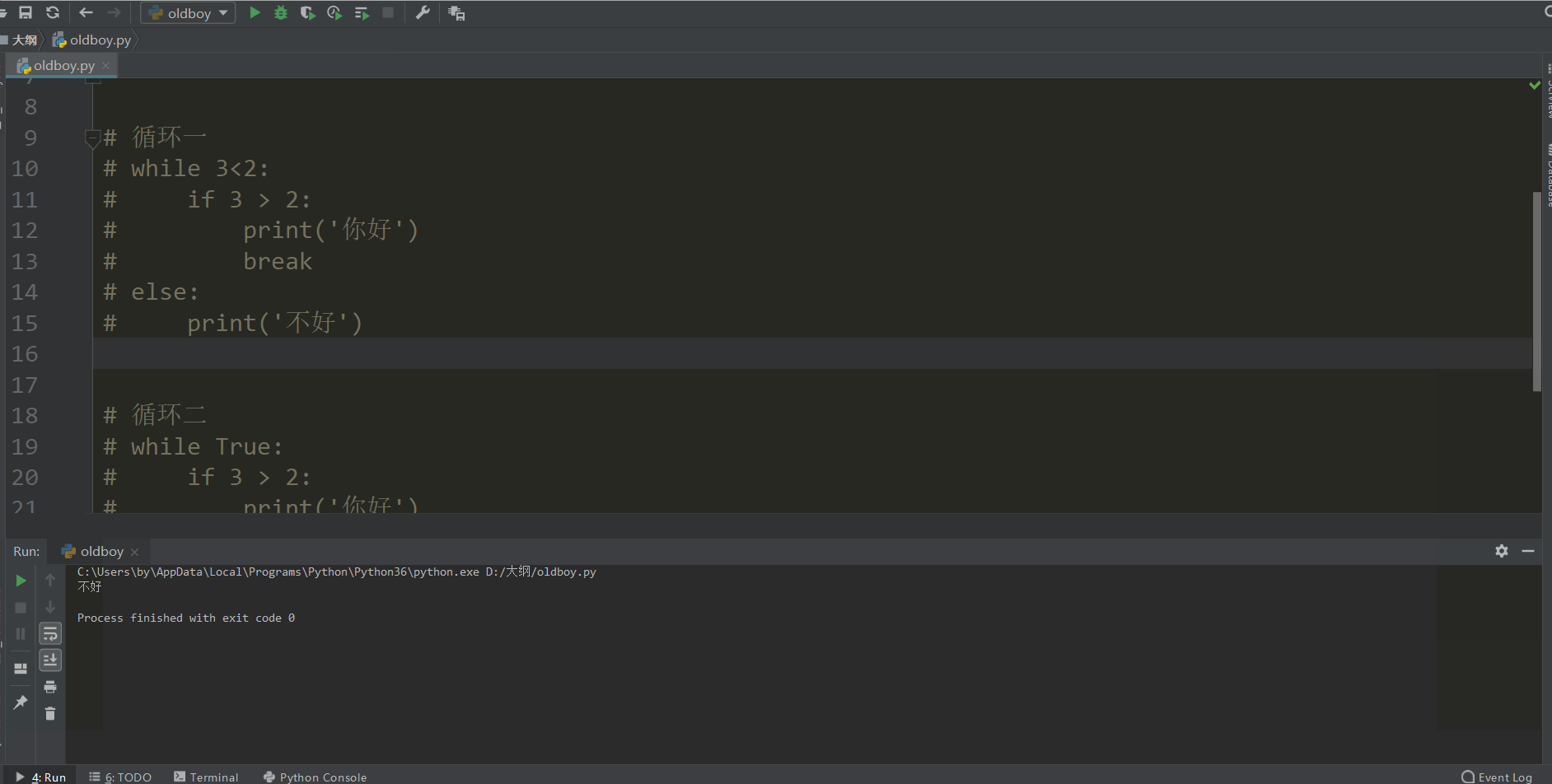
这个执行的效果是因为
循环一执行了循环也执行了if条件打印了你好然后碰到break循环结束了
循环二执行了循环也执行了if条件打印了你好,但是没有break 就继续重复执行了
循环一将3>2改成3<2这个条件就不成立,然后执行了else里打印了不好
while else 练习
首先让用户输入序号选择格式如下:
0.退出
1.开始登录
如果用户选择序号0 就提示用户退出成功
如果用户选择序号1就让用户输入用户名密码然后进行判断,正确就终止循环,错误重新输入
二.格式化输出
现在有个需要我们录入我们身边好友的信息,格式如下:
------------ info of Alex Li ----------
Name : Alex Li
Age : 22
job : Teacher
Hobbie: girl
------------- end ----------------
我们现在能想到的办法就是用一下方法:
name = input('请输入姓名:')
age = input('请输入年龄:')
job = input('请输入职业:')
hobby = input('请输入爱好:')
a = '------------ info of Alex Li ----------'
b = 'Name:'
c = 'Age:'
d = 'Job:'
e = 'Hobby:'
f = '------------- end ----------------'
print(a+
'\n'+
b+
name+
'\n'+
c+
age+
'\n'+
d+
job+
'\n'+
e+
hobby+
'\n'+
f)
# 运行结果
------------ info of Alex Li ----------
Name:meet
Age:18
Job:it
Hobby:3
------------- end ----------------
这样写完全没有问题,但是会不会比较繁琐呢,有些大佬肯定会想这不都实现了吗,还逼叨逼什么啊,那是没有体验过格式化输出有多霸道,我们现在来体验下霸道的姿势
2.1 %s
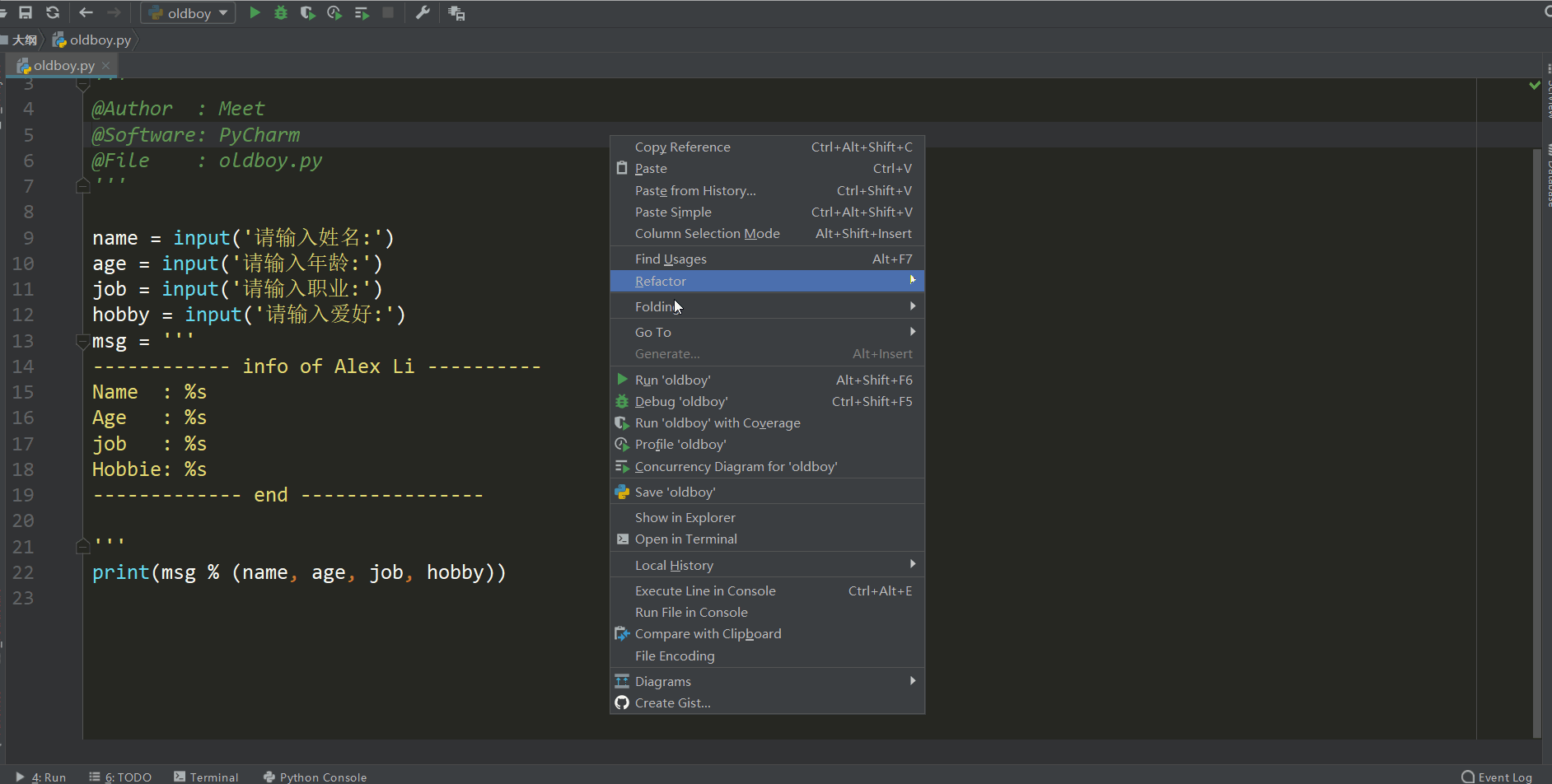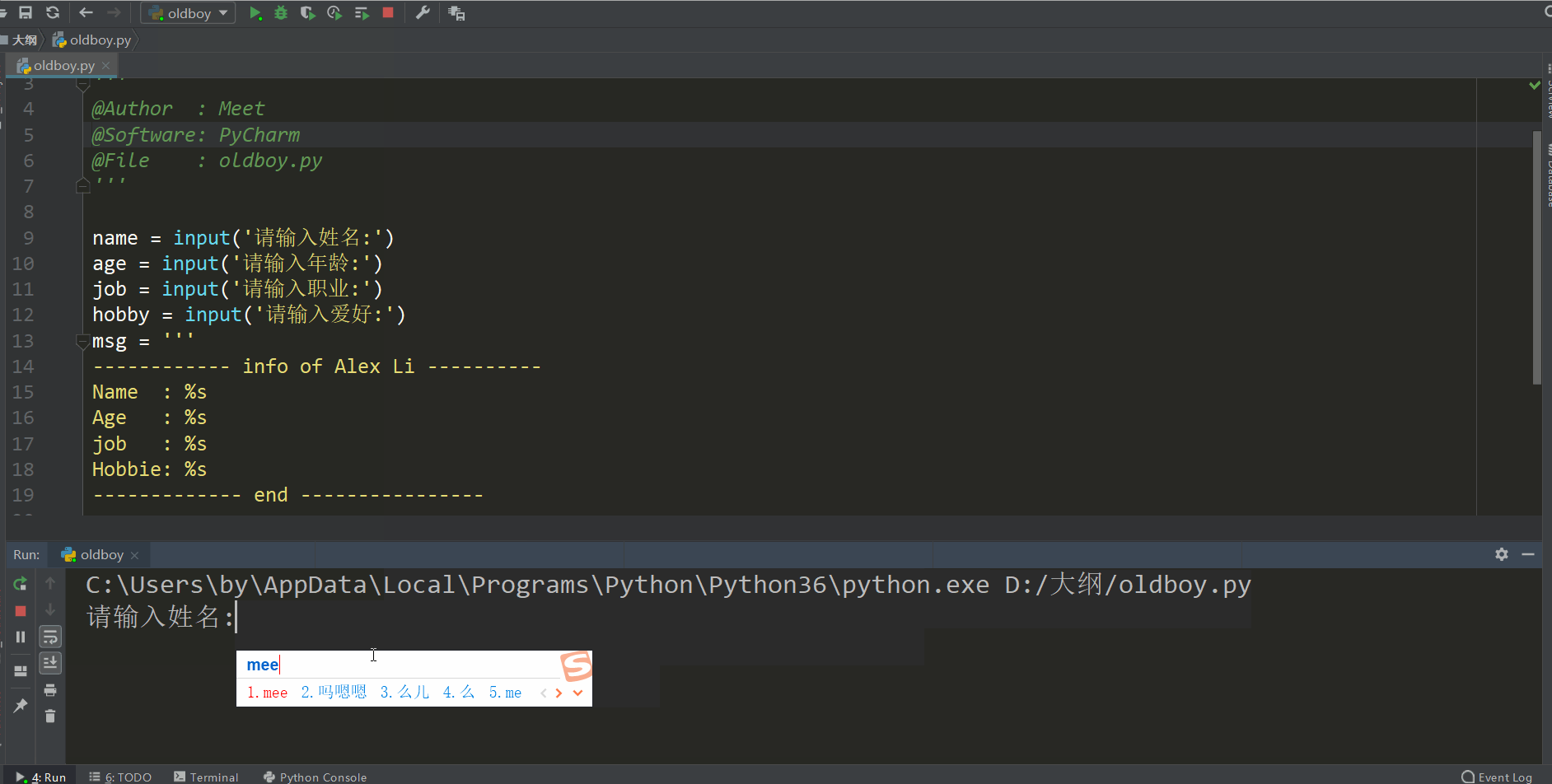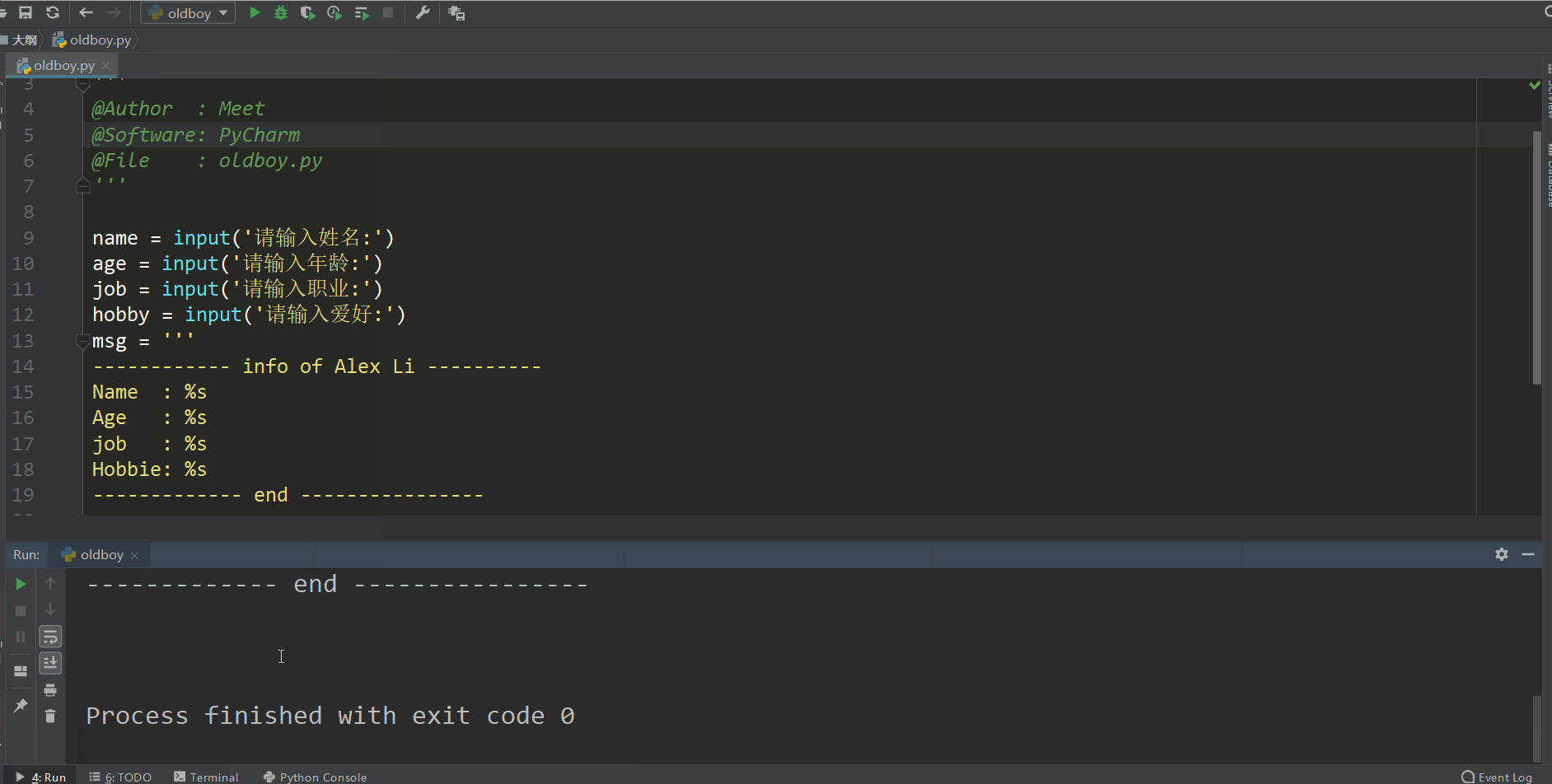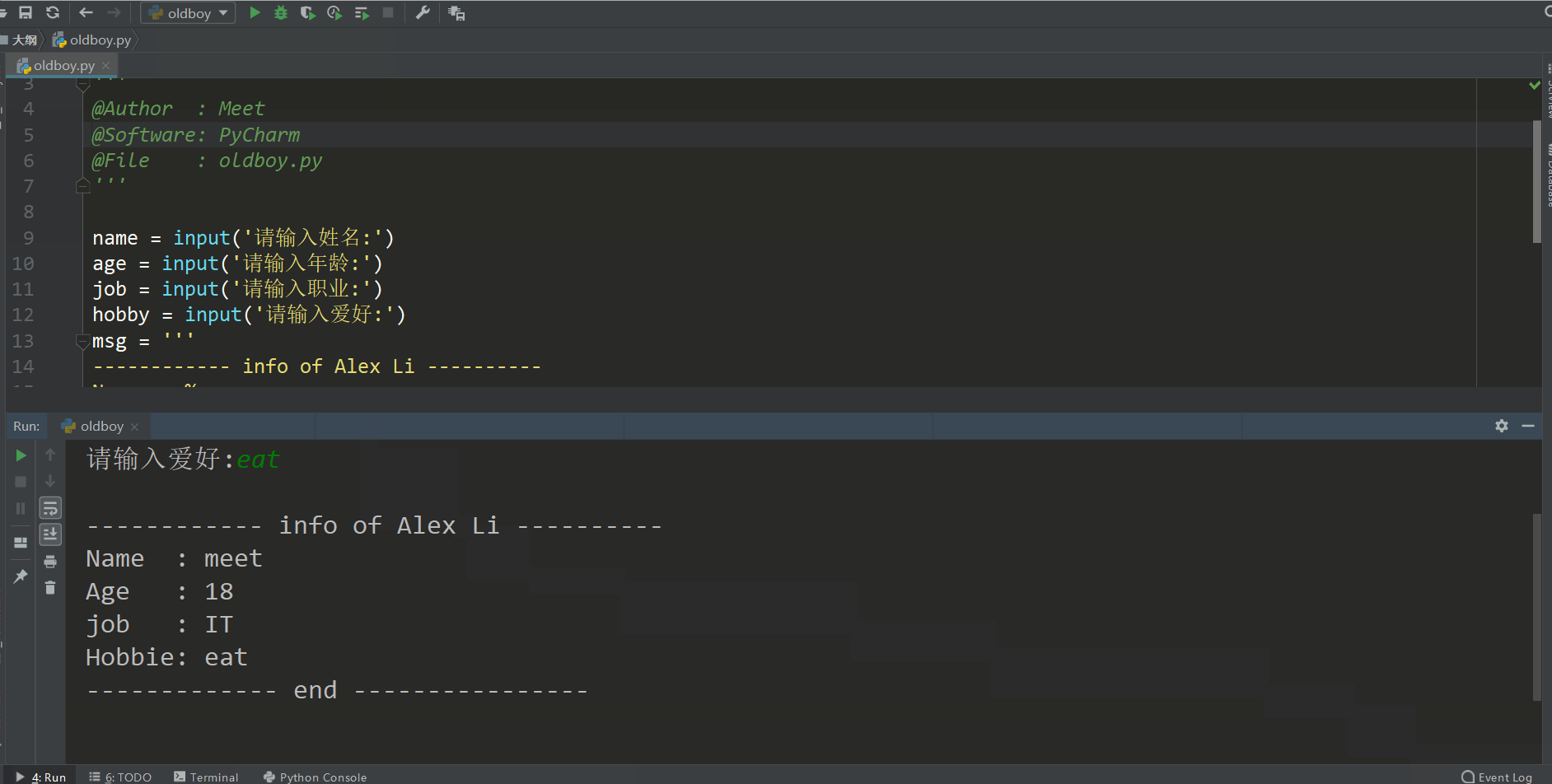
name = input('请输入姓名:')
age = input('请输入年龄:')
job = input('请输入职业:')
hobby = input('请输入爱好:')
msg = '''
------------ info of Alex Li ----------
Name : %s
Age : %s
job : %s
Hobbie: %s
------------- end ----------------
'''
print(msg%(name,age,job,hobby))
我们但从代码的数量来看,这样就比那样的少,看到这里有细心的老铁们肯定在想%s这是啥玩意?
% 是一个占位, 回想下我们小时候给朋友占位子的场景,是的这个就是占位.那s又是什么呢? s代码的字符串类型;
2.2 %d|%
name = input('>>>')
s1 = '1234%d'%int(name)
s2 = '1234%i'%int(name)
print(s1)
print(s2)
结果:
>>>89
123489
123489
# %d和%i这种格式化只能用数字来填补占位
2.3 %%
num = input('>>>')
s= '目前学习进度:%s%%'%num
print(s)
结果:
>>>80
目前学习进度:80%
# 如果我们字符串中想要显示单独的%就需要用来个%%来转义,不然程序会认为那是一个占位
三.运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算.
今天我们暂只学习 算数运算、比较运算、逻辑运算、赋值运算、成员运算
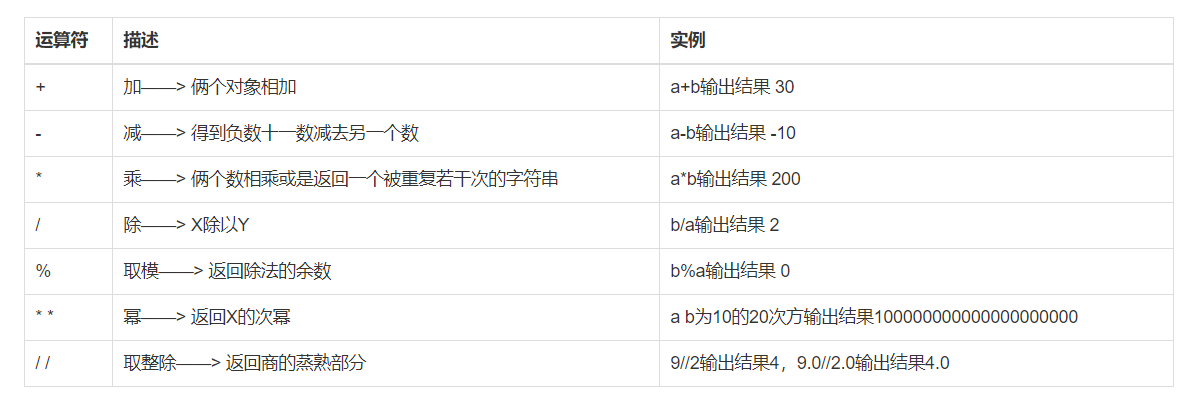
3.1 算数运算
以下假设变量:a=10,b=20

3.2 比较运算
以下假设变量:a=10,b=20

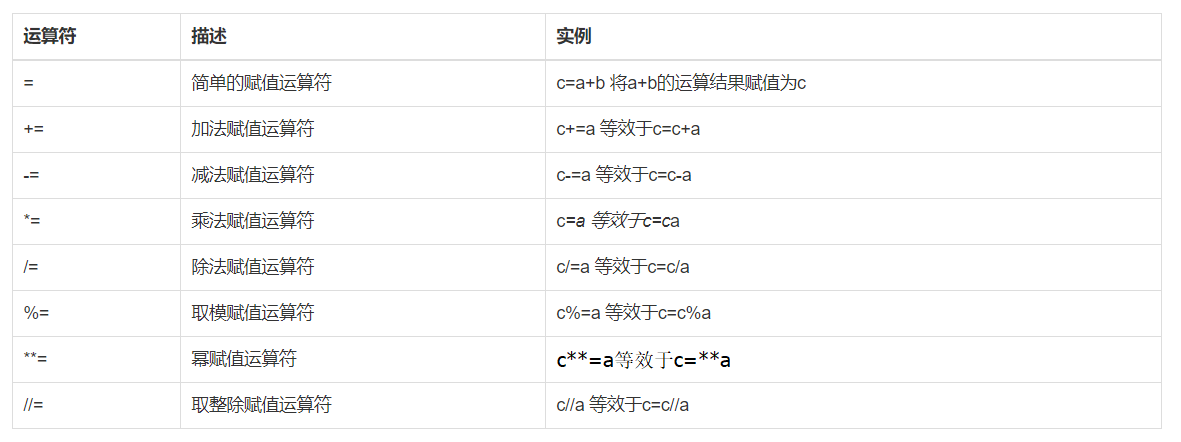
3.3 赋值运算
以下假设变量:a=10,b=20
3.4 逻辑运算

针对逻辑运算的进一步研究:
在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
例题:
判断下列逻辑语句的True,False。
x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
3>4 or 4<3 and 1==1
1 < 2 and 3 < 4 or 1>2
2 > 1 and 3 < 4 or 4 > 5 and 2 < 1
not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6

例题:求出下列逻辑语句的值。
8 or 4
0 and 3
0 or 4 and 3 or 7 or 9 and 6
3.5 成员运算
in not in :
判断子元素是否在原字符串(字典,列表,集合)中:
例如:
#print('喜欢' in 'dkfljadklf喜欢hfjdkas')
#print('a' in 'bcvd')
#print('y' not in 'ofkjdslaf')
四.编码
咱们的电脑,存储和发送文件,发送的是什么?电脑里面是不是有成千上万个二极管,亮的代表是1,不亮的代表是0,这样实际上电脑的存储和发送是不是都是010101啊
我们发送的内容都是010101010这样写的内容比较多就不知道是什么了,所以我们想要明确的区分出来发送的内容就需要
在某个地方进行分段.计算机中设定的就是8位一断句
4.1 ASCII
计算机:
储存文件,或者是传输文件,实际上是010101010
计算机创建初期,美国,是7位一段,但是发明者说为了拓展,留出一位,这样就是8位一段句。8位有多少种可能 ?256
密码本:
ascii
00000001
01000001 01000010 01000011 ABC
随着计算机的发展. 以及普及率的提高. 流⾏到欧洲和亚洲. 这时ASCII码就不合适了. 比如: 中⽂汉字有几万个. 而ASCII 多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境. 比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了.
4.2 GBK
GBK, 国标码占用2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是用英文写的. 你不支持英文肯定不行. 而英文已经使用了ASCII码. 所以GBK要兼容ASCII.
这里GBK国标码. 前⾯的ASCII码部分. 由于使⽤两个字节. 所以对于ASCII码⽽言. 前9位都是0
字母A:0100 0001 # ASCII
字母A:0000 0000 0100 0001 # 国标码
随着全球化的普及,发展到欧洲,亚洲等国家,发现这些根本不够用,所以创建了万国码。
因为全球语言很多,ascii不足以存储这么多对应关系,创建了一个超级密码本:万国码unicode
8 位 == 1个字节.
hello h一个字符,e一个字符,he就不是一个字符.
中国:中是一个字符,国是一个字符.
4.3 unicode
创建之初,16位,2个字节,表示一个字符.
英文: a b c 六个字节 一个英文2个字节
中文 中国 四个字节 一个中文用2个字节
缺点:浪费资源,优点:速度快!
4.4 UTF-8
对Unicode进行升级: utf-8
utf-8 用最少用8位数,去表示一个字符.
英文: 8位,1个字节表示.
欧洲文字: 16位,两个字节表示一个字符.
中文,亚洲文字: 24位,三个字节表示.
utf-16 用最少用16位数。
gbk:
国标,只能中国人自己用, 一个中文用16位,两个字节表示。
4.5 单位转化
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
1024ZB = 1YB
1024YB = 1NB
1024NB = 1DB
常⽤到TB就够了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号