
2017年双色球中奖号码
网络爬虫,又称网页蜘蛛、网络机器人。随着计算机技术的高速发展,互联网中的信息量越来越大,搜索引擎应运而生。传统的搜索引擎会有返回结果不精确等局限性。为了解决传统搜索引擎的局限性,专用型网络爬虫在互联网中越来越常见。同时,专用型网络爬虫具有专用性,可以根据制定的规则和特征,最后只体现和筛选出有用的信息。
在国内,唯一能合法暴富的方法似乎只有彩票中奖了。虽然人人都知道中奖的概率很低,但希望总是存在的。中奖的号码虽然不能直接推算出来,但根据概率计算将中奖的稍微调大点还是可能的,在进行概率计算前要做的就是收集数据,好在中国福利彩票并不禁止收集数据进行概率计算。
2.利用python在网页收集信息
本次实验主要是爬取2017年双色球中奖号码以及统计中奖结果。
import re from bs4 import BeautifulSoup import ur11ib2 from mylog import MyLog as mylog class DoubleColorBallItem(object): date=None #开奖日期 order=None #当年的顺序 red1=None #第一个红球的号码 red2=None #第二个红球的号码 red3=None #第三个红球的号码 red4=None #第四个红球的号码 red5=None #第五个红球的号码 red6=None #第六个红球的号码 blue=None #篮球号码 mony=None #彩池金额 firstPrize=None #一等奖中奖人数 secondPrize=None #二等奖中奖人数 class GetDoubleColorBallNumber(object): '''这个类用于获取双色球中奖号码,返回一个txt文件 ''' def _init_(self): self.urls=[] self.log=mylog() self.getUrls() self.items=self.spider(self.urls) self.pipelines(self.items) def getUrls(self): '''获取数据来源网页 ''' URL=r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html' htmlContent=self.getResponseContent(URL) soup=BeautifulSoup(htmlContent,'lxml') tag=soup.find_all(re.compile('P'))[-1] pages=tag.strong.get_text() for i in xrang(1,int(pages)+1): url=r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_'+str(i) +'.html' self.urls.append(url) self.log.info('u添加URL:%S到URLS\r\n'%url) def getResponseContent(self,url): '''这里单独使用一个函数返回页面返回值,是为了后期方便地加入proxy和headers等 ''' try: respone=urllib2.urlopen(url.encode('utf8')) except: self.log.error(u'python返回URL:%s数据失败 \r\n'%url) else: self.log.info(u'python返回URL:%s数据成功 \r\n'%url) return response.read() def spider(self,urls): '''这个函数的作用是从获取的数据中过滤得到中奖信息 ''' items=[] for url in urls: htmlContent=self.getResponseContent(url) soup=BeautifulSoup(htmlContent,'lxml') tags=soup.find_all('tr',attrs={}) for tag in tags: if tag.find('em'): item=DoubleColorBallItem() TagTd=tag.find_all('td') item.date=TagTd[0].get_text() item.order=TagTd[1].get_text() TagEm=TagTd[2].find_all('em') item.red1=tagEm[0].get_text() item.red2=tagEm[1].get_text() item.red3=tagEm[2].get_text() item.red4=tagEm[3].get_text() item.red5=tagEm[4].get_text() item.red6=tagEm[5].get_text() item.blue=tagEm[6].get_text() item.money=tagTd[3].find('strong').get_text() item.firstPrize=tagTd[4].find('strong').get_text() item.secondPrize=tagTd[5].find('strong').get_text() items.append(item) self.log.info(u'获取日期为:%s的数据成功'%(item.date)) return items def pipelines(self,items): fileName=u'双色球.txt'.encode(GBK) with open(fileName,'w') as fp: for item in items: fp.write('%s %s \t %s %s %s %s %s %s %s \t %s \t %s %s \n' %(item.date,item.order,item.red1,item.red2,item.red3,item.red4,item.red5,item.red6,item.blue,item.money,item.firstPrize,item.secondPrize)) self.log.info(u'将日期为:%s的数据存入"%s"...' %(item.date,fileName.decode('GBK'))) if _name_=='_main_': GDCBN=GetDoubleColorBallNumber()
爬取结果如图所示(截取部分截图):
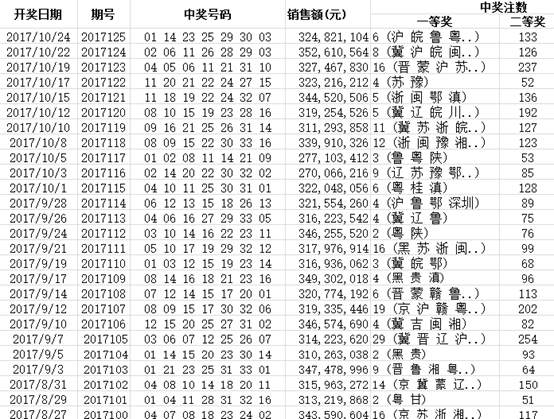
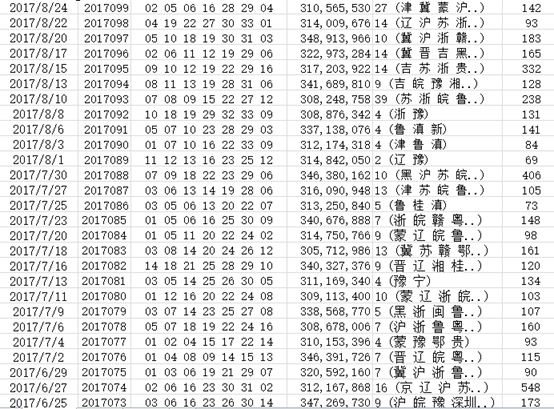
图2.1 2017年每期开奖信息
2017年中奖号码如图所示(截取部分图):

图2.2 2017年每期开奖号码
将中奖号码保存至qiu.txt,分析统计结果如图所示:
import jieba #处理中文需要的库 fo=open('qiu2.txt','r')#把qiu.txt的内容读出到of里 numbers=fo.read()#把of的内容给numbers #print(numbers) numberss=list(jieba.cut(numbers))#精准模式来分词 exp={' ','\n'} #把不要统计的词放在一个集合里 dict={} #建立空字典来存需要统计的词频 keys=set(numbers)-exp #在文的集合里(词频不重复、无序),排除我们不要的词,即exp里面的词 for i in keys: #对一个字典的键值(唯一),进行统计 dict[i]=numbers.count(i)#统计的内容词频来自numbers里(里面的词可能会重复) count=list(dict.items()) #因为字典式不能排序的,所以要变成可以排序的列表。具体是对字典里的什么内容排序呢?就是对字典里的每一对值排序,怎么才能对一对排序呢?字典的items()就是输出一对值得函数。 count.sort(key=lambda x:x[1],reverse=True) #lambda()是个定义函数匿名的 for i in range(33): #打印统计数字的出现次数 print(count[i]) fo.close()

图2.3 统计2017年中奖号码
用工具做成词云的结果为:
import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt txt=open('qiu2.txt','r',encoding='gb2312').read() cy = WordCloud(font_path='msyh.ttc').generate(txt) #wordcloud默认不支持中文,这里的font_path需要指向中文字体 plt.imshow(cy, interpolation='bilinear') plt.axis("off") plt.show()

图2.4 2017年中奖号码词云
3.结论
由图可以看出,2017呢喃双色球中奖的号码中,号码21、15和14和23出现的比较多一些,可以适当考虑这几个号码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号