文件

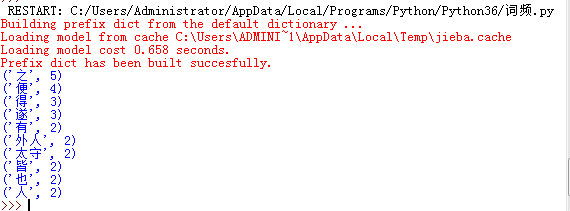
a.精准模式
import jieba #处理中文需要的库 fo=open('b.txt','r')#把b.txt的内容读出到of里 news=fo.read()#把of的内容给news news=list(jieba.cut(news))#精准模式来分词 #print(news) exp={'',',','。','\n'} #把不要统计的词放在一个集合里 dict={} #建立空字典来存需要统计的词频 keys=set(news)-exp #在文章的集合里(词频不重复、无序),排除我们不要的词,即exp里面的词 for i in keys: #对一个字典的键值(唯一),进行统计 dict[i]=news.count(i)#统计的内容词频来自news里(里面的词可能会重复) count=list(dict.items()) #因为字典式不能排序的,所以要变成可以排序的列表。具体是对字典里的什么内容排序呢?就是对字典里的每一对值排序,怎么才能对一对排序呢?字典的items()就是输出一对值得函数。 count.sort(key=lambda x:x[1],reverse=True) #lambda()是个定义函数匿名的
for i in range(10): print(count[i]) fo.close()
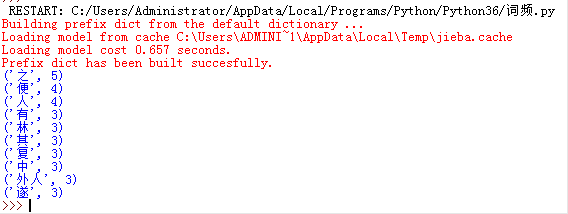
B.全模式
news=list(jieba.cut(news,cut_all=True))#把上面的news=list(jieba.cut(news))换成这个即可
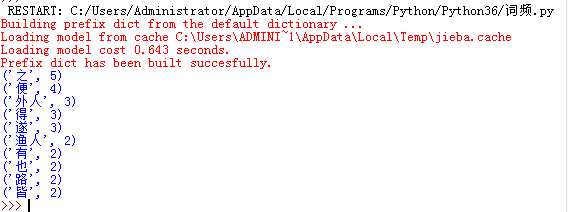
3.搜索引擎
news=list(jieba.cut_for_search(news))#把上面的news=list(jieba.cut(news))换成这个即可
D,把一个文本保存

第一行: 新建一个c.txt文件,把它给fo
第二行:把内容写在fo里,
第三行:保存
pip install jieba
Users\duym\AppData\Local\Programs\Python\Python36>pip install wordcloud-1.3.2-cp36-cp36m-win_amd64.whl

 浙公网安备 33010602011771号
浙公网安备 33010602011771号