hadopp的shuffle阶段简述(自己理解)
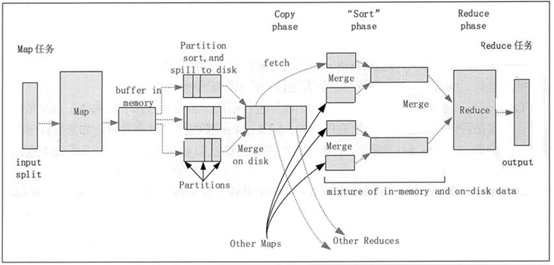
hadoop的shuffle分为两个阶段
map端的shuffle:Sort、Spill、Merge
1、来一个输入分片,分配一个map任务来处理,默认以一个HDFS块的大小(64M)为一个分片,
把数据首先放到内存中的一个缓冲区,做一些预排序,提升效率;
2、每个map任务都有一个内存缓冲区(默认100M),当缓冲区数据量达到特定阈值是(默认80%),
缓冲区内容会写磁盘(spill阶段),Map写缓冲区也是同时进行的,但如果缓冲区被塞满,
map任务会阻塞,直到写磁盘完成;
3、到达一次阈值,创建一个溢出写文件,最终多个溢出写文件
被合并成一个索引文件和数据文件(多路归并排序)(sort阶段);
4、归并完毕后,Map任务删除所有的临时溢出写文件,告知TaskTracker任务完成,只要其中一个
Map任务完成,Reduce任务就会开始复制输出(copy)
(Map任务输出文件放到运行Map任务的TaskTracker的本地磁盘上)
reduce端的shuffle:Copy、Merge、Reduce
1、reduce进程启动一些数据复制线程,从Map任务所在的TaskTracker获取输出文件(copy)
2、将复制数据放入缓冲区,Merge有三种形式,内存到内存,内存到磁盘,磁盘到磁盘。
默认情况下,第一种形式不启用,第二种形式一直在运行(Spill 阶段),直到结束,第三种形式生成最终的文件
3、当reduce的输出文件确定,shuffle阶段结束,然后就是reduce执行,把结果放到(HDFS)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号