
CPU擅长逻辑处理控制,GPU适合高强度的并行计算任务,为什么会存在这种差别?今天搜集了些相关资料,摘抄总结如下。
一、什么是GPU
GPU这个概念是由Nvidia公司于1999年提出的。GPU是显卡上的一块芯片,就像CPU是主板上的一块芯片。那么1999年之前显卡上就没有GPU吗?当然有,只不过那时候没有人给它命名,也没有引起人们足够的重视,发展比较慢。
自Nvidia提出GPU这个概念后,GPU就进入了快速发展时期。简单来说,其经过了以下几个阶段的发展:
1)仅用于图形渲染,此功能是GPU的初衷,这一点从它的名字就可以看出:Graphic Processing Unit,图形处理单元;
2)后来人们发现,GPU这么一个强大的器件只用于图形处理太浪费了,它应该用来做更多的工作,例如浮点运算。怎么做呢?直接把浮点运算交给GPU是做不到的,因为它只能用于图形处理(那个时候)。最容易想到的,是把浮点运算做一些处理,包装成图形渲染任务,然后交给GPU来做。这就是GPGPU(General Purpose GPU)的概念。不过这样做有一个缺点,就是你必须有一定的图形学知识,否则你不知道如何包装。
3)于是,为了让不懂图形学知识的人也能体验到GPU运算的强大,Nvidia公司又提出了CUDA的概念。
二、CPU和GPU的关系和差别
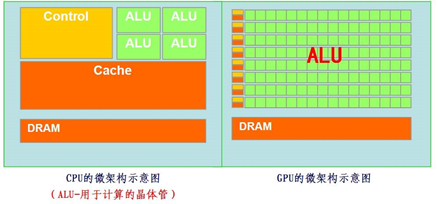
从上图可以看出GPU(图像处理器,Graphics Processing Unit)和CPU(中央处理器,Central Processing Unit)在设计上的主要差异在于GPU有更多的运算单元(如图中绿色的ALU),而Control和Cache单元不如CPU多,这是因为GPU在进行并行计算的时候每个运算单元都是执行相同的程序,而不需要太多的控制。Cache单元是用来做数据缓存的,CPU可以通过Cache来减少存取主内存的次数,也就是减少内存延迟(memory latency)。GPU中Cache很小或者没有,因为GPU可以通过并行计算的方式来减少内存延迟。因此CPU的Cahce设计主要是实现低延迟,Control主要是通用性,复杂的逻辑控制单元可以保证CPU高效分发任务和指令。所以CPU擅长逻辑控制和串行计算,而GPU擅长高强度的并行计算。打个比方,GPU就像成千上万的苦力,每个人干的都是类似的苦力活,相互之间没有依赖,都是独立的,简单的人多力量大;CPU就像包工头,虽然也能干苦力的活,但是人少,所以一般负责任务分配,人员调度等工作。
可以看出GPU加速是通过大量线程并行实现的,因此对于不能高度并行化的工作而言,GPU就没什么效果了。而CPU则是串行操作,需要很强的通用性,主要起到统管和分配任务的作用。
三、什么是CUDA
CUDA(Compute Unified Device Architecture),通用并行计算架构,是一种运算平台。它包含CUDA指令集架构以及GPU内部的并行计算引擎。你只要使用一种类似于C语言的CUDA C语言,就可以开发CUDA程序,从而可以更加方便的利用GPU强大的计算能力,而不是像以前那样先将计算任务包装成图形渲染任务,再交由GPU处理。
注意,并不是所有GPU都支持CUDA。
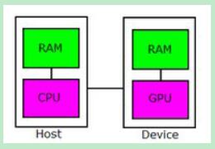
在CUDA的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由host端程序将结果从显卡的内存中取回。
四、什么是cuDNN
cuDNN(CUDA Deep Neural Network library)是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
参考:
[1] http://www.cnblogs.com/feng9exe/p/6723214.html
[2] http://blog.csdn.net/u014380165/article/details/77340765

 浙公网安备 33010602011771号
浙公网安备 33010602011771号