
C++ 练气期之指针所指何处
1. 指针
指针是一种C++数据类型,用来描述内存地址。
什么是内存地址?
内存中的每一个存储单元格都有自己的地址,地址是使用二进制进行编码。地址从形态上看是一个整型数据类型。但是,它的数据含义并不表示数字,而是一个位置标志,类似于门牌号。

指针类型数据的算术运算:
- 在地址上
加上或减去一个正整数,表示向前或向后移动地址。移动地址的意义:可实现从一个存储位置到达另一个存储位置。 - 地址与地址之间也可以相减,表示两个地址之间的差距。
- 地址与地址之间不可以相加、相乘、相除运算。对地址进行相加、相乘、相除类似门牌号门牌号之间相加、相乘、相除,没有任何意义可言。
2. 指针变量
变量是一个存储块,为了能访问到变量中的数据,开发者需要为变量指定一个名字,即变量名。编译器会在分配变量后,把变量和变量名进行关联。
变量名和变量地址有什么关系?
变量名是变量的逻辑地址,由开发者提供。而变量地址是变量的物理地址,指变量在内存中的具体位置。如下声明语句,在编译时,编译器会做一些细碎的底层工作。
int num=20;
- 根据数据类型的约定,在
内存中找到一个可用的内存块。int一般大小为4B。 - 获取到内存块的物理地址,并把物理地址和开发者提供的变量名(逻辑名)进行关联,并保存在映射表中。
- 把数字
20保存在num变量中。
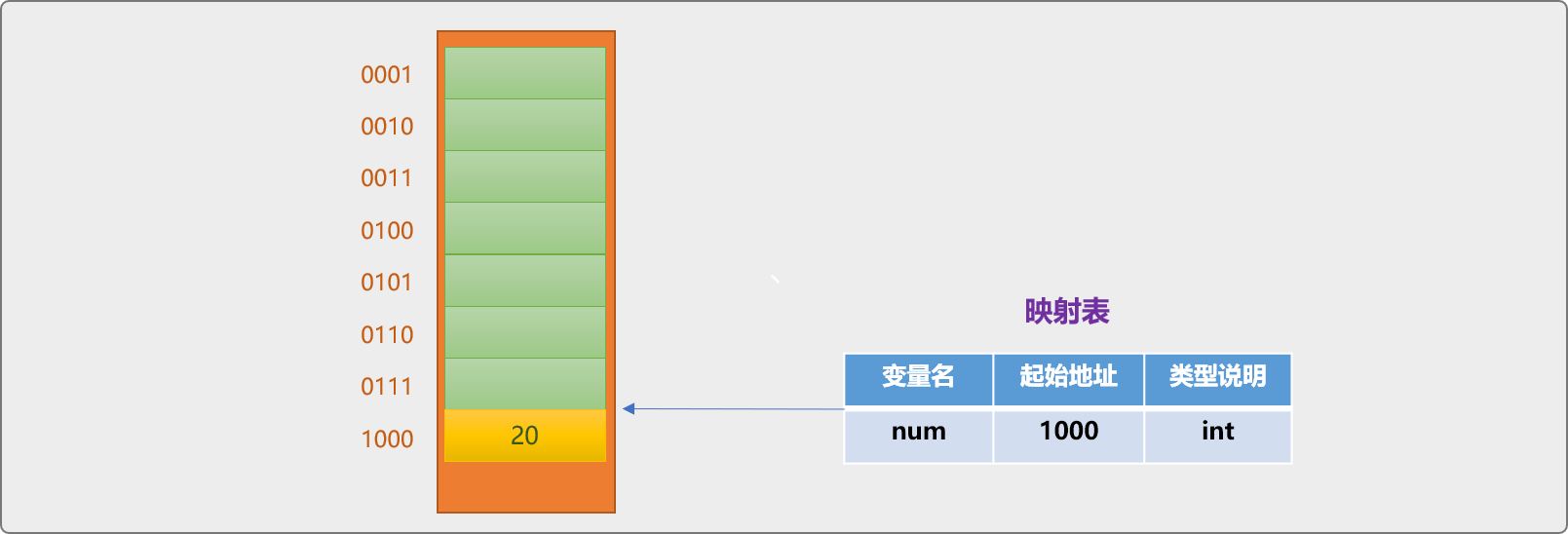
在使用 num访问变量时,需要借助映射表,找到变量名对应的内存地址,方能访问变量中的数据。变量名是变量地址的逻辑名。
std::cout<<num;
//输出结果:20
能不能获取到变量在内存的地址,通过地址访问变量?
当然可以,前提是需要声明一个指针变量,保存变量的物理地址。
用来保存地址(指针)类型数据的变量称为
指针变量。
指针变量也是内存中的一个存储块,只是变量中存储的是另一个变量在内存中的地址。如下代码,保存 num变量在内存的地址。
//整型类型变量
int num=20;
//指针类型的变量
int* num_p=#
代码说明:
int *表示指针类型。声明指针变量时,需要指定变量是用来保存指针类型数据。
int *表示指针变量是用来保存一个int类型变量的地址,并不是指变量用来保存一个整型数据。
&运算符,取地址运算符。&num表示获取num变量的内存(物理)地址。
既然是变量,指针变量在内存也有属于自己的存储位置。如下图所示,只是指针变量中保存的是地址信息。
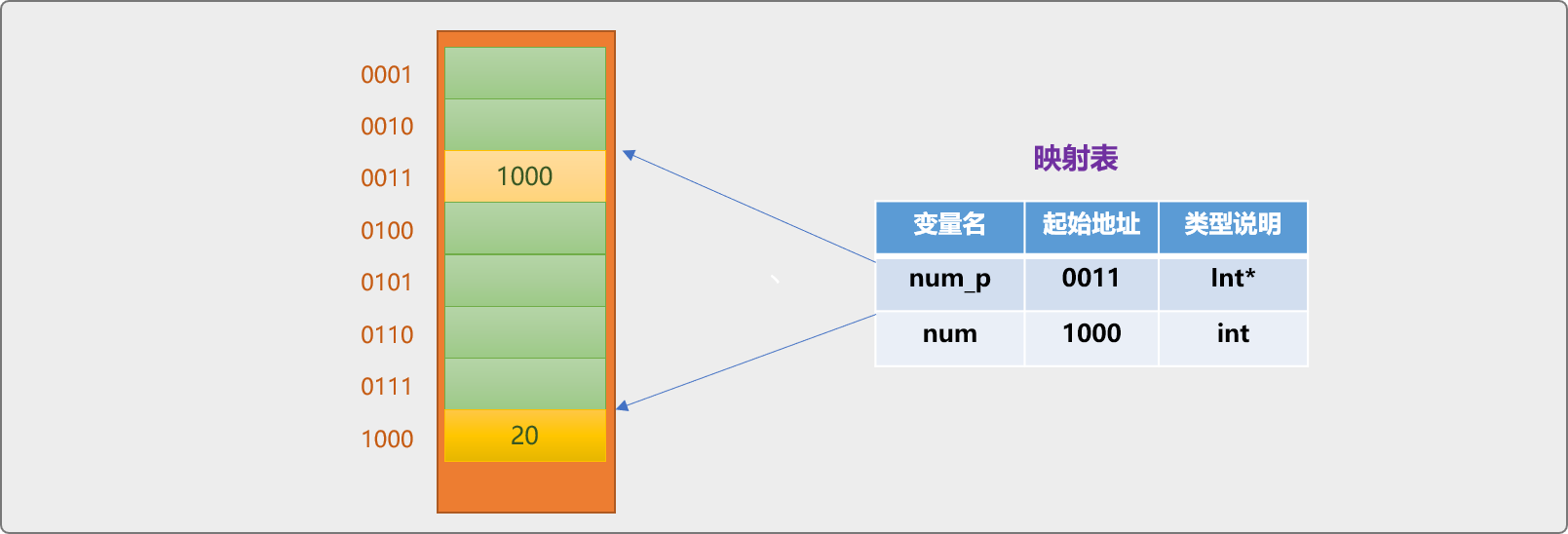
指针变量实际占用内存大小是多少,由底层编译器决定。
如何通过指针变量中的地址访问 num 变量?
如下代码,先试着直接输出指针变量 num_p 中的数据。
std::cout<<num_p;
输出结果:0x70fe14。很明显这是内存地址的 16进制格式,也证实指针变量中存储的是地址。
千万别问我为什么输出的不是
1000。图片只是一个演示。
有了这个地址后,可以通过这个地址访问num变量中的数据。
std::cout<<*num_p;
//输出:20
需要注意:在声明和通过地址访问数据时,都要使用 *符号:
- 声明时
*表示指针类型。int* num_p; - 使用指针变量时,表示通过地址找到变量中的数据。
*num_p 和 num是访问同一个变量的两种方案。前者是使用物理名(内存地址)访问变量的语法,后者是使用逻辑名(变量名)访问变量。
同样的也能够使用指针变量对其引用的变量进行赋值。
int num=20;
int* num_p=#
//通过指针变量赋值,和 num=30 等同
*num_p=30;
std::cout<<*num_p<<std::endl;
std::cout<<num<<std::endl;
//输出结果:
30
30
3. 几个问题
3.1 为什么要使用指针变量
在使用指针变量时,总会有一个疑问,既然能够使用变量名访问变量,为什么还要搞一个指针变量。指针变量不仅要占用内存空间,且语法繁琐,是不是有点啰嗦了。
其实,指针变量是C系列语言的特色,是演化过程中保留下来的原始特性:
- 访问速度。
指针访问是直接硬件访问,速度较快。
遍历数组时,通过指针的加法、减法运算法则,可以向前或向后快速移动指针。
int nums[4]={1,2,3,4};
int* nums_p=nums;
for(int i=0;i<4;i++){
std::cout<<*(nums_p+i)<<std::endl;
}
//输出
1
2
3
4
数组变量本质是指针变量,保存着数组在内存中的首地址。所以在把数组的地址赋值另一个指针变量时,int* nums_p=nums;是不需要使用&符号的。
上述代码nums_p+i让指针变量能加上一个正整数,实现指针的移动,这里要注意,加上 1 不是表示只移动一个存储单元格,而是移动int大小。
如果知道数据在数组中的位置,可以直接在首指针基础上加上一个移动单位,便能快速访问数组中的数据。
- 访问
new创建的内存块。
如下语句:
int *num01=new int;
new运算符会在堆中开辟一个用来保存int类型数据的存储块,返回存储块的内存地址(指针类型数据) ,这时只能使用指针变量保存,并且通过指针变量使用这个存储块 。
指针变量的存在为使用堆提供了必要条件,C++称堆为动态内存区域,开发者可随时根据自己的需求在程序运行时申请、使用。
理论上讲,编译器也可以让开发者提供变量名,然后把变量名和
new返回的地址进行映射。显然,省略映射环节,直接指针访问,即减轻了编译器的负担,又提升了访问速度。
int *num01=new int;
*num01=40;
std::cout<<*num01<<std::endl;
//输出:40
- 使用指针变量作为函数的参数,用来影响函数调用处变量中的值。
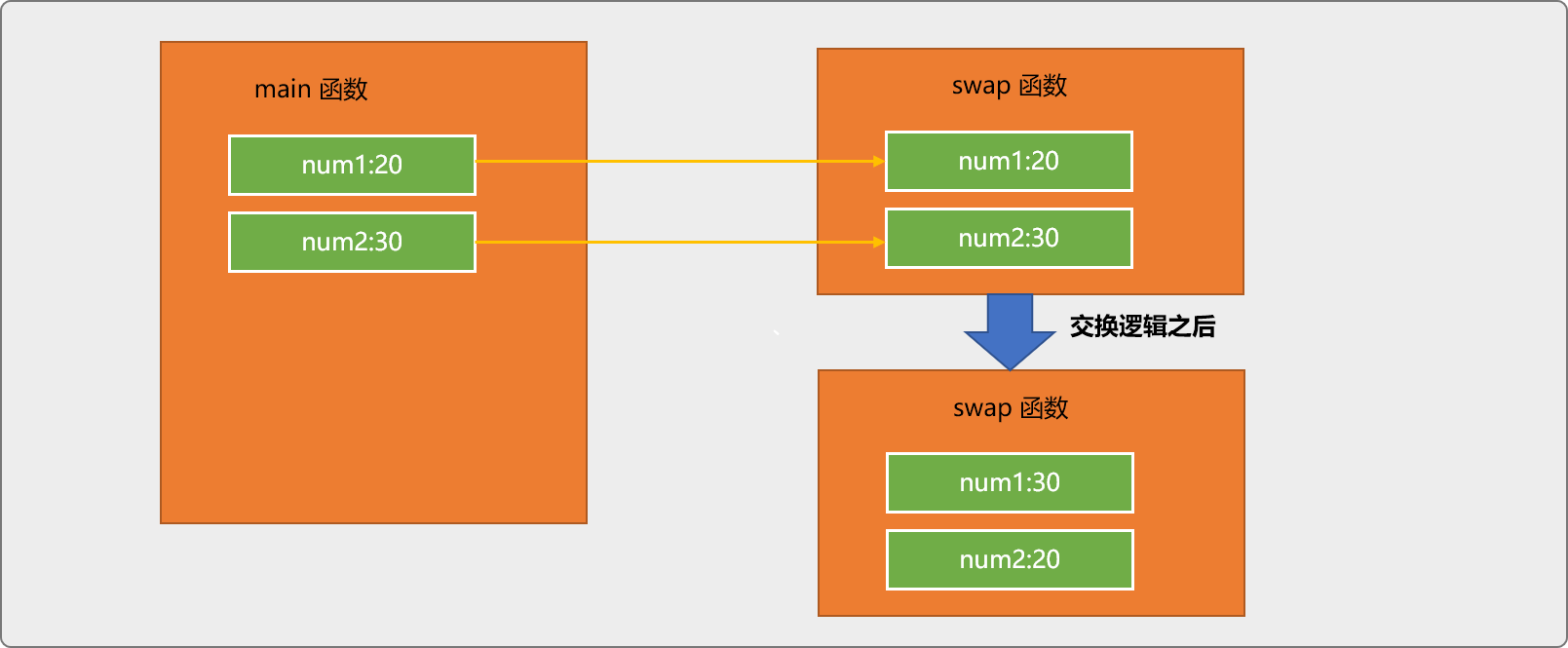
如果现在有一个需求,使用一个函数交换 2 个变量中的数据。先看一下下面的代码是否能实现这个效果。
#include <iostream>
//交换函数
void swap(int num1,int num2){
int tmp=num1;
num1=num2;
num2=tmp;
}
int main(int argc, char** argv) {
int num1=20;
int num2=30;
std::cout<<"交换前:"<<num1<<":"<<num2<<std::endl;
swap(num1,num2);
std::cout<<"交换后:"<<num1<<":"<<num2<<std::endl;
return 0;
}
输出结果:
交换前:20:30
交换后:20:30
主函数中的 num1和num2变量中的数据根本没有交换。
原因在于调用函数swap时,参数是值传递。所谓值传递,指把主函数中num1和num2变量的值传递给swap函数中的 num1和num2变量。swap的交换逻辑仅修改了自身 2 个变量中的值。
如下图所示,主函数变量中的数据没有改变。
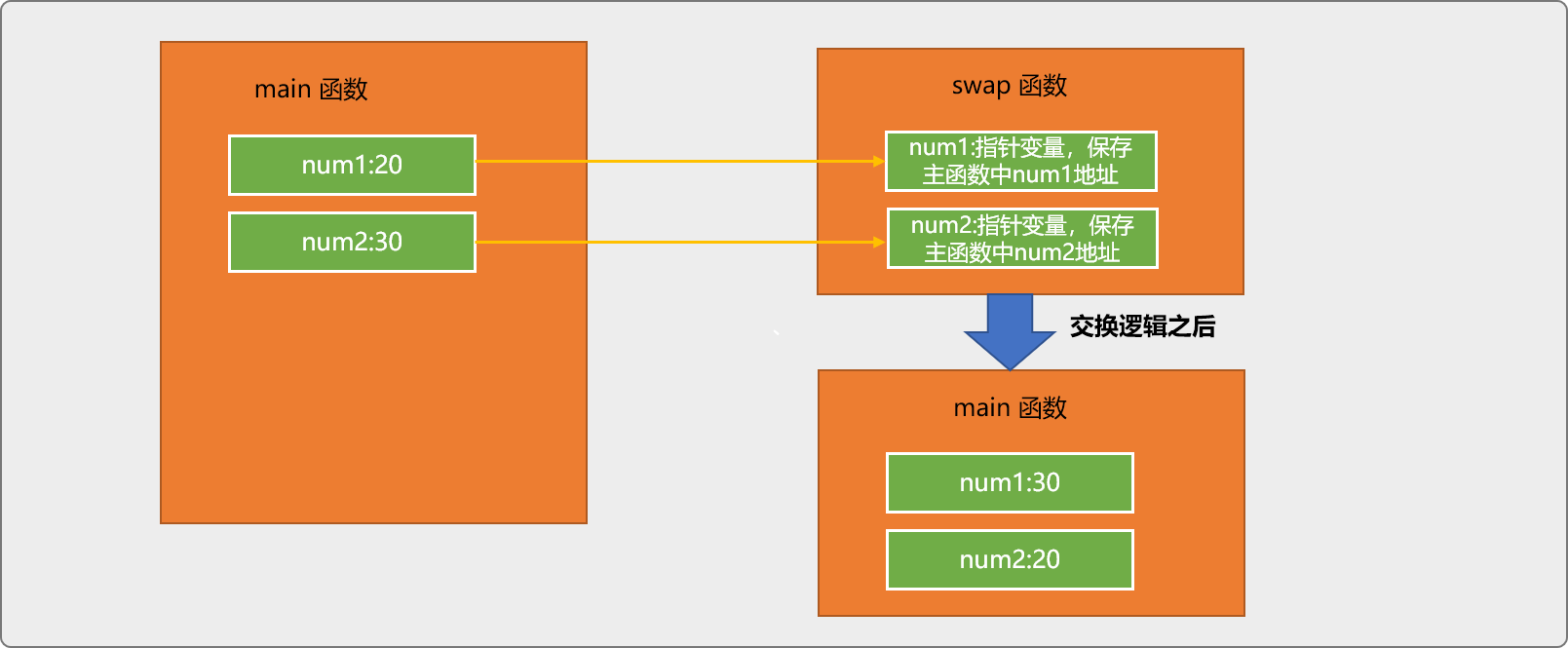
如果希望通过调用swap后直接修改主函数中num1和num2中的值,可以使用指针变量作参数。
#include <iostream>
//形参为指针类型
void swap(int* num1,int* num2){
//*num1 通过地址访问主函数中的 num1 变量
int tmp=*num1;
//交换的是主函数中变量中的值
*num1=*num2;
*num2=tmp;
}
int main(int argc, char** argv) {
int num1=20;
int num2=30;
std::cout<<"交换前:"<<num1<<":"<<num2<<std::endl;
//主函数把变量的地址传递给 swap 函数
swap(&num1,&num2);
std::cout<<"交换后:"<<num1<<":"<<num2<<std::endl;
return 0;
}
输出结果:
交换前:20:30
交换后:30:20
指针作为参数,传递的是变量地址,意味着,swap函数中两个变量引用了主函数中两个变量的物理地址。可以实现修改主函数中变量值的目的。
相当于主函数把变量房间的钥匙传递给
swap函数,swap再使用钥匙进入主函数中的变量,进行数据维护。
3.2 指针潜在的风险
3.2.1 初始化风险
必须初始化: 如下代码,编译器不会报任何错误,但实际上是没有任何意义的代码。
int* p;
std::cout<<p<<std::endl;
std::cout<<*p<<std::endl;
输出结果:
0x40ebd9
264275272
当声明指针变量 p时,如果没有指定初始值,编译器会随意指定一个值。指望把这个值当成一个有效地址,是没有意义的。如果把这指针变量用于代码逻辑,会产生无中生有的数据,显然是违背数据的准确性和可靠性。
所以,在声明指针变量后,一定要对其进行初始化。
不能使用整型常量初始化: 使用整型数字常量初始化指针变量,编译层面是通不过的。
//语法错误
int* p=0x40aed9;
0x40aed9即使是一个有效的内存地址数据,因为类型不同,也不能把整型数据赋值给一个指针类型变量。
但是,可以强制类型转换后再赋值。
地址形态上是数字,也仅是形态上是,本质上不是数字类型,不具有数字语义,也不具有数字运算操作能力,不能把地址类型与数字类型混淆。
//正确
int* p=(int*)0x44eb99;
虽然,通过强制转换可以成功初始化指针变量,但是存在潜在风险:
0x44eb99地址不一定是一个有效的地址。0x44eb99即使是一个有效地址,有可能此地址正被其它变量使用。如此,你便修改了其它变量的值。误打误撞,跑到了别人家里。
如下代码,本意并不是想让p保存score变量的内存地址。如果恰好0x70fddc就是score的内存地址。则通过*p对变量的修改最终会导致score变量中的数据被修改。
int score=89;
//本意是想使用一个空闲的空间,误打误撞引用了 score 的地址
int* p=(int*)0x70fddc;
//会修改 score 中的值
*p=56;
std::cout<<score<<std::endl;
std::cout<<*p<<std::endl;
//输出
56
56
可以认为指针访问是变量名访问的另一种形式,所以在初始化指针变量时, 需要使用 &或 new 运算符合理计算出来的地址。指针变量必须是一个已经存在的、合法变量的内存地址。
类型一致初始化: 如下代码是错误的,千万不要认为会发生自动类型转换。num_p只能引用double类型变量的地址,这是语法层面约定。
int num=34;
//语法错误,声明指针时的数据类型,严格规定了指针变量能引用的变量类型
double* num_p=#
3.2.2 越界风险
指针越界: 指指针移动到了非法区域,如下代码:
int num=34;
int* num_p=#
std::cout<<"正常输出:"<<*num_p<<std::endl;
//指针移到了一个没有声明的区域
std::cout<<"移动指针输出:"<<*(num_p+1)<<std::endl;
输出结果:
正常输出:34
移动指针输出:7405060
虽然指针变量可以通过加上一个整型数字进行移动。但是一定要控制合法范围,否则会发生如上的非法访问,非法访问到的数据一旦用于数据逻辑,会存在很大的风险。
3.3 多级指针
指针变量本身也是一个存储块,它所在内存地址是否还可以保存在另一个指针变量中?
显然,这是可以的,如下代码:
//声明常规变量
int num=20;
//一级指针变量:用来保存 num 变量的地址
int* num_p=#
//二给指针变量,用来保存 num_p 变量的地址
int** num_p_p=&num_p;
int**表示二级指针类型,本质还是内存地址,是另一个指针变量的内存地址。
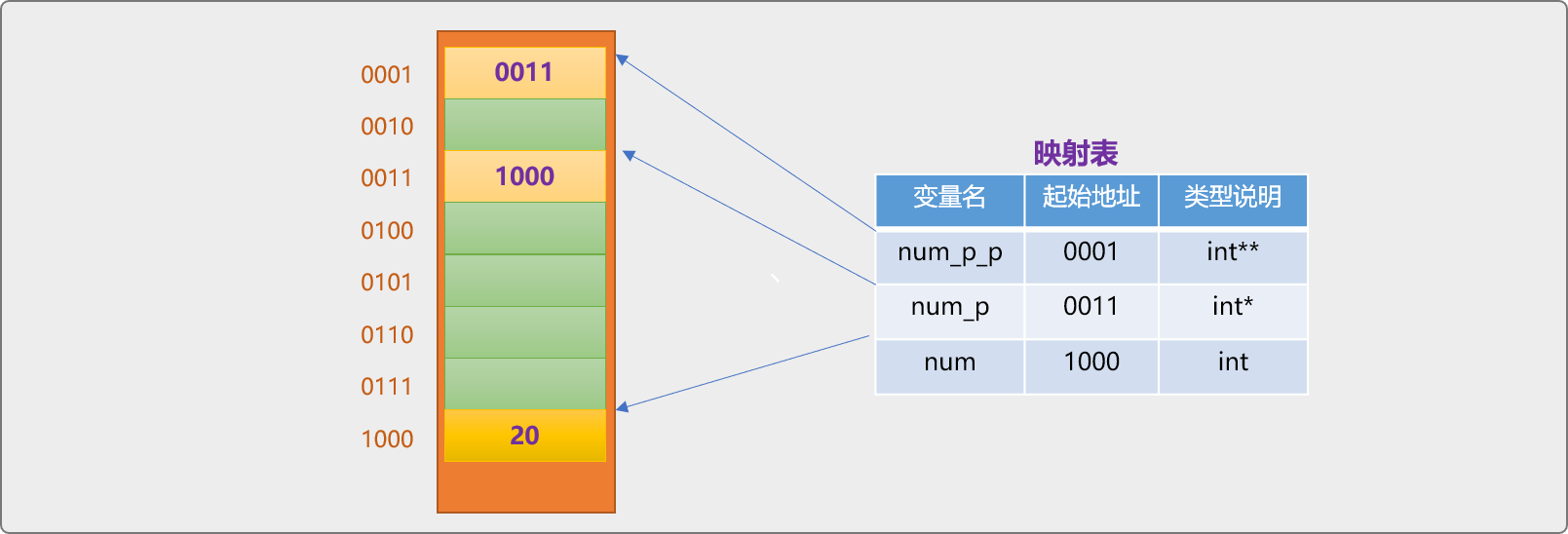
使用二级指针访问 num变量中的数据。
//……
*(*num_p_p)=30;
std::cout<<"输出:"<<num<<std::endl;
代码解释:
*num_p_p获取到num_p变量中的内存地址值1000。*(*num_p_p)利用上面返回的1000地址,找到变量num位置,并返回变量num的值。
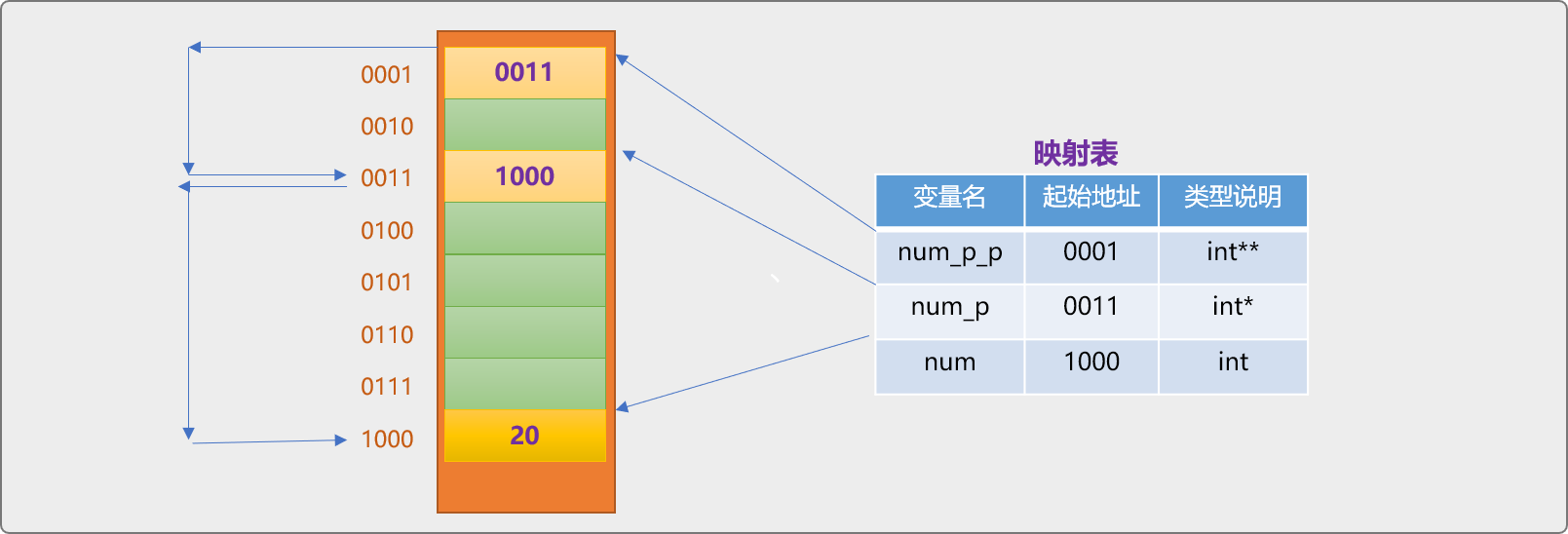
同理可以使用多维指针,如下是三维指针。
int num=20;
int* num_p=#
int** num_p_p=&num_p;
int*** num_p_p_p=&num_p_p;
*(*(*num_p_p_p))=30;
std::cout<<"输出:"<<num<<std::endl;
//输出:30
4. 总结
虽然可以通过使用指针提升内存的访问性能,但也因存在指针的自由性,易出现潜在风险。如JAVA在语法层面对指针使用做了限制,权衡利弊,虽然消弱了指针的自由性,同时也降低了代码的潜在风险。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】