

C++ 炼气期之数组探幽
1. 数组概念
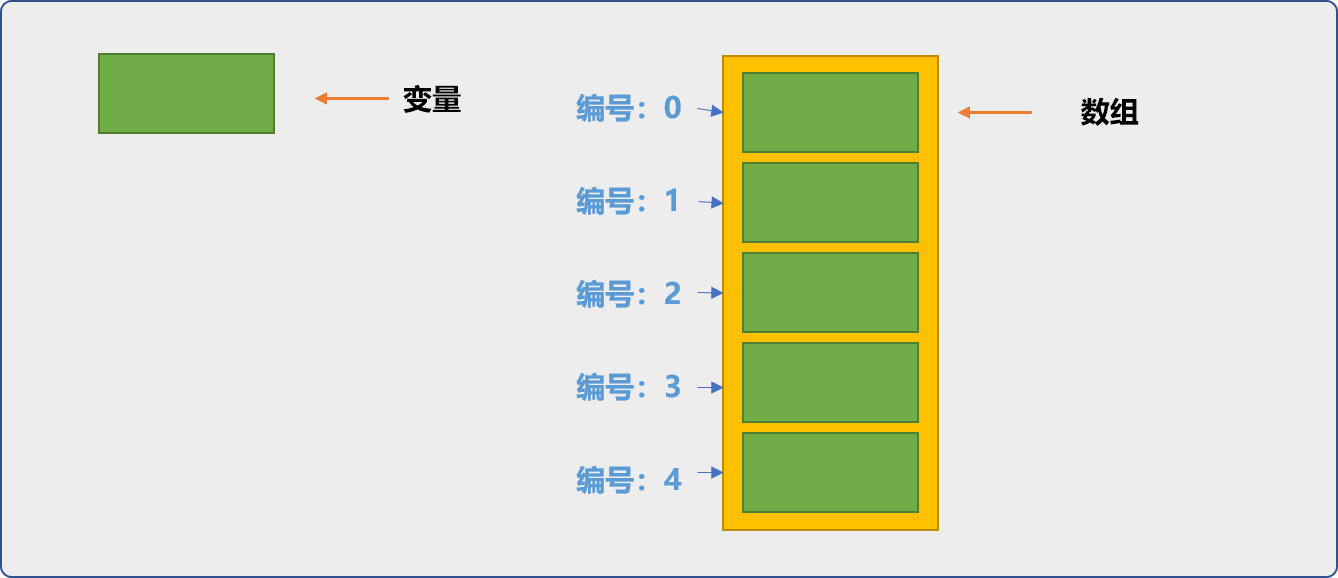
变量是内存中的一个存储块,大小由声明时的数据类型决定。
数组可以认为是变量的集合,在内存中表现为一片连续的存储区域,其特点为:
- 同类型多个变量的集合。
- 每一个变量没有自己的名字。
- 数组会为每一个变量分配一个位置编号 。
- 可以通过变量在数组中的位置编号(下标)使用变量。
C++中称数组为复合类型,复合类型指除了基本类型之外或通过基本类型组合而成的新类型。如类、结构体、枚举……
数组是一种数据结构,与栈、队列、树、图……这类数结构不同,数组是实体数据结构,有自己的物理内存描述。栈、队列、树……是抽象数据结构,或者说是一种数据存储思想,没有对应的物理存储方案,需开发者自行设计逻辑存储方案。
什么时候使用数组?
在需要保存大量同类型数据的应用场景下可以考虑选择数组。因数组中的变量是相邻的,如同一条藤上的瓜(顺藤摸瓜),访问起来非常方便快捷。
大部分抽象数据结构的底层都可借助数组来实现。
连续存储的优点一眼可知,但是连续也会带来新的问题,程序运行过程中,会产生内存碎片,当数组需要的空间较大时,底层逻辑可能无法腾出一大片连续空间来。
当需要考虑充分利用空间时,
链表当是首选。
下面,通过数组的使用流程,让我们全方面了解数组。
2. 创建数组
根据数组在内存中的存储位置,有 2 种创建方式:
- 静态创建。
- 动态创建。
2.1 静态创建
2.1.1 语法
创建数组时需要指定 3 方面信息:
数组名:数组名就是变量名,只是这个名称指的是一片连续区域。数据类型:数组用来保存什么样类型的数据。数组长度:编译器需要根据数组大小开辟空间。
int num[10];
如上语法,创建了可以存储 10 个整型数据的数组。
创建数组后,怎么访问数组中的变量?
编译器会为数组中的 10 个 int 存储块从 0开始编号。编号从 0开始,到数组长度-1结束,编号也称为下标。如果需要访问数组中的第一个变量中的数据,则如下代码可实现:
int num[10];
cout<<num[0]<<endl;
正因为数组的下标属性,数组通常借助循环语法结构进行整体遍历。
创建数组后是否存在数据?
遍历一次数组,便可以看到数组中所有的数据信息。
int num[10];
for(int i=0;i<10;i++){
cout<<num[i]<<endl;
}
输出结果可能会让你摸不着头。这是啥意思?
1
0
4254409
0
0
0
34
0
0
0
创建数组后,数组中会有数据信息,是内存中相应位置曾经存储过的或由编译器随机生成的数据。对于创建数组初衷(保存自己的数据)的你而言,这都是垃圾数据。
随机数据:每一次运行上述代码,结果可能都不一样。
所以,必须对数组进行初始化,这样数组中的数据才会有意义。
2.1.2 初始化
初始化指创建数组后为数组中的变量指定初始值。
初始化语法:
- 创建后通过循环语法结构赋值。
int num[10];
for(int i=0; i<10; i++) {
num[i]=i*10;
}
- 单个变量赋值。
int num[10];
num[0]=10;
- 边创建边赋值,
{}符号可以用来表示数组字面常量。
//正确
int num[10]={1,3,4,9};
在赋值时,实际指定的值可以少于数组的长度。如果反过来,如下代码则行不通。
//错误
int num[3]={1,3,4,9};
上述赋值代码,实际值超过数组创建时的长度约束,语法上不能通过。如果边创建、边赋值分成 2 行,也是不行的。如下代码是错误的。
int num[3];
//错误
num=={1,3,4,9};
如下代码,省略数组长度也是可以的,编译器会根据给定的值判断出数组长度。
int num[]={1,3,4,9};
- 全部初始化为
0。如下代码,初始化时只指定一个值且为0时,这里的语义不是指给数组中的第一个变量赋值,而是为数组中的所有变量指定初始值为0。
int num[5]={0};
//输出数组所有值
for(int i=0; i<5; i++) {
cout<<num[i]<<endl;
}
输出结果:
0
0
0
0
0
如果用下面的代码进行初始化,语义是:数组的第一个变量赋值为 1,其余变量赋值都为 0。
int num[5]={1,0};
for(int i=0; i<5; i++) {
cout<<num[i]<<endl;
}
输出结果:
1
0
0
0
0
理解上述语法的语义后,以此类推,对于下面的代码,想必很容易猜到输出结果:
int num[5]={1,2,0};
for(int i=0; i<5; i++) {
cout<<num[i]<<endl;
}
C++11中提供更清晰、简洁、安全的初始化语法。如下语法,是不是很简洁、惊艳。数组和{}之间可以不用等于号,太体贴了,生怕你多敲一个字母,会手痛。且为数组中的每一个变量赋值0。没有多余的废话。
int num[5] {};
for(int i=0; i<5; i++) {
cout<<num[i]<<endl;
}
当然,你一定要加一个等于号让代码符合你曾经的认知也是可以的。
int num[5]= {};
除此之外,对数组初始化时,禁止类型宿窄转换。如下代码,会有编译警告提示,2.5是浮点类型,存储存到 int类型数组中,是类型缩窄。C++11是禁止的。
int num[5] ={3,2.5};
2.1.3 越界问题
C++中使用数组,没有访问越界一说。所谓访问越界,指下标超过数组创建时指定的大小范围。
越界在
Java语言中认定是语法错误。
int num[5];
//理论是越界的
num[6]=20;
for(int i=0; i<7; i++) {
//输出了 7 个数据
cout<<num[i]<<endl;
}
上述代码,创建数组时,确定了数组长度为 5,其有效下标应该是0~4。但 num[6]=20能正确执行且循环输出时居然能得到 20。
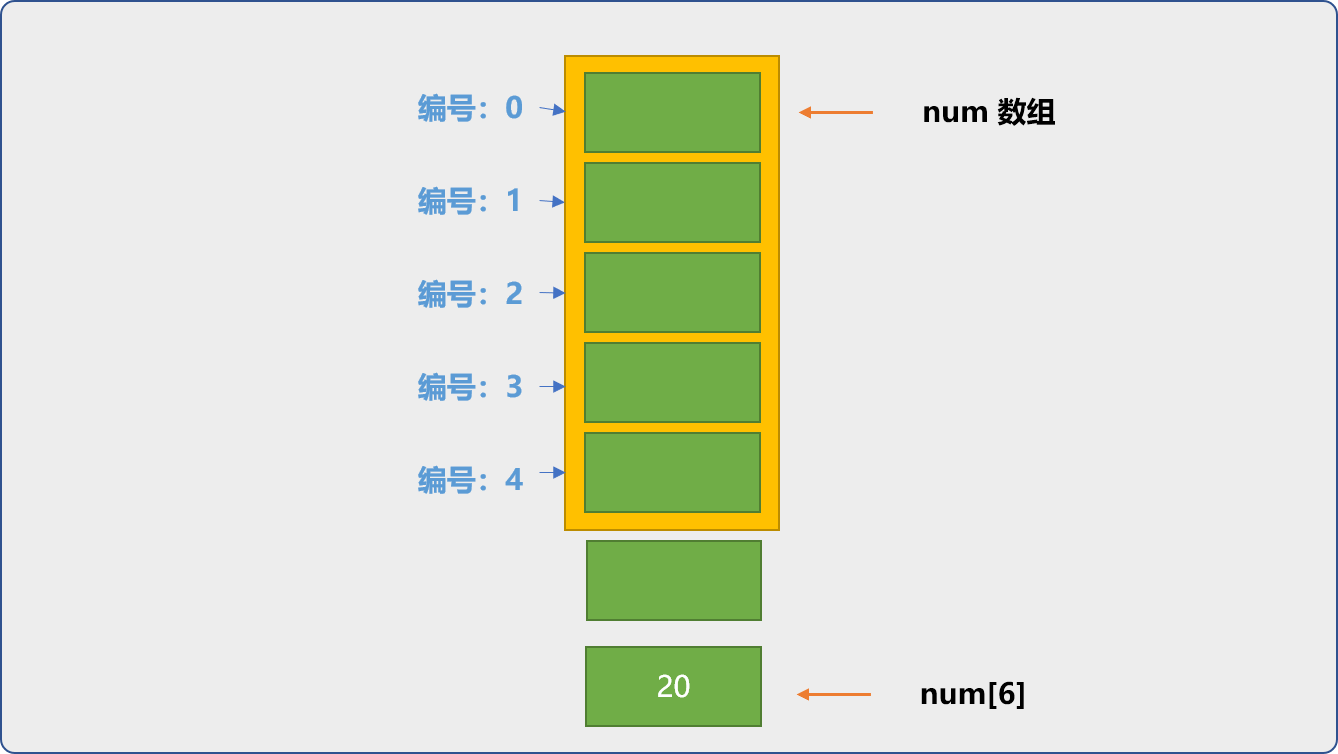
0
0
34
0
0
0
20
C++并不会阻止你的访问超过数组边界,但是,开发者需要从源头上切断这种行为。类似于相邻两家,关系很好,相互之间不设阻隔墙,但不意味着你能随意出入对方家里。
2.2.4 数组与指针
数组在内存中的存储结构有 2 个部分:
- 存储数组数据的内存区域。
- 存储数组首地址的内存变量。
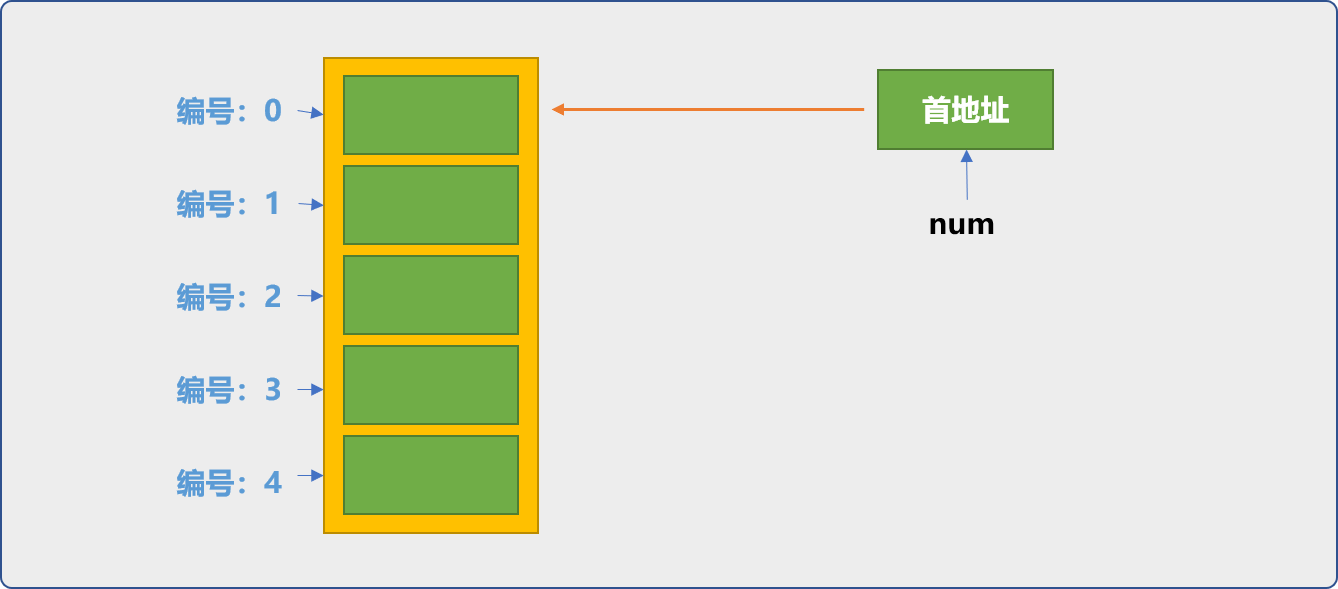
数组名本质是指针变量,保存着数组的首地址,也是第一个存储位置。
int num[5]={4,1,8,2,6};
cout<<"数组的地址:"<<num<<endl;
//输出结果:
//数组的地址:0x70fe00 16进制描述的内存地址
如果要得到数组第一个位置的数据,则需要使用*运算符。
int num[5]={4,1,8,2,6};
cout<<"数组中的第一个位置的数据:"<<*num<<endl;
//数组中的第一个位置的数据:4
除了使用*运算符,还可以使用[下标]语法。两者语法上有差异,但是语义是一样的。可以认为[下标]访问语法是指针访问语法的简化版。
int num[5]={4,1,8,2,6};
cout<<"数组中的第一个位置的数据:"<<num[0]<<endl;
//数组中的第一个位置的数据:4
如果要访问其它位置的数据,可以通过移动指针实现。
Tip:
num+1可以让指针移到数组的下一个变量位置。这里的1具体移动多少,由创建数组时指定的数据类型决定,如本文数组是int类型,1便是移动4 字节。
int num[5]={4,1,8,2,6};
cout<<"数组中第二个位置的数据:"<<*(num+1)<<endl;
//数组中第二个位置的数据:1
当然,完全可以使用[下标]替代。
int num[5]={4,1,8,2,6};
cout<<"数组中第二个位置的数据:"<<num[1]<<endl;
指针是C++语言的一大特色,能够让开发者直接操作内存地址(属于直接硬件操作),正因为此原因,编译器无法干涉,所以指针移动的范围只受限于物理内存大小的影响。如下代码能正常运行。
int num[5]={4,1,8,2,6};
//完全超界,但人家就是能运行 ,指针的手能伸到天涯海角
for(int i=0;i<1000000;i++){
cout<<*(num+i)<<endl;
}
了解指针的特性后,也就不会奇怪为什么访问数组时能够越界。使用指针时务必谨慎,需要靠个人行为对之约束。
2.2.5 小结
通过静态创建语法创建的数组,称为静态数组,其特点如下:
- 在
编译时,就需要为数组指定大小,或说数组大小在编码时就必须给定。 - 静态创建数组时不能使用
auto关键字。
//错误语法
auto num[5];
- 数组名中保存有数组大小的信息。如下代码可以获取到数组长度。
int num[10];
//sizeof得到num实际占用的内存空间,以字节为单位
int len=sizeof(num)/4;
cout<<len;
//输出:10
- 静态数组的数据保存在
栈中,在编译期间进行空间分配,在生命周期结束后自动回收。
2.2 动态创建
动态创建:指数组的大小可以在运行时动态指定,除此之外,和静态创建的底层区别在于存储位置的不同,动态创建的数组的数据存储在堆中。
堆的特点:
- 开发者可以根据自己的需要提出空间使用申请。
- 当空间不再需要时,开发者需要手动释放空间。
先看一下创建语法:
int *num=new int[10];
代码解释:
num是指针变量,用来保存数组的首地址。new是运算符,其作用是在堆中开辟空间,并把空间的首地址返回。int[10],指开辟空间的大小,以及保存什么类型的数据。
num是首地址,也是数组中第一个位置的地址。
int *num=new int[10];
//初始化第一个位置的数据
*num=10;
cout<<"第一个位置的数据:"<<*num<<endl;
如下通过对整个数组进行初始化:
int *num=new int[10];
for(int i=0; i<10; i++) {
*(num+i)=i*10;
}
for(int i=0; i<10; i++) {
cout<<*(num+i)<<endl;
}
输出结果:
0
10
20
30
40
50
60
70
80
90
同样可以使用[下标]语法结构,对访问数组。
int *num=new int[10];
for(int i=0; i<10; i++) {
num[i]=i*10;
}
for(int i=0; i<10; i++) {
cout<<num[i]<<endl;
}
动态数组可以在运行时改变数组的大小。静态创建方式是一锤定音的买卖,一旦确定后,就不能再改变。如下代码是正确的。
int *num=new int[10];
num=new int[20];
正因为动态数组的动态性,无法通过代码获得它的长度。
int *num=new int[10];
cout<<sizeof(num)/4<<endl;
//输出结果:2,并不是数组的长度。
当动态数组的使命结束后,开发者需要使用 delete运算符手动释放数组所占用的空间。
int *num=new int[10];
//delete num;语法上可行,会产生不确定行为
delete [] num;
这里要注意,如果不加[],语法上是没有问题的,但是,会有不确定的因素存在,所以!请务必加[]。
3. 数组性能分析
得益于数组内存结构的连续性,只要知道数据的位置,便能快速访问到。查询时间度复杂度可以达到O(1)。在查询类的应用场景下,数组存储方案应该成为首选。
当在数组中插入数据时,需要把数据向后移动为插入的数据挪出位置,且需要在创建数组时预留足够多的空间,否则会有数据丢失的风险。
//最后一位为预留位置
int num[10]= {1,2,3,4,5,6,7,8,9,0};
for(int i=0; i<10; i++) {
cout<<num[i]<<"\t";
}
cout<<endl;
int newNum=0;
int pos=0;
cout<<"请输入要插入的数据:"<<endl;
cin>>newNum;
cout<<"请输入要插入的位置:"<<endl;
cin>>pos;
//从插入位置的数据向后移动
for(int i=9; i>pos-1; i--) {
num[i]=num[i-1];
}
num[pos-1]=newNum;
for(int i=0; i<10; i++) {
cout<<num[i]<<"\t";
}
运行结果:
1 2 3 4 5 6 7 8 9 0
请输入要插入的数据:
13
请输入要插入的位置:
5
1 2 3 4 13 5 6 7 8 9
删除数据时,需要把数据删除位置之后的数据向删除位置移动(向前)。
int num[10]= {1,2,3,4,5,6,7,8,9,10};
for(int i=0; i<10; i++) {
cout<<num[i]<<"\t";
}
cout<<endl;
int pos=0;
cout<<"请输入要删除的位置:"<<endl;
cin>>pos;
//从插入位置的数据向前移动
for(int i=pos-1; pos<8; i++) {
num[i]=num[i+1];
}
//最后一位补 0
num[9]=0;
for(int i=0; i<10; i++) {
cout<<num[i]<<"\t";
}
运行结果:
1 2 3 4 5 6 7 8 9 10
请输入要删除的位置:
4
1 2 3 5 6 7 8 9 10 0
在数组中插入、删除数据的时间复杂度为O(n)。
在频繁需要插入、删除的应用场景下,可以选择比数组性能更好的链表。
4. 总结
本文介绍了数组的 2 种创建方式,并对数组的操作性能做了简单的分析。数组遍历时是通过底层的指针移动来实现的。指针是C系列语言的一大特点,是一把双刃剑,用的好能御敌千里之外,用的不好!bug满天飞。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!