day05 模块学习
目录
1.模块简介
2.collections模块常见方法
3.random模块
4.time模块
5.pickle模块
6.json模块
7.os模块
8.sys模块
9.正则表达式
10.re模块
内容
一.模块简介
概述:模块就是一个py文件或者装有py文件的文件夹
import 文件
from 文件(包) import 具体内容
模块的简单分类:
1.内置模块
2.自定义模块
3.第三方模块
二.collections模块常见方法
collections模块主要封装了了⼀一些关于集合类的相关操作. 比如, 我们学过的Iterable, Iterator等等. 除了了这些以外, collections还提供了了⼀一些除了了基本数据类型以外的数据集合类 型. Counter, deque, OrderDict, defaultdict以及namedtuple
1.Counter() 计数器方法
例子1:统计每个字符出现的次数,结果以键值对的形式呈现,但是外面包了一个小括号
c = Counter("周杰伦的歌曲很经典,大部分的传唱度都很高,很多人都很喜欢周杰伦")
print(c)
例子2:通过get查看指定的字符出现次数
from collections import Counter
c = Counter("周杰伦的歌曲很经典,大部分的传唱度都很高,很多人都很喜欢周杰伦")
print(c.get("周"))
例子3:统计列表里面周杰伦这个元素出现的次数
lst = ["周杰伦","华晨宇","TFBOLS","周杰伦"]
r = Counter(lst)
obj = r.get("周杰伦")
print(obj)
2.defaultdict()默认值字典
例子1:当查询一个不存在的key时会指定给你先指定默认的那个值,之后进行显
from collections import defaultdict
d = defaultdict(lambda :123) ps:定义字典默认值
d["Joy"] = "周杰伦"
print(d.get("Joy"))
print(d["wlh"]) ps:查询一个不存在的key
print(d)
3.deque 双向队列
顾名思义:两边都可以进行添加删除操作。
概述:在双向队列之前需要了解两种数据结构
1.栈:FILO 先进后出->砌墙的砖头, 老师傅做馒头 (目前比较类似于栈的有列表,后去补创建栈的方法....)栈的单词stack
2.队列:FIFO 先进先出-> 买火⻋车票排队, 所有排队的场景
队列的queue模块
import queue
q = queue.Queue() ps:创建队列,打印q的时候是一串内存地址,如果要获取值需要使用get方法
q.put("花花")
q.put("毛毛")
q.put("王大陆")
print(q)
print(q.get()) ps:按照创建的先后顺序进行取值,也就是队列的特点了。
print(q.get())
print(q.get())
deque常见操作
from collections import deque
d = deque()
d.append("牡丹花")
d.appendleft("樱桃花")
d.append("腊梅")
d.append("兰花")
d.appendleft("罂粟花")
print(d)
print(d.pop())# "兰花"
print(d.popleft()) # "罂粟花"
print(d.pop())# "腊梅"
print(d.popleft()) #"樱桃花"
print(d.popleft()) # "牡丹花"
ps:append默认从右边添加 appendleft从左边添加。 pop默认从右边删除,popleft从左边开始删除
4.nametuple()
命名元组, 顾名思义. 给元组内的元素进⾏行行命名. 比如. 我们说(x, y) 这是⼀一个元组. 同 时. 我们还可以认为这是⼀一个点坐标.
这时, 我们就可以使⽤用namedtuple对元素进⾏行行命名
from collections import namedtuple
nt = namedtuple("point",["x","y"])
p = nt(1,2)
print(p)
print(p.x)
print(p.y)
5.orderdict
orderdict 顾名思义. 字典的key默认是⽆无序的. 而OrderedDict是有序的
dic = {'a':'娃哈哈', 'b':'薯条', 'c':'胡辣汤'}
print(dic)
from collections import OrderedDict
od = OrderedDict({'a':'娃哈哈', 'b':'薯条', 'c':'胡辣汤'})
print(od)
defaultdict: 可以给字典设置默认值. 当key不存在时. 直接获取默认值:
from collections import defaultdict
dd = defaultdict(list)
print(dd["娃哈哈"])
三.random模块
所有关于随机相关的内容都在random模块中.
print(random.random()) ps:0~1之间的小数
print(random.uniform(3, 10)) ps:3~10之间的随机小数
print(random.randint(1, 10)) ps:1~10之间的随机整数
print(random.randrange(1, 10, 2)) ps:1~10之间的随机奇数
print(random.choice([1, '周杰伦', ["盖伦", "胡辣汤"]])) ps:随机打印一个元素
print(random.sample([1, '23', [4, 5]], 2)) ps:随机组合列表外的一个数和列表
lst = [1, 2, 3, 4, 5, 6, 7, 8] ps:随机打乱顺序
random.shuffle(lst)
print(lst)
四.time模块
import time
查看系统时间,拿到的是一个数字从1970-01-01 00:00:00开始计算
1.时间戳转化成格式化时间的过程 首先拿到一个时间戳->其次转换成结构化时间->最后方可转化成格式时间
t1 = time.time()
print(t1) #时间戳
t = time.localtime() #结构化时间
print(t)
t2 = time.strftime("%Y-%m-%d %H:%M:%S",t)
print(t2) ps:格式化时间
2.把用户输入的格式化时间转换成系统可识别的时间戳,转化过程:获取到用户输入的一个格式化时间->通过strptime转换成结构化时间->最后通过mktime函数转换成时间戳
obj = input("请输入日期(%Y-%m-%d %H:%M:%S):")
obj1 = time.strptime(obj,"%Y-%m-%d %H:%M:%S")
obj2 = time.mktime(obj1)
print(obj2)
3.算时间差
import time
s1 = "1989-01-02 8:00:00"
n1 = time.mktime(time.strptime(s1, "%Y-%m-%d %H:%M:%S"))
print(n1)
s2 = "1989-01-02 14:35:00"
n2 = time.mktime(time.strptime(s2, "%Y-%m-%d %H:%M:%S"))
diff = n2 - n1
display_min = diff // 60
display_hour = display_min // 60
display_min = display_min % 60
print(display_hour,display_min)
print(f"{display_hour}小时{display_min}分钟")
实例:计算两个时间之间差了多少年月日时分秒
true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S'))
time_now=time.mktime(time.strptime('2019-05-05 11:00:00','%Y-%m-%d %H:%M:%S'))
diff_time=time_now-true_time
struct_time = time.localtime(diff_time)
print('过去了了%d年年%d⽉月%d天%d⼩小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1,struct_time.tm_mday,struct_time.tm_hour,struct_time.tm_min,struct_time.tm_sec))
4.常用格式化选项说明已经结构化时间说明
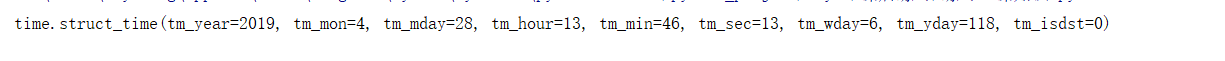
分别对应:年,月,日,时,分,秒,周几(默认从0开始),今年的第多少天,是不是夏令营时间daylight saving time(1.是夏令营时间,0.不是夏令营时间,-1.不详)
日期格式化的标准
%y 两位数的年年份表示(00-99)
%Y 四位数的年年份表示(000-9999)
%m ⽉月份(01-12)
%d ⽉月内中的⼀一天(0-31)
%H 24⼩小时制⼩小时数(0-23)
%I 12⼩小时制⼩小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的⽉月份名称
%B 本地完整的⽉月份名称
%c 本地相应的⽇日期表示和时间表示
%j 年年内的⼀一天(001-366)
%p 本地A.M.或P.M.的等价符
%U ⼀一年年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W ⼀一年年中的星期数(00-53)星期⼀一为星期的开始
%x 本地相应的⽇日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
五.pickle模块
pickle. 可以将我们python中的任意数据类型转化成bytes并写入到⽂文件中. 同样也 可以把⽂文件中写好的bytes转换回我们python的数据. 这个过程被称为反序列列化
1.序列化一个列表到文件里面然后又反序列化出来
import pickle
lst = ["张一山", "李四", "王二麻子"]
pickle.dump(lst,open("pickle.dat",mode="wb"))
f = open("pickle.dat",mode="rb")
ll = pickle.load(f)
print(ll)
2.在文件里面序列化和发序列化数据
import pickle
lst = ["张一山", "李四", "王二麻子"]
s = pickle.dumps(lst)
print(s) ps:此时文件的形式以字节的格式呈现
s = b'\x80\x03]q\x00(X\t\x00\x00\x00\xe5\xbc\xa0\xe4\xb8\x80\xe5\xb1\xb1q\x01X\x06\x00\x00\x00\xe6\x9d\x8e\xe5\x9b\x9bq\x02X\x0c\x00\x00\x00\xe7\x8e\x8b\xe4\xba\x8c\xe9\xba\xbb\xe5\xad\x90q\x03e.'
s1 = pickle.loads(s)
print(s1)
总结:dump 是把字符序列化到文件里面,load是把文件里面的字节读出来,有点类似于encode和decode。而dumps和loads主要用于终端里面交互。
pickle序列列化的内容是⼆二进制的内容(bytes) 不是给⼈人看的。
六.json模块
json是我们前后端交互的枢纽. 相当于编程界的普通话. ⼤大家沟通都⽤用 json. json全 称javascript object notation. 翻译过来叫js对象简谱.
1.字典序列化
import json
dic = {"a": "⼥女女王", "b": "萝莉", "c": "⼩小清新"}
s = json.dumps(dic,ensure_ascii=False)
print(s)
s = '{"a": "⼥女女王", "b": "萝莉", "c": "⼩小清新"}'
s1 = json.loads(s)
2.文件里面操作
lst = [{"a": 1}, {"b": 2}, {"c": 3}]
f = open("test.json", mode="w", encoding="utf-8")
for el in lst:
s = json.dumps(el, ensure_ascii=True) + "\n"
f.write(s)
f.close()
f = open("test.json", mode="r", encoding="utf-8")
for line in f:
dic = json.loads(line.strip())
print(dic)
f.close()
七.os模块
所有和os相关的模块都在os下
os.makedirs('dirname1/dirname2') 生成多层递归目录
os.removedirs('dirname1')若⽬目录为空,则删除,并递归到上⼀一级⽬目录,如若也为空,则删 除,依此类推
os.mkdir('dirname') ⽣生成单级⽬目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空⽬目录,若⽬目录不不为空则⽆无法删除,报错;相当于shell中 rmdir dirname
lst = os.listdir('dirname')
print(lst) 列列出指定⽬目录下的所有⽂文件和⼦子⽬目录,包括隐藏⽂文件,并以列列表⽅方式 打印
递归查询D盘下的所有文件
def func(filepath, n):
lst = os.listdir(filepath)
for item in lst: # 文件名 day01
fp = os.path.join(filepath, item) # D:\PyCharmProject\周末26期\day01
if os.path.isdir(fp):
print("\t"*n, item)
func(fp, n+1) # 开始递归
else:
print("\t"*n,item) # 文件名
# open(fp,mode="w").write(123)
func("D:/", 1)
os.remove() 删除⼀一个⽂文件 os.rename("oldname","newname") 重命名⽂文件/⽬目录
os.system("bash command") 运⾏行行shell命令,直接显示 os.popen("bash command).read() 运⾏行行shell命令,获取执⾏行行结果
os.stat('path/filename') 获取⽂文件/⽬目录信息
os.getcwd() 获取当前⼯工作⽬目录,即当前python脚本⼯工作的⽬目录路路径
os.chdir("dirname") 改变当前脚本⼯工作⽬目录;相当于shell下cd
os.path.abspath(path) 返回path规范化的绝对路路径
os.path.split(path) 将path分割成⽬目录和⽂文件名⼆二元组返回
os.path.dirname(path) 返回path的⽬目录。其实就是os.path.split(path)的第⼀一个元素
os.path.basename(path) 返回path最后的⽂文件名。如何path以/或\结尾,那么就会返回空值。
os.path.exists(path) 如果path存在,返回True;如果path不不存在,返回False
os.path.isabs(path) 如果path是绝对路路径,返回True
os.path.isfile(path) 如果path是⼀一个存在的⽂文件,返回True。否则返回False
os.path.isdir(path) 如果path是⼀一个存在的⽬目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路路径组合后返回,第⼀一个绝对路路径之前的参数
os.path.getatime(path) 返回path所指向的⽂文件或者⽬目录的最后访问时间
os.path.getmtime(path) 返回path所指向的⽂文件或者⽬目录的最后修改时间
os.path.getsize(path) 返回path的⼤大
# 特殊属性:
os.sep 输出操作系统特定的路路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使⽤用的⾏行行终⽌止符,win下为"\r\n",Linux下为"\n"
os.pathsep 输出⽤用于分割⽂文件路路径的字符串串 win下为;,Linux下为:
os.name 输出字符串串指示当前使⽤用平台。win->'nt'; Linux->'posix'
八.sys模块
所有和python相关的都在sys模块
sys.argv 命令⾏行行参数List,第⼀一个元素是程序本身路路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路路径,初始化时使⽤用PYTHONPATH环境变量量的值
sys.platform 返回操作系统平台名称
内容详情待续............
九.正则表达式
http://tool.chinaz.com/regex/进⾏行行在线测试
常用的元字符
\w 匹配字符字母下划线
\W 匹配非数字字母下划线
\d 匹配数字
\D 匹配非数字
\s 匹配空白
\S 匹配非空白
\t 匹配制表符
\n 匹配换行符
\b 匹配单词以什么结尾
. 匹配任意一个字符除了换行以外
^ 匹配以什么开始
$ 匹配以什么结束
a|b 匹配a或者b字符
[^ ] 取反
()匹配括号内的表达式,也表示一个组
[...] 匹配中括号中的字符
量词:
* 匹配前面的字符出现0次或者多次
?匹配前面的字符出现0次或者1次
+ 匹配前面的字符出现1次或者多次
{n} 匹配括前面的字符n次
{n,} 匹配括号前面的内容n或或者多次
{n,m} 匹配前面的字符n次到m次
小例子
.* 贪婪匹配
.*? 惰性匹配
?P<name>
匹配邮箱\w+@\w+\.(com|net)
匹配身份证 \d{17}[\d|x]|\d{15}
十.re模块
1. findall 查找所有. 返回list
2. search 会进⾏行行匹配. 但是如果匹配到了了第⼀一个结果. 就会返回这个结果. 如果匹配不 上search返回的则是None
3. match 只能从字符串串的开头进⾏行行匹配
4. finditer 和findall差不多. 只不过这时返回的是迭代器
5. split 按照指定的字符进行切割
6. sub 进行替换
7.subn 进行替换以后还会显示替换的次数并且以元组的形式返回
8. compile 将正则表达式编译成一个正则表达式对象
应用实例:
s = "<span><div>倚天屠龙</div><div>少林武当</div></span>fasdfasdfsda</div>"
it = re.finditer(r"<div>.*</div>",s)
for i in it:
print(i.group()) 贪婪匹配结果如下:
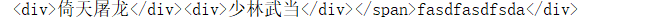
此时我需要找到我想要的数据
<div>倚天屠龙</div><div>少林武当</div>

ps:在贪婪匹配的模式后面加?表示惰性匹配,而此时我也能得到我想要的数据but我只要div里面的有效数据,操作如下:

ps:在原来的基础上增加了小括号?P<name>
踩坑总结:.* 点是匹配除了换行符以外的所有,在匹配多行的时候容易出问题,此时在匹配的末尾加上re.S解决。
踩坑补充1:在要匹配的选项里面写?: 取消权限
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组⾥里里内容返回,如果想要匹 配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
踩坑补充2:split切割
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的结果是不不同的,
#没有()的没有保留留所匹配的项,但是有()的却能够保留留了了匹配的项,
#这个在某些需要保留留匹配部分的使⽤用过程是⾮非常重要的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号