
MESI(缓存一致性协议)
概述
由于内存的运行速度和CPU的运行速度相差太多,所以现代计算机CPU都不是直接操作内存,而是直接操作寄存器和高速缓存,如果只有一个CPU这个事情就很简单,但是如果计算机中有多个核,那每个CPU都从主内存中读取了同一个变量,如何保证缓存的一致性,就变得非常麻烦,现在常用的解决办法有两种。
- 总线锁定:当某个CPU需要修改某个数据的时候,通过锁住内存总线,使得别的CPU无法访问内存中的数据,从而保证缓存的一致性,但这种实现方式会导致CPU执行效率降低,现在很少被使用。
- 缓存锁:当一个CPU要修改缓存中的变量时,会对缓存加锁,同时会通过总线通知别的CPU,让他们的变量副本失效,这样同样可以保证一次只有一个CPU修改变量的值,从而保证缓存一致性。
以上两种方法的实质作用都是为了防止读取到脏数据和更新的结果无效。
高速缓存结构
在介绍缓存一致性协议之前有必要先介绍一下高速缓存的数据的组织形式。因为把高速缓存的数据结构介绍清楚,有助于理解下面MESI协议。
高速缓存的结构和jdk中的HashMap的结构有点类似,都是采用数组进行分桶,之后采用拉链法挂到对应的桶上,具体结构如下:
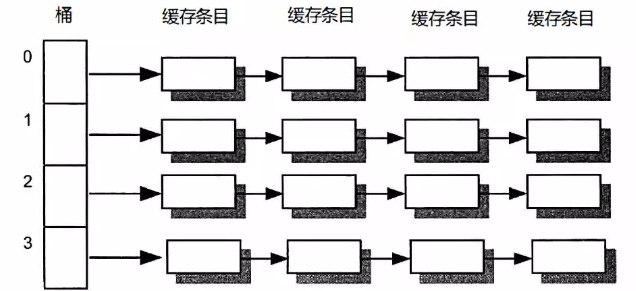
链表中节点名称叫做cache entry,下面看一下cache entry的结构:
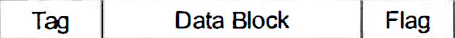
其中tag用来定位cache entry,data block用来保存缓存的数据,flag就是重点了,这个标识就是用来标注当前节点的状态,对应下面要介绍的MESI协议的四种状态,分别位M,E,S,I。
MESI协议介绍
有了上面的铺垫,下面就开始介绍MESI协议,MESI是四个单词的首字母缩写,Modified修改,Exclusive独占,Shared共享,Invalid无效,下面就简要介绍一下这四种状态。
M:表示当前CPU的高速缓存中的变量副本是独占的,而且和主存中的变量值不一致,而且别的CPU的flag不可能是这个状态。如果别的CPU想要读取变量的值,不能直接读主内存中的值,而是需要将处于M状态的变量刷新回主内存才可以。
E:表示当前CPU的高速缓存中的变量副本是独占的,别的CPU高速缓存中该变量的副本不能处于该状态,但是,处于E状态的高速缓存变量的值和主内存中的变量值是一致的。
S:处于S状态表示CPU中的变量副本和主存中数据一致,而且多个CPU都可以处于S状态,举例,当多个CPU读取主内存的值的时候高速缓存的flag就处于S状态。
I:表示当前CPU的高速缓存的变量副本处于不合法状态,不可以直接使用,需要从主内存重新读取,flag的初始状态就是I。
MESI状态转换
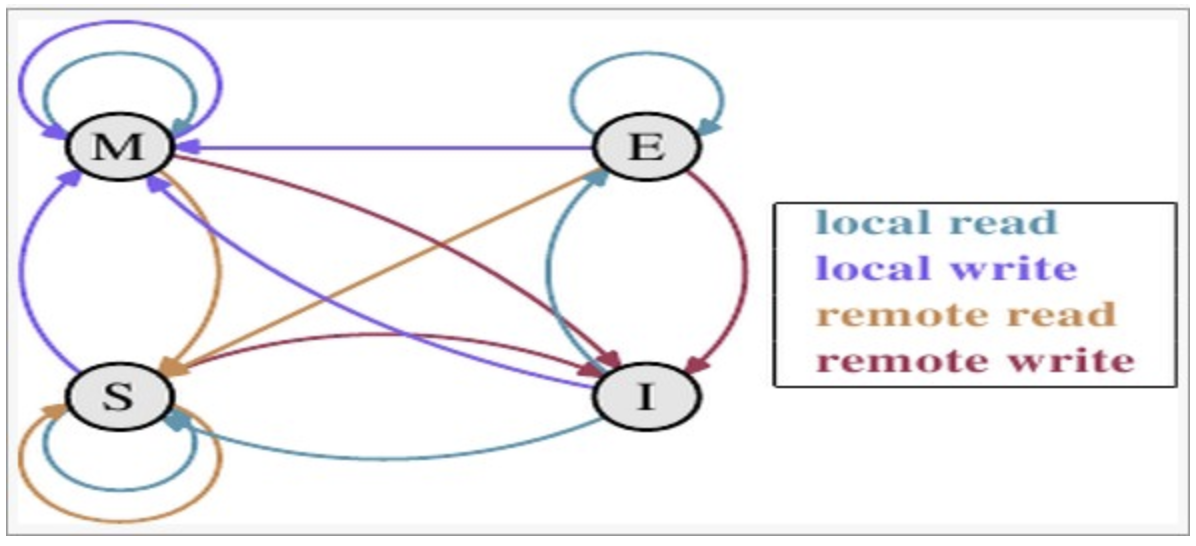
说明:
- local read(本地读取):本地cache读取本地cache
- local write(本地写入):本地cache写入本地cache
- remote read(远端读取):其他cache读取本地cache
- remote write(远端写入):其他cache写入本地cache
上图切换解释:
| 状态 | 触发本地读取 | 触发本地写入 | 触发远端读取 | 触发远端写入 |
|---|---|---|---|---|
| M状态(修改) | 本地cache:M 触发cache:M 其他cache:I |
本地cache:M 触发cache:M 其他cache:I |
本地cache:M→E→S 触发cache:I→S 其他cache:I→S 同步主内存后修改为E独享,同步触发、其他cache后本地、触发、其他cache修改为S共享 |
本地cache:M→E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 同步和读取一样,同步完成后触发cache改为M,本地、其他cache改为I |
| E状态(独享) | 本地cache:E 触发cache:E 其他cache:I |
本地cache:E→M 触发cache:E→M 其他cache:I 本地cache变更为M,其他cache状态应当是I(无效) |
本地cache:E→S 触发cache:I→S 其他cache:I→S 当其他cache要读取该数据时,其他、触发、本地cache都被设置为S(共享) |
本地cache:E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 当触发cache修改本地cache独享数据时时,将本地、触发、其他cache修改为S共享.然后触发cache修改为独享,其他、本地cache修改为I(无效),触发cache再修改为M |
| S状态(共享) | 本地cache:S 触发cache:S 其他cache:S |
本地cache:S→E→M 触发cache:S→E→M 其他cache:S→I 当本地cache修改时,将本地cache修改为E,其他cache修改为I,然后再将本地cache为M状态 |
本地cache:S 触发cache:S 其他cache:S |
本地cache:S→I 触发cache:S→E→M 其他cache:S→I 当触发cache要修改本地共享数据时,触发cache修改为E(独享),本地、其他cache修改为I(无效),触发cache再次修改为M(修改) |
| I状态(无效) | 本地cache:I→S或者I→E 触发cache:I→S或者I →E 其他cache:E、M、I→S、I 本地、触发cache将从I无效修改为S共享或者E独享,其他cache将从E、M、I 变为S或者I |
本地cache:I→S→E→M 触发cache:I→S→E→M 其他cache:M、E、S→S→I |
既然是本cache是I,其他cache操作与它无关 | 既然是本cache是I,其他cache操作与它无关 |
以上状态转换过程,是博客园的一个大佬总结的,这里直接拿过来使用了,抱歉,上面已经注明出处。在原文中作者并没有做过多的解释对于上面的转换过程,这里我就做一下解释。
上面每个单元格中都有三个cache,介绍一下
- 本地cache,可以认为就是其中的一个CPU中的cache
- 触发cache,可以认为是触发了read或者写操作的CPU的cache,如果触发cache就是本地cache,那这两个相同
- 其他cache,除了上面介绍的两个CPU的cache(如果本地cache就是触发cache,就只有一个)其他的CPU的cache
最左边的状态,可以认为就是本地cache的状态,上面的表格就是当本地的cache分别处于M、E、S、I 这四种状态,触发cache发生读操作或者写操作之后,每个cache状态发生的变化。
MESI消息
上面只是给出了MESI状态的转换,但是并没有给出如果某个CPU发生读或者写操作,CPU之间通过总线之间的交互方式是什么样子的,下面就介绍一个MESI发送的消息总类。
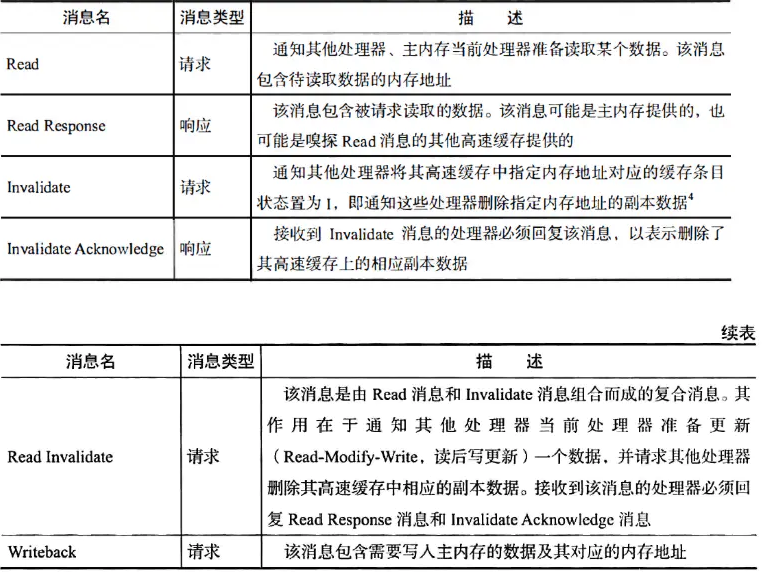
上面图中都有详细的解释,就不过多介绍了,这里说明一下Read Invalidate请求,这个请求和Read请求的不同之处是他不只是要Read的结果,还需要别的CPU的缓存失效。
MESI协议举例
以上的过程都是理论性的介绍,下面通过一个例子来感受一下。
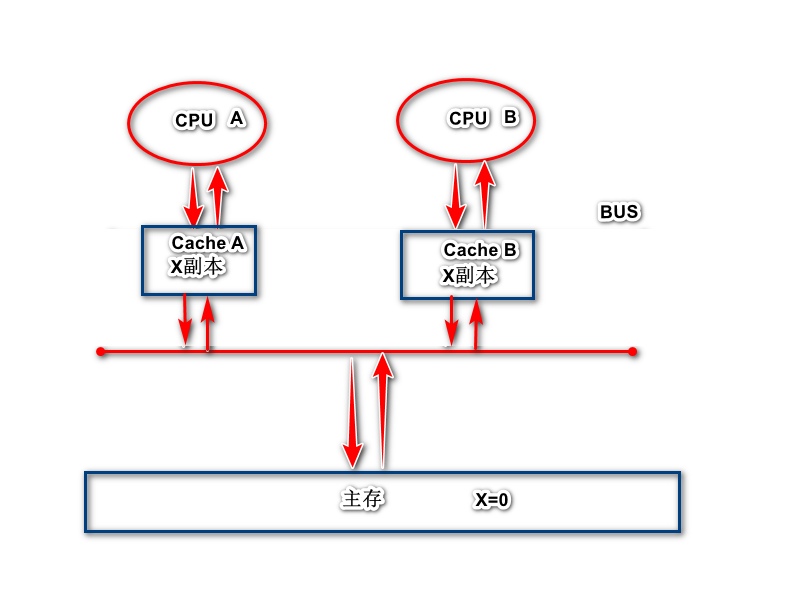
图片来源:正确理解MESI协议
说明:图中有两个CPU,主存中有一个变量X = 0,下面就介绍一个CPU A和CPU B读写X的过程。
- 初始状态,cache A和cache B中都没有X的副本,CPU A发起read请求向主内存,主内存会向总线发送ReadResponse,之后CPU A将Cache A的状态更改位E,表示独占。
- CPU B发起Read请求,此时CPU A和CPU B同时嗅探总线,发现主内存的变量X不只有一个副本,此时CPU A将Cache A的状态更改位S,CPU B收到ReadResponse之后,更改状态位S。
- 假如这时CPU A要修改变量X的值为1,这时CPU A先发起Invalidate请求,当CPU B嗅探该请求之后,会将Cache B的状态更新为I,之后回复Invalidate Acknowledge,当CPU A收到CPU B发送的ack之后,才会更改变量X的值为1,之后更新Cache A的状态为M。
- 如果此时CPU B要读取变量X,发现自己缓存的状态为I,则会发起Read请求,这时CPU A嗅探到Read请求,会将Cache A中的X的值刷新回主内存,然后会将自己的状态更新为E,之后,CPU A会将X的值同步给CPU B,在之后两者的状态都更新为S。
MESI性能优选
在上面的例子中,有这么一个场景,就是CPU A要修改Cache A的值,这个时候他需要先发送Invalidate请求,等到别的CPU都返回了ack,才可以真正的开始修改缓存中的值。这个过程其实有两个地方要等待。
- CPU A需要等待别的CPU返回ack,这个过程浪费时间
- CPU B需要先将Cache B的状态更新为I,之后再返回ack,这个过程也非常浪费时间
所以针对这两点,从硬件级别就做了两点优化,引入了store buffer(写缓冲区)和Invalidate queues(失效队列),对应于上面例子中的优化具体如下:
- CPU A将X的值写入到写缓冲区,之后直接发送Invalidate请求,然后CPU就去做别的事情,当所有的ack都收到之后,再把写缓冲区中的值更新到高速缓存。
- CPU B收到CPU A发送的invalidate请求之后,并不会直接去修改Cache B的状态,而是将请求信息放入Invalidate Queues中,等CPU有空闲了再处理。
以上两个存储结构的引入的确可以解决MESI协议效率低的问题,但是由于延迟执行却带来了新的问题,就是常见的可见性和有序性的问题,下面就举例分析一下引入上面两个存储结构之后导致的可见性和有序性的问题。
可见性问题:
- 如果CPU A修改了X的值,但是并没有直接刷新回高速缓存,这个时候如果CPU A或者CPU B要使用X的值,对于CPU A来说,他的缓存状态时S,说明和内存中的状态一致,所以就直接使用了旧的值。对于CPU B来说,他的状态也是S,他也会直接使用这个值,但是其实这个时候X的值已经被CPU A修改过了,但是却没有生效。
有序性问题:
思考这么一段代码
1 2 3 4 5 6 7 8 9 10 11 | public class Test { static int a = 1; static int c = 1; public static void main(String[] args) { new Thread(()->{ a = 2; int b = c; }).start(); }} |
在上面的代码中,有两个全局变量,在main中有一个线程,这个线程先执行了一个写操作,对a进行重新赋值,之后执行了一个读操作,如果在多线程的环境中,第一步写操作会先放到写缓冲区,收到ack之后将写缓冲区的数据刷新回主内存,在别的线程看来,其实是先执行的第二步赋值操作,而不是第一步,这样顺序就出现了问题,这就是所说的有序性问题。
内存屏障
上面提到了使用store buffer和invalidate queues之后会有可见性和有序性的问题,那如何解决这些问题,就是下面要介绍的内存屏障来解决。
内存屏障(memory barrier)是一个CPU指令。其基本作用:
- 阻止屏障两边的代码发生指令重排
- 强制将写缓冲区/高速缓存的数据刷新回主内存,并使得相应的缓存中的数据失效
在详细介绍内存屏障之前需要先介绍两个指令
- store指令:将数据刷新到主内存中
- load指令:从主内存中重新加载最新的数据
内存屏障在不同的硬件有不同的实现,本文介绍一下x86的内存屏障实现
-
Store Barrier:在x86中是sfence指令实现的,强制该屏障之前的store指令都执行完才可以执行sfence指令,然后才可以执行屏障之后的store指令。
- Load Barrier:在x86中是lfence指令实现的,强制该屏障之前的load指令都执行完才可以执行Ifence指令,然后才可以执行屏障之后的load指令。
- Full Barrier:在x86中是mfence指令实现的,该指令相当于sfence和Ifence两个指令的功能。
jvm为了屏蔽硬件的差异,定义了自己的内存屏障,其底层是使用硬件的内存屏障。
- LoadLoad内存屏障:相当于上面介绍的Load Barrier内存屏障的作用。
- StoreStore内存屏障:相当于上面介绍的Store Barrier内存屏障的作用。
- StoreLoad内存屏障:相当于上面介绍的Full Barrier内存屏障,这个是最全能的,相当于其他三个内存屏障的功能,但是相应的开销也更大。
- LoadStore内存屏障:这个在上面没有对应的硬件指令,不清楚jvm如何实现的,不过功能是在LoadStore内存屏障之前Load指令执行完之后才可以执行LoadStore,之后才可以执行后面的Store指令。
介绍完内存屏障,那可见性和有序性如何解决呢?
可见性问题:
1 2 3 4 5 6 7 8 9 10 11 12 | public class Test { static int a = 1; static int c = 1; public static void main(String[] args) { new Thread(()->{ a = 2; StoreLoad();//伪代码 int b = c; }).start(); }} |
还是上面介绍的例子,如果在a = 2之后加入StoreLoad指令,就可以保证a的值从写缓冲区写入到高速缓存,如果硬件同时要求写入主内存,还会刷新回主内存,之后才会执行int b = c;这个load操作,这样就可以保证可见性。
有序性问题:

public class Test { static boolean isRunning = true; public static void main(String[] args) { new Thread(()->{ isRunning = false; StoreLoad(); //伪代码 while (isRunning){ System.out.println("执行了"); } }).start(); } }
本例中可能会发生指令重排的地方就是isRunning = false;赋值操作还没有执行,先执行了下面的while,当然CPU可以保证最终结果的正确性,所以这里并没有出现问题,如果一定保证代码不发生指令重排,可以在isRunning = false;下面加一个StoreLoad指令,防止指令重排序。其实有序性问题有一个著名的例子,就是单例模式使用double check进行初始化单例的时候,在高并发的场景下依然可能会出问题,这个例子放到介绍volatile的时候再介绍。
总结
本文从硬件说起,提到了现代计算机系统的多核和多级缓存的架构,由这个架构引发了缓存不一致的问题,为了解决缓存不一致的问题引入了MESI协议,之后详细介绍了MESI协议的工作机制和状态转换规则,之后介绍了MESI协议的优化方法,由此方法又引发了可见性和有序性的问题,最后介绍了内存屏障,以及内存屏障是如何解决可见性和有序性问题的。由于本人水平有限,文中有些例子举的可能不太恰当,如有错误或者说法有不当的地方,望大家指正。
推荐大家阅读:
深入学习缓存一致性问题和缓存一致性协议MESI(一)[转载]
参考文章
深入学习缓存一致性问题和缓存一致性协议MESI(一)[转载]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?