
java基础之----hbase
hbase体系架构和设计模型
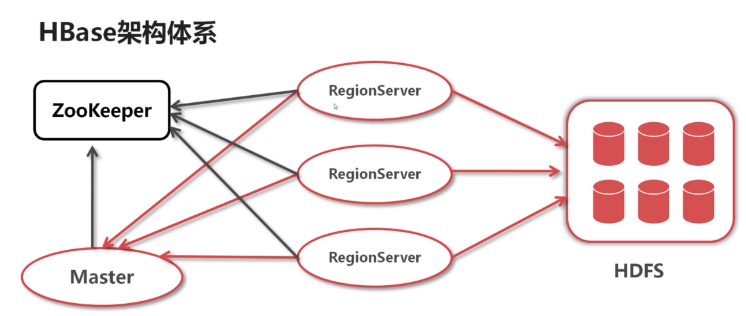
上图过于简单,具体详细的架构图如下
zookeeper:作为分布式协调框架
HRegionServer:向master报告自己的健康状态和自己管理的region信息,管理region。同时把自己的健康状态和管理的region信息也会同步到zookeeper。具体作用如下:
- 维护master分配给他的region,处理对这些region的io请求
- 负责切分正在运行过程中变的过大的region
Master:Hbase每时每刻只有一个hmaster主服务器程序在运行,hmaster将region分配给region服务器,协调region服务器的负载并维护集群的状态。Hmaster不会对外提供数据服务,而是由region服务器负责所有regions的读写请求及操作,具体作用如下:
- 为Region server分配region
- 负责Region server的负载均衡
- 发现失效的Region server并重新分配其上的region
- HDFS上的垃圾文件回收
- 处理schema更新请求
HDFS: storefile是存储在hdfs上的
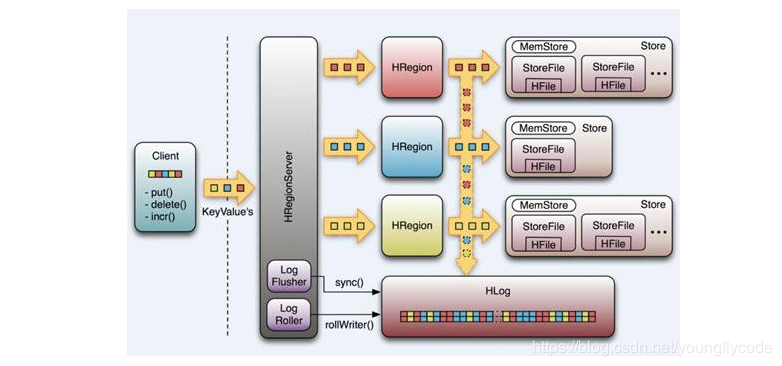
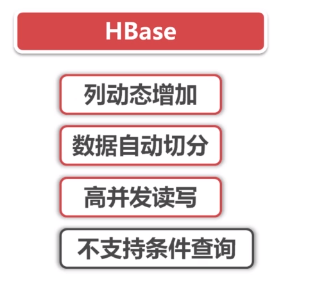
具体说一下,首先整个hbase分布式集群只有一个master,多个HRegionServer,HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个 Region,Region是分布式分布式存储的最小单元,但并不是存储的最小单元,Store是存储的最小单元,Region由一个或者多个Store组成,每个Store会保存一个Column Family;每个Store又由一个MemStore 或0至多个StoreFile 组成;MemStore 存储在内存中,StoreFile存储在HDFS中
hbase表结构
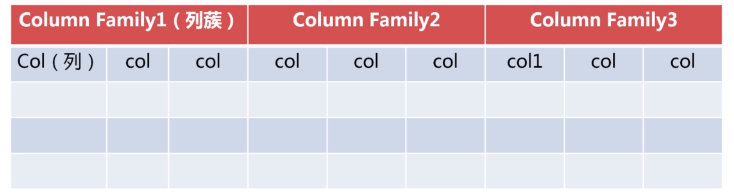
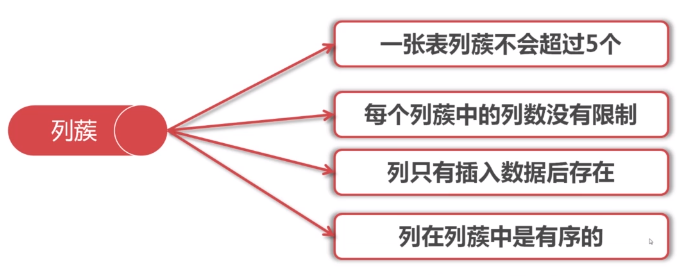
创建表的时候不需要指定col,需要指定Column Family。
举例如下:
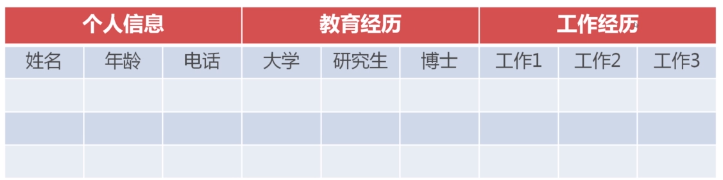
hbase的数据模型
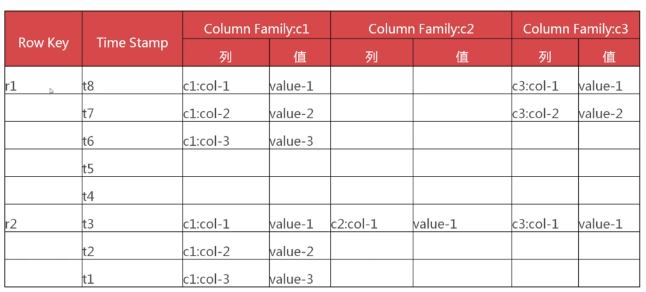
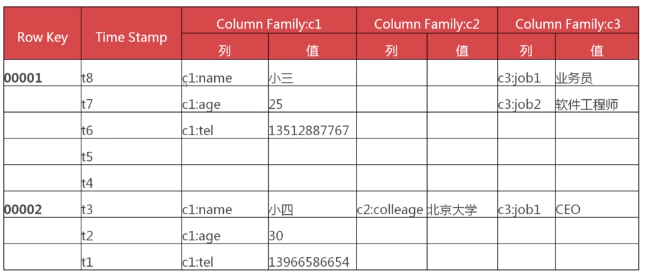
具体举例如下:
列簇设计原则
region举例说明

hbase和关系数据库比较
WEB管理界面
Hbase读写流程
- client向hregionserver发送写请求。
- Regionserver找到目标Region。
- Region会检查数据是否与Schema一致。
- 若客户端没有指定时间戳,默认取当前时间。
- hregionserver将数据写到hlog(write ahead log)。为了数据的持久化和恢复。
- hregionserver将数据写到内存memstore(判断Memstore是否需要Flush为Storefile文件)
- 响应客户端Client请求
读数据流程:
- Client访问ZK,查找-ROOT-表,获取.META.表信息,这两个是什么东东呢?其实也是hbase中的两个表其中.META表中放的是每个region的信息,而.META表本身也保存在不同的region上,所以这些保存.META的region信息保存在.ROOT表中
- 从.META.表查找,获取存放目标数据的HRegion信息,从而找到对应的HRegionServer
- 通过HRegionServer获取需要查找的数据
- Region会先从Memstore中查询,命中则返回(先查Memstore的好处是在内存中,查询快)。
- 若Memstore没有,则扫描StoreFile(这个过程可能会扫描很多StoreFIle),数据从内存和硬盘合并后缓存到内存中的数据块中最后响应给客户端
shell操作hbase
./bin/hbase shell进入
- create : create 'table' 'family1' ,'family2' ,'family'
- enable : put 'table','0001','family:username','zhangsan'
- describe : describe 'table'
- disabled : disable 'table'
- is_enabled
- disable
- drop
- list
对数据的操作
1.count
2.put
3.delete
delete 'test','0001','info:age'
4.scan
5.get
get 'test','0001','info:username'
6.truncate
truncate 'test'

