
java基础之----elasticsearch
概述
Elasticsearch简称es,是一个基于Lucene分布式的搜索引擎,使用Java开发,基于RESTful web接口,提供近实时搜索,广泛应用与很多的搜索场景,比如github的搜索就是使用es做的。
Elasticsearch架构
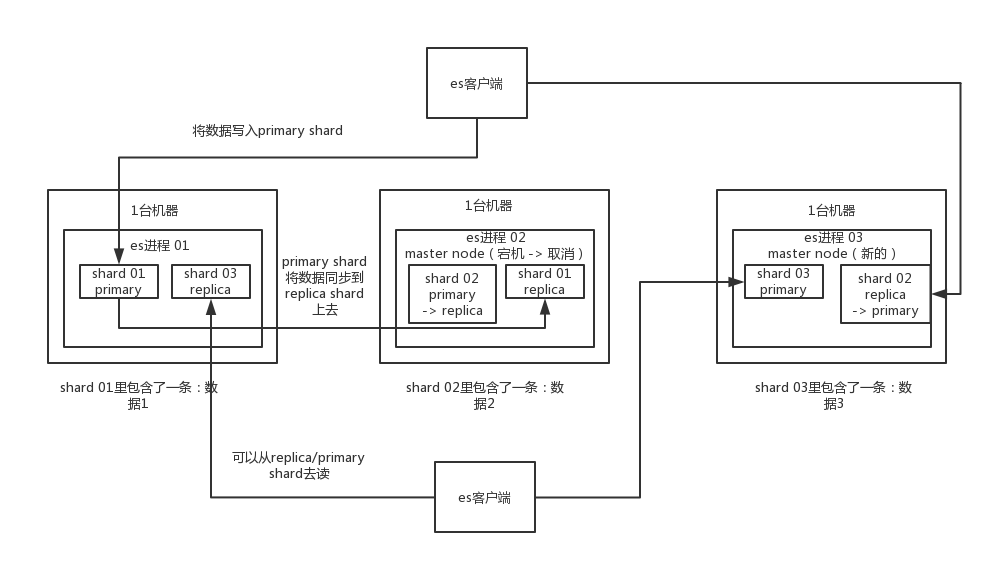
说明:上图是石杉老师的一个课程中画的es的架构图,图中的es有三个节点,然后有一个index,这个index分三个分片(shard)存储,每个分片有一个副本。可以看出其实es的架构和kafka很像,下面就结合这个图来分析一下es的架构和kafka的相同点和不同点和一些基本概念介绍。
基本概念介绍
index:索引,很多的文章说这个类似与数据库,其实在真实使用的时候其实不是,更像是一个表,因为一个数据库中会存储多个表,比如商品表,用户表,但是一个索引中一般不会把这两个放到一个索引中。索引是包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
shard:分片,类似与kafka的partition,可以让一个索引存储到多个分片中,进而存储到不同的服务器上,实现分布式的存储,易于扩展,提高吞吐量和性能。
replica:副本,分片的副本,kafka的partition也有类似的设计,主要作用是为了容灾,但是这个和kafka的副本还是有区别的,kafka的副本只是可以同步主partition的数据,不能读,就是说kafka的读和写都只能在主分区进行,而es的shard不同,es的replica除了作为主shard的备份以外,还可以读,提高es的并发能力。
Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
Node:节点(简单理解为集群中的一个服务器),集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
document:文档,索引中存储的实际内容,类似与表中的一条数据。
架构总结
es的分布式架构是非常典型和常见的分布式架构,多个节点组成集群,易于扩展,数据保存到集群中采取分散保存,提高并发和容灾能力,数据保存到磁盘同时写日志,防止数据丢失。
Elasticsearch读写原理
es的读原理
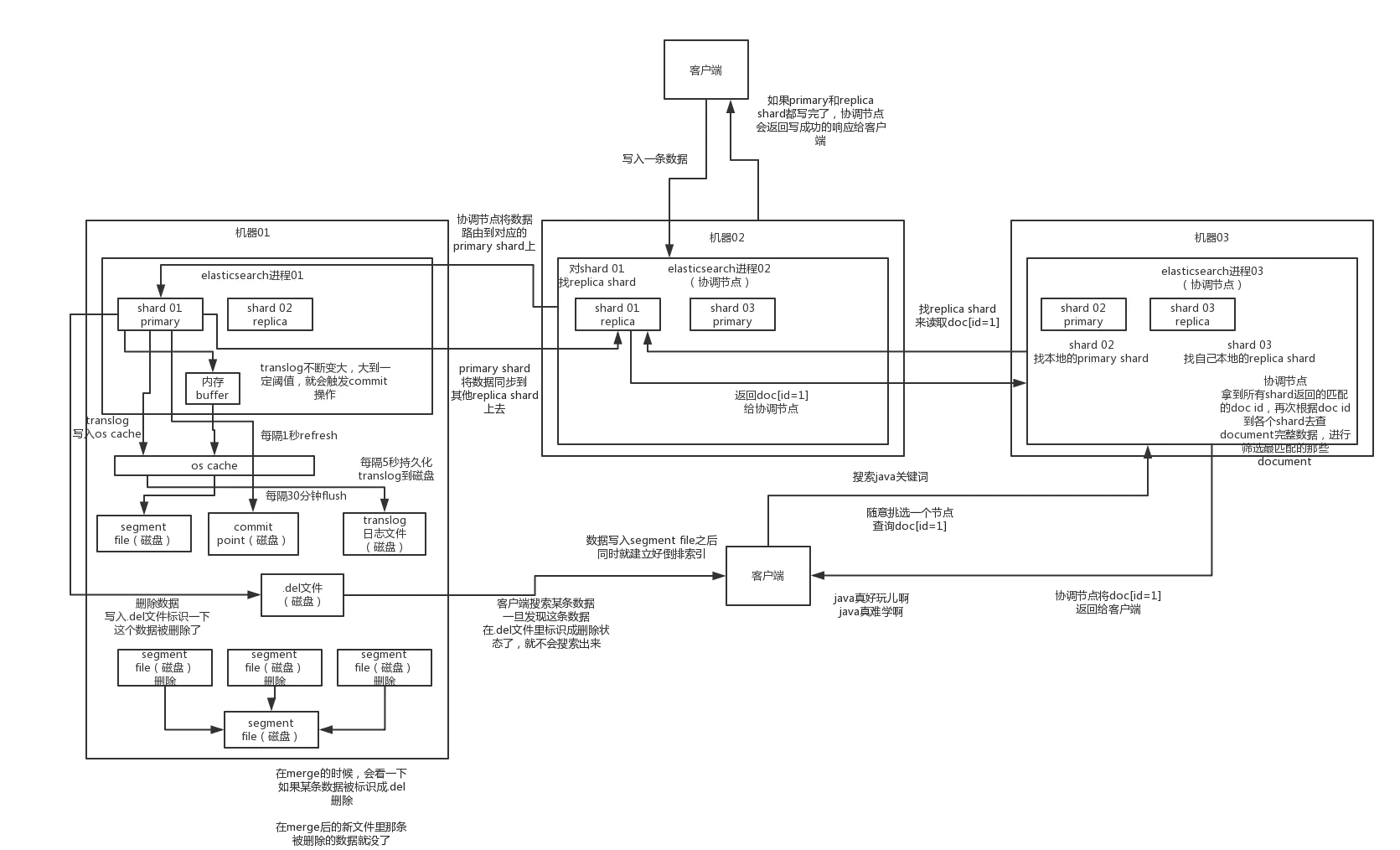
- 客户端发起请求,随机请求一个es的节点,假设查询时通过document的id进行查询,这个节点就会编程协调节点(coordinate node)。
- 协调节点根据请求的document id来说hash路由,可以找到具体存储这个id的shard,之后会转发到具体存储这个shard的节点上。
- 存储该document的shard所在的节点返回document的信息给协调节点,协调节点将信息返回给客户端。
es的写原理
- 客户端选择一个node发送请求过去,这个node就是coordinating node (协调节点)
- coordinating node,对document进行路由,将请求转发给对应的node,这个路由是根据取模的方式路由的
- 实际上的node上的primary shard处理请求,然后将数据同步到replica node
- coordinating node,如果发现primary node和所有的replica node都搞定之后,就会返回请求到客户端
上面的四个步骤是写的原理,但是没有任何具体的细节,比如是直接将数据写入和磁盘中呢?还是先将数据写道内存中,一段时间写一次磁盘呢?下面就详细介绍这个过程。
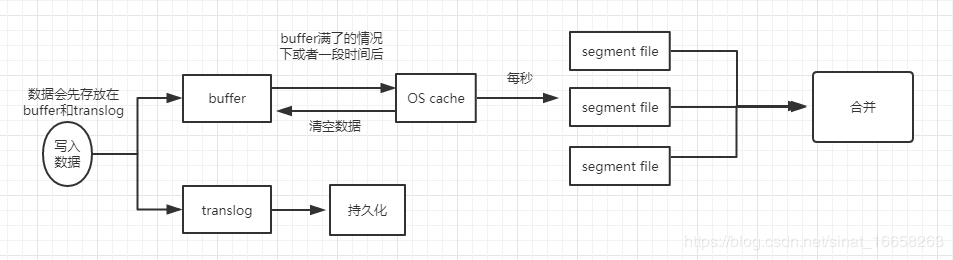
- 写请求的数据,不会立即同步到磁盘,会先保存到内存中的buffer中,当内存中的buffer满了之后,或者1s之后,会自动将buffer中的数据同步到操作系统的cache,这个过程一个专业术语叫做refresh,这个时候es搜索的时候就可以搜到这条数据了,这也是es是准实时的原因,会有大约1s的延迟。上面每秒同步的数据并不会都混在一起,而是每秒的数据是一个segment,之后保存到磁盘也是这样一个一个的小文件。
- 在写buffer的同时,会写log,上图画的有点问题,就是translog不会立即写入到磁盘,log会和buffer中的数据一样,先保存到os cache中,每隔5秒刷新到磁盘,这里会有一个问题,就是如果log还没有刷新的磁盘,此时系统宕机了就会丢失5s的数据。在第二步中,translog如果一直写就会一直增大,那无线增大会把磁盘撑爆,所以translog需要设置一个阈值,当达到阈值之后就清空,es中专业术语叫commit,但是日志不能随便清空,要首先确保os cache中的es 数据都已经落盘了,才可以清空,那es是怎么做的呢?这个也分为3步,分别为:A:先将buffer中的数据刷到os cache B:在磁盘中建一个文件,专业术语叫做commit point文件,这个文件中保存着这次commit操作,从os cache中刷了(专业术语叫做force sync,强制同步)多少segment到磁盘 C:当这个文件搞好之后,就开始fsync数据到磁盘 D:当数据都保存到磁盘之后就把这个translog删除了。 以上的整个commit过程叫做flush操作。
- es中的数据如何更新?es会先把原来的那条数据标记为删除,之后新插入一条数据,下面说一下es是如何删除的。
- 如果es删除数据呢?怎么操作,是这样做的,es不会去找那个要删除的文件,来个物理删除,这种磁盘io操作非常耗时,es会在磁盘中写一个.del文件,把要删除的数据保存在这里面,然后当查询数据的时候,把.del文件中的数据过滤掉,就实现了删除。
- 当磁盘上的segment小文件多到一定的量的时候,es就是执行merge操作,把小文件合并为一个大的segment。
下面是详细流程图,这个是石杉老师画的:
es在亿万级数据场景下如何做性能优化
es性能优化没有什么银弹。不要指望调一个参数,就可以万能的应对所有场景。
1、性能优化杀手锏—filesystem cache
ES数据检索的流程如上所示,第一次检索一个数据时是从磁盘里读的,慢;以后读会从filesystem cache中拿,快。filesystem cache是操作系统级的缓存。
es严重依赖于filesystem cache,如果filesystem cache很大,可以容纳所有的indx segment file索引数据文件,那么搜索时基本都是走内存,性能非常高。走磁盘一般秒级别,走filesystem cache毫秒级。
一般,尽量让机器内存可以容纳数据量的一半。最佳的情况,仅在es中存少量数据,留给filesystem cache的内存要能存下所有数据,这样数据几乎全部走内存来搜索,性能非常高,一般可以在1秒以内。比如现在有一行数据,id name age …30个字段,现在只需要根据id name age三个字段来搜索,就可以只写入这几个字段,然后其他字段存在mysql或hbase中。建议用es + hbase的。
hbase适用于海量数据的在线存储,不做复杂搜索,就做简单的根据id或者范围查询就可以了。从es中根据name和age去搜索,结果可能就10个doc id,然后根据doc id到hbase里去查询每个doc id对应的完整数据,再返回给前端即可。
2、数据预热
做一个缓存预热系统,专门用于对那些比较热的数据,每隔一段时间访问一下,让数据进入filesystem cache。比如微博,看的人很多的数据;再比如电商的热门商品P30。
3、冷热分离
大量的冷门数据一个索引;热数据另一个索引。这可确保热数据在被预热后,尽量都留在filesystem os cache里,别让冷数据给冲刷掉。
4、document模型设计
订单表:id、order_code、total_price
订单条目表:id、order_id、goods_id、purchase_count、price
mysql可以很方便的进行多表关联查询。但是在es中,复杂的关联查询尽量别用,用了性能不好。对于这种情况,设计es数据模型可以搞成两个索引,order索引,orderItem索引
order索引:id、order_code、total_price
orderItem索引:id、order_code、total_price、id、order_id、goods_id、purchase_count、price
首先完成两种数据的关联,然后再将关联好的数据直接写入es中,搜索时,就不需要利用es的语法去完成join了。
总之,对于太复杂的操作,比如join,nested,parent-child搜索都要尽量避免。对于要执行一些复杂操作的思路:
1)在写入时,就设计好模型,加几个字段专门用于存放处理好的数据。
2)用es查出来,然后在程序中封装。
5、分页性能优化
es的分页是比较坑。假如每页10条数据,现在要查询第100页,实际上会把每个shard上的前1000条数据都查到协调节点上,如果有5个shard,协调节点就要对这5000条数据进行一些合并、处理,再获取到最终第100页的10条数据。
翻页时,越深,处理的数据就越多。所以我们会发现越翻到后面,就越是慢。所以es有个参数index.max_result_window = 10000,就是from + size(from和size类似与MySQL的limit 100 10)的大小,当分页的数据大于这个值的时候就无法再获取到结果。
解决方法:
(1)不允许深度分页
系统不允许翻页太深,产品经理可能不同意。
(2)基于scroll api
在这样一些场合,比如app里的推荐商品不断下拉出一页一页的数据,可以基于scroll api来做。
scroll的原理是一次性生成所有数据的快照,每次翻页就是通过游标移动,获取下一页数据,这个性能是很高的,无论翻多少页,都是毫秒级的。
缺陷:
1)适合一页一页往下翻,不能随意跳,也不能往上翻。
2)要保留一段时间内的数据快照,需要确保用户不会持续翻页几个小时。
具体参考:ElasticSearch - 解决ES的深分页问题 (游标 scroll)
es搜索结果排序优化
es搜索时,会为每个匹配的结果做一个评分,评分越高越靠前,但是es的原始评分可能不能满足我们的需求,这是我们就要对原始搜索的结果进行重排序,那怎么进行重排序呢?使用function_score来控制怎么样的文档相关性更高。
ElasticSearch - function_score 简介
ElasticSearch - function_score (field_value_factor具体实例)
ElasticSearch - function_score (weight具体实例)
ElasticSearch - function_score (衰减函数 linear、exp、gauss 具体实例)
问题:
- es节点之间是如何同步的
- buffer的大小是多少
- 为什么数据进入os cache就可以进行搜索了
- 操作系统的cache和内存有什么区别
- 如果translog中的数据还没有满,而os cache满了怎么处理
参考:
生产环境部署方式:https://blog.csdn.net/hanjungua8144/article/details/86355550

