
java基础之----集合
概述
java中的集合类应用非常广泛,而且性能也很好,所以,往往我们都不太注意他们的底层实现原理,但是面试中面试官很喜欢问这些集合类的底层实现原理,那问题来了,掌握这些原理有没有用?(当然这个有用是除了装*之外的^_^),举个例子来说,比如我知道ArrayList是线程不安全的,当多线程时会有问题,我百度一下,查到Vector是线程安全的,我就使用Vector,但是因为Vector底层是用Synchronized实现的线程安全,而synchronized的性能又很低,如果贸然使用Vector就会有问题,所以明白原理还是很重要的。下面主要介绍3中java中常用的集合类。
List类型集合类:
ArrayList、LinkList、Vector、CopyAndWriteArrayList
Map类型集合类:
HashMap、HashTable、LinkHashMap、ConcurrentHashMap
Set类型集合类:
HashSet、TreeSet
详细介绍
ArrayList介绍
使用方法就不用说了,大家应该都知道,而且一些常识也都知道,比如ArrayList线程不安全等,下面讲一下平时可能忽略的几个点。
一、ArrayList使用 List list = new ArrayList();初始化之后默认的存储类型是什么?
默认的存储类型是Object.
二、ArrayList底层是数组结构,那初始化时数组的长度是多少,如果ArrayList长度不够用,扩容时扩容大小是多少?
初始化时默认的长度是10,扩容时是在原来的基础上的1.5倍,扩容时并不是直接在原来的数组基础上新增空闲容量,而是开辟一个新的空间,大小为原来的1.5倍,然后把原来的数据复制过去,至于为什么这样做,这是数组这种数据结构导致的,因为数组一旦初始化之后就不能扩容。
三、ArrayList是线程不安全的,为什么?
先看一下ArrayList中的add方法:
/** * The size of the ArrayList (the number of elements it contains). * * @serial */ private int size; /** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return <tt>true</tt> (as specified by {@link Collection#add}) */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
其一、
这里的elementData[size++] = e;并不是一个原子操作,多线程时可能会有下面的情况发生,A和B两个线程都获取到size = 5,之后同时执行了size++,都变成了6,然后再向数组中赋值,这样会导致你想插入100个值,但实际并没有那么多。
其二、
ArrayList 默认数组大小为 10。假设现在已经添加进去 9 个元素了,size = 9。
线程 A 执行完 add 函数中的ensureCapacityInternal(size + 1)挂起了。
线程 B 开始执行,校验数组容量发现不需要扩容。于是把 "b" 放在了下标为 9 的位置,且 size 自增 1。此时 size = 10。
线程 A 接着执行,尝试把 "a" 放在下标为 10 的位置,因为 size = 10。但因为数组还没有扩容,最大的下标才为 9,所以会抛出数组越界异常 ArrayIndexOutOfBoundsException
四、java8中ArrayList的新特性
1.在java8中Collection集合接口中新增了Spliterator如下,至于Spliteroator的作用,参考这篇文章:
@Override default Spliterator<E> spliterator() { return Spliterators.spliterator(this, 0); }
2.stream流处理
关于stream流,之后会单独写一篇文章,目前先参考这篇文章
LinkList和Vector介绍
由于这两个用的并不是很多,就简要介绍一下,LinkList的底层使用的是链表结构,所以对于插入,删除操作时很快的,但是对于查找就不是很快了。Vector基本和ArrayList相似,区别就是ArrayList会产生线程不安全的地方,Vector都加了个Synchronized关键字修饰,保证线程安全。
CopyOnWriteArrayList介绍
以上介绍的所有list集合类都不能解决并发迭代和写的问题,Vector虽然是线程安全的,只是解决了并发写的时候的问题,但是如果存在并发迭代和写情况就会报:java.util.ConcurrentModificationException,只有CopyOnWriteArrayList解决了这个问题,那是怎么解决的呢?看下面add方法源码:
/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array; /** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { final ReentrantLock lock = this.lock;//重入锁 lock.lock();//加锁啦 try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组 newElements[len] = e; setArray(newElements);//将引用指向新数组,由于volatile保证可数组引用的可见性,所以当这句执行之后,别的读线程就可以获取到最新的值,但是有一个问题就是如果还没有执行到这句,别的线程读到的还是旧数据 return true; } finally { lock.unlock();//解锁啦 } }
通过上面的源码可以看出,CopyOnWriteArrayList每次添加一个新元素就重新建一个数组,对于数据的所有读操作还是在旧数组上执行,而写操作在新的数组执行,就是实现了读写分离,其实数据库的主从库也是这样设计的,就是主库主要是用来做写操作,从库主要做读操作,这样可以增加并发性,但是却牺牲了数据的实时性。上面这种读写分离的设计好处已经说了,缺点也很明显,就是不适合写多的场景,特别是数组中数据量很大的时候,一直新建数组是很耗内存的,反之,也就是说这玩意适合读多写少的场景。
HashMap介绍
同样HashMap基本使用很容易,类似于python中的字典结构。下面介绍一下平时不注意的地方。
一、HashMap的底层存储结构是什么?
java1.7底层存储结构是:数组+链表,java1.8底层存储结构是:数组+链表+红黑树,至于这种组合方式怎么存储下面会介绍
二、HashMap是根据Hash算法存储的,那Hash算法是什么?
举个简单的例子说明一下什么是hash算法,做过分表的同学都知道,比如mysql中单表的数据超过千万查询就会很慢,往往都会采用分表的方式,就是把1000万数据分到很多表中,那问题来了,怎么确定哪些数据到哪张表中呢?这个时候有一个专业的术语叫做路由,其实就是寻找目的表,还是上面的例子,比如分了100张表,如果主键id是int类型的,只需要用主键和100取余就可以确定该条数据应该保存到哪张表中,这就是hash算法。
但是,上面对于分表没问题,但是对于hashMap就有问题了,比如下面的例子:
public void test(){ /**假设hash算法为a%10*/ Map map = new HashMap(); map.put(1,"苗若兰"); map.put(11,"程灵素"); }
上面的示例put进入两个元素,但是经过hash算法之后这两条数据的余数都是1,会存到一个位置上,这就是hash冲突。
三、结合以上一和二的介绍,讲一下hashmap具体的存储方式。
hashmap的主要存储是数组,当初始化hashmap的时候并不会初始化数组,而是等到put数据时才会初始化,初始化数组的长度为16.如果现在要保存16个元素,没有冲突,会非常完美(这里只是举例子,其实不会存到16,会有一个负载因子的概念在里面),但是如果产生了hash冲突,就是多个元素保存到数组的同一个位置,这是hashmap是怎么做的呢,就是把冲突的元素保存成一个链表,如果链表的长度超过8,会把链表转化为红黑树。参考下图
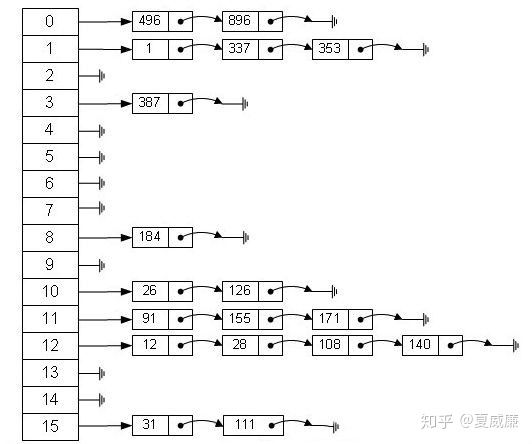
由于hashmap的这种设计方式,极端情况下会发生一个什么问题呢?就是有很多的key发生hash冲突,导致查询性能变慢,为什么这么说呢?如果没有hash冲突,直接经过hash算法查找是一次性就找到了,时间复杂度O(1),如果转化为红黑树之后,时间复杂度是O(log(n))(注:n表示红黑树节点个数),关于hash算法的详细介绍参考这篇文章
四、java8中对hashmap的优化
hashmap中三个重要的点:https://www.jianshu.com/p/281137bdc223
hashmap,resize方法: https://blog.csdn.net/qq32933432/article/details/86668385
上面两篇文章说明了java8中对hashmap进行优化的3个点。
-
计算hash值的方法
java7中计算hash值就是使用hashCode()
java8中使用hashCode高16位和低16位就算异或作为新的低十六位,高十六位不变的方式作为新的hash值。具体代码如下: static final int hash(Object key) {
int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
解释: >>>是移位操作,具体什么是移位,可以去网站找资料,还有一个问题就是这里的为什么是32位,就是把高16位移位到低16位,因为hashCod是int类型的,
而int类型无论是在32位操作系统还是在64位操作系统都是32位的。^表示异或,这个也可以上网上找资料,其实这两个符号就是位运算的知识。
好处:上面解释了操作,但是没有解释这么做有什么好处,java8中寻找key在数组中的位置的方式是使用key的hash值和数组的长度减1,做与运算,具体公式如下:
hash & (length -1)
下面就演示一下:
假设key1的hashCode值为:
0000 0000 0000 0000 0000 0000 0000 0101
key2的hashCode值为:
0000 0000 0000 0001 0000 0000 0000 0101
如果不做上面操作,像java7中一样直接和length - 1,假设map的length是初始长度16做与操作,结果如下
key1与运算:
0000 0000 0000 0000 0000 0000 0000 0101 key1的hashcode值
0000 0000 0000 0000 0000 0000 0000 1111 length-1的即是15的32位二进制表示
0000 0000 0000 0000 0000 0000 0000 0101 与运算的结果
key2与运算:
0000 0000 0000 0001 0000 0000 0000 0101 key2的hashcode值二进制表示
0000 0000 0000 0000 0000 0000 0000 1111 length-1,即是15的32位二进制表示
0000 0000 0000 0000 0000 0000 0000 0101 与运算的结果
结论: 可以发现上面的key1和key2的hashcode值并不相同,但是与运算的结果却是相同的,这样就会发生hash冲突,下面看一下经过java8优化后的hash值,运算的结果。
key1和key1的hashcode的高16位向低十六位移动,之后和原来的hashcode做异或运算之后的结果
0000 0000 0000 0000 0000 0000 0000 0101 key1的hashcode
0000 0000 0000 0000 0000 0000 0000 0000 key1高16位向右移动16位之后的结果
0000 0000 0000 0000 0000 0000 0000 0101 原来的hashcode和移位后的结果做异或运算之后的结果,得出新的hash值
0000 0000 0000 0000 0000 0000 0000 1111 length-1,即是15的32位二进制表示
0000 0000 0000 0000 0000 0000 0000 0101 新的hash值和length-1做与运算之后的结果
0000 0000 0000 0001 0000 0000 0000 0101 key2的hashcode
0000 0000 0000 0000 0000 0000 0000 0001 key2的高16位向右移动16位之后的结果
0000 0000 0000 0000 0000 0000 0000 0100 key2的hashcode和移位之后的结果做异或运算之后的结果,得出新的hash值
0000 0000 0000 0000 0000 0000 0000 1111 length-1,即是15的32位二进制表示
0000 0000 0000 0000 0000 0000 0000 0100 新的hash值和length-1做与运算之后的结果
结论: 经过java8优化新的hash值之后,发现不在发生hash冲突了,其实在java7中,当hashmap数组长度比较短的时候,key的高16并没有参与运算,只有低16位参与与运算,这样在数组长度比较短的时候发生hash冲突的概率就高了,但是在java8中优化了获取hash的算法,是的高
16位也参与运算,这样在hashmap的数组长度较短的时候发生hash冲突的概率也没有那么高了。
-
java8中resize的优化
假设key1和key2的hash值分别如下,并且hashmap的原始长度为16:
0000 0000 0000 0000 0000 0000 0001 0101 key1的hash值
0000 0000 0000 0000 0000 0000 0000 0101 key2的hash值
可以发现,这两个key1在map的长度为16的时候会发生hash冲突,都会存储在数组下标为5的位置。
在java7中,会用这个hash值和31(为什么是31?hashmap的扩容时原来的2倍,map的长度是32,然后做与运算是length-1)的二进制做与运算,重新计算位置,下面就演示一下。
0000 0000 0000 0000 0000 0000 0001 0101 key1的hash值
0000 0000 0000 0000 0000 0000 0001 1111 31的二进制表示
0000 0000 0000 0000 0000 0000 0001 0101 与运算的结果
0000 0000 0000 0000 0000 0000 0000 0101 key2的hash值
0000 0000 0000 0000 0000 0000 0001 1111 31的二进制表示
0000 0000 0000 0000 0000 0000 0000 0101 与运算的结果
可以发现,key1的hash值与31做与运算之后,还是5; key2的hash值和31做与运算之后结果变成了21,就是16+5,可以看出,其实就是原来的数组长度+原来的位置等于扩容之后的位置,那
为题来了,为什么key1的是在原位置,key2是在新位置,原因很简单就是key2倒数第5位是1,而倒数第5位正好是扩容之后的hashmap长度新增的位,与运算之后这个位置还是1,而这个位置是1,
那最终的结果就是原来的数组长度 + 原来的位置。
java8中优化: 所以java8就不在像java7一样重新计算一遍与运算,而是直接根据已经计算好的hash值进行确定在扩容之后的数组中的位置,是的效率更高。
五、HashMap线程不安全,为什么?
java7中在高并发写的时候,当发生hash冲突之后,可能会生成一个循环链表,当去读这个数据的时候发生死循环,这里就不做分析了,感兴趣的参考这篇文章:老生常谈,HashMap的死循环,不过java8中已经修复了这个问题。
ConcurrentHashMap介绍
java7:
采用的是分段锁,就是多个hashTable组成一个concurrentHashMap,避免了对整个数组加锁,那什么是分段锁呢?之前看过一篇博客在优化电商秒杀场景时提出的一个解决方案,就是一个经典的分段锁的使用,下面介绍一下这个大家就明白了。如果仓库中的HuaWei p20的库存是1000台,为了防止库存超卖,会采用加锁机制,就是每次用户下单的时候就检查一下库存还够不够,但是检查的时候就要加锁,防止多线程一起检查一起卖出问题,会出什么问题呢?比如A和B线程同时检查库存还有一个1台,都判断可以卖,这样就会出问题。上面解释了加锁的问题,但是这样做会引发另一个问题,就是性能太差,每次只能一个线程判断。那有没有更好的解决方案?其中一个解决方案就是分段加锁,具体怎么做呢?就是把1000台手机分成很多份,比如50台为一份,总共分成20份,然后呢多线程进来之后会采用一种路由方式去其中一份,然后对这个请求加锁,这样一次就可以同时处理20个请求,性能提高了20倍。这就是分段锁的简单解释。concurrenthashmap也是采用这种方式。
java8:
java8放弃了这种方式,而是采用乐观锁加synchronized来实现,具体怎么做的呢,就是如果某个桶(其实就是数据的某个位置)没有数据,为null,这个时候如果多线程插入这个桶,是通过CAS实现的,但是一旦这个桶中有了数据,下次再有多线程插入这个桶就会直接使用synchronized实现,那估计有小伙伴会问了,为啥当某个桶没有数据时使用CAS就可以,有数据之后就不使用CAS了,答案是源码就是这样写的,哈哈哈,我这里初步解释一下原因,当桶中没有数据时,通过CAS先比较后插入,没问题,因为这时只有一个值,容易比较,但是一旦桶中有数据,接下来就会形成链表或者红黑树,那么要比较链表或者红黑树,再使用CAS就比较麻烦了,其实链表还好,还可以使用CAS,但是红黑树就不太行了,因为不确定新进来的节点到底是放在树的什么位置(不确定是不是这样,有大佬指点下),所以无法使用CAS先比较后插入,所以干脆直接当是链表或者红黑树直接使用synchronized来加锁。
HashTable介绍
hashtable其实就是对hashmap会发生线程不安全的地方使用synchronized加同步锁实现的。(另外说一个小细节,hashtable的key,value不能为null,网上很多解释说无法分辨是因为hash表中不存在还是因为value本身为null,这个解释显然是错的,因为hashtable的contain方法也是一个全局锁,完全可以判断这个key在hash表中是否存在,而不会发生当调用contain方法时有其他线程修改了hashTable)。
HashSet介绍
hashset不用过多介绍,底层是通过hashmap实现的,因为hashmap的key本身就不允许重复。
TreeSet介绍
上面忘了介绍TreeMap,类似于HashSet是基于HashMap,TreeSet是基于TreeMap的,TreeMap的底层存储是使用红黑树实现的,之前介绍hashmap的时候讲到当发生hash冲突,而且发生冲突的个数超过8时会转化为红黑树,这里的treemap直接使用红黑树存储。
总结:
写这篇文章之前,本打算把各个集合类的源码通读一遍,奈何没有耐心,只读了部分关键源码,看源码的过程中我发现,源码和我们平时写的代码有很多地方不太一样,非常简洁。。。或许只是和我写的不太一样,之后有时间再补上详细内容。
待补盲点:
1.java7中的concurrenthashmap中key,value不能为null,这个好理解,但是java8为什么也不能为null呢?
2.concurrenthashmap听说最麻烦的地方就是扩容,具体怎么实现的?
3.hashmap目前使用hash function是什么?是怎么可以规避大面积hash冲突的?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号