
[机器学习]-决策树-最简单的入门实战例子
本文主要介绍决策树的基本概念和如最简单的入门实例
第一部分--基本概念:
什么是决策树?
我不打算搞一段标准的定义放在这里,我个人理解是建立一个树来帮助决策,下面以一个图说明一下(注:图是盗别人的)
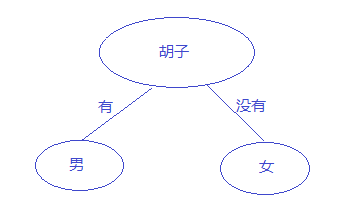
这就是一个决策树,从图中可以一目了然的了解决策树的概念,上面的图中只有一个属性来决定这个人是男还是女,一个属性往往决定的结果并不准确,比如小孩都没有胡子,但是并不能认为小孩都是女孩,这显然不行,那怎么办?如果想相对准确判断,需要再增加属性,比如增加个喉结,如下图:
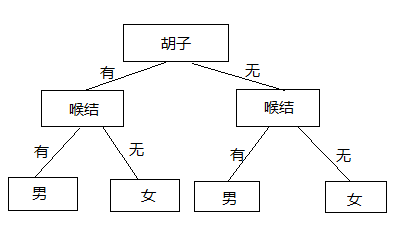
上图就是由两个属性来决定结果,那引出了一个重要的问题,是从胡子开始分,还是从喉结开始分呢?就是每个节点为什么是这样排序,就引出了信息熵的概念
什么是信息熵?
简单来说信息熵,就是反映一个系统的混乱程度,越有序的系统,信息熵越小,反之越大,上面是用了胡子和喉结作为属性来判断一个人是男是女,但是这个系统的不确定性还是很大的,比如一个没有喉结又没有胡子的人,并不一定是女人,可能是小孩,那如果根据这个人有没有JJ,作为判断的依据,那不确定性就会很低,信息熵就会很小。
这里没有举个具体的数字计算,也没有贴公式,主要是编辑数学公式太麻烦,其实公式就是信息的期望。
通过上面的介绍,就可以知道,可以通过计算信息熵来确定从哪个属性开始分,哪个属性作为根节点。
第二部分--代码:
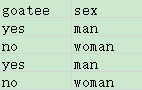
I.数据如下:(goatee 翻译 胡子),只有四个样本,测试样本就一个,在代码中有
II.代码:

# -*- coding: utf-8 -*- import pandas as pd from sklearn.feature_extraction import DictVectorizer from sklearn.preprocessing.label import LabelBinarizer from sklearn import tree def decision_tree(): df = pd.read_excel('../data/K-NN/DecisionTree.xlsx') #要预测的值 label_feature = df['sex'].values print('label_feature:\n'+str(label_feature)) #属性 df_feature = df['goatee'] feature_list = [] for i in df_feature.values: dt_dict = {} dt_dict['goatee'] = i feature_list.append(dt_dict) #封装成需要的数据格式 print('feature_list:\n' + str(feature_list)) dcv = DictVectorizer() #将字典转化为数字 dummyX = dcv.fit_transform(feature_list).toarray() print('dummyX:\n'+ str(dummyX)) lb = LabelBinarizer() dummyY = lb.fit_transform(label_feature) # dummy = dcv.fit_transform(label_feature) print('dummyY:\n' + str(dummyY)) #使用信息熵的规则进行分类 clf = tree.DecisionTreeClassifier(criterion='entropy') clf = clf.fit(dummyX,dummyY) #生成测试数据 oneDummyX = dummyX[0] oneDummyX[0] = 0 newDummyX = oneDummyX print('feature_names'+str(dcv.get_feature_names())) print('newDummyX:\n'+str(newDummyX)) #使用测试数据进行预测 prediction = clf.predict([newDummyX]) print('prediction:\n'+str(prediction)) if __name__ == '__main__': decision_tree()
----------------------------------------------------------菇凉滑溜溜的马甲线-----------------------------------------------------
#输出结果为: label_feature: ['man' 'woman' 'man' 'woman'] feature_list: [{'goatee': 'yes'}, {'goatee': 'no'}, {'goatee': 'yes'}, {'goatee': 'no'}] dummyX: [[0. 1.] [1. 0.] [0. 1.] [1. 0.]] dummyY: [[0] [1] [0] [1]] feature_names: ['goatee=no', 'goatee=yes'] newDummyX: [0. 1.] prediction: [0]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?