linux安装spark-2.3.0集群
(安装spark集群的前提是服务器已经配置了jdk并且安装hadoop集群(主要是hdfs)并正常启动,hadoop集群安装可参考《hadoop集群搭建(hdfs)》)
1、配置scala环境
详细配置过程可参考《linux安装scala环境》,此处就不在详细描述
2、下载spark安装包
因为我之前安装的hadoop是3.0版本的,所以spark我使用的是spark-2.3.0版本
wget https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
3、解压安装包
tar zxvf spark-2.3.0-bin-hadoop2.7.tgz
4、修改配置文件
1、spark-env.sh
复制spark-env.sh.template文件成spark-env.sh(cp spark-env.sh.template spark-env.sh)
在spark-env.sh末尾增加以下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_11
export SCALA_HOME=${SCALA_HOME}
export HADOOP_HOME=/home/hadoop/hadoop-3.0.0
export STANDALONE_SPARK_MASTER_HOST=node101
export SPARK_MASTER_IP=$STANDALONE_SPARK_MASTER_HOST
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_LIBRARY_PATH=${SPARK_HOME}/lib
export SCALA_LIBRARY_PATH=${SPARK_HOME}/lib
export SPARK_MASTER_WEBUI_PORT=18080
if [ -n "$HADOOP_HOME" ]; then
export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.0.0/etc/hadoop
2、slaves
复制slaves.template文件成slaves(cp slaves.template slaves)
修改slave是文件的内容为:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
node101
node102
node103
3、将整个spark解压出来的文件拷贝到另外的两台机器上
5、启动spark集群
cd /home/hadoop/spark/sbin
./start-all.sj
启动成功后会有如下的信息

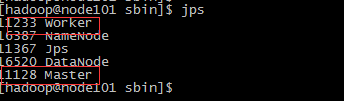
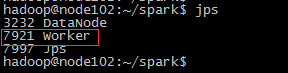
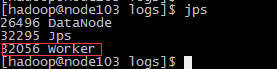
6、检查各节点spark启动情况
分别在三台服务器上使用jps命令查看Master进程和worker进程是否存在,一下是分别是三台服务器的情况
7、使用spark-web在浏览器上查看spark集群的运行情况(之前在配置文件里面配置的端口是18080)