
spm
看了很多关于SPM的介绍,但是网络上的资源大多都是对论文Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories的直接翻译,关于自己的理解谈得很少。这里主要写一下在我看了SPM论文和其提供的代码之后的感想。
SPM,一般中文翻译为空间金字塔,主要是计算机视觉中对图片的一种特征提取的方式. SPM的主要思想为:将图像分成若干块(sub-regions),分别统计每一子块的特征,最后将所有块的特征 拼接起来,形成完整的特征。这就是SPM中的Spatial。在分块的细节上,作者采用了一种多尺度的分块方法,即分块的粒度越大越细 (increasingly fine),呈现出一种层次金字塔的结构,这就是SPM中的Pyramid。
如果细心分析代码那么可以看到,代码主要分为4步来完成,分别对应一个function。
- GenerateSiftDescriptors:
该函数主要是来产生Sift特征,主要需要注意的是它将每一张图片分为了多个patch,这样对每个patch计算Sift特征,最后得到一个多维特征向量。在作者提供的Example中,一张图片480*640,那么对于16*16的patch,gridspacing为8,grid数量为(480/8-1)*(640/8-1)=4661那么可以得到的sift特征数量为4661,每个特征维度为128.
- CalculateDictionary
该函数很简单,就是将刚得到的特征用k-means的方法找到指定size的字典,这里指定的字典size=200或400.那么后面的每张图片的每个sift特征就可以用该字典来表示了,直接去字典里面找和该sift特征最接近的word,直接用index来表示,这个可以用sp_dist2函数来实现。这里注意的是:字典是一个200*128的矩阵,也就是每一行代表着一个k-mean得到的中心sift特征。这个可以在Example跑完后的data文件夹下的dictionary_size(200或400).mat中看到。
- BuildHistograms
该函数在论文里面是没有提到的,它的主要功能在于将每张图片得到的特征(该特征存放在imagename_sift.mat文件中,矩阵为4661*128)转化为texton,该词的翻译为基元,也就是将每张图片中的每个grid产生的sift特征在字典中给对应起来得到一个4661*1的矩阵,该矩阵存放在imagename_texton_ind_size(200).mat文件中。
- CompilePyramid
该函数是最后一步,也就是计算金字塔的步骤,在该函数中将图片按level来进行划分,也就是论文里面的那个图(如下),分了3层,层数l越大,则划分得越细,论文中有句话“More specifically, let us construct a sequence of grids
at resolutions 0, . . . , L, such that the grid at level l has 2 ^(l) cells along each dimension, for a total of D = 2^(dl) cells. ”,实际上意思是对于每层划分,
将图片按照行列的维度进行划分,l=2,则每行没列都做2^2=4个划分,也就是下图最右所示,则所有的cells也就是2^(2*2)=16,这里d=2,对于level l=0,1都是一样道理。做了这样的划分之后,首先计算的是划分最细的特征直方图,这里指的是level 2。那么这里对原图做了16patch的划分,然后计算刚才得到的texton中落在每个patch中的特征sift在词典中的index,多个sift所以形成了一个由index组合的向量,然后计算直方图,这里用hist函数来计算,主要是将词典中每个词也就是每个sift的index在刚得到的向量里面出现的次数得到一个直方图,该直方图是200维。那么对于16个patch都重复计算,最后得到的就是16个200维的直方图特征,所以对于level 2层最后将这些直方图连在一起,就是16*200维。
根据level 2的计算对level 1 ,0重复计算,不过由于粗粒度的特征计算包含了细粒度的计算,所以直接用level 2的计算结果就可以了,这部分代码比较简单,直接看代码就可以了。不过需要注意的是在代码中pyramid_cell这个变量的第一个cell实际上存放的是level 2的特征,是倒过来的。也就是pyramid_cell{1}存放4*4*200,pyramid_cell{2}存放的则是2*2*200,pyradmid{3}存放的则是1*1*200.
最后还有一步就是加权求整张图片级别的特征,这里的思想主要是细粒度的权重大,粗粒度的权重小,这里系数给的是2^(-l)(代码里给的,实际上对应论文里面的,这里l=1,2,3,刚好对应论文里面的2^(-(L-l))),不过这里需要注意的是对于l=3,权重系数为1-(1/2+1/4)=1/4,这是为了归一化。用该系数乘上每个patch得到的直方图特征,
将它们按照细粒度在前,粗粒度在后的顺序连在一起,形成一个4*4*200+2*2*200+1*1*200=4200维度的特征,这对应论文里面,这就是最后图片的特征描述。由于按照level来对图片进行划分,形成一个金字塔结构,所以叫空间金子塔结构。
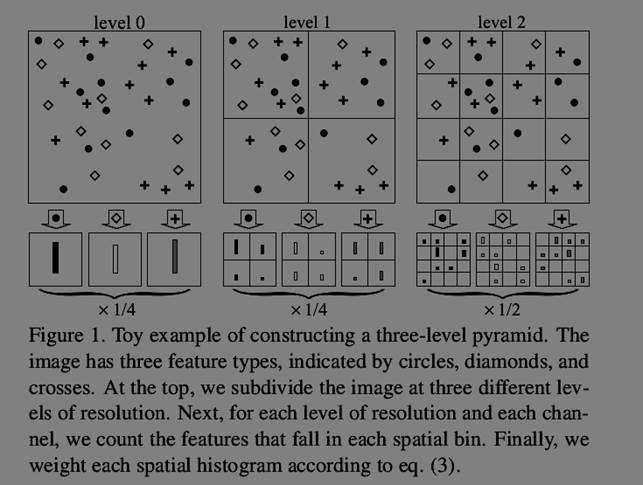
- 最后
在论文里面还提到一些公式,如下
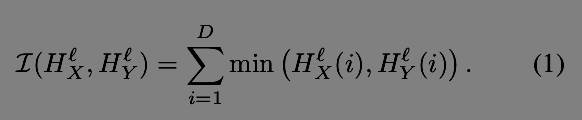
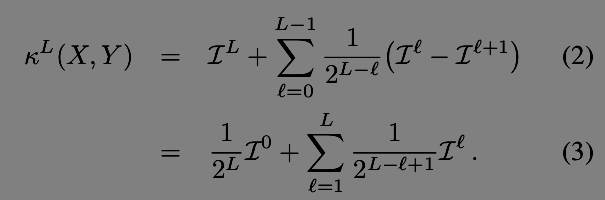
这几个公式主要用来估计相似度的,可以想象为给定两张图片,根据得到的Spm特征进行相似度估计,可以用欧式距离,这里给出了金字塔模型中的相似度估计方法。具体的做法在hist_isect函数中。在(1)中,该函数是一个直方图交集函数(histogram intersection function),对于每个grid产生的200维的直方图,也就是该grid中sift特征落在词典中每个bin的数量,对每个bin中的数量进行比较对小的求和,这就是直方图交集函数。实际代码中,就是先将一个直方图的等于0部分去掉也就是
nonzero_ind = find(x1(p,:)>0);
tmp_x1 = repmat(x1(p,nonzero_ind), [n 1]);
找到大于0部分的,(因为等于0的bin肯定是小的,加和没有意义,直接处理大于0部分就行),然后比较对应部分较小值求和就好。
K(p,:) = sum(min(tmp_x1,x2(:,nonzero_ind)),2)';
。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步