PCIE发展-高速串行互连
参考博文:PCIe扫盲系列博文连载目录篇-PCIe扫盲系列博文连载目录篇(第一阶段)-Felix-电子技术应用-AET-中国科技核心期刊-最丰富的电子设计资源平台 (chinaaet.com)
本文为PCIe扫盲系列博文连载目录篇(第一阶段),所谓第一阶段就是说后面还有第二阶段和第三阶段……第一阶段主要是介绍PCIe总线的发展历史与展望,PCI总线和PCI-X总线的简要回顾,PCIe总线的体系结构入门,PCIe总线的事务层、数据链路层,物理层入门;最后以一个简单的例子进行总结与回顾。
目录如下:
1、前言篇:PCIe扫盲——PCIe简介:http://blog.chinaaet.com/justlxy/p/5100053066
2、PCIe扫盲——PCI总线基本概念:http://blog.chinaaet.com/justlxy/p/5100053077
3、PCIe扫盲——一个典型的PCI总线周期:http://blog.chinaaet.com/justlxy/p/5100053078
4、PCIe扫盲——PCI总线中的Reflected-Wave Signaling:http://blog.chinaaet.com/justlxy/p/5100053079
5、PCIe扫盲——PCI总线的三种传输模式:http://blog.chinaaet.com/justlxy/p/5100053095
6、PCIe扫盲——PCI总线的中断和错误处理:http://blog.chinaaet.com/justlxy/p/5100053096
7、PCIe扫盲——PCI总线的地址空间分配:http://blog.chinaaet.com/justlxy/p/5100053219
8、PCIe扫盲——PCI总线配置周期产生和配置寄存器:http://blog.chinaaet.com/justlxy/p/5100053220
9、PCIe扫盲——66MHz的PCI总线与其技术瓶颈:http://blog.chinaaet.com/justlxy/p/5100053221
10、PCIe扫盲——PCI-X总线基本概念:http://blog.chinaaet.com/justlxy/p/5100053224
11、PCIe扫盲——PCIe总线基本概念:http://blog.chinaaet.com/justlxy/p/5100053225
12、PCIe扫盲——PCIe总线怎样做到在软件上兼容PCI总线:http://blog.chinaaet.com/justlxy/p/5100053245
13、PCIe扫盲——PCIe总线体系结构入门:http://blog.chinaaet.com/justlxy/p/5100053246
14、PCIe扫盲——PCIe总线事务层入门(一):http://blog.chinaaet.com/justlxy/p/5100053247
15、PCIe扫盲——PCIe总线事务层入门(二):http://blog.chinaaet.com/justlxy/p/5100053248
16、PCIe扫盲——PCIe总线事务层入门(三):http://blog.chinaaet.com/justlxy/p/5100053249
17、PCIe扫盲——PCIe总线数据链路层入门:http://blog.chinaaet.com/justlxy/p/5100053250
18、PCIe扫盲——PCIe总线物理层入门:http://blog.chinaaet.com/justlxy/p/5100053261
19、PCIe扫盲——一个Memory Read操作的例子:http://blog.chinaaet.com/justlxy/p/5100053263
第二阶段的目录篇地址为:http://blog.chinaaet.com/justlxy/p/5100053328
第三阶段的目录篇地址为:http://blog.chinaaet.com/justlxy/p/5100053481
第四阶段的目录篇地址为:http://blog.chinaaet.com/justlxy/p/5100057779
第五阶段的目录篇地址为:http://blog.chinaaet.com/justlxy/p/5100061871
1. GenZ,CXL,NVLINK,OpenCAPI,CCIX乱战
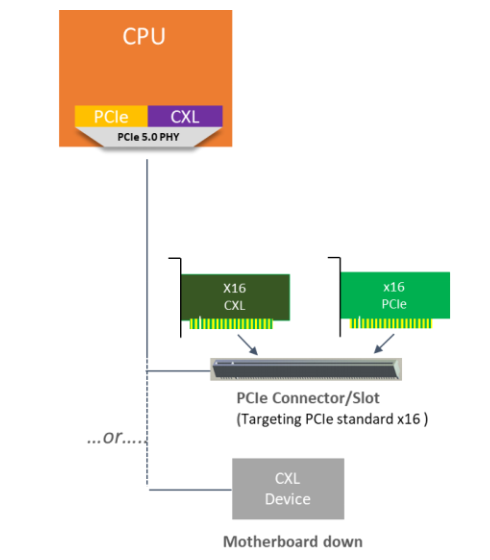
纵观数据中心业界,底层技术方面其实正处在一场架构变革的初始点,这场变革就是I/O总线的网络化以及I/O资源的大规模池化。
众所周知,在开放平台下,PCIE是目前高性能I/O设备普遍采用的总线类型,目前已经到Gen4,很快会到Gen5。但是PCIE总线的树形拓扑以及有限的设备标识ID号码范围,导致其无法形成一个大规模网络,这个问题在NVMe盘未普及之前显得不那么是个问题,但是NVMe盘得道广泛应用之后,会占用大量的PCIE同道数量,这使得原本捉襟见肘的PCIE总线资源更加紧张,GPU、NIC、FPGA/ASIC卡的接入数量就会被NVMe盘挤占,虽然可以用PCIE Switch来解决同道数量不够的问题,但是对于PCIE总线设备ID号的不足,PCIE Switch也并没有方便的解决方案,虽然可以用NTB方式来解决,但是这又需要在Host端OS内核底层增加一层驱动,这种对内核的变更使得该方案只适合用在封闭系统里,比如一些企业级存储系统。
PCIE的另外2个问题是,存储器地址空间隔离、不支持Cache Coherency事务。PCIE网络中的地址空间虽然也是64bit,但是其原本设计初衷是该网络的地址空间是私有的,与CPU的地址空间并不是原生融合的,需要地址翻译寄存器来做基地址翻译,然而对于Intel平台,这个翻译靠软件来执行,而且规则也很简单,就是不翻译,维持原有地址。
这样的话,虽然CPU可以直接访问PCIE网络中的地址,而PCIE设备也可以访问CPU地址空间中的地址(比如Host RAM),但是由于PCIE事务层不支持Cache Cohernecy事务的处理,所以PCIE设备端无法缓存CPU地址域中的数据,所以每次都必须去访问Host RAM来获取数据。
设备端无法缓存的话,每次都访问Host RAM有什么问题么?问题就是延迟太高,通过DDR同道直接访问内存延迟在40ns左右,而通过PCIE访问则会在100ns级别,如果是小尺寸访存请求,性能将会比较差。正因如此,对于目前的GPU、FPGA/ASIC等加速卡,普遍采用现将数据从Host RAM拷贝到加速卡上的内部存储器,计算,算完了再拷贝回Host RAM。
很显然,只要两招就能解决上述问题,第一就是将总线速率提升,降低访问延迟,第二就是在物理链路之上增加对Cache Cohernecy(下简称CC)事务的处理,也就是在设备一侧增加一个CC Agent与CPU一侧的Agent交互。关于CC缓存一致性详细底层架构和原理可阅读《大话计算机》一书第6章。
基于上面两个考虑,IBM最早推出了CAPI(Coherent Accelerator Processor Interface)接口,当年我还写了一篇文章来介绍。CAPI1.0接口复用了PCIE物理层、链路层和事务层,并利用PCIE数据包的Payload字段隧道化封装了CC和CAPI控制事务(这两者后文统称CAPI事务),在CPU一侧增加针对CAPI事务的解析处理模块,然后在加速卡芯片一侧,IBM提供CAPI的事务解析逻辑IP用于集成到第三方芯片中。在后来的CAPI版本中,逐渐演化成了OpenCAPI,有了自己的物理、链路、事务层,以及独立的处理模块,与PCIE分离。IBM下一步甚至会用OpenCAPI来连接DDR内存,内存卡上会有一颗OpenCAPI~DDR4/5的桥接芯片来负责适配。IBM不愧为业界大佬,在这方面风范犹存而且先带领大家玩了起来,不过毕竟是廉颇已老,跟风者寥寥无几,GPU/FPGA/ASIC厂商似乎并不是十分买账,毕竟OpenPower的机器在数据中心占比实在是太低了。
时隔4年,Intel也跟了上来,在2019年3月份推出了Compute Express Link(CXL)协议接口,其与CAPI酷似,也是将CXL协议封装到PCIE链路层数据包中传送,并在CPU端的PCIE总控后端按照事务标识分流CXL专属事务给CXL处理逻辑处理。IBM毕竟廉颇已老,如今是牙膏厂Intel的天下,Intel振臂一呼,那都得跟上来。
IBM和Intel各玩各的,这业界不能就让他俩这么单独玩。早在几年前,GenZ(Generation Z)这套协议雏形初现,如今已经是羽翼丰满。GenZ除了具有CAPI和CXL的功能之外,还将总线拓展成了交换式网络,也就是加入了GenZ Switch这个角色,可以将大量的CPU、I/O设备、存储器挂接到GenZ网络上,实现更高的扩展性。GenZ是一个开放组织,其不依赖于任何CPU平台,目前已经有60多家厂商加入了GenZ组织,其中包括Intel的老对手AMD。然而AMD对GenZ似乎不是很上心,不过Intel推出了CXL之后,AMD估计应该心里多少都有点涟漪,我猜测AMD应该不会自己另起炉灶搞一套总线,而应该斩钉截铁的站队GenZ阵营,直接在CPU里继承GenZ主控,或者采用Microchip(收购了Microsemi、PMC)等I/O控制器老牌公司的外置GenZ I/O控制器。
再说说淫威大这边的事。Nvidia给人感觉一直是diaodiao的,GenZ、CXL、人家一个也没看上,也不跟风,而是自己搞了一套NVLINK,而且反扑了IBM,IBM大佬竟然在Power CPU里继承了NVLINK控制器,奇怪的是NV竟然还是OpenCAPI组织成员,但最终却反客为主,够diao吧?NVLINK可以支持CPU-GPU间链路也可以支持GPU-GPU间链路,而且NV diao上加diao,连NVLINK Switch都自己搞出来了,而且还搞出了搭载16个GPU+NVLINK Switch的整机方案:DGX/HGX,以及即将推出的第二代整机平台方案。整个平台满配据说要数百万¥。
现在的时间线是:CAPI->GenZ->NVLINK->CXL。这还没完,ARM平台不掺和进来这出戏就不够精彩。ARM选择了加入另一个开放的访存和I/O网络平台(CCIX)Cache Coherent Interconnect for Accelerators。CCIX酷似GenZ。AMD也在这个平台里。完整的时间线应该是这样的:CAPI->GenZ->CCIX->NVLINK->CXL。
那么,这几员大将,到底谁能在这场架构变革中胜出?冬瓜哥的观点是这样的,OpenCAPI基本不用考虑,IBM的生态目前无法与Intel抗衡,而且OpenCAPI只支持CPU直连,尚未支持OpenCAPI Switch,后续估计也不会搞。CXL嘛,Intel的面子大家还是要给的,加上Intel目前的生态控制力,大家就算是为了规避风险,也必然会选择跟风,所以胜算较大。但是如OpenCAPI一样,CXL目前仅仅只支持CPU点对点直连拓扑,尚未有CXL Switch的打算,不过冬瓜哥猜测,Intel更高概率不会做外部Switch,而Microchip这类外部I/O主控、Expander/Switch公司在这方面更有经验和积累,这块蛋糕给它们来做似乎更加合理,再加上业界都不想让牙膏厂继续一家独大,所以GenZ前景还是非常明朗的,从加入它的众多厂商就可以看出。老牌I/O控制器和Switch厂商Microchip目前加入了GenZ和OpenCAPI,而且是GenZ的核心贡献者,有没有可能将来是CXL+GenZ的融合架构呢?不是没有这个可能,因为在CXL发布时,Intel官方特地邀请了GenZ的发言人,其中似乎有强烈暗示CXL和GenZ应该是趋于融合,前者只管点对点直连,到了外面则交给GenZ。
至于NVLINK,既然NV要diao到底,那谁也拦不住,毕竟GPU集群使用的越来越多,GPU和GPU之间怎么勾搭那是人家自己的事情。CCIX,目前看来前景不是十分明朗,AMD和ARM这对难兄难弟能否引领CCIX独占鳌头,很难说。
2. PCIe演进方向?CCIX简介
摩尔定律逐渐降速,业界需要一同寻找提升计算性能、同时保持低功耗的方法。CCIX联盟的成立旨在实现一种新型互联,专注于新兴的加速应用,如机器学习、网络处理、存储卸载、内存数据库和4G/5G 无线技术。这个标准使得基于不同指令集的处理器,将缓存一致性、对等计算的优势扩展至许多加速设备包括FPGA、GPU、网络或存储适配器、智能网络和定制的专用集成电路。CCIX 通过扩展现有成熟的数据中心硬件和软件基础设施来简化开发和采用。这最终能使系统设计者将合适的异构组件无缝集成来满足特定系统需求。
缓存一致性的加速器互联,即CCIX™(读成“see 6”)是一种能够将两个或两个以上器件通过缓存一致性的方式来共享数据的片间互联。机器学习和大数据应用正深刻的变革数据处理的方式。通过片外加速器的定制,传统处理器从计算到网络的应用都得到了增强;这推动了产业整体向加速器和异构计算发展。对目前很多计算任务,加速器能够比单独的处理器速度更快、功耗更低的完成所需功能。但是,不受管控的异构会带来软件复杂性。CCIX 旨在优化、简化异构系统的架构设计,同时基于不同指令集(ISA)的处理器或应用特定的加速器提升系统的带宽、降低时延。
今天,高科技的版图是由新的、大规模的消费者服务的创新构成的,例如5G、云计算、物联网、大数据和自动驾驶。机器学习和人工智能应用根本性的改变了消费者行为。这又推进了平台和解决方案不断演进,通过高效、可扩展的方式来支持这些新应用。仅以中央处理器为中心的服务器架构的解决方案无法满足这些应用的性能需求。因此需要基于高效的异构计算架构的解决方案,包含加速器例如图形处理单元(GPU)、可编程逻辑阵列(FGPA)、智能网卡(NIC)和很多其它领域特定的可编程器件。PCI Express (PCIe) 是目前最常见的,处理器和片外加速器间传输数据的协议。尽管PCIe 协议作为输入输出(IO)协议很有效,但不能支持IO 设备成为对等计算模型中的一个无缝组件。
随着片外加速器的应用越来越多,高性能、低延时和易用性成为下一代互联的首要诉求。

CCIX分层架构
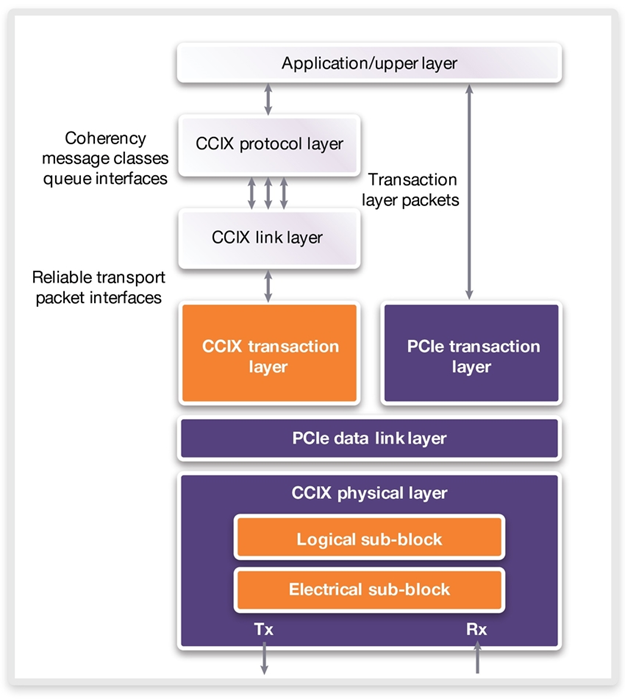
CCIX规范的最大优势之一是它建立在PCI Express规范的基础之上。CCIX的一致性协议只需很少修改或者无需修改就可以通过PCI Express链路传递。如下图所示,某个现有的PCI Express控制器实施可以通过逻辑进行扩展,以实现CCIX事务层。CCIX事务层负责携带一致性消息,而块 – 即CCIX协议层和链路层 -- 负责实现一致性协议本身并对其执行操作。这些块需要与用于缓存的内部片上系统(SoC)逻辑进行紧密集成,并且可能是特定于该SoC上使用的具体架构。在其今后设计中实现CCIX的SoC设计人员通常希望将CCIX协议及链路层与CCIX事务层分开,以使前者能够与内部SoC逻辑紧密集成。
CCIX 栈的最上层是CCIX 协议层。这一层负责一致性协议,包括内存的读、写流。这一层提供了片上一致性协议(例如Arm AMBA CHI)的简单映射。这一层定义的缓存状态使得硬件能够确定内存的状态。比如硬件可以确定数据是否唯一且未被修改(和内存一致),或是共享且被修改的(和内存不一致)。
CCIX 协议层之下是CCIX 链接层。这一层负责CCIX 协议层定义的代理(agent)之间消息的传输格式。目前CCIX 链接层是构建在PCIe 之上,但是基于分层架构,CCIX 将来可以映射到不同的传输层。此外,这一层负责端口聚合,使得多个端口能够聚合在一起提升带宽。
CCIX 和PCIe 事务层负责处理它们各自的包。PCIe 协议支持部署虚拟通道,使得不同数据流通过一个PCIe 链路。将CCIX 和PCIe 传输流各分到一个虚拟通道,CCIX 和PCIe 传输可以共享相同的链路。CCIX 能够传输标准的PCIe 包,或经过优化的CCIX 包。经过优化的CCIX 包删减了PCIe 包里的几个不必要的字段。传输标准的PCIe 包时可以采用现有的PCIe 交换器。传输经过优化的CCIX 包,能降低PCIe 的额外开销,使得一致性传输的包更小、更高效。
PCIe 数据链路层执行数据链路层的所有正常功能。这些功能包括 CRC 错误校验、包确认和超时检查,和信用初始化及交换。
如前所述,CCIX的最大的吸引力之一就是它与PCI Express的兼容性。实际上,CCIX的缓存一致性协议可以通过运行8GT/s或更快速度的任何PCI Express链路来传递。PCI Express 4.0规定的最高数据速率为16GT/s,这在一条16通道链路上可以达到总双向带宽约64GB/s,但CCIX联盟的一些成员需要更大的带宽。他们认为,通过将传输速率提高到25GT/s,一条CCIX链路可以在相同的条件下达到100GB/s。这导致出现了一项称为“扩展速度模式”(ESM)的CCIX特性。由于PCI Express由一个不同的标准化机构所拥有,所以CCIX联盟选择了一个聪明的机制用于在具有ESM功能的组件与PCI Express组件之间实现兼容性。希望彼此进行通信的两个CCIX组件可以通过正常的PCI Express链路初始化过程(通常是一个硬件自主过程)进行处理,以达到最高的相互支持的PCI Express速度。自此开始,在主机系统上运行的软件可以询问CCIX特定的配置寄存器,并确定两个组件是否都具备ESM能力。如果具备的话,则确定它们的最高支持速度。该软件然后在两个组件上编写其他CCIX特定的寄存器,以便把PCI Express链路速度映射为CCIX ESM链路速度。自此以后,链路协商将针对CCIX ESM速度,因此,通过强制进行链路重新训练,这两个组件现在可以以高达25GT/s的速度进行通信。
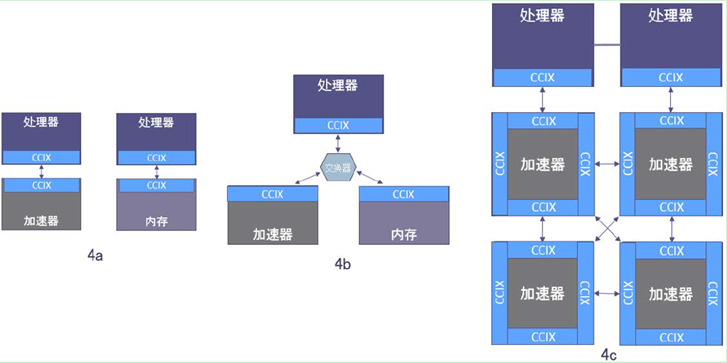
CCIX 系统拓扑样例
得益于分层架构,CCIX 能够支持多种灵活的拓扑结构。最常见的拓扑结构是直接附加的共享虚拟内存。但其它拓扑结构,如交换器、菊花链或网状拓扑,也很容易被构建和支持。
上图中,4a为直接连接,4b为交换器拓扑,4c为混合菊花链。
CCIX 一致性分层架构
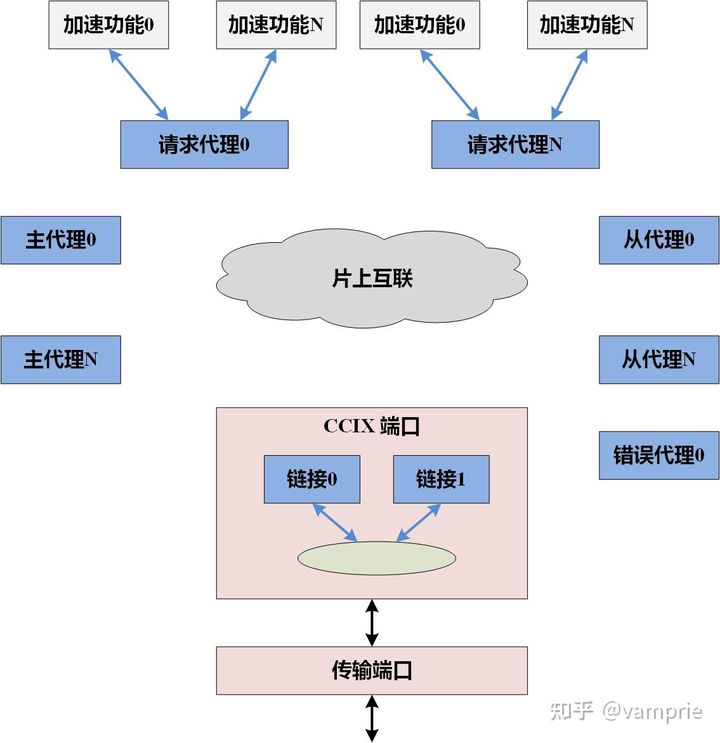
CCIX 协议定义了CCIX 组成模块的内存访问协议。所有CCIX 器件至少有一个具备CCIX 链接的端口。一个CCIX 端口关联一组物理管脚,用于和另一个CCIX 端口连接,在两个或多个不同芯片间交互信息。
同时定义了一些不同的代理类型,哪种代理在哪一个器件取决于器件的功能。定义的代理类型包括:请求代理(RA)、主代理(HA)、从代理(SA)和错误代理(Error Agent)。请求代理、主代理、从代理、错误代理,系统里的端口和链接统称CCIX 组件。一个代理在协议中由一个代理ID 标识。以下对每一种代理类型进行简要描述。
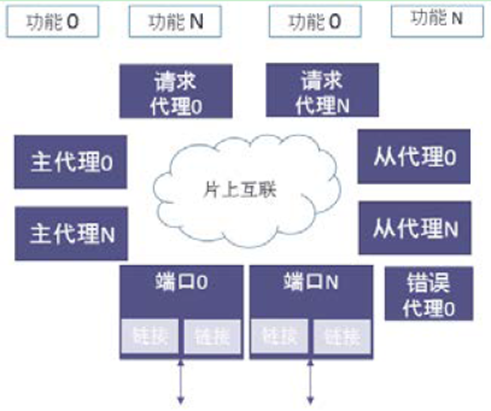
请求代理(RA) - 一个请求代理对系统内的不同地址进行读、写操作。请求代理可以对它已经访问的地址的数据进行缓存。每个CCIX 请求代理可以有一个或多个处理单元作为内部请求的发起者,它(们)的请求由一个CCIX 架构的请求代理执行。根本上说CCIX 请求代理提供了加速器或CCIX 使能的IO 主设备向一致性系统内存的接口。此外,请求代理使得加速器的缓存具备一致性,因此编程者无需感知。
主代理(HA)- 主代理负责管理指定的一段地址的数据一致性。当一个缓存行的状态需要改变时,主代理通过向所需的请求代理发出侦听操作来保持一致性。
从代理(SA)- CCIX 支持扩展系统内存,来包含外设所附的内存。这种情形出现在主代理在一个芯片上,而这个主代理关联的一些或全部物理内存在另一个芯片上时。这种架构组件(扩展内存)称为从代理。从代理不会被请求代理直接访问。请求代理总是访问一个主代理,然后主代理再访问从代理。
错误代理 - 一个错误代理接收并处理协议错误信息。协议错误信息由CCIX 组件发出。
CCIX 数据流样例
基于上述的代理类别,可以描述CCIX 可见的一些常见用例。
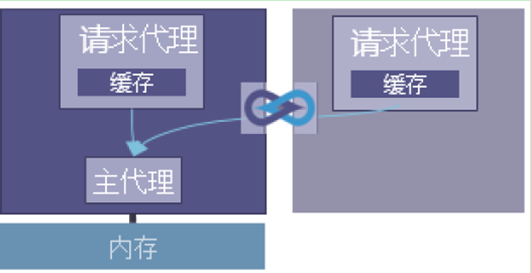
1、加速器共享处理器内存
当采用和部署CCIX 时,最常见的初始用例是处理器和加速器共享缓存。这个用例里有两个请求代理,各自管理自己的缓存。主代理在处理器上,管理连接到该处理器的内存的访问。
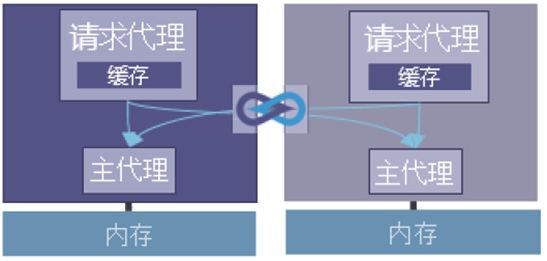
2、共享的处理器和加速器内存
下一种常用模型可能是处理器和加速器共享虚拟内存。在这个用例里,加速器和处理器的内存同在一个共享虚拟内存池里。处理器只需要简单的将待处理的数据的地址指针传给加速器,而不需要复杂的PCIeDMA 和驱动在处理器和加速器内存之间传递数据。有两个请求代理管理各自的缓存,有两个主代理管理内存。免去软件驱动开发和额外开销,可以大幅提升系统性能和简化软件。
3、拓展基本结构
得益于CCIX 非常灵活的特性,它可以在展示的这些基本数据流之外进行拓展。从直接附带的加速器、到网状拓扑和星型网络, CCIX 具备很可观的选项来支持很多种类的拓扑结构。
CCIX 软件
CCIX 对硬件的增强极大推进了片外加速器,同时CCIX 的一个关键优势是它能支持主设备和加速器间的数据共享采用无驱动的数据移动方式。传统的PCIe 加速器需要驱动对加速器写入和读出数据,这增加了延时和计算开销。采用无驱动的数据移动方式,CCIX 还可以将系统内存扩展至主设备的内存之外。
基于CCIX,每个支持CCIX 的设备的行为与现有NUMA(非统一内存访问)操作系统中的节点类似。这种基于内存的方法利用了现有的操作系统功能。在这种模式下,用来共享的所有数据结构都放在处理器和加速器都可访问的共享内存里。这种数据共享模型可以消除加速器特定的控制与管理驱动,允许加速器资源由一个中心调度器安排的长时间运行的任务来调用。这个调度器可以是操作系统调度程序的一部分,或和操作系统调度程序协同。这能简化在虚机或容器上运行的应用所用的软件库,允许开发者用任何语言、有完整的工具支持来编写常规的应用软件。
3. PCI、PCIX、PCIE、CPCI介绍


3.1. PCI
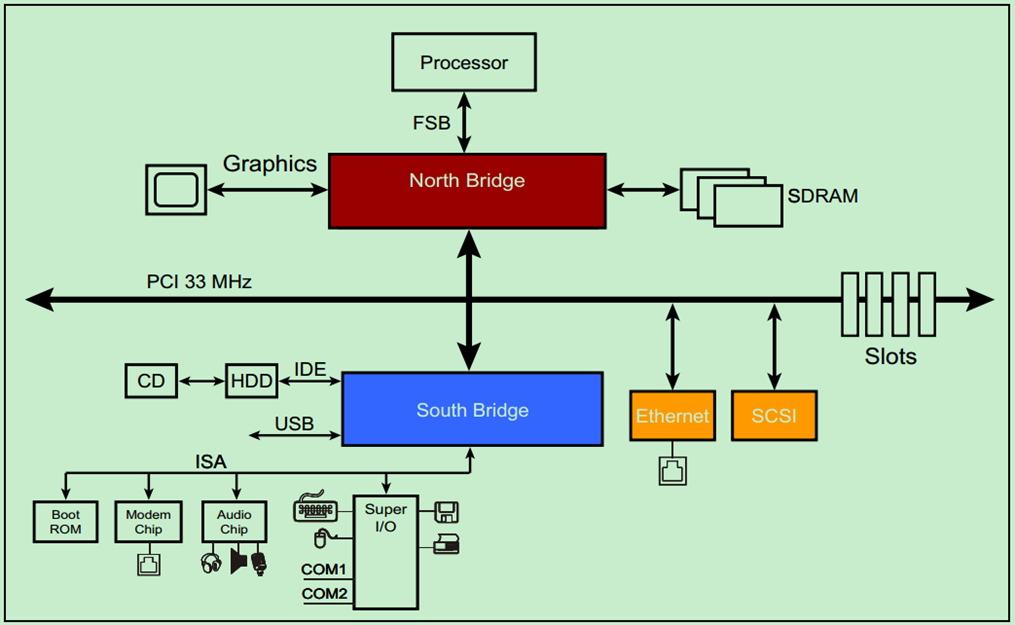
PCI,外设组件互连标准(Peripheral Component Interconnection),是一种由英特尔(Intel)公司1991年推出的用于定义局部总线的标准。此标准允许在计算机内安装多达10个遵从PCI标准的扩展卡。最早提出的PCI总线工作在33MHz频率之下,传输带宽达到133MB/s(33MHz * 32bit/s),基本上满足了当时处理器的发展需要。随着对更高性能的要求,1993年又提出了64bit的PCI总线,后来又提出把PCI 总线的频率提升到66MHz。目前(注:此文写的时间比较早)广泛采用的是32-bit、33MHz的PCI 总线,64bit的PCI插槽更多是应用于服务器产品。从结构上看,PCI是在CPU和原来的系统总线之间插入的一级总线,具体由一个桥接电路实现对这一层的管理,并实现上下之间的接口以协调数据的传送。管理器提供信号缓冲,能在高时钟频率下保持高性能,同时为显卡,声卡,网卡,MODEM等设备提供连接接口,工作频率为33MHz/66MHz。
PCI总线系统要求有一个PCI控制卡,它必须安装在一个PCI插槽内。这种插槽是目前主板带有最多数量的插槽类型,在当前流行的台式机主板上,ATX结构的主板一般带有5~6个PCI插槽,而小一点的MATX主板也都带有2~3个PCI插槽。根据实现方式不同,PCI控制器可以与CPU一次交换32位或64位数据,它允许智能PCI辅助适配器利用一种总线主控技术与CPU并行地执行任务。PCI允许多路复用技术,即允许一个以上的电子信号同时存在于总线之上。
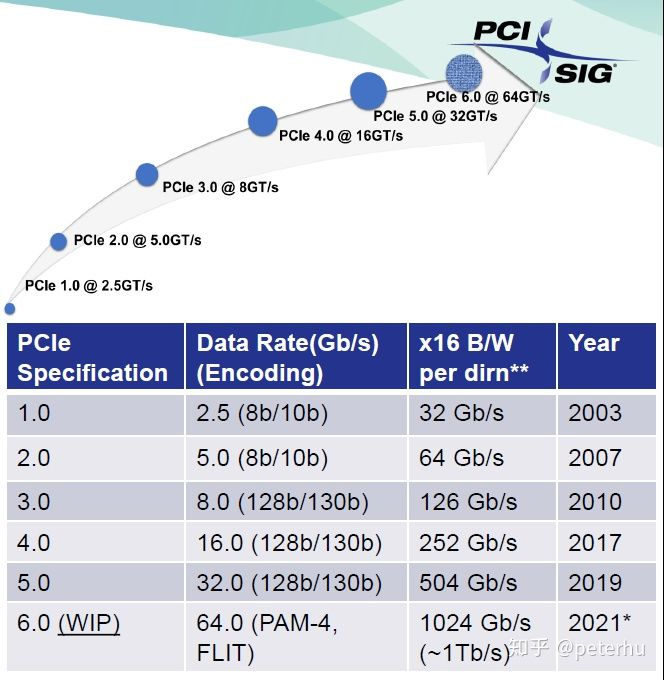
由于PCI 总线只有133MB/s的带宽,对声卡、网卡、视频卡等绝大多数输入/输出设备显得绰绰有余,但对性能日益强大的显卡则无法满足其需求。Intel在2001年春季的IDF上,正式公布了旨在取代PCI总线的第三代I/O技术,该规范由Intel支持的AWG(Arapahoe Working Group)负责制定。2002年4月17日,AWG正式宣布3GIO1.0规范草稿制定完毕,并移交PCI-SIG(PCI特别兴趣小组,PCI-Special Interest Group)进行审核。开始的时候大家都以为它会被命名为Serial PCI(受到串行ATA的影响),但最后却被正式命名为PCI Express,Express意思是高速、特别快的意思。
2002年7月23日,PCI-SIG 正式公布了PCI Express 1.0规范,并于2007年初推出2.0规范(Spec
2.0),将传输率由PCI Express 1.1的2.5GB/s提升到5GB/s。
1.1. PCIX
PCI-X接口是并连的PCI总线的更新版本,仍采用传统的总线技术,不过有更多数量的接线针脚,同时,如前所述的所有的连接装置会共享所有可用的频宽。
与原先PCI接口所不同的是:一改过去的32位,PCI-X采用64位宽度来传送数据,所以频宽自动就倍增两倍,而扩充槽的长度当然就不可避免的加大了,除此之外,其余的包括传输通讯协议、讯号和标准的接头格式都一并兼容,好处是3.3V的32位的PCI适配卡可以用在PCI-X扩充槽上,当然如果你愿意,也可以将64位PCI-X适配卡接在32位PCI扩充槽上,不过,频宽速度将会大减。
这个总线宽度倍增的改良版本对一些专业储存控制器,例如SCSI、iSCSI、光纤信道(Fibre Channel)、10GBit以太网和InfiniBand等其他传输装置,仍然无法提供足够的频宽,因此引进PCI-SIG接口以提供数个不同速度等级,可以从PCI-X 66一路上到PCI-X 533规格,以下表列这些技术细节:
|
总线宽度 |
频率速度 |
功能 |
频宽 |
|
PCI-X 66 64位 |
66MHz |
Hot Plugging,3.3V |
533MB/s |
|
PCI-X 133 64位 |
133MHz |
Hot Plugging,3.3V |
1.06GB/s |
|
PCI-X 266 64位/16位 |
133MHz Double Data |
Hot Plugging,3.3V&1.5V ECC supported |
2.13gb/S |
|
PCI-X 533 64/16位 |
133MHz Quad Data Rate |
Hot Plugging,3.3&1.5V ECC supported |
4.26GB/s |
你可以看到当频率速度到达了PCI-X 133的133MHz事后,就再也升不上去,为了让频宽能够倍增,于是不惜将主存储器及前端总线上已经行之有年而且路人皆知的技术搬过来,因此,PCI-X 266用上Double Data Rate技术,让每一个时钟脉冲的上升与下降边缘都可以传输数据,所以又多出了一倍的机会来传输数据,而PCI-X 533规格更进一步采用每一个时钟脉冲可以传送四次的技术,英特尔早在所有的Pentium 4和Xeon处理器的前端总线就用上这些技术了。
1.1. PCIE
PCI-Express是最新的总线和接口标准,它原来的名称为“3GIO”,是由英特尔提出的,很明显英特尔的意思是它代表着下一代I/O接口标准。交由PCI-SIG(PCI特殊兴趣组织)认证发布后才改名为“PCI-Express”。这个新标准将全面取代现行的PCI和AGP,最终实现总线标准的统一。它的主要优势就是数据传输速率高,目前最高可达到10GB/s以上,而且还有相当大的发展潜力。PCI Express也有多种规格,从PCI Express 1X到PCI Express 16X,能满足现在和将来一定时间内出现的低速设备和高速设备的需求。能支持PCI Express的主要是英特尔的i915和i925系列芯片组。当然要实现全面取代PCI和AGP也需要一个相当长的过程,就象当初PCI取代ISA一样,都会有个过渡的过程。
1.1. CPCI
Compact PCI(Compact Peripheral Component Interconnect)简称CPCI,中文又称紧凑型PCI,是国际工业计算机制造者联合会(PCI Industrial Computer Manufacturer's Group,简称PICMG)于1994提出来的一种总线接口标准。是以PCI电气规范为标准的高性能工业用总线。CPCI的CPU及外设同标准PCI是相同的,并且CPCI系统使用与传统PCI系统相同的芯片、防火墙和相关软件。从根本上说,它们是一致的,因此操作系统、驱动和应用程序都感觉不到两者的区别,将一个标准PCI插卡转化成CPCI插卡几乎不需重新设计,只要物理上重新分配一下即可。为了将PCI SIG的PCI总线规范用在工业控制计算机系统,1995年11月PICMIG颁布了CPCI规范1.0版,以后相继推出了PCI-PCI Bridge规范、Computer Telephony TDM规范和User-defined I/O pin assignment规范。简言之CPCI总线 = PCI总线的电气规范 + 标准针孔连接器+ 欧洲卡规范。
CPCI的出现不仅让诸如CPU、硬盘等许多原先基于PC的技术和成熟产品能够延续应用,也由于在接口等地方做了重大改进,使得采用CPCI技术的服务器、工控电脑等拥有了高可靠性、高密度的优点。CPCI是基于PCI电气规范开发的高性能工业总线,适用于3U和6U高度的电路插板设计。CPCI电路插板从前方插入机柜,I/O数据的出口可以是前面板上的接口或者机柜的背板。它的出现解决了多年来电信系统工程师与设备制造商面临的棘手问题,比如传统电信设备总线VME与工业标准PCI总线不兼容问题。
CPCI技术是在PCI技术基础之上经过改造而成,其特点具体有三个方面:
一是继续采用PCI局部总线技术;
二是抛弃IPC传统机械结构,改用经过20年实践检验了的高可靠欧洲卡结构,改善了散热条件、提高了抗振动冲击能力、符合电磁兼容性要求;
三是抛弃IPC的金手指式互连方式,改用2mm密度的针孔连接器,具有气密性、防腐性,进一步提高了可靠性,并增加了负载能力。
CPCI规范自制定以来,已历经多个版本。最新的PICMG 3.0所规范的CPCI技术架构在一个更加开放、标准的平台上,有利于各类系统集成商、设备供应商提供更加便捷快速的增值服务,为用户提供更高性价比的产品和解决方案。PICMG 3.0标准是一个全新的技术,与PICMG 2.x完全不同,特别在速度上与PICMG 2.x相比,PICMG 3.0速度每秒可达2Tb。PICMG 3.0主要将应用在高带宽电信传输上,以适应未来电信的发展,PICMG 2.x则仍是目前CPCI的主流,并将在很长时间内主宰CPCI的应用。
CPCI具有可热插拔(Hot Swap)、高开放性、高可靠性。CPCI技术中最突出、最具吸引力的特点是热插拔。简言之,就是在运行系统没有断电的条件下,拔出或插入功能模板,而不破坏系统的正常工作的一种技术。热插拔一直是电信应用的要求,也为每一个工业自动化系统所渴求。它的实现是:在结构上采用三种不同长度的引脚插针,使得模板插入或拔出时,电源和接地、PCI总线信号、热插拔启动信号按序进行;采用总线隔离装置和电源的软启动;在软件上,操作系统要具有即插即用功能。目前CPCI总线热插拔技术正在从基本热切换技术向高可用性方向发展。
CPCI所具有高开放性、高可靠性、可热插拔的特点,使该技术除了可以广泛应用在通讯、网络、计算机电话之外,也适合实时系统控制、产业自动化、实时数据采集、军事系统等需要高速运算、智能交通、航空航天、医疗器械、水利等模块化及高可靠度、可长期使用的应用领域。由于CPCI拥有较高的带宽,它也适用于一些高速数据通信的应用,包括服务器、路由器、交换机等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号