ShuffleNet深度学习网络-结构简介
参考博文:https://www.cnblogs.com/dengshunge/p/11407104.html
ShuffleNet是旷世提出的高效轻量化网络,是一款很值得一提的轻量化网络,其相关论文也是很有价值的。
ShuffleNet V1
该网络提出于2017年,论文为《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》。
由于Xception和ResNeXt中存在大量密集的1*1卷积,导致网络十分低效。因此,旷世提出了pointwise group convolutions来减少1*1卷积的计算复杂度。但是,这样会带来副作用:通道间的信息没有得到很好的交流融合。所以,继而提出channel shuffle来帮助信息在不同特征通道中的流动。可以看出,ShuffleNet V1的主要两个创新点是pointwise group convolutions和channel shuffle。
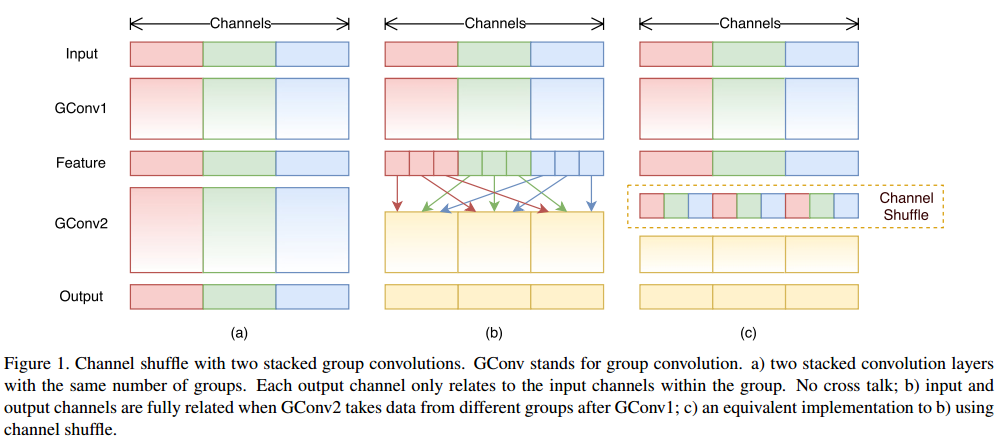
如Fig.1所示,左图是普通的group卷积,卷积核只有相应的输入通道进行作用,不同通道之间信息没有交流。如果组数等于通道数,就可以理解成mobilenet中的depthwise convolution。(b)图是将通道进行重新打乱排列,使得不同通道信息之间能相互交流。(c)图是(b)图的等价,使用了channle shuffle进行通道重新排列。如果group卷积能够获得不同group中的输入数据,输入特征和输出特征就能很好的关联起来。通过channle shuffle操作,能构建更加强有力的网络结构。
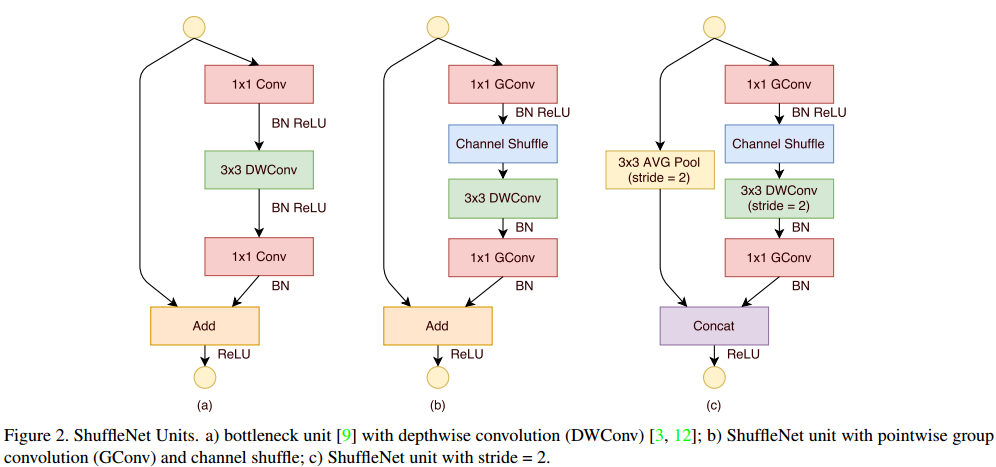
为了使用好channel shuffle的操作,作者提出了ShuffleNet网络。首先,我们先看一下其基本单元ShuffleNet Unit。如Fig.2所示,(a)图是ResNeXT的残差模块,经过1*1的卷积来降低通道数,然后使用3*3的group卷积,最后使用1*1的卷积将通道数提升回原来。(b)图是作者提出的ShuffleNet Unit,与残差模块类似,将残差模块中的1*1卷积换成1*1的group卷积,并加入了channel shuffle操作。值得注意的是,3*3的group卷积后,没有接激活函数。(c)图是步长为2的情况,基本类似,但最后是concat操作,而不是add,这样做的目的是在很小的计算成本下,更容易扩大通道数。
接下来分析一下,ShuffleNet的FLOPs的变化。假设输出尺寸为c∗h∗wc∗h∗w,和bottleneck中的通道数为mm,gg是分组的组数。
- ResNet的FLOPs为hwcm+9hwm2+hwmc=9hwm2+2hwcmhwcm+9hwm2+hwmc=9hwm2+2hwcm
- ResNeXt的FLOPs为hwcm+9hwm2/g2+hwcm=9hwm2/g+2hwcmhwcm+9hwm2/g2+hwcm=9hwm2/g+2hwcm
- ShuffleNet的FLOPs为9hwm+2hwcm/g9hwm+2hwcm/g(但我自己计算出来的是hwcm/g2+9hwm2/g2+hwcm/g2hwcm/g2+9hwm2/g2+hwcm/g2,不知道哪里出错的)
可以看出,ShuffleNet相对的FLOPs较小。换而言之,在相同的计算资源限制下,ShuffleNet能使用更宽的特征图。这个对轻量化网络来说,是非常重要的。因为轻量化网络通常由于特征图宽度不足而无法更好处理信息。
基于提出的ShuffleNet Unit,可以构建出Shuffle网络, 如Table.1所示。在整体计算资源变化不大下(~140MFLOPs),当组数g扩大的时候,可以采用更加宽的特征图,来更好的编码信息。

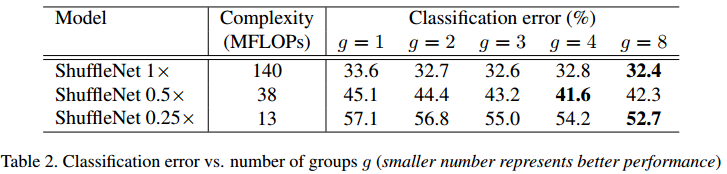
为了评估pointwise group convolution的重要性,作者在上面的网络中使用了不同的g值(通道数会变化的情况),结果如Table.1所示。利用看出,当g>1时,性能会比g=1的情况好(g=1的网络类似于Xception)。所以,小网络会因为分组而得到准确率上的提升。作者认为这是因为更大的特征图宽度对特征的编码起到更多作用。但也值得注意的是,g值越大并不一定越好,网络可能会饱和或者准确率出现恶化。
最后作者在ARM平台上测试了ShuffleNet的真实速度,发现,尽管g=4或者g=8有更高的准确率,但效率却不是最高的。最终采用g=3来折中准确率和最终运行速度。作者还尝试了加入SE模块,但速度大大变慢了。
ShuffleNet V2
该网络提出于2018年,《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》。主要的创新点是提出了4条轻量化的原则,并基于此4条原则,在v1基础上提出了ShuffleNet V2。
首先介绍一下FLOPs,这里引用了知乎博主的介绍。
FLOPS: floating point operations per second
FLOPs: floating point operations
FLOPS: 全大写,指每秒浮点运算次数,可以理解为计算的速度。是衡量硬件性能的一个指标。(硬件)
FLOPs: s小写,指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。(模型) 在论文中常用GFLOPs(1 GFLOPs = 10^9 FLOPs)
在衡量计算复杂度时,通常使用的是FLOPs(the number of float-point operations),但FLOPs是一个间接衡量的指标,它是一种近似但不等价于直接衡量指标。在实际中,我们所关心的是速度或者延时,而这些才是直接衡量的指标。因此,使用FLOPs作为唯一衡量计算复杂度的指标,是不充分的,而且容易导致次优的网络设计。
直接衡量指标(速度)和间接衡量指标(FLOPs)之间的差异,主要源于以下两个原因:
- 还有多个影响速度的指标,并未纳入FLOPs的考虑范围中。例如MAC(memory access cost,内存访问成本),MAC对group卷积的速度影响很大;平行度(degree of parallelism),高平行度的网络的推理速度更快。
- 不同平台对推理时间的影响。例如,CUDNN对3*3的卷积进行了优化,不能简单认为其是1*1卷积的9倍。
所以,接下来作者对网络的衡量指标有两点,i)使用直接衡量指标(速度);ii)在特定的同一个平台上进行衡量。

Fig.2是ShuffleNet v1和MobileNet v2的时间占比图。从图中可以看出,FLOPs仅仅是考虑了卷积部分,但其他时间同样不能忽略,例如数据的读取,Element-wise等操作。
基于上述的观察,提出了4条关于轻量化网络设计的原则:
- 当输入通道数和输出通道数的值接近1:1时,能减少MAC时间;
- 过多的group卷积,会增加MAC时间;
- 网络的分裂会降低平行度;
- Element-wise操作是不可以忽略的,包括ReLU,AddTensor,ADDBias等。
作者批判了部分轻量化网络,ShuffleNet v1过多依赖于group卷积,违反了原则2,而且使用了bottleneck模块,违反了原则1;MobileNet v2使用了倒残差模块,违反了原则1,使用了过多的深度可分离卷积核ReLU,违反了原则4;而AutoML出来的网络会存在分裂,违反了原则3。
所以,根据上述的4条原则,设计一种高效而且轻量化网络的关键是,如何保持大通道数和通道数不变的情况下,即不使用过多卷积,又不过多分组。

为了实现刚刚说的目的,引入了channel split操作,如Fig.3所示。(a)和(b)图是ShuffleNet v1中的基础单元。(c)图是引入了channel split操作的ShuffleNet v2的基本单元。(d)图是步长为2时的单元。
在该单元一开始,输入被分成两个分支,通道数分别是c−c‘c−c‘和c‘c‘。左边的分支保持不变,恒定变化;右边的分支会经过3个卷积,使用了相同的输入通道数和输出通道数。其中,两个1*1的卷积不再是group卷积,而是普通的卷积。当卷积完成后,两个分支会进行concat,最后使用channel shuffle来进行不同通道之间的信息交流。
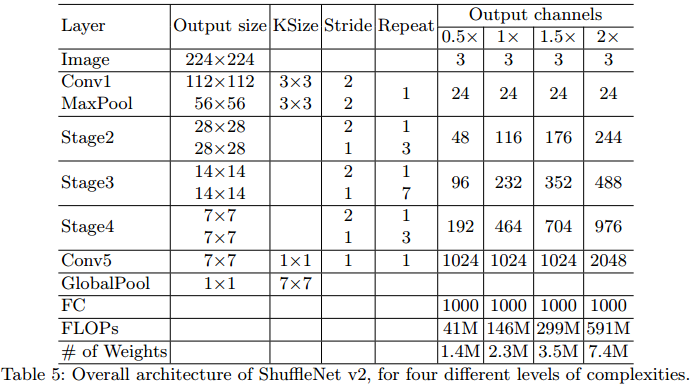
基于上述的基本单元,构成ShuffleNet v2的网络结构,如Table.5所示。其中,c‘=c/2c‘=c/2。
综上所述,ShuffleNet v2提出的4条原则,是十分有意义的。现在很多AutoML出来的网络,其是以FLOPS作为限制条件的,所以最后出来的网络FLOPS很低,但实际进行测试时,速度缺未能达到预期效果,如EfficientNet b0,实测速度约为11ms,在resnet34的速度为6ms。
另外,在接近的计算资源下,ShuffleNet v2确实能达到较高的准确率和速度,是一个很好的网络结构。
最后,旷世在一年后,开源了ShuffleNet,有兴趣的话,开源研究一下:https://github.com/megvii-model/ShuffleNet-Series

 浙公网安备 33010602011771号
浙公网安备 33010602011771号