Faster-RCNN深度学习网络-结构简介
参考博文:https://blog.csdn.net/zziahgf/article/details/79311275
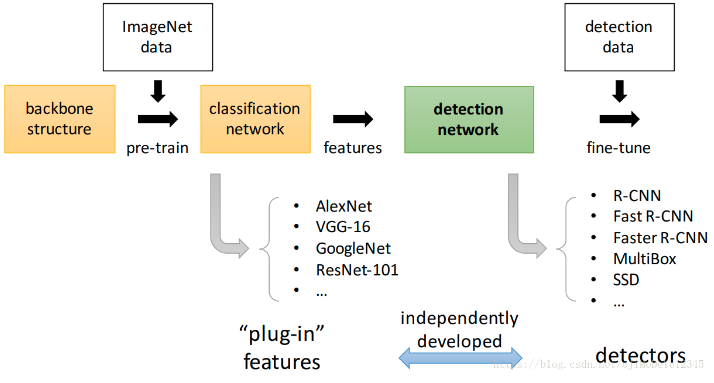
目标检测的一般结构:
1. 背景
Faster R-CNN 发表于 NIPS 2015,其后出现了很多改进版本,后面会进行介绍.
R-CNN - Rich feature hierarchies for accurate object detection and semantic segmentation 是 Faster R-CNN 的启发版本. R-CNN 是采用 Selective Search 算法来提取(propose)可能的 RoIs(regions of interest) 区域,然后对每个提取区域采用标准 CNN 进行分类.
出现于 2015 年早期的 Fast R-CNN 是 R-CNN 的改进,其采用兴趣区域池化(Region of Interest Pooling,RoI Pooling) 来共享计算量较大的部分,提高模型的效率.
Faster R-CNN 随后被提出,其是第一个完全可微分的模型. Faster R-CNN 是 R-CNN 论文的第三个版本.
R-CNN、Fast R-CNN 和 Faster R-CNN 作者都有 Ross Girshick.
2. 网络结构
Faster R-CNN 的结构是复杂的,因为其有几个移动部件. 这里先对整体框架宏观介绍,然后再对每个部分的细节分析.
问题描述:
针对一张图片,需要获得的输出有:
- 边界框(bounding boxes) 列表;
- 每个边界框的类别标签;
-
每个边界框和类别标签的概率.

Figure 1. Faster R-CNN 结构
首先,输入图片表示为 Height × Width × Depth 的张量(多维数组)形式,经过预训练 CNN 模型的处理,得到卷积特征图(conv feature map). 即将 CNN 作为特征提取器,送入下一个部分.
这种技术在迁移学习(Transfer Learning)中比较普遍,尤其是,采用在大规模数据集训练的网络权重,来对小规模数据集训练分类器. 后面会详细介绍.
然后,RPN(Region Propose Network) 对提取的卷积特征图进行处理. RPN 用于寻找可能包含 objects 的预定义数量的区域(regions,边界框).
基于深度学习的目标检测中,可能最难的问题就是生成长度不定(variable-length)的边界框列表. 在构建深度神经网络时,最后的网络输出一般是固定尺寸的张量输出(采用RNN的除外). 例如,在图片分类中,网络输出是 (N, ) 的张量,N 是类别标签数,张量的每个位置的标量值表示图片是类别 labeli 的概率值.
在 RPN 中,通过采用 anchors 来解决边界框列表长度不定的问题,即,在原始图像中统一放置固定大小的参考边界框. 不同于直接检测 objects 的位置,这里将问题转化为两部分:
对每一个 anchor 而言,
- anchor 是否包含相关的 object?
- 如何调整 anchor 以更好的拟合相关的 object?
这里可能不容易理解,后面会深入介绍.
当获得了可能的相关objects 和其在原始图像中的对应位置之后,问题就更加直接了. 采用 CNN 提取的特征和包含相关 objects 的边界框,采用 RoI Pooling 处理,并提取相关 object 的特征,得到一个新的向量.
最后,基于 R-CNN 模块,得到:
- 对边界框内的内容进行分类,(或丢弃边界框,采用 background 作为一个 label.)
- 调整边界框坐标,以更好的使用 object.
显而易见,上面忽略了一些重要的细节信息. 但,包括了 Faster R-CNN 的大致思想.
3. 基础网络
正如上面所说,Faster R-CNN 第一步是采用基于分类任务(如,ImageNet)的 CNN 模型作为特征提取器. 听起来是比较简单的,但,重要的是理解其如何工作和为什么会有效,并可视化中间层,查看其输出形式.
网络结构很难说哪种是最好的. Faster R-CNN 最早是采用在 ImageNet 训练的 ZF 和 VGG,其后出现了很多其它权重不同的网络. 如,MobileNet 是一种小型效率高的网络结构,仅有 3.3M 参数;而,ResNet-152 的参数量达到了 60M. 新网络结构,如 DenseNet 在提高了结果的同时,降低了参数数量.
3.1. VGG
在讨论网络结构孰优孰劣之前,这里以 VGG16 为例.
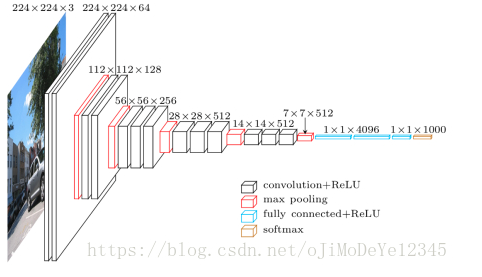
Figure 2. VGG16 网络结构
VGG16 是 ImageNet ILSVRC 2014 竞赛的模型,其是由 Karen Simonyan 和 Andrew Zisserman 发表在论文 Very Deep Convolutional Networks for Large-Scale Image Recognition 上.
今天来看,VGG16 网络结构是不算深的,但在当时,其将网络层比常用的网络结构扩展了两倍,开始了 “deeper→more capacity→better”的网络结构设计方向(在训练允许的情况).
VGG16 图片分类时,输入为 224×224×3 的张量(即,一张 224×224 像素的 RGB 图片). 网络结构最后采用 FC 层(而不是 Conv 层)得到固定长度的向量,以进行图片分类. 对最后一个卷积层的输出拉伸为 rank 1 的张量,然后送入 FC 层.
由于 Faster R-CNN 是采用 VGG16 的中间卷积层的输出,因此,不用关心输入的尺寸. 而且,该模块仅利用了卷积层. 进一步去分析模块所使用的哪一层卷积层. Faster R-CNN 论文中没有指定所使用的卷积层,但在官方实现中是采用的卷积层 conv5/conv5_1 的输出.
每个卷积层利用前面网络信息来生成抽象描述. 第一层一般学习边缘edges信息,第二层学习边缘edges中的图案patterns,以学习更复杂的形状等信息. 最终,可以得到卷积特征图,其空间维度(分辨率)比原图小了很多,但更深. 特征图的 width 和 height 由于卷积层间的池化层而降低,而 depth 由于卷积层学习的 filters 数量而增加.

Figure 3. 卷积特征图
在 depth 上,卷积特征图对图片的所有信息进行了编码,同时保持相对于原始图片所编码“things”的位置. 例如,如果在图片的左上角存在一个红色正方形,而且卷积层有激活响应,那么该红色正方形的信息被卷积层编码后,仍在卷积特征图的左上角.
3.2. VGG vs ResNet
ResNet 结构逐渐取代 VGG 作为基础网络,用于提取特征. Faster R-CNN 的共同作者也是 ResNet 网络结构论文 Deep Residual Learning for Image Recognition 的共同作者.
ResNet 相对于 VGG 的明显优势是,网络更大,因此具有更强的学习能力. 这对于分类任务是重要的,在目标检测中也应该如此.
另外,ResNet 采用残差连接(residual connection) 和 BN (batch normalization) 使得深度模型的训练比较容易. 这对于 VGG 首次提出的时候没有出现.
3.3. Anchors
在获得了处理后的图片后,需要寻找 proposals,如用于分类的 RoIs(regions of interest). anchors 是用来解决长度不定问题的.
目标是,寻找图片中的边界框bounding boxes,边界框是具有不同尺寸sizes和长宽比aspect ratios 的矩形.
假设,已经知道图片中有两个 objects,首先想到的是,训练一个网络,输出 8 个值:两对元组 xmin,ymin,xmax,ymax,分别定义了每个 object 的边界框. 这种方法存在一些基本问题. 例如,当图片的尺寸和长宽比不一致时,良好训练模型来预测,会非常复杂. 另一个问题是无效预测:预测 xmin 和 xmax 时,需要保证 xmin<xmax.
事实上,有一种更加简单的方法来预测 objects 的边界框,即,学习相对于参考boxes 的偏移量. 假设参考 box:xcenter,ycenter,width,height,待预测量 Δxcenter,Δycenter,Δwidth,Δheight,一般都是很小的值,以调整参考 box 更好的拟合所需要的.
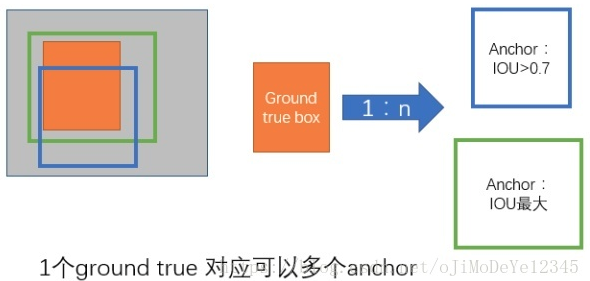
Anchors 是固定尺寸的边界框,是通过利用不同的尺寸和比例在图片上放置得到的 boxes,并作为第一次预测 object 位置的参考 boxes.

因为是对提取的 Convwidth×Convheight×ConvDepth 卷积特征图进行处理,因此,在 Convwidth×Convheight 的每个点创建 anchors. 需要理解的是,虽然 anchors 是基于卷积特征图定义的,但最终的 anchos 是相对于原始图片的.
由于只有卷积层和 pooling 层,特征图的维度是与原始图片的尺寸成比例关系的. 即,数学地表述,如果图片尺寸 w×h,特征图的尺寸则是 w/r×h/r. 其中,r 是下采样率(subsampling ratio). 如果在卷积特征图空间位置定义 anchor,则最终的图片会是由 r 像素划分的 anchors 集. 在 VGG 中, r=16.

Figure 4. 原始图片上的 Anchor Centers.
为了选择 anchors 集,一般是先定义许多不同尺寸(如,64px,128px,256px等)和boxes 长宽比(如,0.5,1,1.5等),并使用所有可能的尺寸和比例组合.

Figure 5. 左:Anchors;中:单个点的 Anchor;右:全部Anchors.
4. RPN - Region Proposal Network
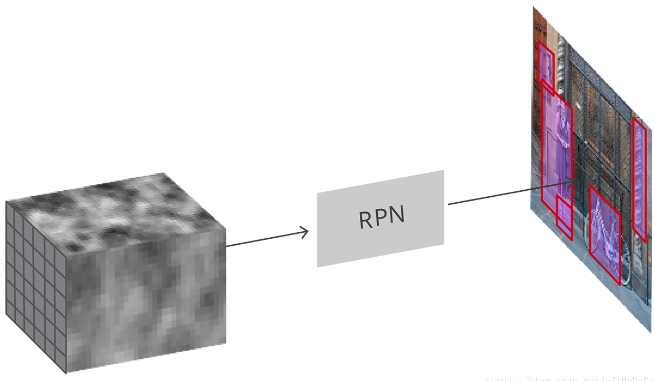
Figure 6. RPN 结构 - RPN 输入是卷积特征图,输出图片生成的 proposals.
RPN 利用所有的参考 boxes(anchors),输出一系列 objecs 的良好的 proposals. 针对每个 anchor,都有两个不同的输出:
[1] - anchor 内是某个 object 的概率.
RPN 不关注于 anchor 是某个 object class,只是确定其可能是一个 object (而不是背景background). 即: RPN 不关心 object 类别,只确定是 object 还是 background.
利用 object score,去滤出将要用于第二阶段的效果不佳的 boxes.
[2] - anchor 边界框回归输出
边界框的输出用于调整 anchors 来更好的拟合预测的 object.
RPN 是全卷积(full conv) 网络,其采用基础网络输出的卷积特征图作为输入. 首先,采用 512 channel,3×3 kernel 的卷积层,然后是两个并行的 1×1 kernel 的卷积层,该卷积层的 channels 数量取决每个点的 anchors 的数量.

Figure 7. RPN 结构的全卷积实现,k 是 anchors 数量.
对于分类层,每个 anchor 输出两个预测值:anchor 是背景(background,非object)的 score 和 anchor 是前景(foreground,object) 的 score.
对于回归层,也可以叫边界框调整层,每个 anchor 输出 4 个预测值:Δxcenter,Δycenter,Δwidth,Δheight,即用于 anchors 来得到最终的 proposals.
根据最终的 proposal 坐标和其对应的 objectness score,即可得到良好的 objects proposals.
4.1. 训练、目标和损失函数
RPN 有两种类型的预测值输出:二值分类和边界框回归调整.
训练时,对所有的 anchors 分类为两种类别. 与 ground-truth object 边界框的 Intersection over Union (IoU) 大于 0.5 的 anchors 作为 foreground;小于 0.1 的作为 background.
然后,随机采样 anchors 来生成batchsize=256 的 mini-batch,尽可能的保持 foreground 和 background anchors 的比例平衡.
RPN 对 mini-batch 内的所有 anchors 采用 binary cross entropy 来计算分类 loss. 然后,只对 mini-batch 内标记为 foreground 的 anchros 计算回归 loss. 为了计算回归的目标targets,根据 foreground anchor 和其最接近的 groundtruth object,计算将 anchor 变换到 object groundtruth 的偏移值 correct Δ.
Faster R-CNN 没有采用简单的 L1 或 L2 loss 用于回归误差,而是采用 Smooth L1 loss. Smooth L1 和 L1 基本相同,但是,当 L1 误差值非常小时,表示为一个确定值 σ, 即认为是接近正确的,loss 就会以更快的速度消失.
采用动态 batches 是很有挑战性的. 即使已经尝试保持 background 和 foreground 的 anchors 的平衡比例,也不总是可行的. 根据图片中 groundtruth objects 和 anchors 的尺度与比例,很有可能得不到 foreground anchors. 这种情况时,将采用与 groundtruth boxes 具有最大 IoU 的 anchors. 这与理想情况相差很远,但实际中一般总能有 foreground 样本和要学习目标.
4.2. 后处理
[1] - 非极大值抑制(Non-maximum suppression)
由于 Anchors 一般是有重叠的overlap,因此,相同 object 的 proposals 也存在重叠.
为了解决重叠 proposals 问题,采用 NMS 算法处理,丢弃与一个score 更高的 proposal 间 IoU 大于预设阈值的 proposals.
虽然 NMS 看起来比较简单,但 IoU 阈值的预设需要谨慎处理. 如果 IoU 值太小,可能丢失 objetcs 的一些 proposals;如果 IoU 值过大,可能会导致 objects 出现很多 proposals. IoU 典型值为 0.6.
[2] - Proposal 选择
NMS 处理后,根据 sore 对 topN 个 proposals 排序. 在 Faster R-CNN 论文中 N=2000,其值也可以小一点,如 50,仍然能的高好的结果.
4.3. 单独应用 RPN
RPN 可以独立使用,不用 2-stage 模型.
当处理的问题是,单个 object 类时,objectness 概率即可作为最终的类别概率. 此时,“foreground” = “single class”,“background”=“not single class”.
可以应用于人脸检测(face detection),文字检测(text detection),等.
仅单独采用 RPN 的优点在于,训练和测试速度较快. 由于 RPN 是仅有卷积层的简单网络,其预测效率比采用分类 base 网络的效率高.
5. RoI Pooling
RPN 处理后,可以得到一堆没有 class score 的 object proposals.
待处理问题为,如何利用这些边界框 bounding boxes,并分类.
一种最简单的方法是,对每个 porposal,裁剪,并送入pre-trained base 网络,提取特征;然后,将提取特征来训练分类器. 但,这就需要对所有的 2000 个 proposals 进行计算,效率低,速度慢.
Faster R-CNN 则通过重用卷积特征图(conv feature map) 来加快计算效率. 即,采用 RoI(region of interest) Pooling 对每个 proposal 提取固定尺寸的特征图. R-CNN 是对固定尺寸的特征图分类.
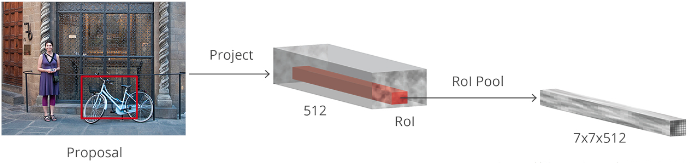
Figure 8. RoI Pooling
目标检测中,包括 Faster R-CNN,常用一种更简单的方法,即:采用每个 proposal 来对卷积特征图裁剪crop,然后利用插值算法(一般为双线性插值 bilinear)将每个 crop resize 到固定尺寸 14×14×ConvDepth. 裁剪后,利用 2×2 kernel 的 Max Pooling 得到每个 proposal 的最终 7×7×ConvDepth 特征图.之所以选择该精确形状,与其在下面的模块(R-CNN)中的应用有关.
6. R-CNN -- Region-based CNN
R-CNN 是 Faster R-CNN 框架中的最后一个步骤.
- 计算图片的卷积特征图conv feature map;
- 然后采用 RPN 对卷积特征图处理,得到 object proposals;
- 再利用 RoI Pooling 对每个 proposal 提取特征;
- 最后,利用提取特征进行分类.
R-CNN 是模仿分类 CNNs 的最后一个阶段,采用全连接层来输出每个可能的 object 类别class 的score.
R-CNN 有两个不同的输出:
- 对每个 proposal 分类,其中类别包括一个 background 类(用于去除不良 proposals);
- 根据预测的类别class,更好的调整 proposal 边界框.
在 Faster R-CNN 论文中,R-CNN 对每个 proposal 的特征图,拉平flatten,并采用 ReLU 和两个大小为 4096 维的全连接层进行处理.然后,对每个不同 objects 采用两个不同的全连接层处理:
- 一个全连接层有 N+1 个神经单元,其中 N 是类别 class 的总数,包括 background class;
- 一个全连接层有 4N 个神经单元. 回归预测输出,得到 N 个可能的类别 classes 分别预测 Δcenterx,Δcentery,Δwidth,Δheight.
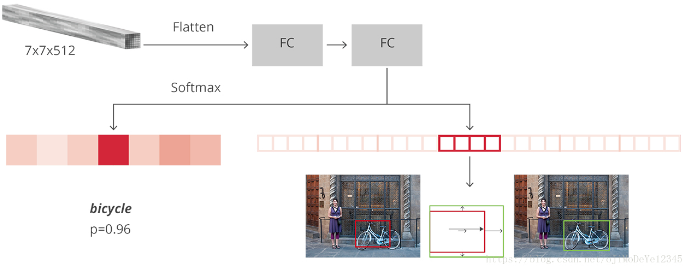
Figure 9. R-CNN 结构
6.1. 训练和目标
R-CNN 的目标基本上是与 RPN 目标的计算是一致的,但需要考虑不同的可能的 object 类别 classes.
根据 proposals 和 ground-truth boxes,计算其 IoU.
与任何一个 ground-truth box 的 IoU 大于 0.5 的 proposals 被设为正确的 boxes. IoU 在 0.1 到 0.5 之间时设为 background.
与 RPN 中目标组装相关,这里忽略没有任何交叉的 proposals. 这是因为,在此阶段,假设已经获得良好的 proposals,主要关注于解决难例. 当然,所有的这些超参数都是可以用于调整以更好的拟合 objects.
边界框回归的目标计算的是 proposal 与其对应的 ground-truth间的偏移量,只对基于 IoU 阈值设定类别class 后的 proposals 进行计算.
随机采用一个平衡化的 mini-batch=64,其中,25% 的 foreground proposals(具有类别class) 和 75% 的background proposals.
类似于 RPNs 的 losses,对于选定的 proposals,分类 loss 采用 multiclass entropy loss;对于 25% 的 foreground proposals 采用 SmoothL1 loss 计算其与 groundtruth box 的匹配.
由于 R-CNN 全连接网络对每个类别class 仅输出一个预测值,当计算边框回归loss 时需谨慎. 当计算 loss 时,只需考虑正确的类别.
6.2. 后处理
类似于 RPN,R-CNN 最终输出一堆带有类别 class 的objects,在返回结果前,再进一步进行处理.
为了调整边界框,需要考虑概率最大的类别的 proposals. 忽略概率最大值为 background class 的proposals.
当得到最终的 objects 时,并忽略被预测为 background 的结果,采用 class-based NMS. 主要是通过对 objects 根据类别class 分组,然后根据概率排序,并对每个独立的分组采用 NMS 处理,最后再放在一起.
最终得到的 objects 列表,仍可继续通过设定概率阈值的方式,来限制每个类的 objects 数量.
7. Faster R-CNN 训练
Faster R-CNN 在论文中是采用分步 multi-step 方法,对每个模块分别训练再合并训练的权重. 自此,End-to-end 的联合训练被发现能够得到更好的结果.
当将完整的模型合并后,得到 4 个不同的 losses,2 个用于 RPN,2 个用于 R-CNN. RPN 和 R-CNN 的base基础网络可以是可训练(fine-tune)的,也可以是不能训练的.
base基础网络的训练与否,取决于待学习的objects与可用的计算力. 如果新数据与 base基础网络训练的原始数据集相似,则不必进行训练,除非是想尝试其不同的表现. base基础网络的训练是比较时间与硬件消耗较高,需要适应梯度计算.
4 种不同的 losses 以加权和的形式组织. 可以根据需要对分类 loss 和回归 loss 设置权重,或者对 R-CNN 和 RPNs 设置不同权重.
采用 SGD 训练,momentum=0.9. 学习率初始值为 0.001,50K 次迭代后衰减为 0.0001. 这是一组常用参数设置
采用 Luminoth 训练时,直接采用默认值开始.
8. 评价 Evaluation
评价准则:指定 IoU 阈值对应的 Mean Average Precision (mAP),如 mAP@0.5.
mAP 来自信息检索,常用与计算 ranking 问题的误差计算,以及评估目标检测结果.
9. 总结
至此,对 Faster R-CNN 的处理方式有了清晰的理解,可以根据实际应用场合来做一些应用.
如果想进一步深入理解,可以参考 Luminoth Faster R-CNN 实现.
Faster R-CNN 可以用于解决复杂的计算机视觉问题,并取得很好的效果. 虽然这里模型是目标检测,但对于语义分割,3D目标检测等,都可以基于以上模型. 或借鉴于 RPN,或借鉴于 R-CNN,或两者都有. 因此,能够深度理解其工作原理,对于更好的解决其它问题很有帮助.
Related
[1] - 知乎 - Faster R-CNN
[2] - 知乎 - 原始图片中的ROI如何映射到到feature map?
[3] - 论文阅读学习 - Faster R-CNN
[4] - 论文阅读学习 - Fast R-CNN
[5] - Caffe源码 - RoI Pooling 层

 浙公网安备 33010602011771号
浙公网安备 33010602011771号