DeepLab深度学习网络-结构简介
参考博文:https://blog.csdn.net/weixin_41923961/article/details/82995656
斯坦福大学李飞飞组的研究者提出了 Auto-DeepLab,其在图像语义分割问题上超越了很多业内最佳模型,甚至可以在未经过预训练的情况下达到预训练模型的表现。Auto-DeepLab 开发出与分层架构搜索空间完全匹配的离散架构的连续松弛,显著提高架构搜索的效率,降低算力需求。深度神经网络已经在很多人工智能任务上取得了成功,包括图像识别、语音识别、机器翻译等。虽然更好的优化器 [36] 和归一化技术 [32, 79] 在其中起了重要作用,但很多进步要归功于神经网络架构的设计。在计算机视觉中,这适用于图像分类和密集图像预测。
Deeplab v1&v2
paper: deeplab v1https://arxiv.org/pdf/1412.7062v3.pdf && deeplab v2 https://arxiv.org/pdf/1412.7062v3.pdf
远古版本的deeplab系列,就像RCNN一样,其实了解了后面的v3和v3+就可以不太管这些了(个人拙见)。但是为了完整性和连贯性,所以读了这两篇paper。
Astrous conv
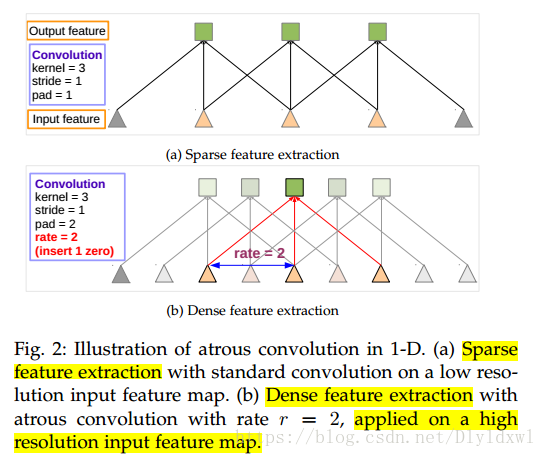
参考deeplab v2的插图。其实这个图经常可以看到,想说明什么呢?该图是一维卷积示意图。对于使用了s=2后的low resolution feature map再进行standard conv的效果和在原feature map上使用rate=2 的dilation conv是一模一样的。实际中使用s=2+standard conv和rate = 2的dilation conv仅仅是对应的感受野相同,并不是使用的像素点一样,这张图个人觉得有点障眼法的感觉。作者用了sparse/dense feature map的概念,其实就是low/high resolution feature map,直观上看起来分辨率低的当然稀疏啊。
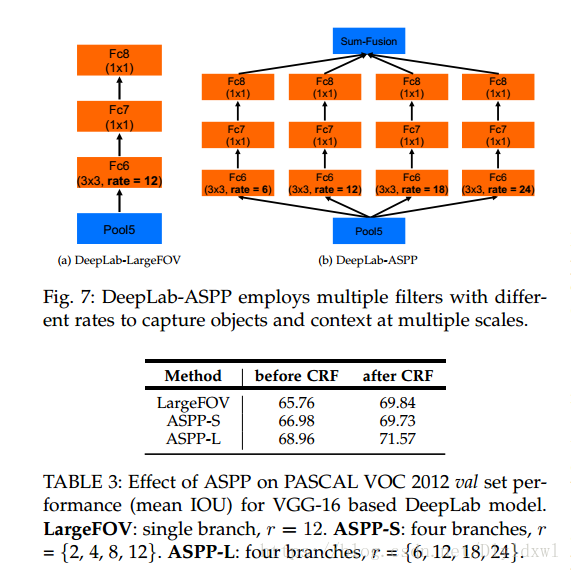
ASPP结构
图右的结构,作者对比了单独的rate(左边结构),有不小的提升。多尺度进行dilation conv,其实RFBnet(2017 CVPR )对SSD的改进就是参考这个思路,inception + aspp。Receptive Field Block Net for Accurate and Fast Object Detection
V2用Resnet 101作为backbone,有一定提升,v1和v2都用了CRF。关于CRF的不再赘述了,其实后面的版本都没有用这个了。训练用的poly策略。
Deeplab v3
paper: Rethinking Atrous Convolution for Semantic Image Segmentation https://arxiv.org/abs/1706.05587
implementation: github https://github.com/NanqingD/DeepLabV3-Tensorflow
v3的创新点一是改进了ASPP模块;二是参考了图森组的Understanding Convolution for Semantic Segmentation中HDC https://arxiv.org/abs/1702.08502的思想。其实就是对应纵横两种结构。backbone还是resnet 101.
论文中Fig2画了几种常见的捕获multi-scale context的方法。
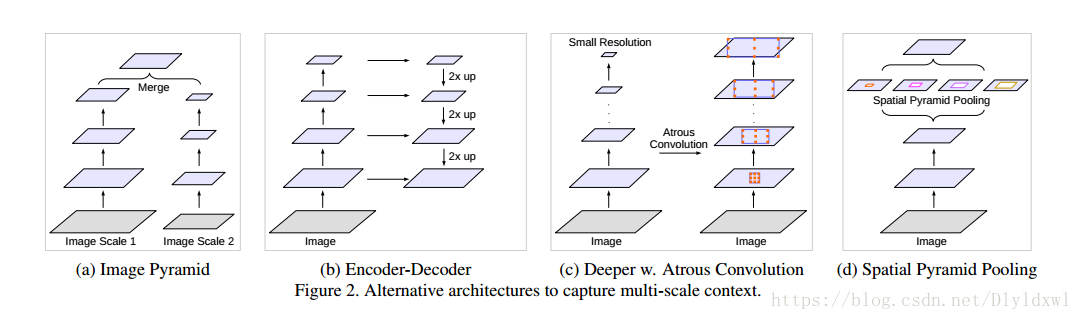
(a)图像金字塔。输入图像进行尺度变换得到不同分辨率input,然后将所有尺度的图像放入CNN中得到不同尺度的分割结果,最后将不同分辨率的分割结果融合得到原始分辨率的分割结果,类似的方法为DeepMedic;
(b)编码-解码。FCN和UNet等结构;
(c)本文提出的串联结构。
(d)本文提出的Deeplab v3结构。最后两个结构右边其实还需要8×/16×的upsample,在deeplab v3+中有所体现。当然论文的Sec 4.1也有提到,下采样GT容易在反向传播中丢失细节,因此上采样feature map效果更好。
ASPP的改进
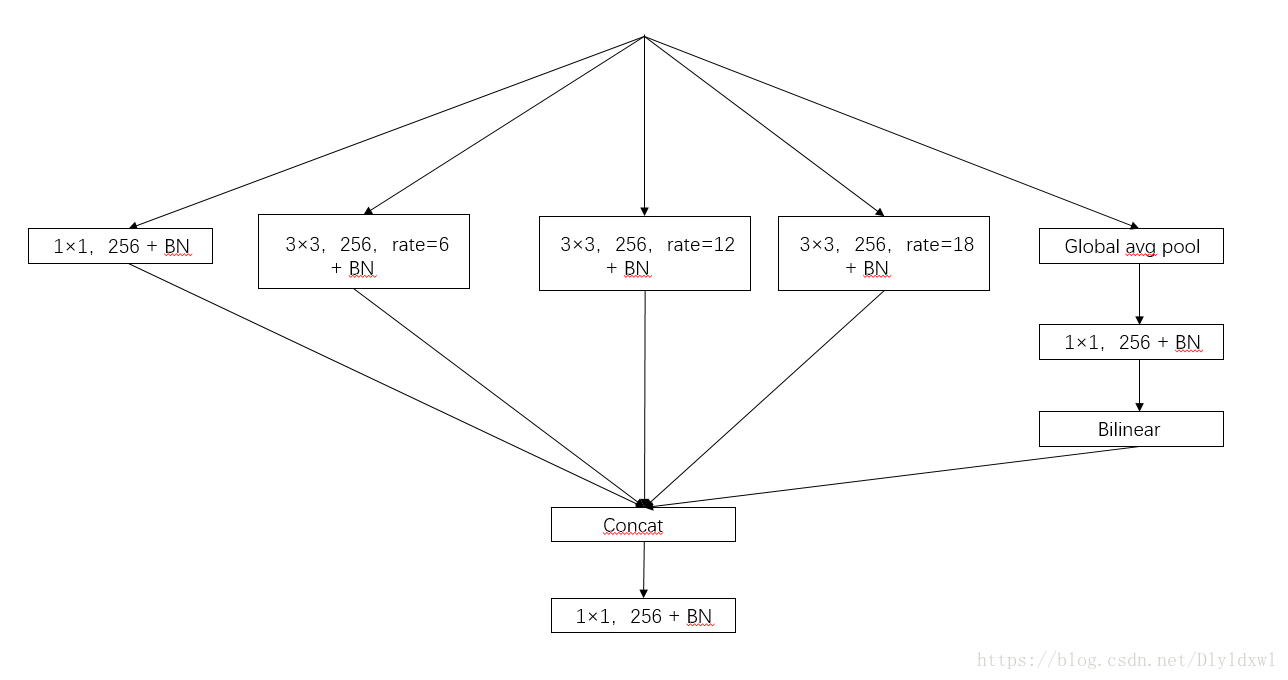
改进后的aspp长下图那个样子,多了个1*1的conv和global avg pool。关于1*1卷积,论文中3.3第一段解释的有点意思,当rate=feature map size时,dilation conv就变成了1*1 conv,所以这个1*1conv相当于rate很大的空洞卷积。此外引入了全局池化这个branch,这个思想是来源于PSPnet(参考博客),简言之就是spp在分割上的应用,多尺度pooling。根据代码实现来看,每个branch后面都没有relu,其实有没有BN,个人觉得不是很要紧,毕竟BN是线性操作,可以合并到conv里面,论文的Sec 4.1 说明了V3的所有层是用了BN的,BN可以加速训练还有弱正则,所以一般都会用。针对ASPP,作者设计了一种“纵式”的结构,如下图fig5。


"串联"结构
如下图所示,复制conv4的结构3次,后面的每个block都有一个基准dilation Rate,在每一个block里面参考HDC的思想,又设置了[1,2,1]的rate,所以每个conv的rate = Rate*rate.在论文4.2的Multi-grid部分详细进行了解释对比。

两种方法的结构合并并不会带来提升,相比较来说,aspp的纵式结构要好一点。所以deeplab v3一般也是指aspp的结构。
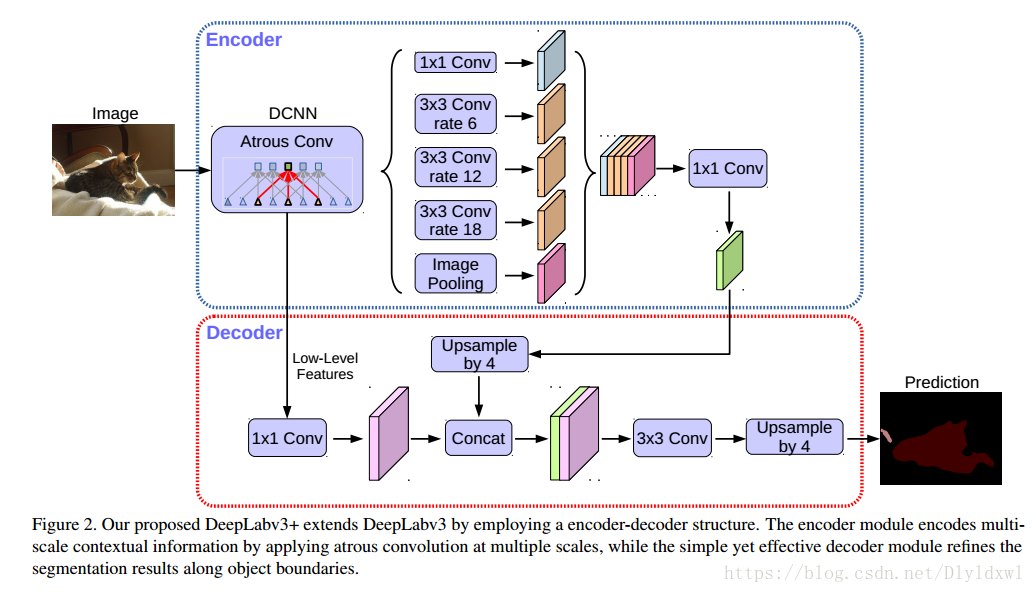
Deeplab v3+
paper:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation http://cn.arxiv.org/abs/1802.02611
Implementation:github https://github.com/jfzhang95/pytorch-deeplab-xception
在deeplab v3中说到了需要8×/16×的upsample 最终的feature map,很明显这是一个很粗糙的做法。v3+的创新点一是设计基于v3的decode module,二是用modify xception作为backbone。
论文中同样给出了一幅对比图,(a)是v3的纵式结构,(b)是常见的编码—解码结构,(c)是本文提出的基于deeplab v3的encode-decode结构。
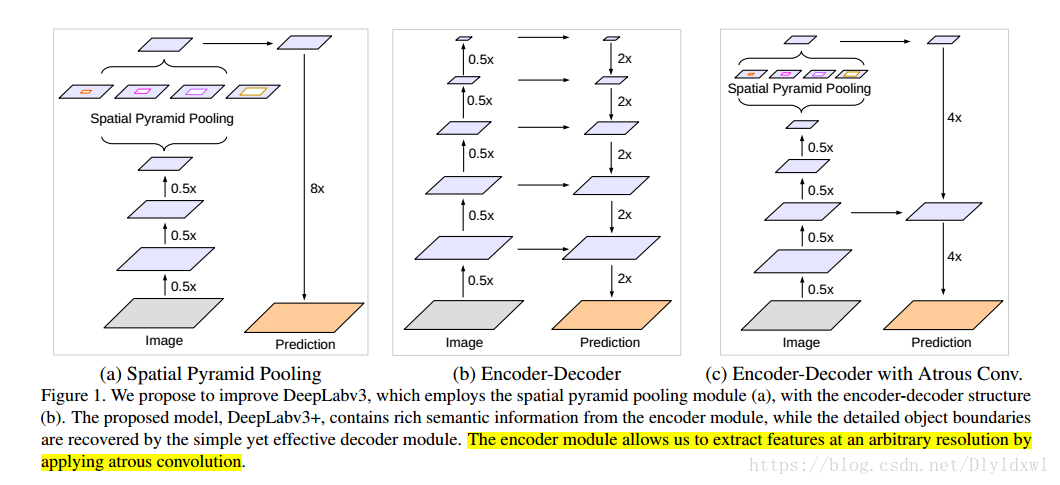
论文中介绍了两种backbone,一是Resnet101,二是改进后的xception。xception效果好于resnet,所以我只关注了xception,毕竟v3+主打也是xception backbone。下面从backbone和decode来简要概括v3+的结构。
Modify Xception
具体结构参照下图。和原来的xception不一样的地方有三,一是Middle flow重复了16次,ori xception是8次,也就是用了more layers;二是pooling均换为了dw+pw+s=2,本人在很多网络也实验过,把pool换成conv或者合并到现有的卷积层,均能提高一定的map。在Entry flow中stride =16,所以训练的时候需要把Exit flow的stride=2换为rate=2的dilation conv(Middle不改变resolution)(train_os=16),因此后面的层也都是rate=2,这又导致The Gridding Effect,然而论文4.3中说明了这个地方用HDC思想并不会带来提升,因此保留了一系列的rate=2;三是在所有的dw层后面加上了BN和relu,加BN无可厚非,线性操作而已,但是重新加relu是真的玄学啊。

Decoded module
xception的输出2048维特征接到ASPP上得到256维multi-scale context feature map(一般s=16),再4×上采样,和backbone上的同分辨率的low-level feature map concat(一般是entry flow的第一个shortcut block的输出,刚好s=4)。这个时候要让low-level feature map在concat后的总特征图中占比小,因为它的语义信息太少了,所以接了1*1的低维conv,这个地方可不是为了降低计算量,关于这个conv的channel选取,论文给出了对比试验Table 1。concat后再接3*3 conv block,它的channel和block个数,论文中也进行了实验验证Table 2.最后再进行4×上采样,达到原图的分辨率。此外,作者还实验了将aspp和decode中的卷积替换为depthwise conv,mIOU没有明显降低,flops大大降低了。
简绘deeplab v3和v3+的ASPP模块结构,如下图所示:参照我贴的重实现的代码来看,ASPP每个部分后面均有relu。
官方给出一个PPT,内容关于deeplab v1,2.3区别,
链接: https://download.csdn.net/download/dlyldxwl/10557350

 浙公网安备 33010602011771号
浙公网安备 33010602011771号