DeepSpeech深度学习网络-结构简介
参考博文:https://blog.csdn.net/Left_Think/article/details/75577512 和 https://zhuanlan.zhihu.com/p/38516611 和 https://blog.csdn.net/xmdxcsj/article/details/70300591
对于传统的语音识别,通常会分为3个部分:语音模型,词典,语言模型。语音模型和语言模型都是分开进行训练的,因此这两个模型优化的损失函数不是相同的。而整个语音识别训练的目标(WER:word error rate)与这两个模型的损失函数不是一致的。
对于端到端的语音识别,模型的输入就为语音特征(输入端),而输出为识别出的文本(输出端),整个模型就只有一个神经网络的模型,而模型的损失采用的CTC Loss。这样模型就只用以一个损失函数作为训练的优化目标,不用再去优化一些无用的目标。
另外语音处理中有几个难点:输入的语音与目标文本之间的对齐(alignment);语音的切片,如何切,多长的窗口切一刀,是很难定义的;输出结果需要处理后才能映射到目标label上;CTC完美地解决了这几个问题。deepspeech = RNN layers + CTC loss 的模型结构,来学习音频到文本的映射的,从而实现端到端的语音识别。deepspeech是处理speech-to-text的基于深度学习框架的引擎,详见百度的paper: https://arxiv.org/pdf/1412.5567.pdf .
Deep Speech1网络结构
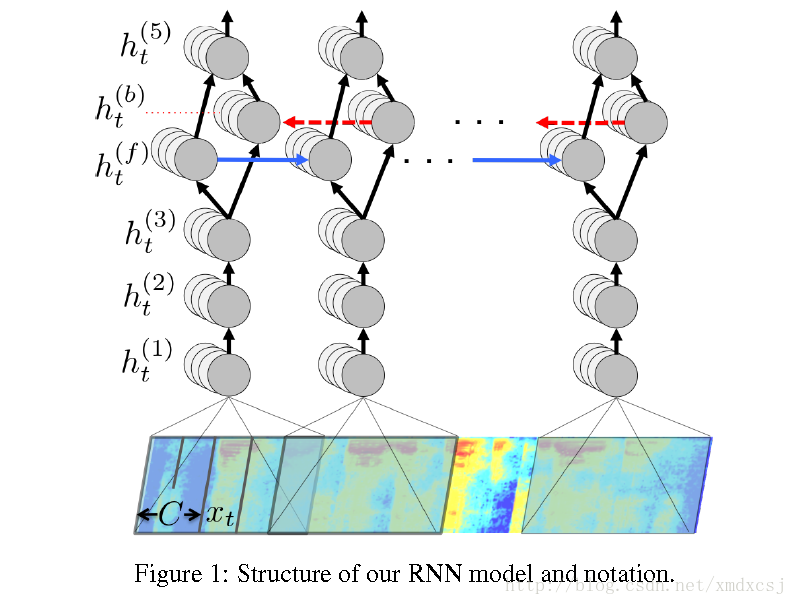
网络输入是context特征,输出是char,训练准则是CTC,解码需要结合ngram语言模型。 共五层,前三层是简单的DNN结构,第四层是双向RNN,第五层的输入是RNN的前向和后向单元,后面跟着softmax分类。
-
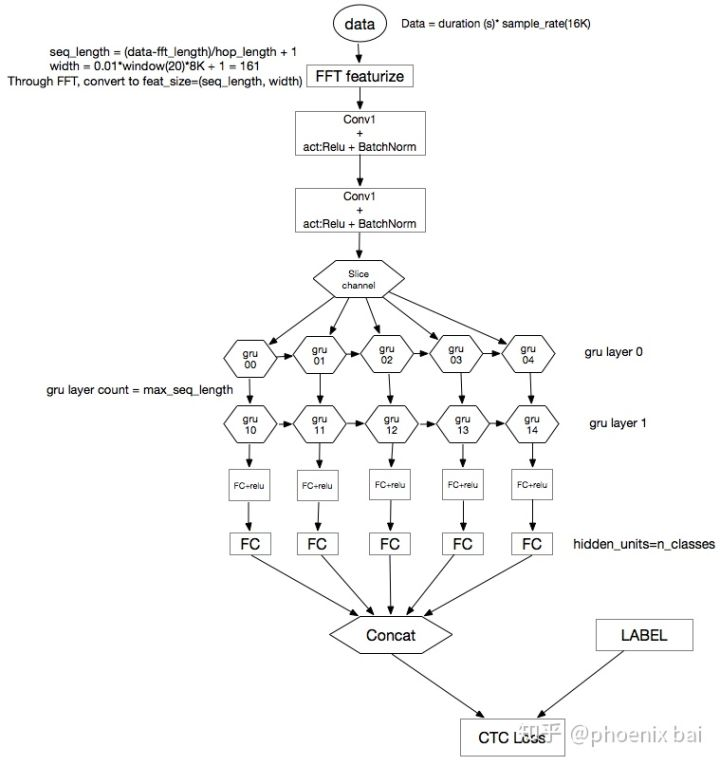
data是由音频文件组成,这里假设格式是wav,采样频率是16k,时长是t seconds. 那么,读进来的一个音频文件,等于 t (sec) * 16K 的float类型的数组。
-
接着做快速傅立叶变换(FFT),seq_length和width公式定义,生成维度为(seq_length, width)的数组
-
再此基础上,做两层的卷积(激励函数用relu,再加batchnorm很重要), 对于音频来讲,是在时域和频域组成的二维空间上的卷积。怎么理解,我再想想。。。
-
卷积后的数据shape(seq_len_after_conv, width_after_conv)计算公式:
-
seq_len_after_conv = (seq_length-filter)/step_size+1
-
sclice_channel 是将 seq_len_after_conv, 以1为单位,切成多片,即seq_len_after_conv=10,则切成10片,你可以认为是10个x input,作为下面的rnn层的输入,你可以理解为是要输入RNN层的input sequence。
-
RNN层中 ,我们使用的是GRU,seq_len_after_conv的值为多少,则有多少个GRU unit。其中,GRU中的hidden_units数,用户定义
-
GRU后面的FC中的hidden_units,用户自己定义。
-
之后的FC层的hidden_units,是由字母表(alphabet)的数量来决定的。这就是我们要做的分类的类别表。e.g. 若输入是英文,则alphabet={a-z, blank},若输入是中文,则alphabet的定义可以多种多样,完全取决于你的目标,如,可以是音素集合,也可以是带有声调的字母集 {a, ā, á, ǎ, à ......}, 这样学的label sequence就是带声调的拼音序列了。这个可以简单理解为是通过这么多步聚的神经网络层学到的,input_sequence的特征列表,维数为(seq_len_after_conv, alphabet_size),即输入序列的每一时刻值,都由alphabet_size长度的向量来表示,做个softmax后,可认为是当前时刻的值为alphabet集合中的任一字母的概率分别是多少。
-
concat后,为与label sequence算Loss的打磨版的(input)sequence了。
-
接着算CTS LOSS。CTS LOSS是可导的,所以可以用任一种梯度优化算法:SGD, ADAM, NAG etc.
LSTM & GRU
- LSTM主要组成部分:forget gate, input_gate, output_gate, cell_state, hidden_unit
- GRU就是LSTM的variants而己,更易于理解,且计算效率更高,效果与LSTM相等,所以越来越受青睐中. GRU主要组成部分:reset_gate, update_gate, hidden_unit,就这么简单
- 需要理论基础的,网上太多,额外我也讲不明白,所以靠感兴趣的筒子们自学了
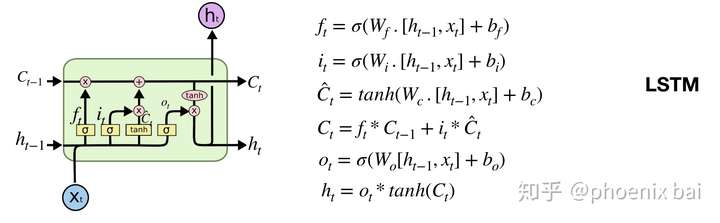
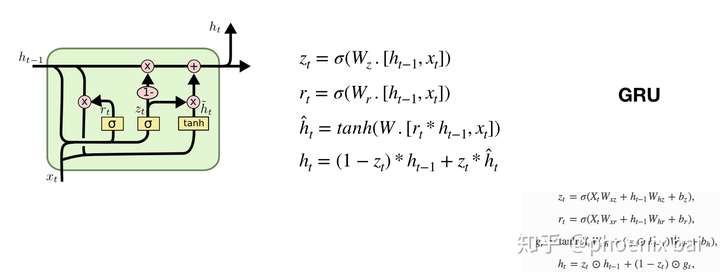
GRU右下角的公式是实现代码,中间的公式更抽象一些。
Deep Speech2网络结构
相比于Deep Speech,使用HPC技术,将训练时间由几周缩短到几天,尝试了更为复杂的网络结构。
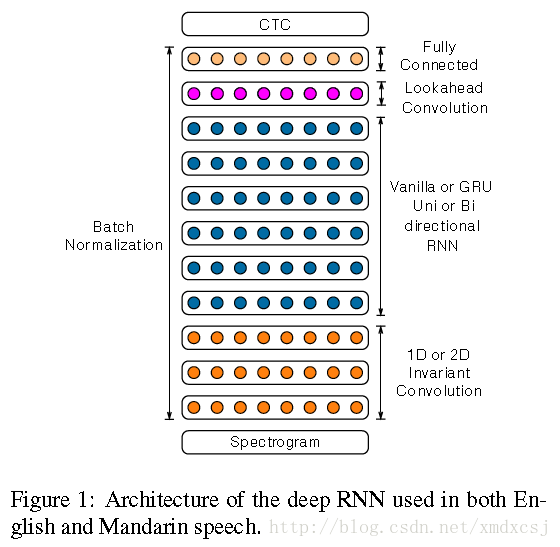
网络输入是context特征,输出是char(英文对应a/b/c,中文对应6000汉字),训练准则是CTC,解码需要结合ngram语言模型。
Batch Normalization
在网络层数更深的时候,效果更明显,收敛更快而且误差更小。
SortaGrad
CTC训练的早期不稳定,长句子容易出现梯度异常(有些概率near-zero)。在第一个epoch,将训练句子按照长度排序,首先使用断句训练,后面的epoch再按照随机顺序。
GRU
GRU相比于vanilla RNN可以取得更好的结果,同时比LSTM更容易训练。
Convolution
在网络的最底层使用3层的CNN结构。
Lookahead Convolution
使用双向RNN可以获得更好的准确性,但是对on-line服务来讲,延时问题比较明显,为了解决这个问题,在RNN上面增加了一层Lookahead Convolution。

adaptation
传统的Hybrid系统在语言之间迁移相对困难,end-to-end系统相对简单,只需要更换最后的输出节点就可以。
CTC结构介绍
背景
Connectionist temporal classification简称CTC,翻译不太清楚,可以理解为基于神经网络的时序类分类。其中classification比较好理解,表示分类问题;temporal可以理解为时序类问题,比如语音识别的一帧数据,很难给出一个label,但是几十帧数据就容易判断出对应的发音label,这个词也给出CTC最核心的意义;connectionist可以理解为神经网络中的连接。
语音识别声学模型的训练属于监督学习,需要知道每一帧对应的label才能进行有效的训练,在训练的数据准备阶段必须要对语音进行强制对齐。
CTC的引入可以放宽了这种一一对应的限制要求,只需要一个输入序列和一个输出序列即可以训练。有两点好处:不需要对数据对齐和一一标注;CTC直接输出序列预测的概率,不需要外部的后处理。
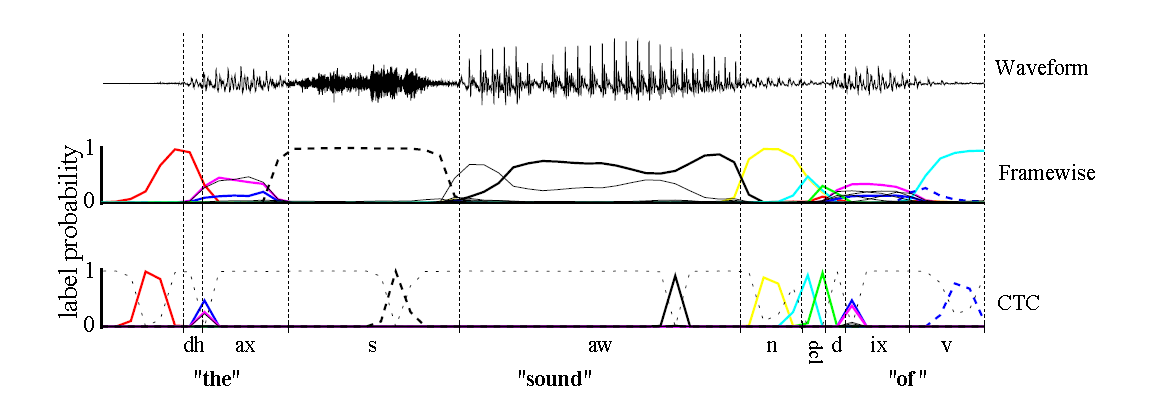
如上图,传统的Framewise训练需要进行语音和音素发音的对齐,比如“s”对应的一整段语音的标注都是s;而CTC引入了blank(该帧没有预测值),“s”对应的一整段语音中只有一个spike(尖峰)被认为是s,其他的认为是blank。对于一段语音,CTC最后的输出是spike的序列,不关心每一个音素对应的时间长度。
输出
语音识别中的DNN训练,每一帧都有相应的状态标记,比如有5帧输入x1,x2,x3,x4,x5,对应的标注分别是状态a1,a1,a1,a2,a2。
CTC的不同之处在于输出状态引入了一个blank,输出和label满足如下的等价关系:F(a−ab−)=F(−aa−−abb)=aab. 多个输出序列可以映射到一个输出。
CTC训练
训练流程和传统的神经网络类似,构建loss function,然后根据BP算法进行训练,不同之处在于传统的神经网络的训练准则是针对每帧数据,即每帧数据的训练误差最小,而CTC的训练准则是基于序列(比如语音识别的一整句话)的,比如最大化p(z|x)p(z|x),序列化的概率求解比较复杂,因为一个输出序列可以对应很多的路径,所有引入前后向算法来简化计算。
前期训练准备:
- 输入
xx,长度为T
- 输出集合
AA表示正常的输出
A′=A⋃{blank}A′=A⋃{blank}表示输出全集
A′TA′T表示输入x对应的输出元素集合
- 输出序列
ππ表示输出路径
ll表示输出label序列
FF表示路径到label序列的映射关系
- 概率
ytkykt表示时间t输出k的概率
p(π|x)=∏t=1Tytπtp(π|x)=∏t=1Tyπtt表示基于输入x的输出ππ路径的概率
p(l|x)=∑π∈F−1(l)p(π|x)p(l|x)=∑π∈F−1(l)p(π|x)表示输出label序列的概率是多条路径的概率和。
前后向算法
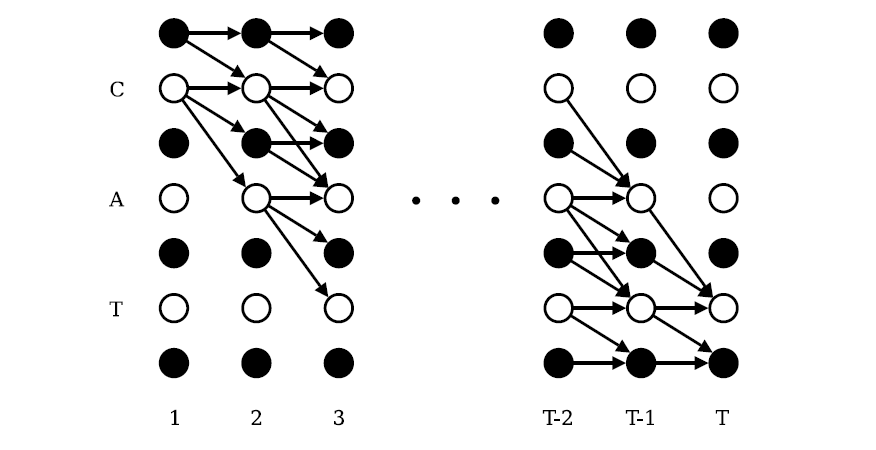
考虑到计算p(l|x)p(l|x)需要计算很多条路径的概率,随着输入长度呈指数化增加,可以引入类似于HMM的前后向算法来计算该概率值。为了引入blank节点,在label首尾以及中间插入blank节点,如果label序列原来的长度为U,那么现在变为U’=2U+1。
CTC 解码
解码是对于输入序列x找出概率最大的输出序列l,而不是概率最大的一条输出路径,因为输出路径和输出序列是多对一关系。
l∗=argmax{p(l|x)}
best path decoding
最优路径找出每一帧输出的最大概率组成的输出序列即为最后的解码结果,这种方式会引入问题。
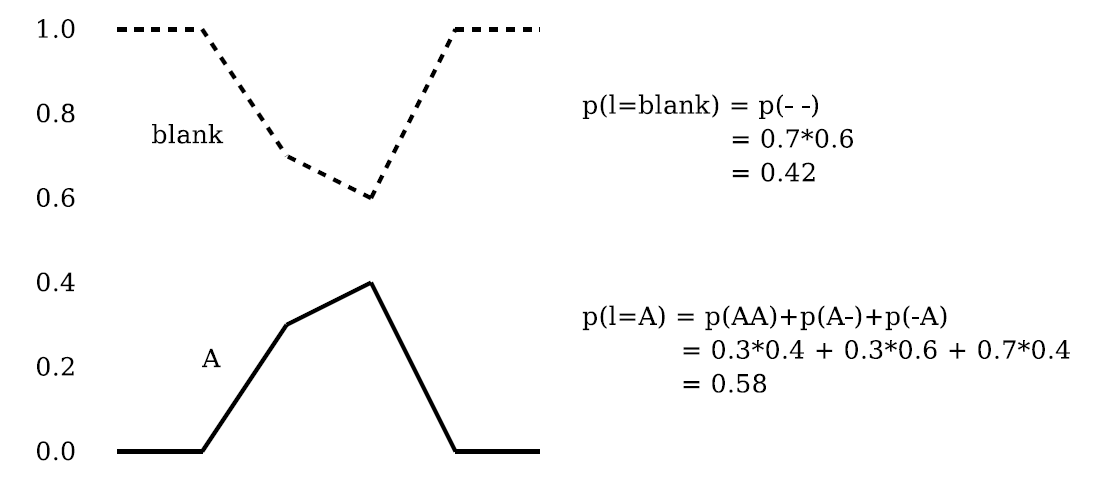
对于上图,这种方法解码出来的结果是blank,但是A的概率反而更高。
constrained decoding
对于语音识别,可以引入语言模型等grammar限制,求解问题变为如下形式:
l∗=argmax{p(l|x)}{p(l|G)} ;其中G表示grammar;可以使用传统的token传播算法进行解码。
假设词典D包含2个单词w,分别是{北,京},每个单词对应两个因素,所以|w′|=5|w′|=5
北 b ei
京 j ing

t=1的时候,每个w的前两个tok被激活
当t=2的时候,每个w的tok只能在单词内传播,对于“北”来说,tok(北,3,2)和tok(北,4,2)将会被激活,同时tok(北,2,2)有两条路径可以达到,这里取两条路径的最大概率,加上b音素在t=2时刻对应的概率的对数值,作为tok(北,2,2)的得分。与此同时,b->ei这条路径完成了“北”这个单词对应的输出,所以此时“北”将会有对应的输出tok(北,-1,2)。
当t=3的时候,对于“京”这个单词,除了正常的单词内tok传播,还将涉及到单词和单词之间的tok传播,找到所有单词w的输出tok得分和p(京|w)之和的最大值,作为tok(京,0,3),并且将该w对应的单词放到tok(京,0,3)的history。tok(京,0,3)将可以向tok(京,1,4)传播。
以此类推…….
整体上来看,解码过程类似于hmm的维特比,找出最大概率对应的路径,不同之处在于ctc解码引入了blank节点用于得到最终的输出序列,而不关心每一帧的输出结果。
通过设定beam,可以对每个时刻t对应的word输出tok进行剪枝,加快解码速度。
CTC-WFST解码
类似于HCLG的wfst结构,EESEN: END-TO-END SPEECH RECOGNITION USING DEEP RNN MODELS AND WFST-BASED DECODING文章提出了TLG的网络结构
Grammar
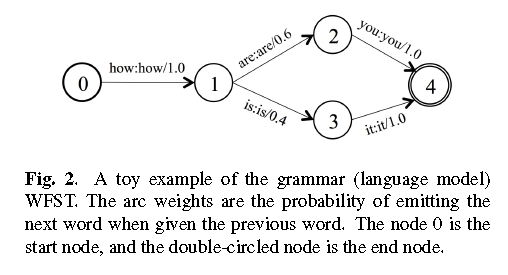
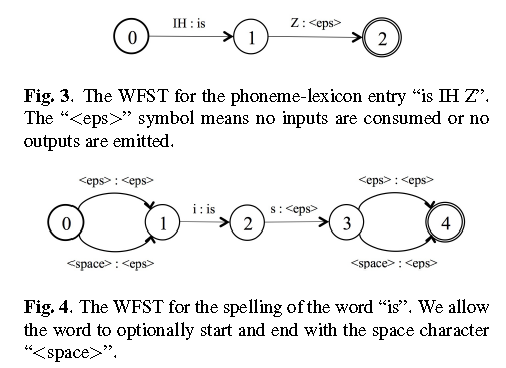
Lexicon
有两种形式,可以基于characters和phonemes。
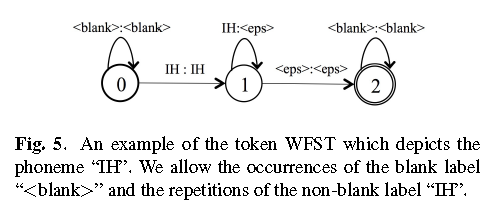
Token
对应于传统的state,前后添加blank,而且状态存在自旋
网络表达式
S=T∘min(det(L∘G))
相比于传统的hybrid方法,准确率差不多,解码速度有三倍以上的提升。原因在于,状态数从几千个降到了几十个,减小了网络复杂度。
CTC-源码训练
essen源码参考https://github.com/yajiemiao/eesen,这里简单说一下涉及到训练前后向的核心算法源码实现。以单句训练为准(多句并行类似),用到的变量
变量 含义
phones_num 最后一层输出节点个数,对应于|phones|+1
labels_num 一句话对应的标注扩展blank以后的个数,比如”123”扩展为”b1b2b3b”
frames_num 一句话对应的总的帧数,对应于时间t
ytkykt 最后一层输出
atkakt softmax层的输入
CTC error
ctc.Eval(net_out, targets, &obj_diff);
涉及到的变量的维度:
变量 维度
net_out frames_num*phones_num
alpha/beta frames_num*labes_num
ctc_error frames_num*phones_num
本来可以使用最终的公式求出对atkakt的error,代码中却分成了两部求解,可能逻辑上能体现出error反向传播的过程,但是实际感觉没有必要

 浙公网安备 33010602011771号
浙公网安备 33010602011771号