KWS语音识别技术-简介
博文参考:https://blog.csdn.net/mao_hui_fei/article/details/85129137 和 https://www.cnblogs.com/talkaudiodev/p/10635656.html 和 https://blog.csdn.net/weixin_30876945/article/details/97322378 和 https://blog.csdn.net/baienguon/article/details/80539296
1,语音认别技术发展过程
语音识别技术是指机器自动将人的语音的内容转成文字,又称 Automatic Speech Recognition,即ASR技术。语音识别是一门交叉的、非常复杂的学科,需要具备生理学、声学、信号处理、计算机科学、模式识别、语言学、心理学等相关学科的知识。
语音识别的研究是个漫长而且艰难的过程,它的发展可以追溯到20世纪50年代,1952年贝尔实验室首次实现Audrey英文数字识别系统,这个系统当时可以识别单个数字0~9的发音,并且对熟人的准确度高达90%以上。在同时期,MIT、普林斯顿相继推出少量词的独立词识别系统。

1971年美国国防部研究所(DARPA)赞助了五年期限的语音理解研究项目,推动了语音识别的一次大发展。DARPA在整个科技的发展过程中扮演了非常重要的角色,它专门给高科技研究项目提供资金支持,包括无人机、卫星等等。在DARPA的支持下,IBM、卡内基梅隆大学(CMU)、斯坦福等学术界和工业界非常顶级的研究机构也都加入到语音识别的研究中去。其中,卡耐基梅隆大学研发出harpy语音识别系统,该系统能够识别1011个单词,在这个时期大词汇量的孤立词识别取得实质性进展。

到了1980年,语音识别技术已经从从孤立词识别发展到连续词识别,当时出现了两项非常重要的技术:隐马尔科夫模型( HMM )、N-gram语言模型。1990年,大词汇量连续词识别持续进步,提出了区分性的模型训练方法MCE和MMI,使得语音识别的精确度日益提高,尤其适用于长句子的情况下,与此同时,还提出了模型自适应方法MAP和MLLR。在工业方面,剑桥推出首个开源的语音识别训练工具HTK,在商业方面,Nuance发布了首个消费级产品Dragon Dictate。
到了21世纪,随着深度学习的不断发展,神经网络之父Hinton提出深度置信网络( DBN ),2009年, Hinton和学生Mohamed将深度神经网络应用于语音识别,在小词汇量连续语音识别任务TIMIT上获得成功。
2,传统语音认别方法介绍
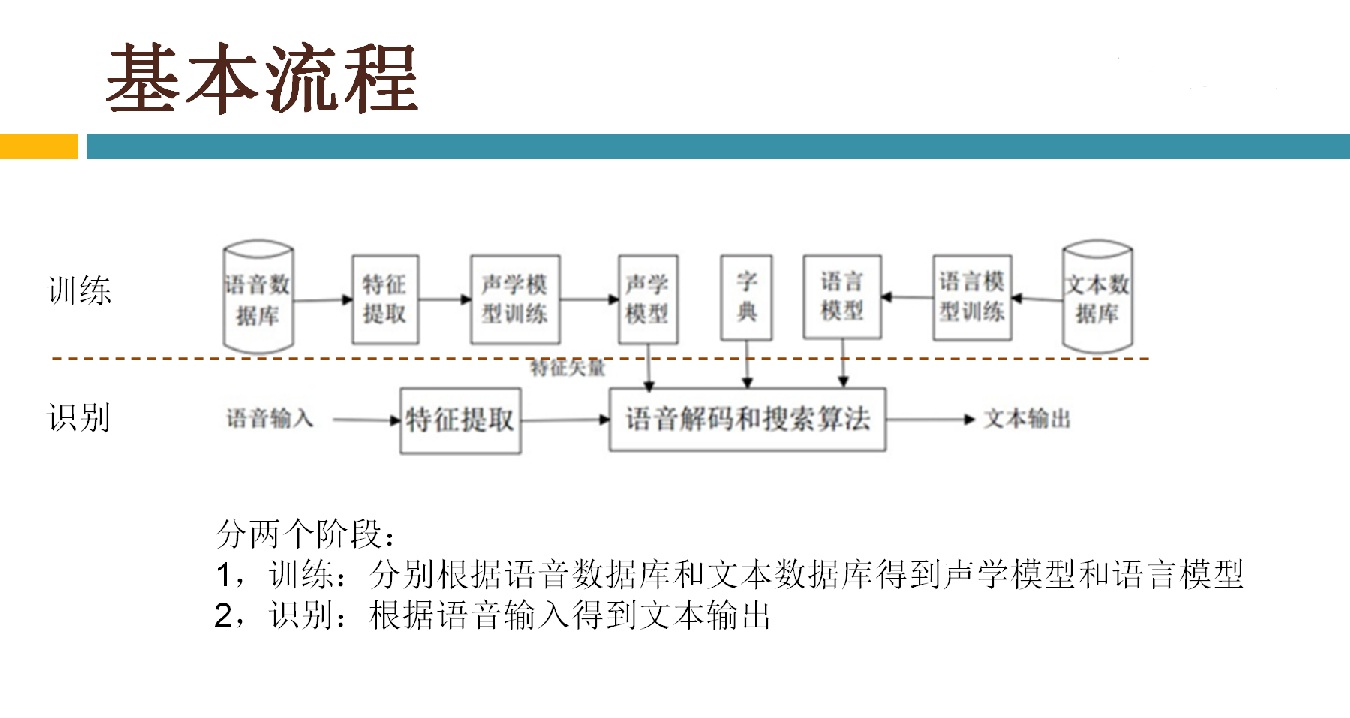
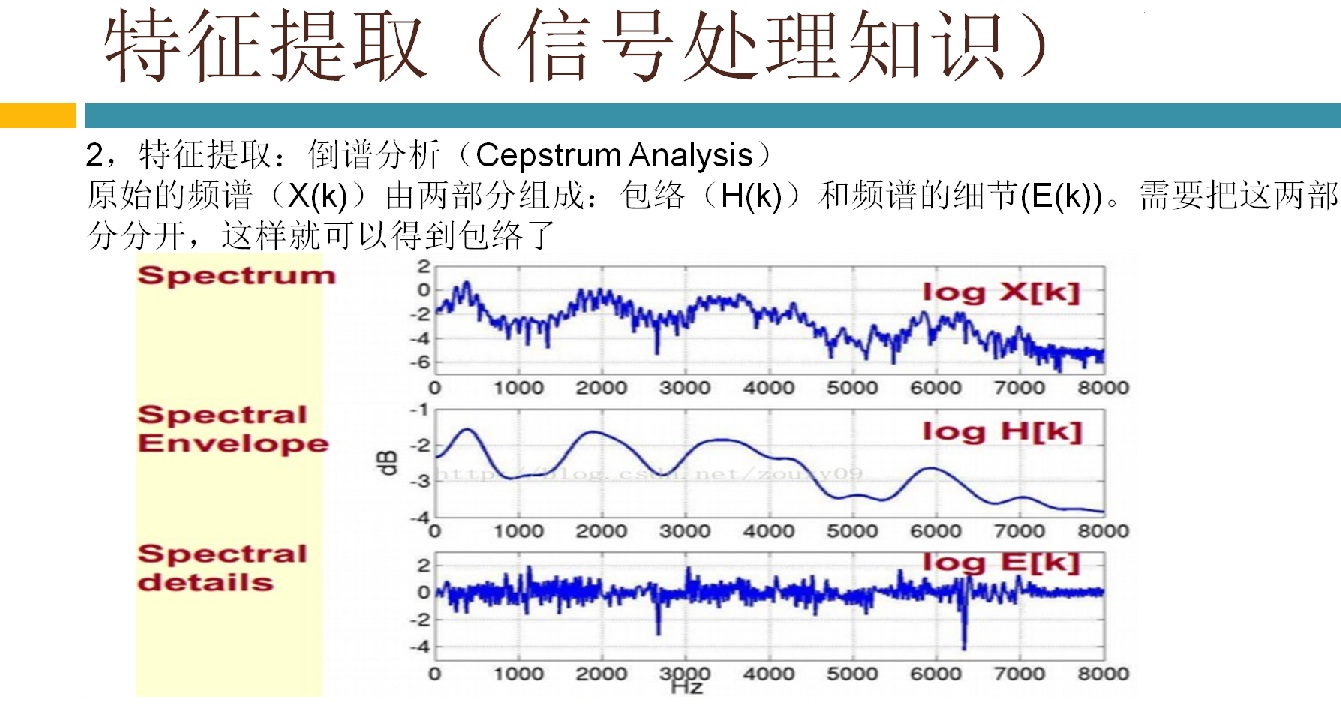
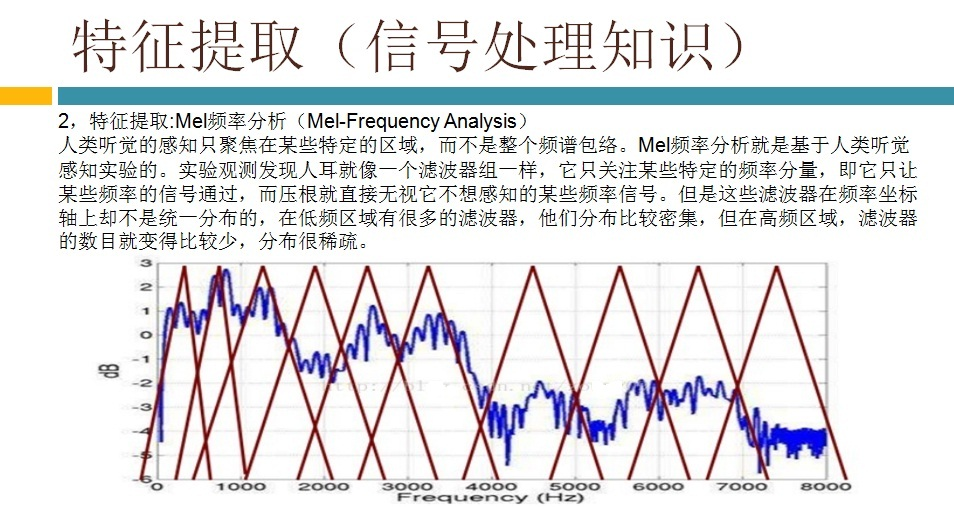
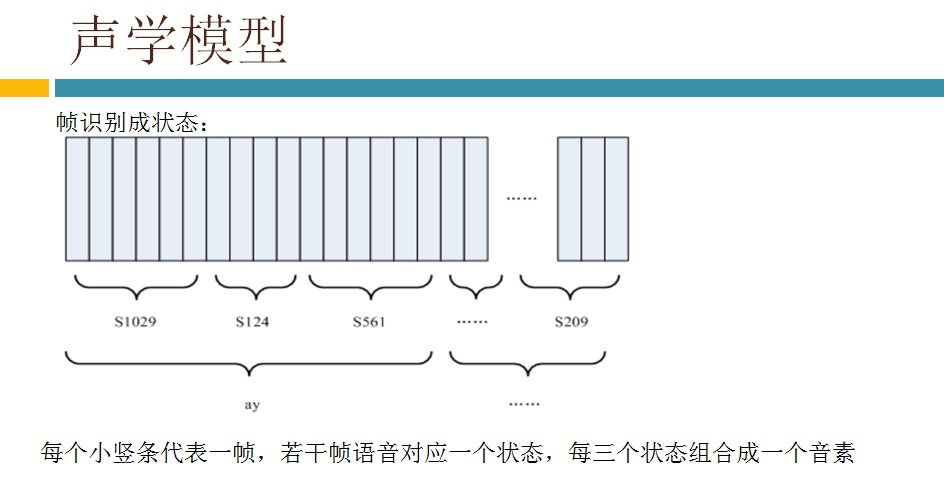
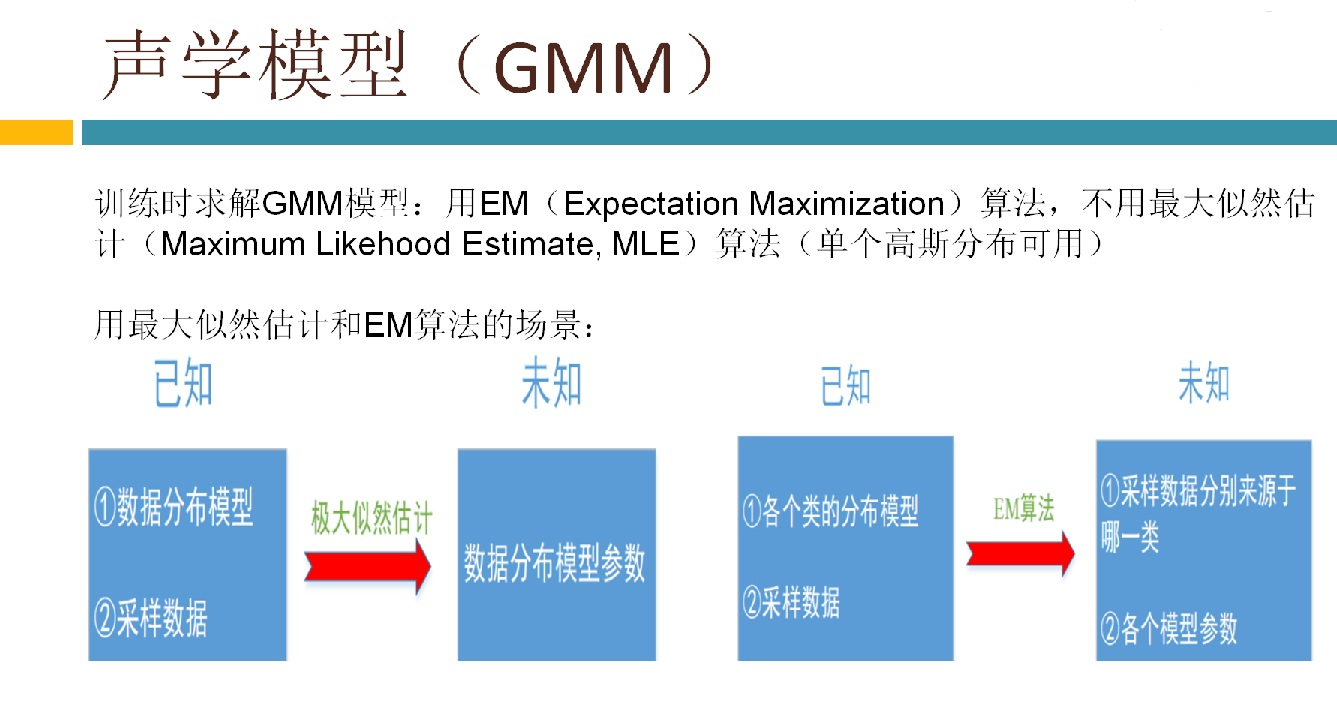
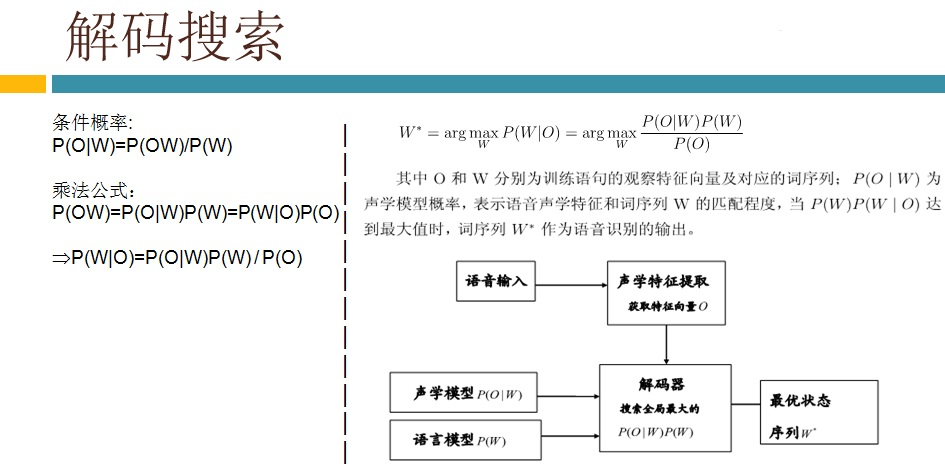
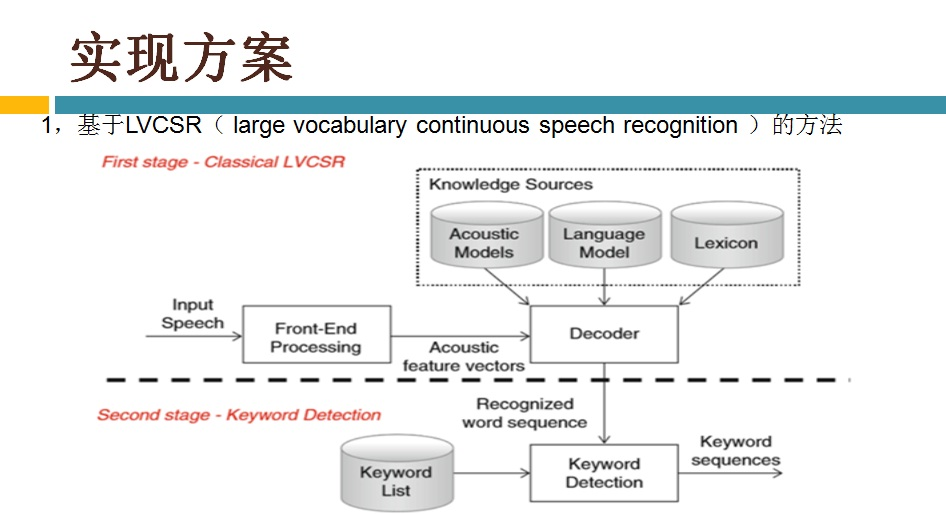
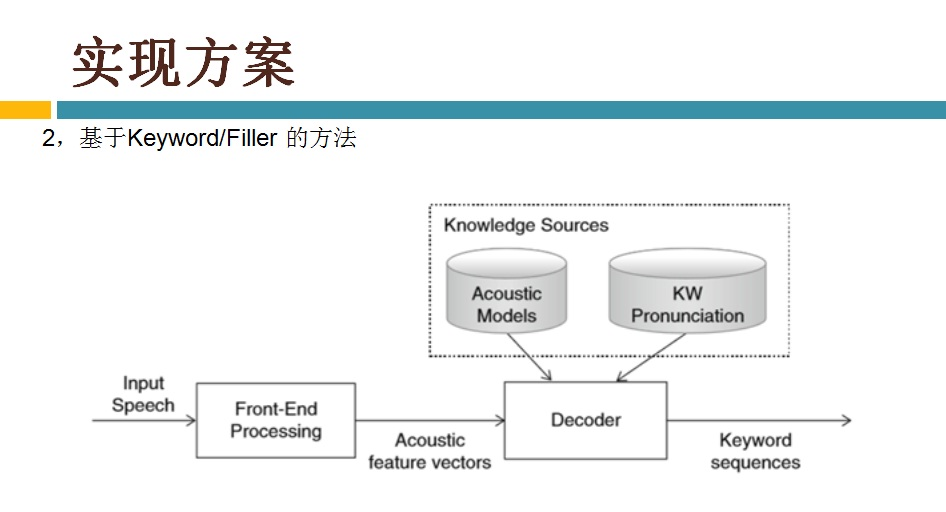
语音识别传统方法主要分两个阶段:训练和识别,训练阶段主要是生成声学模型和语言模型给识别阶段用。传统方法主要有五大模块组成,分别是特征提取(得到每帧的特征向量),声学模型(用GMM从帧的特征向量得到状态,再用HMM从状态得到音素)、发音字典(从音素得到单词)、语言模型(从单词得到句子)、搜索解码(根据声学模型、发音字典和语言模型得到最佳文本输出),即从帧得到特征向量(VAD(voice activity detect)降噪和分帧,特征提取干的话),从特征向量得到状态(GMM干的话),从状态得到音素(HMM干的话),从音素得到单词(发音字典干的活),从单词得到句子(语言模型干的活)。传统方法除了在特征提取上用到信号处理知识,其余全都是概率统计等知识。








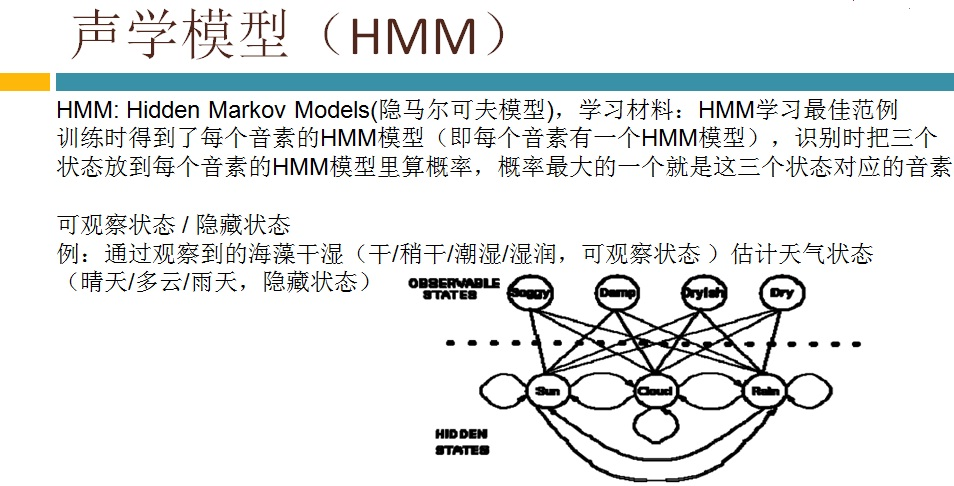


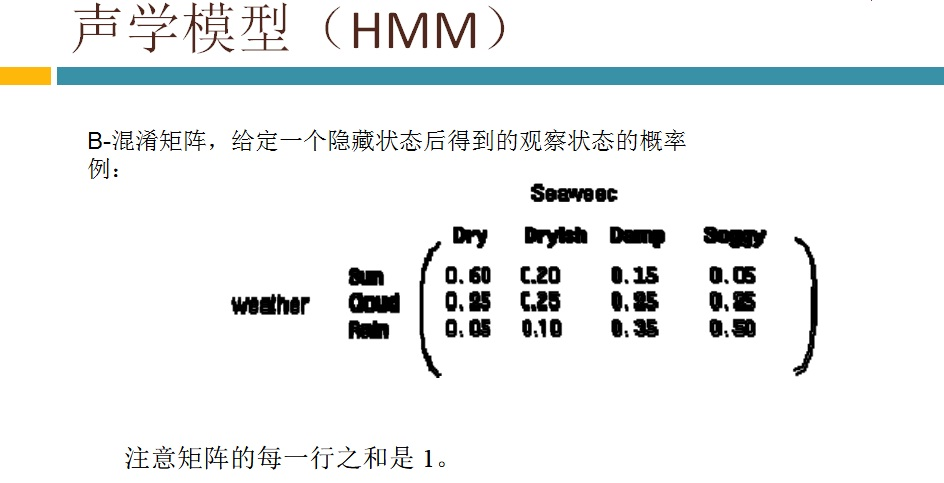

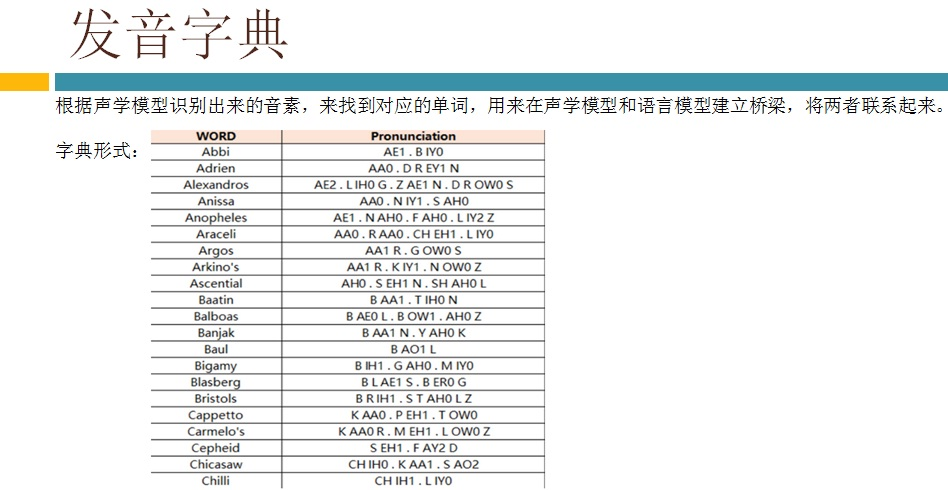



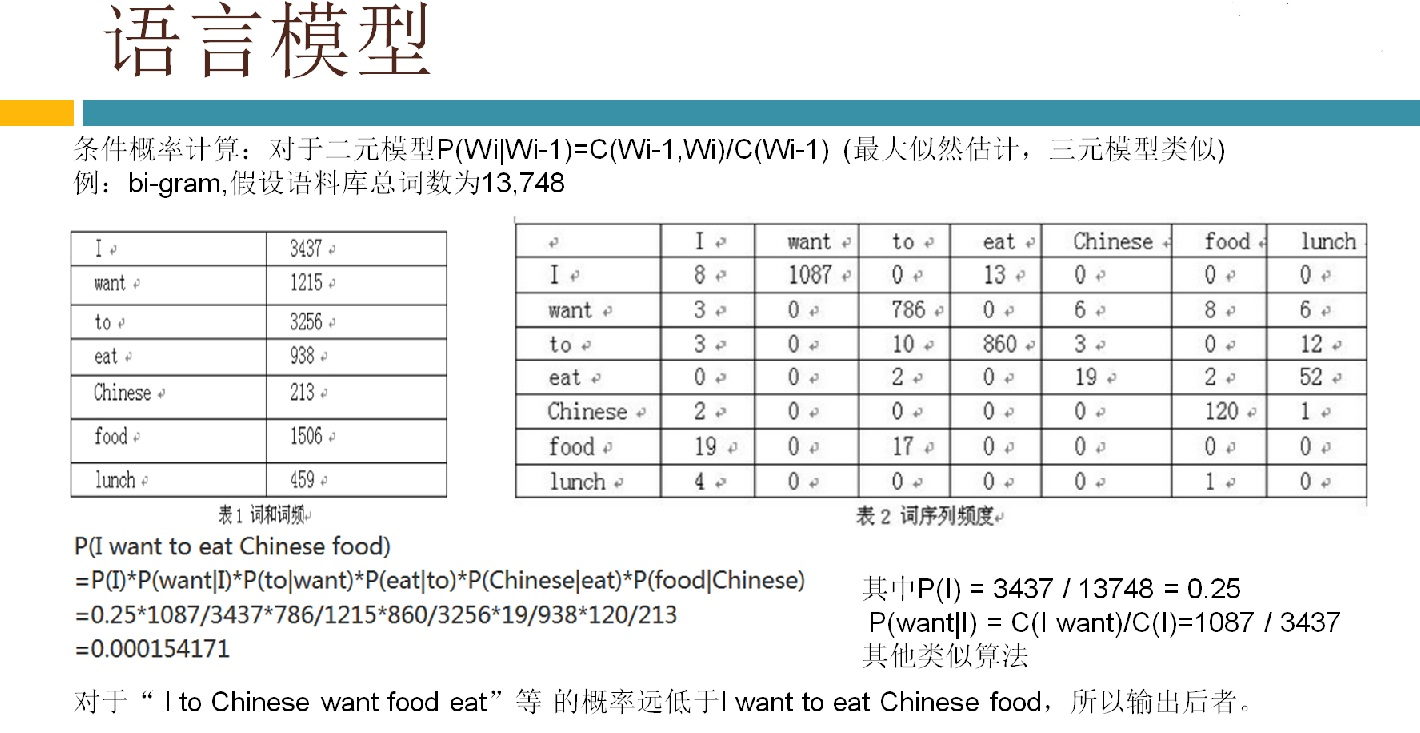
3,语音认别---VAD语音活动性处理介绍
完整的amr编码器还包括语音激活检测(VAD)和丢帧、错帧的消除。VAD的作用是检测当前输入信号中是否有语音,它的输入是输入信号本身和AMR编码器计算出来的参数集,VAD用这个信息来决定每20ms语音帧中是否包括语音。在VAD没有检测到语音的情况下,AMR采用8种速率之外的低速率噪声编码模式,以节省移动台的功率,降低整个网络的干扰和负载。此外,当语音帧由于传输错误而丢失时,为了使接听者感觉不到丢帧,应完成丢帧和错帧的消除,并用预测的参数集进行语音合成。
在语音增强中,我们希望从带噪语音信号中剔除噪音,得到纯净的语音信号,第一步就是提取噪音信息。通常的思路是通过VAD函数得到非语音片段,而非语音片段可以认为是纯噪音片段。从而可以从纯噪音信号中提取出有用信息,例如进行傅里叶变换得到噪音频谱等,再进而做下一步处理。例如谱减法,维纳滤波。此处不作讨论。
VAD有很多种方法,此处介绍一种最简单直接的办法。 通过short timeenergy (STE)和zero cross counter (ZCC) 来测定。(实际上精确度高的VAD会提取4种或更多的特征进行判断,这里只介绍两种特征的基本方法)。
l STE: 短时能量,即一帧语音信号的能量
l ZCC: 过零率,即一帧语音时域信号穿过0(时间轴)的次数。
理论基础是在信噪比(SNR)不是很低的情况下,语音片段的STE相对较大,而ZCC相对较小;而非语音片段的STE相对较小,但是ZCC相对较大。因为语音信号能量绝大部分包含在低频带内,而噪音信号通常能量较小且含有较高频段的信息。故而可以通过测量语音信号的这两个特征并且与两个门限(阈值)进行对比,从而判断语音信号与非语音信号。
通常对语音信号分帧时取一帧20ms (因为一般会进行短时傅里叶变换,时域和频域的分辨率需要一个平衡,20ms为平衡点,此处不用考虑)。此处输入信号采样率为8000HZ。因此每一帧长度为160 samples.STE的计算方法是 , 即帧内信号的平方和。
在本文中ZCC的计算方法是,将帧内所有sample平移1,再对应点做乘积,符号为负的则说明此处过零,只需将帧内所有负数乘积数目求出则得到该帧的过零率。
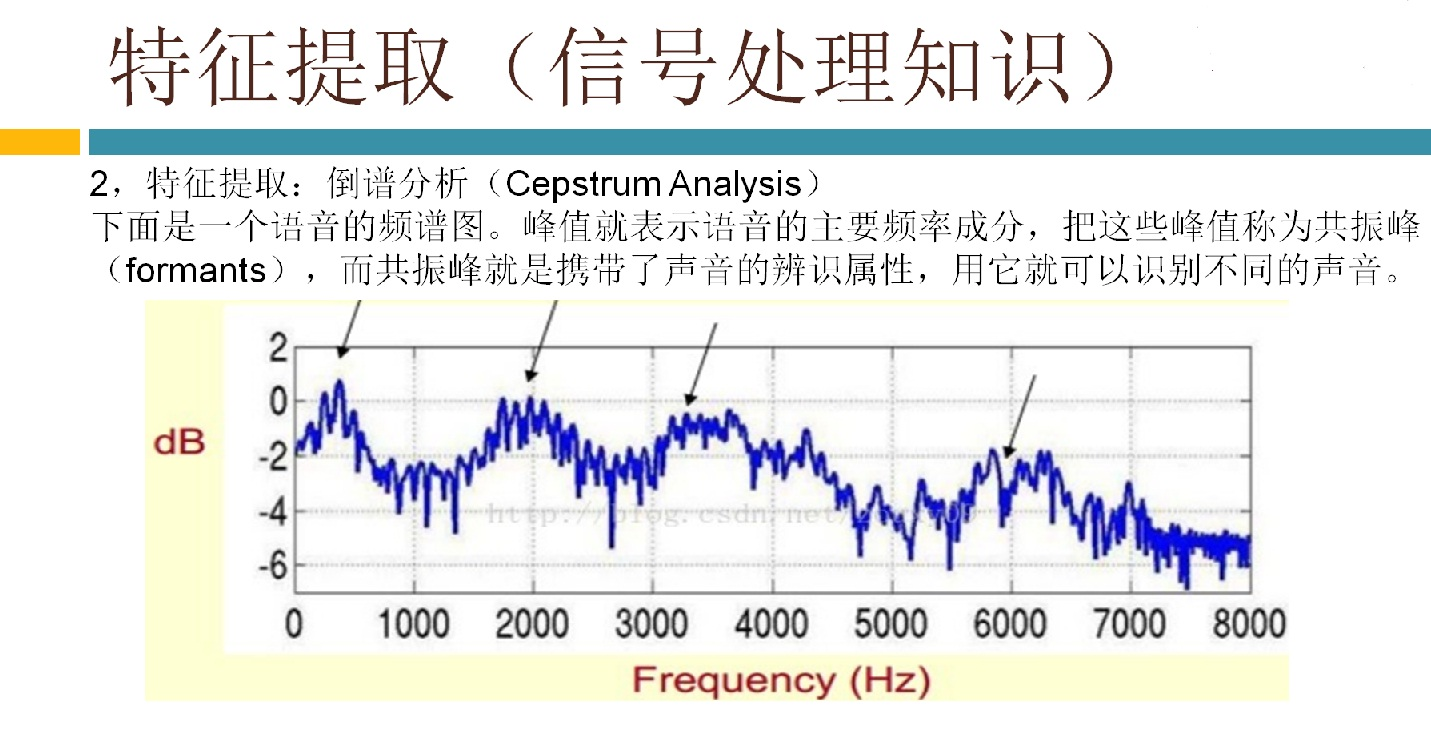
VAD(Voice Activity Detection)基于能量的特征常用硬件实现,谱(频谱和倒谱)在低信噪比(SNR)可以获得较好的效果。当SNR到达0dB时,基于语音谐波和长时语音特征更具有鲁棒性。
当前的判决准则可以分为三类:基于门限,统计模型和机器学习。
基于能量的准则是检测信号的强度,并且假设语音能量大于背景噪声能量,这样当能量大于某一门限时,可以认为有语音存在。然而当噪声大到和语音一样时,能量这个特征无法区分语音还是纯噪声。
早先基于能量的方法,将宽带语音分成各个子带,在子带上求能量;因为语音在2KHz以下频带包含大量的能量,而噪声在2~4KHz或者4KHz以上频带比0~2HKz频带倾向有更高的能量。这其实就是频谱平坦度的概念,webrtc中已经用到了。在信噪比低于10dB时,语音和噪声的区分能力会加速下降。

可以将一段语音片段分为 静音段、过度段、语音段、结束。
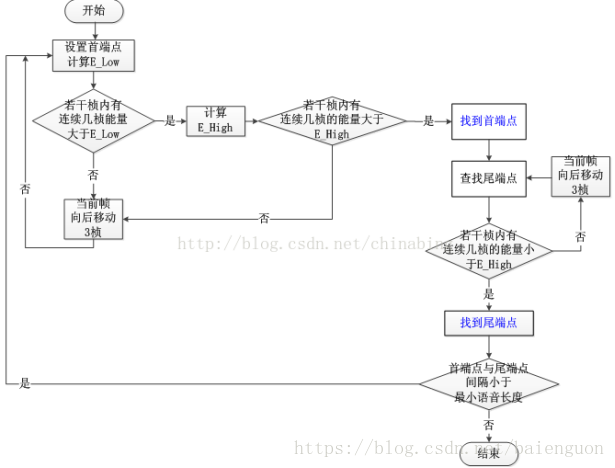
比较常用的VAD技术是基于短时能量和过零率的双门限端点检测。
1. 分别对短时能量和过零率设置两个门限值energy_low, energy_high和zcr_low, zcr_high
energy_high > energy_low
zcr_high > zcr_low
2. 计算一帧的短时能量enegry和过零率zcr
若enegry > energy_low && zcr > zcr_low,则进入过度段
3. 计算一帧的短时能量和过零率,
若enegry > energy_high && zcr > zcr_high, 此时还不能断定语音开始,
继续计算几帧短时能量和过零率,若enegry > energy_high && zcr > zcr_high,则可判定语音开始。
能量双门限VAD流程图:
基于短时能量和短时平均过零率的端点检测介绍:




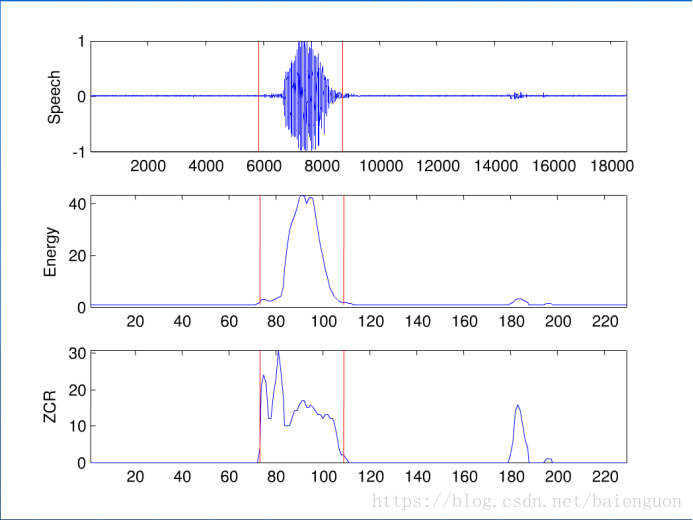
数字“4”的短时能量与平均过零率
音频端点检测就是从连续的语音流中检测出有效的语音段。它包括两个方面,检测出有效语音的起始点即前端点,检测出有效语音的结束点即后端点。可以降低存储或传输的数据量,在有些应用场景中,使用端点检测可以简化人机交互,比如在录音的场景中,语音后端点检测可以省略结束录音的操作。
语音信号是一个以时间为自变量的一维连续函数,计算机处理的语音数据是语音信号按时间排序的采样值序列,这些采样值的大小同样表示了语音信号在采样点处的能量。
采样点的能量值通常使用采样值的平方,一段包含N个采样点的语音的能量值可以定义为其中各采样值的平方和。这样,一段语音的能量值既与其中的采样值大小有关,又与其中包含的采样点数量有关。为了考察语音能量值的变化,需要先将语音信号按照固定时长比如20毫秒进行分割,每个分割单元称为帧,每帧中包含数量相同的采样点,然后计算每帧语音的能量值。如果音频前面部分连续M0帧的能量值低于一个事先指定的能量值阈值E0,接下来的连续M0帧能量值大于E0,则在语音能量值增大的地方就是语音的前端点。同样的,如果连续的若干帧语音能量值较大,随后的帧能量值变小,并且持续一定的时长,可以认为在能量值减小的地方即是语音的后端点。现在的问题是,能量值阈值E0怎么取?M0又是多少?理想的静音能量值为0,故上面算法中的E0理想状态下取0。不幸的是,采集音频的场景中往往有一定强度的背景音,这种单纯的背景音当然算静音,但其能量值显然不为0,因此,实际采集到的音频其背景音通常有一定的基础能量值。
我们总是假设采集到的音频在起始处有一小段静音,长度一般为几百毫秒,这一小段静音是我们估计阈值E0的基础。对,总是假设音频起始处的一小段语音是静音,这一点假设非常重要!!!!在随后的降噪介绍中也要用到这一假设。在估计E0时,选取一定数量的帧比如前100帧语音数据(这些是“静音”),计算其平均能量值,然后加上一个经验值或乘以一个大于1的系数,由此得到E0。这个E0就是我们判断一帧语音是否是静音的基准,大于这个值就是有效语音,小于这个值就是静音。
至于M0,比较容易理解,其大小决定了端点检测的灵敏度,M0越小,端点检测的灵敏度越高,反之越低。语音应用的场景不同,端点检测的灵敏度也应该被设置为不同的值。例如,在声控遥控器的应用中,由于语音指令一般都是简单的控制指令,中间出现逗号或句号等较长停顿的可能性很小,所以提高端点检测的灵敏度是合理的,M0设置为较小值,对应的音频时长一般为200-400毫秒左右。在大段的语音听写应用中,由于中间会出现逗号或句号等较长时间的停顿,宜将端点检测的灵敏度降低,此时M0值设置为较大值,对应的音频时长一般为1500-3000毫秒。所以M0的值,也就是端点检测的灵敏度,在实际中应该做成可调整的,它的取值要根据语音应用的场景来选择。以上只是语音端点检测的很简单的一般原理,实际应用中的算法远比上面讲的要复杂。
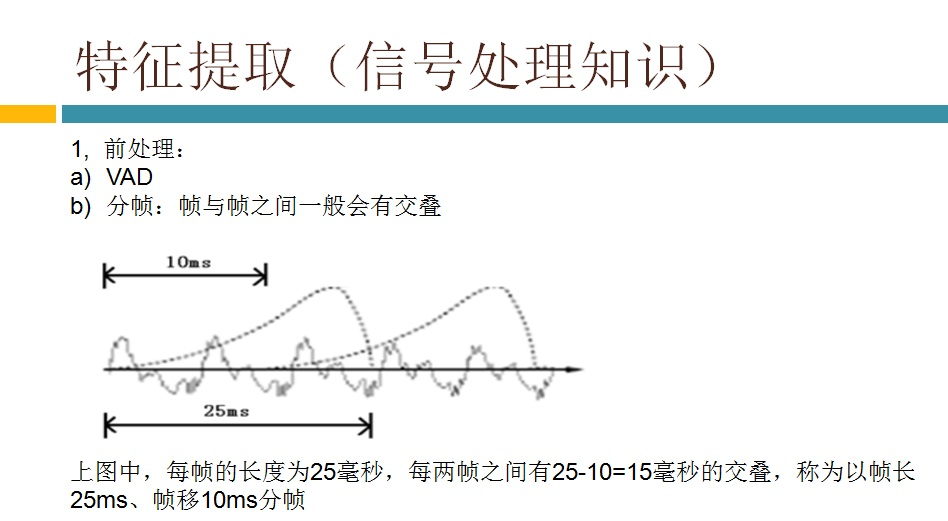
要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现,这里不详述。帧与帧之间一般是有交叠的,就像下图这样:
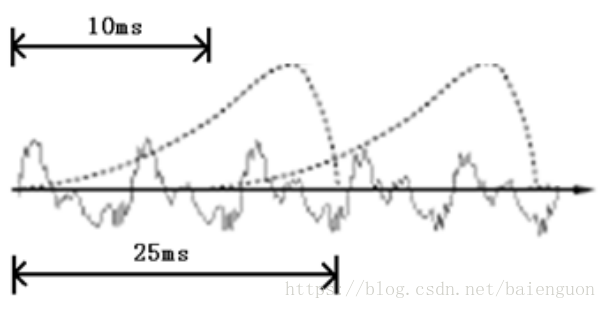
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
在用VAD算法确定静音和语音数据的开始和起止点之前,需要对语音数据进行处理,然后再计算语音数据的开始和起止点,这个过程称为数据的预处理,有些VAD算法是基于短时能量和过零率实现的,并不进行预处理操作,但实验表明,对数据进行预处理之后的效果要比不进行预处理的效果好。可以对数据进行去除直流和加窗两个预处理。采样频率的设置:我们人耳一般可以听到的频率最高就是16000HZ。根据采样定理,一般采样频率要是这个的两倍才不会发生混叠。所以我们在通话的时候采样频率一般是8Khz,带宽就需要16Khz。这样就基本可以使得通话的体验非常到位,还原度非常高!不是说采样频率越高声音的效果就越好,这是一个此消彼长的情况。这一次我们采样就用16Khz,这样其实已经可以把基本的声音采下来。因为人耳对于低频还是更加敏感!现在的高保真就是44.1Khz的采样率。
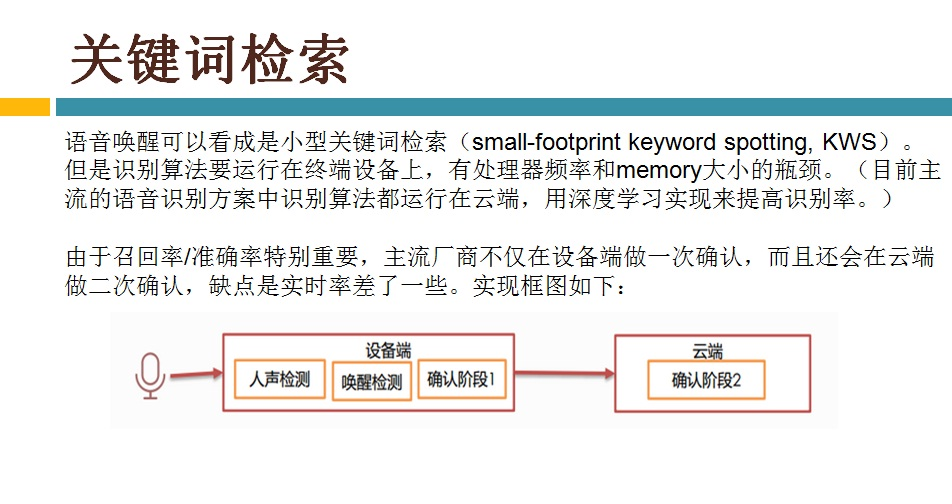
4,语音认别---唤醒技术KWS介绍
由于目前终端(如手机)上的CPU还不足够强劲,不能让语音识别的各种算法跑在终端上,尤其现在语音识别都是基于深度学习来做了,更加不能跑在终端上,所以目前主流的语音识别方案是声音采集和前处理在终端上做,语音识别算法则放在服务器(即云端)上跑。虽然这种方案有泄漏隐私(把终端上的语音数据发给服务器)和没有网络不能使用等缺点,但也是不得已而为之的,相信在不久的将来等终端上的CPU足够强劲了会把语音识别的所有实现都放在终端上的。
是不是意味着终端上做不了语音识别相关的算法了?其实也不是,语音唤醒功能是需要在终端上实现的。语音唤醒是指设定一个唤醒词,如Siri的“Hi Siri”,只有用户说了唤醒词后终端上的语音识别功能才会处于工作状态,否则处于休眠状态。这样做主要是为了降功耗,增加续航时间。目前很多终端都是靠电池供电的,对功耗很敏感,是不允许让语音识别功能一直处于工作状态的。







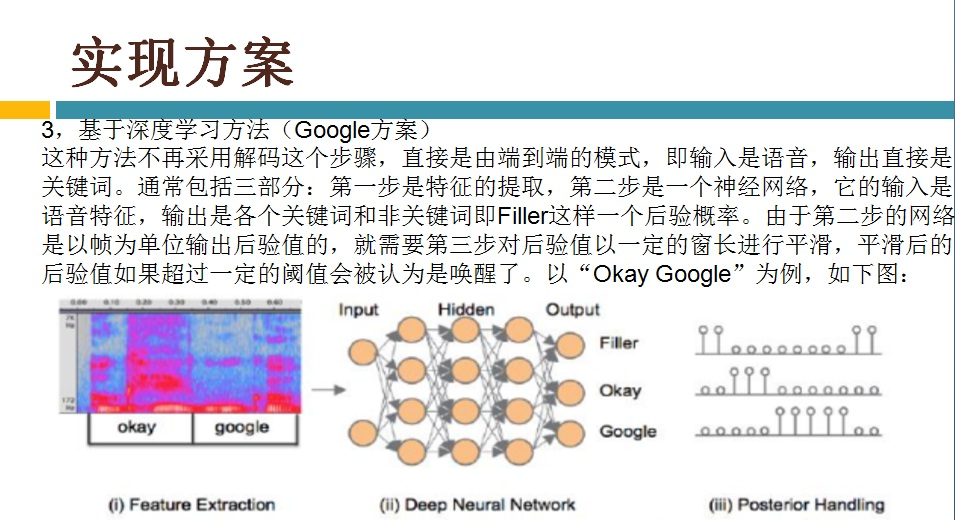

Google 基于CNN实现的算法,属于Deep KWS方案
评判标准:FRR (False Reject Rate), "漏警率", CNN的FRR比DNN的FRR提升了27%~44%.
限制了乘法的运算量,限制了参数的数量
很早以前大家使用HMM,后来2014年,Google使用了DNN的方案SMALL-FOOTPRINT KEYWORD SPOTTING USING DEEP NEURAL NETWORKS - 2014 IEEE,然后2014年有人使用CNN进行语音识别Deep Convolutional Neural Networks for large-scale speech tasks, 但是这种CNN架构对计算量要求比较大,而KWS方案对计算量要求有一定的限制,所以本论文中他们提出了优化了版本的CNN方案。
Baidu基于CRNN实现的算法KWS方案
又一个Deep KWS方案
CRNN (Convolutional Recurrent Neural Networks): CNN+RNN,
流程:PCEN -> CNN -> BRNN -> DNN -> SoftMax
RNN对信噪比大的场景很有帮助
Apple基于DNN实现的算法KWS方案
手表中使用的DNN模型只有一个,是介于Small DNN和Large DNN之间的模型。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号