SiruiXu-2022-DiverseHumanMotionPredictionGuidedByMultiLevelSpatialTemporalAnchors-ECCV(oral)
# Diverse Human Motion Prediction Guided by Multi-level Spatial-Temporal Anchors #paper
1. paper-info
1.1 Metadata
- Author:: [[Sirui Xu]], [[Yu-Xiong Wang]], [[Liang-Yan Gui]]
- 作者机构::
- Keywords:: #HMP
- Journal:: #ECCV oral
- Date:: [[October 23, 2022]]
- 状态:: #Done
- 链接:: https://doi.org/10.1007/978-3-031-20047-2_15
- 修改时间:: 2022.12.01
1.2. Abstract
Predicting diverse human motions given a sequence of historical poses has received increasing attention. Despite rapid progress, existing work captures the multi-modal nature of human motions primarily through likelihood-based sampling, where the mode collapse has been widely observed. In this paper, we propose a simple yet effective approach that disentangles randomly sampled codes with a deterministic learnable component named anchors to promote sample precision and diversity. Anchors are further factorized into spatial anchors and temporal anchors, which provide attractively interpretable control over spatial-temporal disparity. In principle, our spatial-temporal anchor-based sampling (STARS) can be applied to different motion predictors. Here we propose an interaction-enhanced spatial-temporal graph convolutional network (IE-STGCN) that encodes prior knowledge of human motions (e.g., spatial locality), and incorporate the anchors into it. Extensive experiments demonstrate that our approach outperforms state of the art in both stochastic and deterministic prediction, suggesting it as a unified framework for modeling human motions. Our code and pretrained models are available at https://github.com/Sirui-Xu/STARS.
Introduction
prediction diverse human motions
可看做生成问题,可通过生成模型进行预测。但是生成模型会造成模式坍塌问题,如(fig1.)所示,生成模型在学习过程中会集中于数据中的主模式。会忽略了边缘特征。
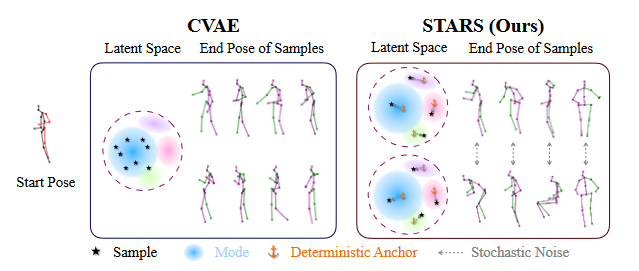
However, current motion capture datasets are typically constructed in a way that there is only a single ground truth future sequence for each single historical sequence, which makes it difficult for generators to model the underlying multi-modal densities of future motion distribution.
在实践中,生成器倾向于忽略随机编码中的差异,而只产生类似的预测。
\(\color{red}{思考:}\) 只有一个真实未来序列-->构造多个伪真实序列-->如何训练?
作者提出的策略:Multi-Level Spatial-Temporal AnchoR-Based Sampling(STARS) 。作者利用人体动作是具有惯性的思想,将潜在变量解耦为两部分:
- stochastic component(noise)
- deterministic learnable component (anchors)
多样性由noise产生,人体动作的随机性由此建模,这减轻了必须对整个未来多样性进行建模的负担。
动作的差异性可分为空间和时间两个方面的差异,于是作者将anchors也分为spatial anchors和temporal anchors,并且通过直接线性插值的方法,在不同时间或空间插入特定的anchors可以控制动作序列的生成。并且anchor可以与任何预测器兼容,作者使用了Interaction-Enhanced Spatial-Temporal Graph Covolutional Network(IE-STGCN)。
3. Methodology
3.1 Mutil-Level Spatial-Temporal Anchor-based sampling
未来动作序列的多样性可分为:
- deterministic component:在不同主体执行的不同动作中,速度、方向、运动模式等存在相关或课共享的变化。
- stochastic component:给定一个主体产生的动作序列,动作的变化幅度是随机的。
作者根据上述的多样性,将潜在变量解耦成对应的两部分,随机部分由潜在变量\(p(z)\)控制,而确定部分由\(K \ learnable \ parameter(\mathcal{A}=\{a_k\}_{k=1}^K)\)控制,也就是作者提出的anchor。
Deterministic anchors are expected to identify as many modes as possible, which is achieved through a carefully designed optimization, while stochastic noise further specifies motion variation within certain modes.
确定性锚点应该识别尽可能多的模式,这是通过精心设计的优化实现的,而随机噪声则进一步指定了某些模式下的运动变化。
经过上述介绍后,将预测序列的多模态分布表示为:
\(\color{red}{如何解耦是重中之重}\)
生成模型表示为:
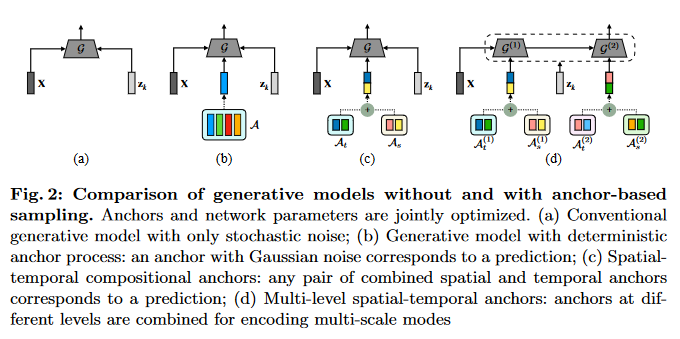
在进一步,通过时间和空间两个维度,分别得到对应的空间锚点\(\mathcal{A}_s=\{a_i^s\}_{i=1}^{K_s}\)和时间锚点\(\mathcal{A}_t=\{a_j^t\}_{j=1}^{K_j}\) ,可以通过控制二者来得到对应的动作序列。于是生成模型可写作:
不仅如此,为了增加多样性,锚点也可以嵌套:
以上三种模式可用(fig.2)解释:
train
根据\(K\)个锚点,对每一个历史序列产生\(K\)个未来序列。损失函数可分为3类:
- 重构损失。
- 多样化损失。
- 动作限制损失。
每个锚点损失单独进行训练的。
3.2 Interaction-Enhanced Spatial-Temporal Graph Convolutional Network
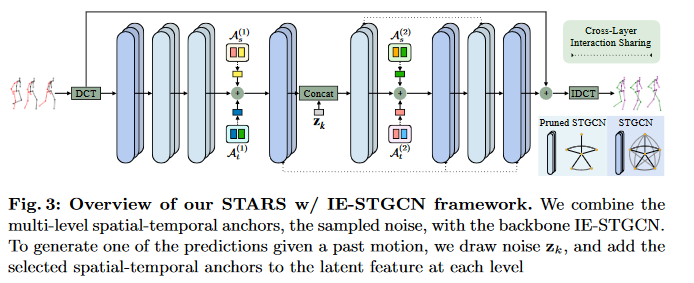
GCN的迭代公式为:
其中\(\mathbf{A d j}_{s}^{(l)}\)表示空间邻接矩阵,\(\mathbf{A d j}_{f}^{(l)}\)表示频率邻接矩阵。将最后输出\(H_k^{(L)}\)reshape成\(\tilde{Y}_k\in \mathbb{R}^{M\times V\times C^{(L)}}\) ,然后经过DCT reverse 得到最后输出。
Conceptually, interactions between spatial-temporal nodes should be relatively invariant across layers, and different interactions should not be equally important. For example, we would expect constraints and dependencies between “left arm” and “left forearm,” while the movements of “head” and “left forearm” are relatively independent.
时空节点之间的相互作用在各层之间相互不变,并且不同的相互作用重要程度不一样,作者认为独立地为每一层构建一个完整的时空图是多余的。所以,作者引入了两种方式Cross-Layer Interaction Sharing和spatial interaction pruning,前者在不同层共享参数,后者修剪完全图。
\(\color{blue}{Cross-Layer Interaction Sharing}\) :
在模型学习过程中,空间依赖是不会变的,作者发现以一层的间隔共享邻接矩阵是有效的,如(fig.3)\(Adj_s^{(4)}=Adj_s^{(6)}=Adj_s^{(8)} \ and \ Adj_s^{(5)}=Adj_s^{(7)}\)
\(\color{blue}{Spatial Interaction Pruning}\):
图中的节点依赖是不同的,为此加入掩码矩阵。\(\hat{Adj}_s^{l}=M_s \odot Adj_s^{(l)}\)
we emphasize spatial locality based on skeletal connections and mirror symmetry tendencies.
4. Experiments
- dataset
- Human3.6M
- HumanEva-I
- Metrics
- Average pairwise Distance
- Average Displacement Error
- Final Displacement Error
- Multi-Model ADE
- Multi-Modal FDE
5. 总结
多样性和控制是关键,已有的生成模型的模式坍塌问题,之前的方法有重新映射潜在变量,这篇文章将潜在变量解耦成确定部分和随机部分,并且可以通过插值的方式来控制动作的生成。如何解耦将是我接来下的重点思考方向。
