An-Survey-Vision-Transformer-2022
# A Survey on Vision Transformer #paper
1. paper-info
1.1 Metadata
- Author:: [[Kai Han]], [[Yunhe Wang]], [[Hanting Chen]], [[Xinghao Chen]], [[Jianyuan Guo]], [[Zhenhua Liu]], [[Yehui Tang]], [[An Xiao]], [[Chunjing Xu]], [[Yixing Xu]], [[Zhaohui Yang]], [[Yiman Zhang]], [[Dacheng Tao]]
- 作者机构::
- Keywords:: #DeepLearning , #Transformer , #Survey
- Journal:: [[IEEE Transactions on Pattern Analysis and Machine Intelligence]]
- Date:: [[2022]]
- 状态:: #Done
1.2 Abstract
Transformer, first applied to the field of natural language processing, is a type of deep neural network mainly based on the self-attention mechanism. Thanks to its strong representation capabilities, researchers are looking at ways to apply transformer to computer vision tasks. In a variety of visual benchmarks, transformer-based models perform similar to or better than other types of networks such as convolutional and recurrent networks. Given its high performance and less need for vision-specific inductive bias, transformer is receiving more and more attention from the computer vision community. In this paper, we review these vision transformer models by categorizing them in different tasks and analyzing their advantages and disadvantages. The main categories we explore include the backbone network, high/mid-level vision, low-level vision, and video processing. We also include efficient transformer methods for pushing transformer into real device-based applications. Furthermore, we also take a brief look at the self-attention mechanism in computer vision, as it is the base component in transformer. Toward the end of this paper, we discuss the challenges and provide several further research directions for vision transformers.
关键字:Transformer, Self-attention, Computer Vision, High-level vision, Low-level vision , Video
1.3 Introduction
- 深度学习整体发展历程,
CNN->RNN->Transformer Transforms起源, transforms最先应用于NLP领域,取得了重大的成就。Transforms在CV领域的成功。本篇摘要的重点
Inspired by the major success of transformer architectures in the field of NLP, researchers have recently applied transformer to computer vision (CV) tasks.
- 文章主要内容:
In this paper, we focus on providing a comprehensive overview of the recent advances in vision transformers and discuss the potential directions for further improvement.
- 分类(
By application scenarios)

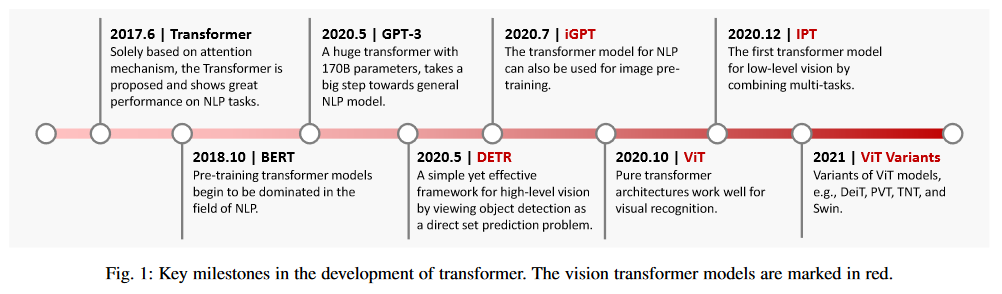
1.4 文章架构
2. Formulation OF Transformer

2.1 General Formulation of self-attention
2.2 Scaled Dot-product Self-Attention
- Multi-Head Attention
2.3 Other Key Concepts in Transformer
- Residual Connection in the Encoder and Decoder
- Feed-Forward Network
- Final Layer in the Decoder
3. Revisiting Transformers For NLP

3.1 BERT and its variants
3.2 Generative Pre-trained Transformer models
- GPT
- GPT2
- GPT3
3.3 Other NLP-related domains
- BioNLP Domain
Transformer应用深远,可拓展到其他领域。
The rapid development of transformer-based models on a variety of NLP-related tasks demonstrates its structural superiority and versatility, opening up the possibility that it will become a universal module applied in many AI fields other than just NLP. The following part of this survey focuses on the applications of transformer in a wide range of computer vision tasks that have merged over the past two years.
4. Vision Transformer
4.1 Backbone for Representation Learning
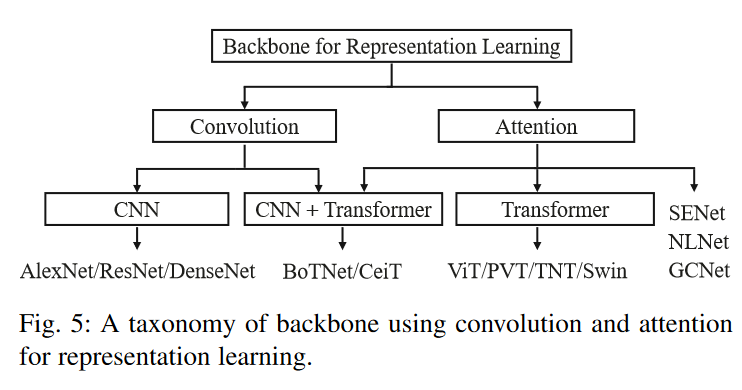
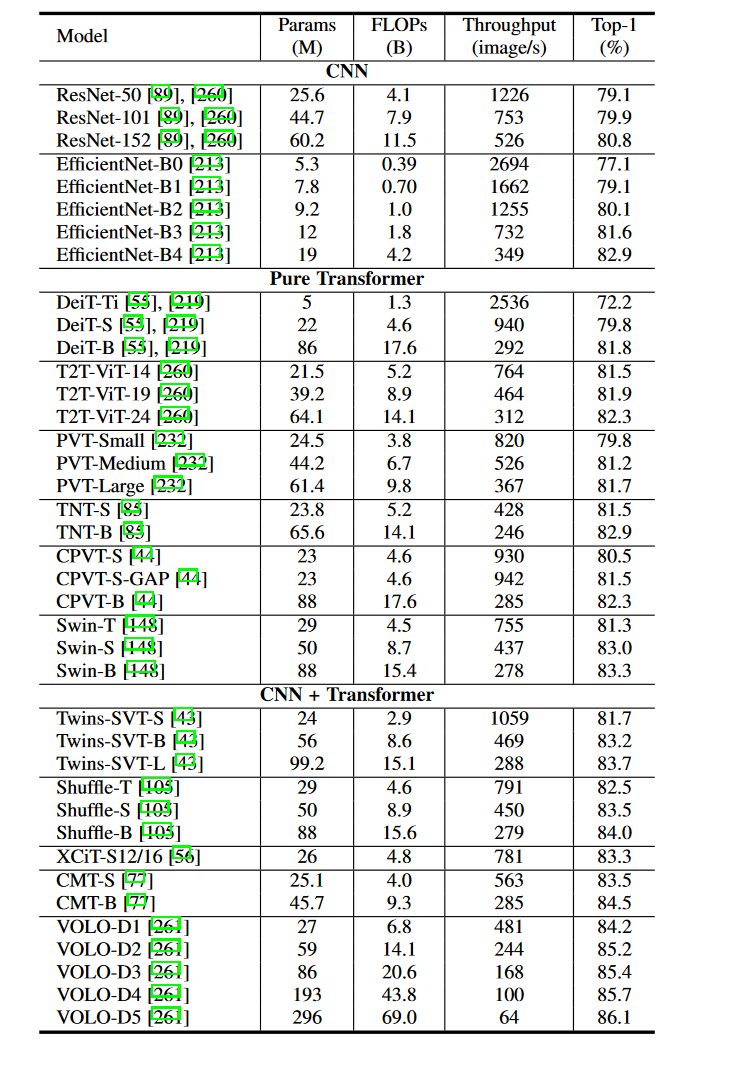
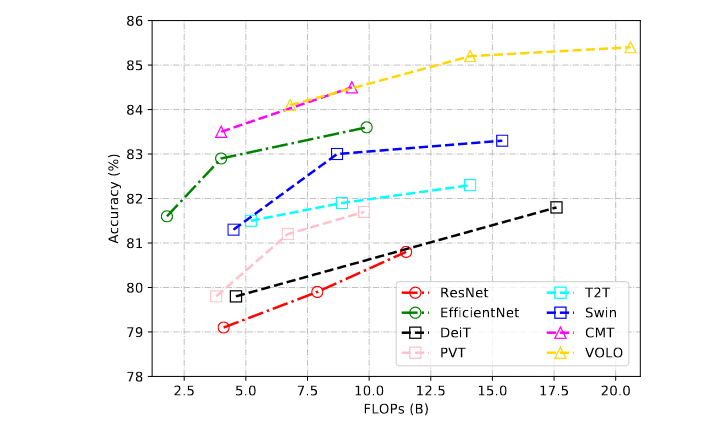

4.1.1 Pure Transformer
- ViT

- CvT, CeiT, LocalViT, CMT
- LeViT:提出了一种
hybrid neural network混合神经网络,可以快速进行图片分类。 - BoTNet: 在resnet网络的最后的
bottleneck block用自注意力机制代替卷积块。 - Visformer:反应了CNN和Transformer之间的差异。
4.1.3 Self-supervised Representation Learning
- Generative Based Approach
iGPT - Contrastive Learning Based Approach
对比学习是计算机视觉领域的最受欢迎的自监督学习方法。
4.2 High/Mid-level Vision
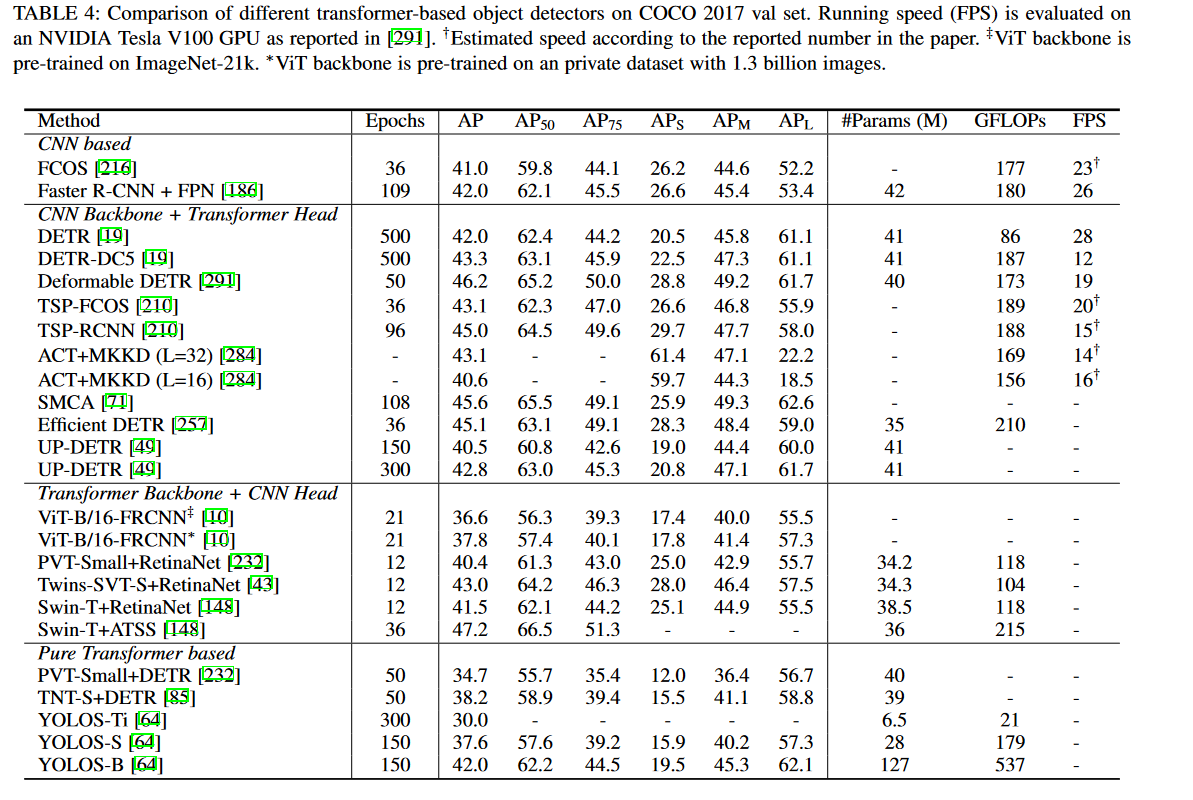
4.2.1 Generic Object Detection
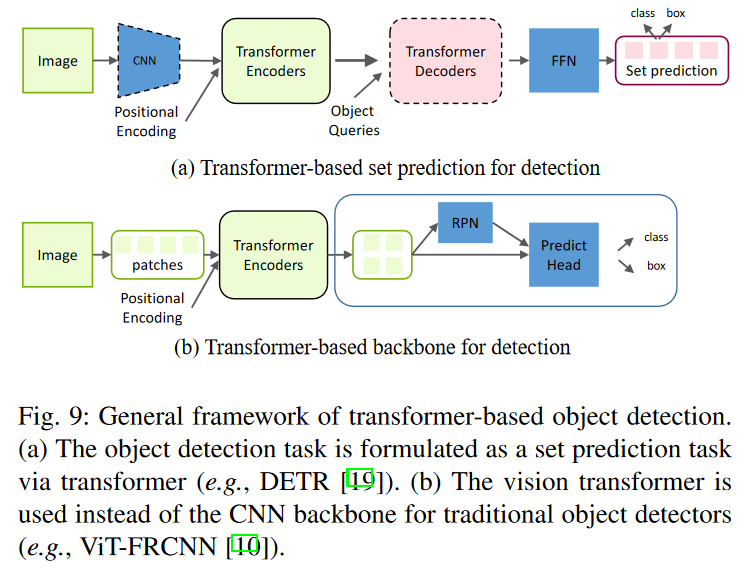
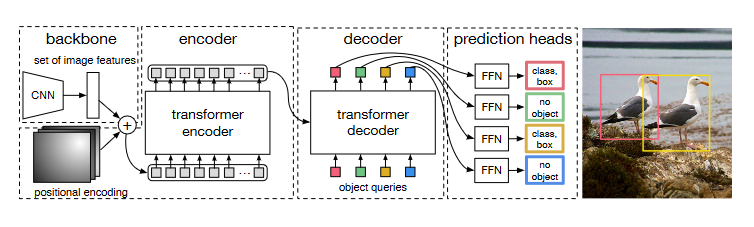
Transformer-based Set Prediction for Detection
- DETR
-
Transformer-based Backbone for Detection
-
Pre-training for Transformer-based Object Detection
4.2.2 Segmentation
- Transformer for Panoptic Segmentation
- Transformer for Instance Segmentation
- Transformer for Semantic Segmentation
- Transformer for Medical Image Segmentation
4.2.3 Pose Estimation
Transformer for Hand Pose Estimation
Transformer for Human Pose Estimation
4.2.5 Other Tasks
- Pedestrian Detection
- Lane Detection
- Scene Graph.
- Tracking
- Re-Identification
- Point Cloud Learning.
4.3 Low-level Vision
4.3.1 Image Generation
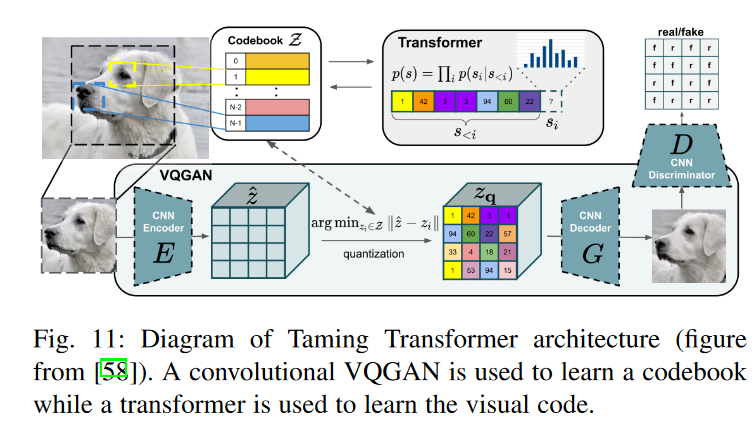

4.4 Video Processing
4.4.1 High-level Video Processing
- Video Action Recognition
- Video Retrieval
- Video Object Detection
- Multi-task Learning
4.4.2 Low-levle Video Processing
- Frame/Video Synthesis
- Video Inparnting
5. Conclusions and Discussions
5.1 Challenges
- 模型专一性,专门为CV设计的模型
- 模型通用性和鲁棒性
- 模型可解释性
- 模型高效性
5.2 Future Prospects
- 高效性和计算机性能之间的平衡
- 模型处理多任务
- CNN/Transformer 模型选择

 浙公网安备 33010602011771号
浙公网安备 33010602011771号