005-DeepResidualLearning2015(ResNet)
# Deep Residual Learning for Image Recognition #paper
1. paper-info
1.1 Metadata
- Author:: * Authors: [[Kaiming He]], [[Xiangyu Zhang]], [[Shaoqing Ren]], [[Jian Sun]]
- 作者机构::
- Keywords:: #DeepLearning , #ResNet
- Date:: [[2015-12-10]]
- 状态:: #Doing
Abstract
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets [41] but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
摘要结构,针对什么问题,做了什么工作,用的什么思想,达到了什么效果。
2. Introduction
2.1 研究现状
深度卷积网络取得了重大的突破,网络深度至关重要(更深层的网络可以更好的提取特征)。网络越深并不代表模型的效果越好,很容易产生梯度消失/爆炸vanishing/exploding gradients 的问题。该问题已经通过BNbatch normalization所解决。
2.2 新问题
当更深的网络开始收敛时,产生了一种退化问题:网络层数的增加,精度很快达到饱和,然后迅速下降。这种问题并不是过拟合引起,并且更深的网络精度会更差。如图2-1
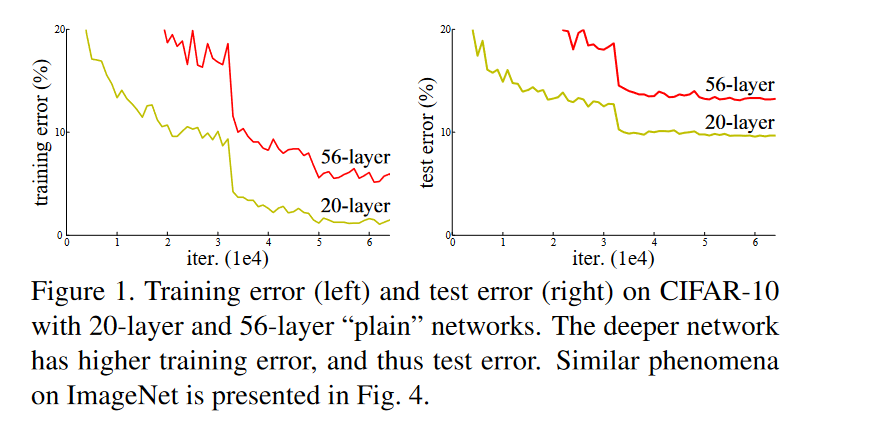
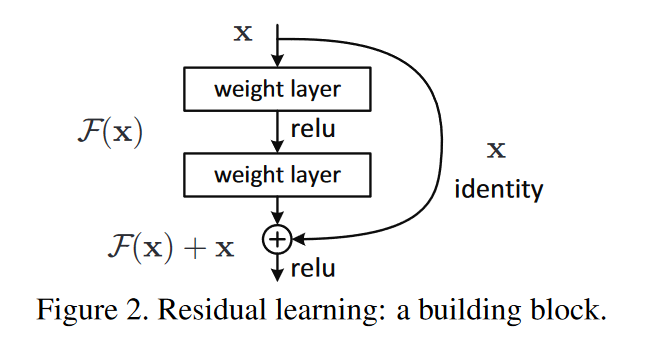
假设我们的网络块所需要学习的映射的 \(H(x)\) ,对于普通的网络结构来说,是直接学习该\(H(x)\), 导致更深的网络块是恒等映射。残差块让堆叠的非线性网络块学习一个新的映射\(F(x) = H(x)-x\) ,然后该残差块的新输出为\(F(x)+x\) ,这时候新的映射关系(整体)就是\(F(x)+x=H(x)-x+x=H(x)\)
2.4 新方案的优点
- 没有带来多余的参数和计算复杂度
- 新网络块依然能够通过梯度下降的方式更新
- 训练效果显著
ResNets 的集成在 ImageNet 数据集上达到了 3.57% 的 top-5 错误率,在其他数据集上也同样优秀。
3. Deep Residual Learning
该章节详细介绍深度残差网络,理论-> 实现-> 网络结构
- 理论
\(H(x)\) 为几个网络堆叠块要拟合的映射,让这些堆叠快去近似\(H(x)-x\) - 实现
ResNet块定位为\(y=F( x_{i} ,W_{i} )+x, (1)\)
上个方程 \(x,F\) 的维度必须是相等的,如果不是这种情况(例如,当更改输入/输出通道时),我们可以通过快捷连接执行线性投影\(W_{s}\) 来匹配维度:
这样会带来更多的参数。
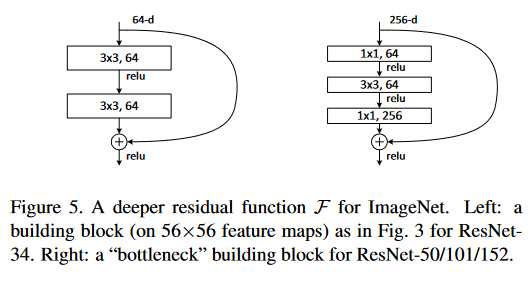
残差函数\(F\) 的形式是可变的。本文中的实验包括有两层或三层的函数\(F\) ,同时可能有更多的层。但如果\(F\) 只有一层,方程(1)类似于线性层:\(y=W1x+x\),实验表面没有优势。
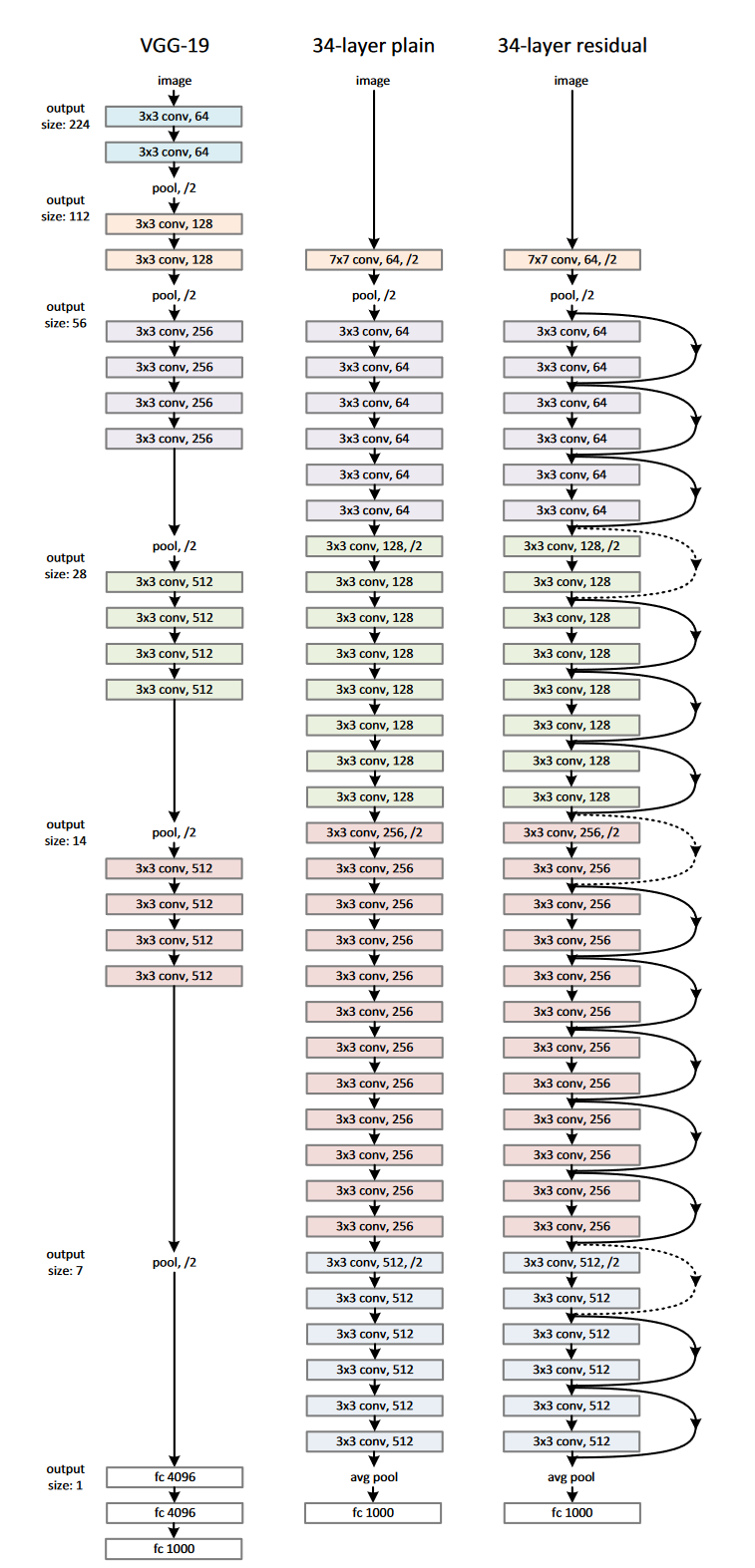
简单网络: 我们简单网络的基准(图3-2,中间)主要受到VGG网络(图3-2,左图)的哲学启发。卷积层主要有3×3的滤波器,并遵循两个简单的设计规则:(i)对于相同的输出特征图尺寸,层具有相同数量的滤波器;(ii)如果特征图尺寸减半,则滤波器数量加倍,以便保持每层的时间复杂度。我们通过步长为2的卷积层直接执行下采样。网络以全局平均池化层和具有softmax的1000维全连接层结束。图3-2(中间)的加权层总数为34。
残差网络: 基于上述的简单网络,我们插入快捷连接(图3-2,右),将网络转换为其对应的残差版本。当输入和输出具有相同的维度时(图3中的实线快捷连接)时,可以直接使用恒等快捷连接(方程(1))。当维度增加(图3中的虚线快捷连接)时,我们考虑两个选项:(A)快捷连接仍然执行恒等映射,额外填充零输入以增加维度。此选项不会引入额外的参数;(B)方程(2)中的投影快捷连接用于匹配维度(由1×1卷积完成)。对于这两个选项,当快捷连接跨越两种尺寸的特征图时,它们执行时步长为2。
3.1 Implementation for ImageNet

4. Experiments
4.1 Imagenet 分类
实验对比图:
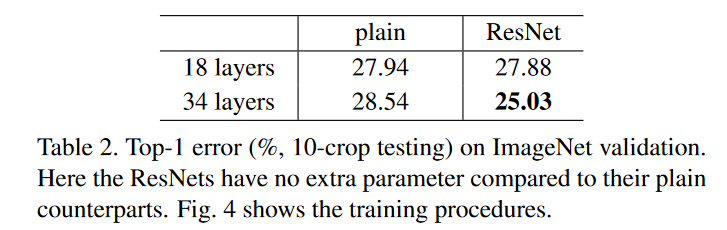
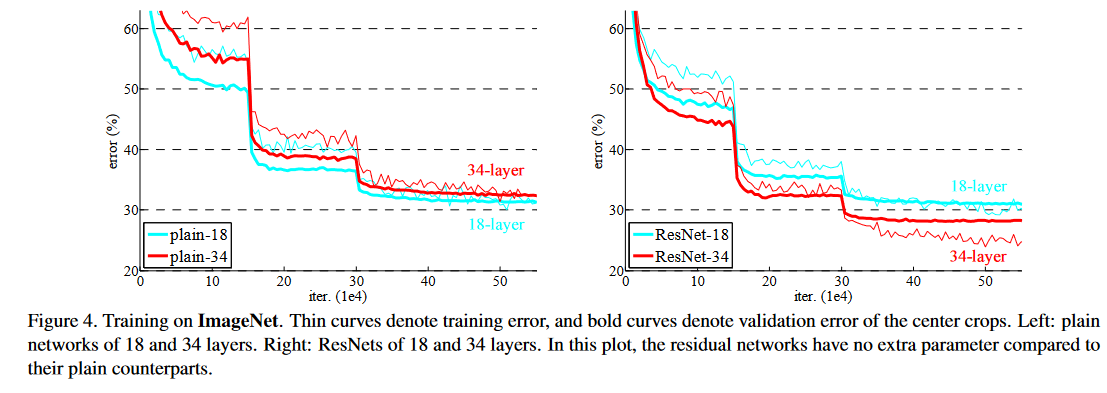
4. 代码实现
https://github.nowall.world/weiaicunzai/pytorch-cifar100/blob/master/models/resnet.py#L115
https://blog.paperspace.com/writing-resnet-from-scratch-in-pytorch/
https://nn.labml.ai/resnet/index.html
参考
- 文章
https://rohanvarma.me/resnet/ # ResNet Paper Notes
https://blog.paperspace.com/writing-resnet-from-scratch-in-pytorch/ 代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号