


pytorch学习0001
nn.ModuleList()对象
ModuleList是Module的子类,当在Module中使用它的时候,就能自动识别为子module。
当添加 nn.ModuleList 作为 nn.Module 对象的一个成员时(即当我们添加模块到我们的网络时),所有 nn.ModuleList 内部的 nn.Module 的 parameter 也被添加作为 我们的网络的 parameter。
Our function will return a nn.ModuleList. This class is almost like a normal list containing nn.Module objects. However, when we add nn.ModuleList as a member of a nn.Module object (i.e. when we add modules to our network), all the parameters of nn.Module objects (modules) inside the nn.ModuleList are added as parameters of the nn.Module object (i.e. our network, which we are adding the nn.ModuleList as a member of) as well.
简单的说,就是把子模块存储在list中.它类似于list, 既可以 append 操作,也可以做 insert 操作,也可以 extend 操作. 但是由于把layers存入Modulelist中后只是完成了存储作用,所以不能直接在forward中直接运行,需要通过索引调出相应的submodule.
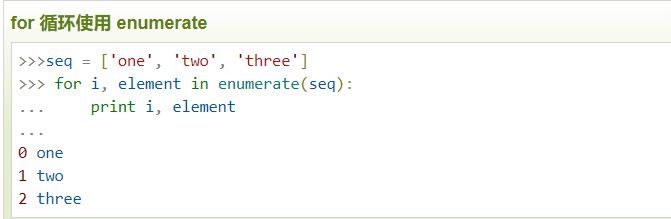
enumerate()
函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
nn.Sequential()对象
nn.Conv2d二维卷积可以处理二维数据
nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True))
参数:
in_channel: 输入数据的通道数,例RGB图片通道数为3;
out_channel: 输出数据的通道数,这个根据模型调整;
kennel_size: 卷积核大小,可以是int,或tuple;kennel_size=2,意味着卷积大小(2,2), kennel_size=(2,3),意味着卷积大小(2,3)即非正方形卷积
stride:步长,默认为1,与kennel_size类似,stride=2,意味着步长上下左右扫描皆为2, stride=(2,3),左右扫描步长为2,上下为3;
padding: 零填充
Input Channels
Input Channels指输入图像的通道数(如灰度图像就是1通道,RGB图像忽略alpha通道后就是3通道)。
Kernel Channels
Kernel Channels不是一个值,它是两个值组成的一组值,表征了这个卷积核将输入图像从多少个通道映射到多少个通道上,如下(当然也可以反过来写):
(和Input Channels相等的通道数,用了多少种卷积核)(和Input \ Channels相等的通道数,用了多少种卷积核)
(和Input Channels相等的通道数,用了多少种卷积核)
这里说种其实是想说,实际用的卷积核数量是Input Channels乘以后面的这个"卷积核种数"。也就是说对于每种卷积核都按照输入通道数分成了不同通道上的卷积核,对于不同通道上的同种卷积核:它们不共享权值,但共享一个偏置。
Kernel Size
Kernel Size指卷积核的长宽,如为3则卷积核是3乘3的。
Stride
Stride指每次移动卷积核的步长,显然这个值会大幅影响输出的Feature Map的shape。
Padding
Padding指为输入图像外围补充的圈数,注意如28乘28的图像,补充Padding=1就变成30乘30的了(而不是29乘29)。这个值一般直接在卷积时候定义,不必手动为输入图像加Padding。
3.卷积计算过程:
h/w = (h/w - kennel_size + 2padding) / stride + 1
x = ([10,16,30,32]),其中h=30,w=32,对于卷积核长分别是 h:3,w:2 ;对于步长分别是h:2,w:1;padding默认0;
h = (30 - 3 + 20)/ 2 +1 = 27/2 +1 = 13+1 =14
w =(32 - 2 + 2*0)/ 1 +1 = 30/1 +1 = 30+1 =31
batch = 10, out_channel = 33
故: y= ([10, 33, 14, 31])
BatchNorm2d()
在卷积神经网络的卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定,BatchNorm2d()函数数学原理如下:

BatchNorm2d()内部的参数如下:
1.num_features:一般输入参数为batch_size*num_features*height*width,即为其中特征的数量
2.eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5
3.momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数)
4.affine:当设为true时,会给定可以学习的系数矩阵gamma和beta
激活函数(activation function)
torch.cat
torch.cat是将两个张量(tensor)拼接在一起,cat是concatnate的意思,即拼接,联系在一起。
使用torch.cat((A,B),dim)时,除拼接维数dim数值可不同外其余维数数值需相同,方能对齐。
torch.cat(seq,dim,out=None)
其中seq表示要连接的两个序列,以元组的形式给出,例如:seq=(a,b), a,b 为两个可以连接的序列
dim 表示以哪个维度连接,dim=0, 横向连接,dim=1,纵向连接
torch.max
torch.max(input, dim, keepdim=False, out=None) -> (Tensor, LongTensor)
按维度dim 返回最大值
torch.nonzero(input, out=None):
返回一个包含输入input中非零元素索引的张量,输出张量中的每行包含输入中非零元素的索引
若输入input有n维,则输出的索引张量output形状为z * n, 这里z是输入张量input中所有非零元素的个数
- input(Tensor) - 输入张量
- out - 包含索引值的结果张量
torch.squeeze() 和torch.unsqueeze()
先看torch.squeeze() 这个函数主要对数据的维度进行压缩,去掉维数为1的的维度,比如是一行或者一列这种,一个一行三列(1,3)的数去掉第一个维数为一的维度之后就变成(3)行。squeeze(a)就是将a中所有为1的维度删掉。不为1的维度没有影响。a.squeeze(N) 就是去掉a中指定的维数为一的维度。还有一种形式就是b=torch.squeeze(a,N) a中去掉指定的定的维数为一的维度。
再看torch.unsqueeze()这个函数主要是对数据维度进行扩充。给指定位置加上维数为一的维度,比如原本有个三行的数据(3),在0的位置加了一维就变成一行三列(1,3)。a.squeeze(N) 就是在a中指定位置N加上一个维数为1的维度。还有一种形式就是b=torch.squeeze(a,N) a就是在a中指定位置N加上一个维数为1的维度
cv2.rectangle
cv2.rectangle(img, (x, y), (x+w. y+h), (0, 0, 255), 2) 用于在图像上画出矩阵
参数说明:img表示图片,(x, y)表示矩阵左上角的位置,(x+w, y+h)表示矩阵右下角的位置, (0, 0, 255)表示颜色,2表示线条
模板匹配:表示使用一个图像的模板,在一副主图上:从左到右,从上到下进行滑动,每次只滑动一个像素,最终结果的维度为(h - ht + 1, w - wt + 1),
h表示主图的长,ht表示模板的长, w表示主图的宽,wt表示模板的宽

