

分享一篇关于 C# 高低字节转换的问题
本篇内容主要讲一讲高低字节转换问题;
1、int16 高低位转换
1.1 Uint16转成byte数组,高位在前,低位在后
byte[] command = new byte[2]; double test1 = 5614; UInt16 result = (UInt16)(test1); command[0] = (byte)(result >> 8);//高位 command[1] = (byte)(result & 0xff);//低位 Console.WriteLine("{0}", FormatBytes(command) );
结果如下:
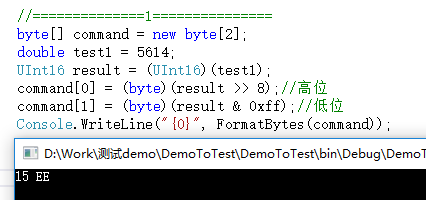
1.2 将byte数组(长度2,高字节在前,低字节在后),转成double数据;
//==============2================== byte[] command2 = new byte[2] { 0x15, 0xee }; double result2 = command2[0] * 256 + command2[1]; Console.WriteLine("{0}", result2);
结果如下:

如果遇到该转换的数据是有符号的(即可能出现负数)的情况,那么必须用下面方式转换,注意转换的时候要注意高字节在前低字节在后!
byte[] command2 = new byte[2] { 0xFE, 0xB6 };
int result2 = BitConverter.ToInt16(new byte[2] {command2 [6],command2[5] }, 0);;
Console.WriteLine("{0}",result2 );
2、INT32 高低位转换问题
2.1将int32 转成byte数组,要求高字节在前,低字节在后;
/// <summary> /// 将x转换成通讯用的字节 /// </summary> /// <returns></returns> public static byte[] Double_Bytes(double x) { byte[] byteLL = new byte[4]; byte[] byteLL2 = new byte[4]; int Result = (int)(x * 1048576.0);//这个看实际需求 byteLL2 = BitConverter.GetBytes(Result); byteLL[0] = byteLL2[3]; byteLL[1] = byteLL2[2]; byteLL[2] = byteLL2[1]; byteLL[3] = byteLL2[0]; return byteLL; } /// <summary> /// byte数组为byte数组赋值的函数 /// obj[objoff + i] = src[i]; /// </summary> /// <param name="src">源值</param> /// <param name="obj">目标数组</param> /// <param name="objoff">源数组在目标数组中的偏移</param> public static void Eva2bytes(byte[] src, byte[] obj, int objoff) { for (int i = 0; i < src.Length; i++) { obj[objoff + i] = src[i]; } } //==============3=============== byte[] command = new byte[4]; double test1 = 113.2535; byte[] byte1 = Double_Bytes(test1); Eva2bytes(byte1, command, 0); Console.WriteLine(FormatBytes(command));
结果如下:
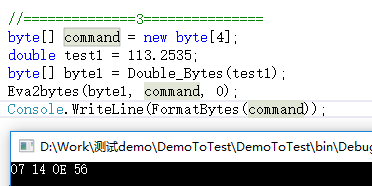
2.2 将byte数组 (长度2,高字节在前,低字节在后)转成double;
public static int ToInt32(byte[] value, int startIndex) { byte[] dst = new byte[4]; Buffer.BlockCopy(value, startIndex, dst, 0, 4); if (BitConverter.IsLittleEndian) { Array.Reverse(dst); } return BitConverter.ToInt32(dst, 0); } //==============4================== byte[] command4 = new byte[4] { 0x07, 0x14,0x0E,0x56 }; double result = ToInt32(command4, 0) / 1048576.0; Console.WriteLine("{0}", result);
结果如下:
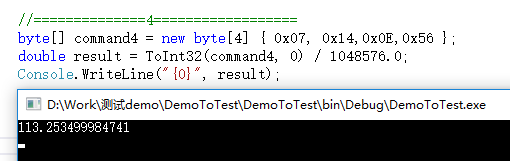
常用单片机内存一个地址只能存八位二进制数,最大数据只能是255(十进制).
当需要储存大于255的数据时,就需要用两个以上的内存地址,低位字节中的数是原数,高位字节中的数要乘以位数再与低位字节中的数相加才是你真要的数.
以下这段摘录网上的,希望你们看的懂吧
大端模式与小端模式
一、概念及详解
在各种体系的计算机中通常采用的字节存储机制主要有两种: big-endian和little-endian,即大端模式和小端模式。
先回顾两个关键词,MSB和LSB:
MSB:Most Significant Bit ------- 最高有效位
LSB:Least Significant Bit ------- 最低有效位
大端模式(big-edian)
big-endian:MSB存放在最低端的地址上。
举例,双字节数0x1234 以big-endian的方式存在起始地址0x00002000中:
| data |<-- address
| 0x12 |<-- 0x00002000
| 0x34 |<-- 0x00002001
在Big-Endian中,对于bit序列中的序号编排方式如下(以双字节数0x8B8A为例):
bit | 0 1 2 3 4 5 6 7 | 8 9 10 11 12 13 14 15
------MSB----------------------------------LSB
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+--------------------------------------------+
= 0x8 B 8 A
小端模式(little-endian)
little-endian:LSB存放在最低端的地址上。
举例,双字节数0x1234 以little-endian的方式存在起始地址0x00002000中:
| data |<-- address
| 0x34 |<-- 0x00002000
| 0x12 |<-- 0x00002001
在Little-Endian中,对于bit序列中的序号编排和Big-Endian刚好相反,其方式如下(以双字节数0x8B8A为例):
bit | 15 14 13 12 11 10 9 8 | 7 6 5 4 3 2 1 0
------MSB-----------------------------------LSB
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+---------------------------------------------+
= 0x8 B 8 A
二、数组在大端小端情况下的存储:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下:
高地址
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
低地址
Little-Endian: 低地址存放低位,如下:
高地址
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
低地址
三、大端小端转换方法:
Big-Endian转换成Little-Endian如下:
#define BigtoLittle16(A) ((((uint16)(A) & 0xff00) >> 8) | \
(((uint16)(A) & 0x00ff) << 8))
#define BigtoLittle32(A) ((((uint32)(A) & 0xff000000) >> 24) | \
(((uint32)(A) & 0x00ff0000) >> 8) | \
(((uint32)(A) & 0x0000ff00) << 8) | \
(((uint32)(A) & 0x000000ff) << 24))
四、大端小端检测方法:
如何检查处理器是big-endian还是little-endian?
联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写。
int checkCPUendian() {
union{ unsigned int a; unsigned char b; }c; c.a = 1; return (c.b == 1); }
好久没有写博客了,今天遇到了一个比较愚蠢的问题,必须记录一下,引以为戒了;
