
消息队列简述
消息队列
1:本质
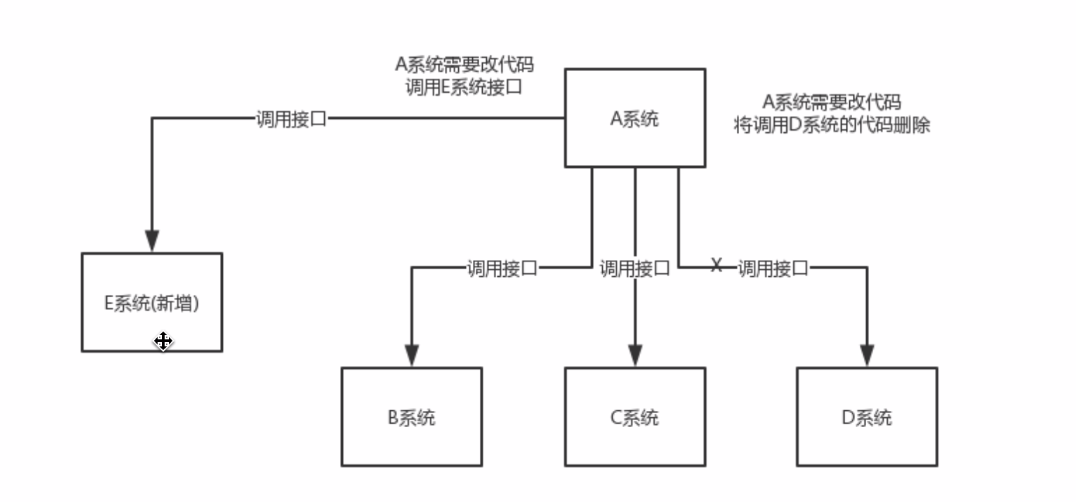
(1) 解耦
使用消息队列后:
总结: 通过MQ, Pub/Sub发布订阅消息这么一个模型。A系统就跟其他系统彻底解耦
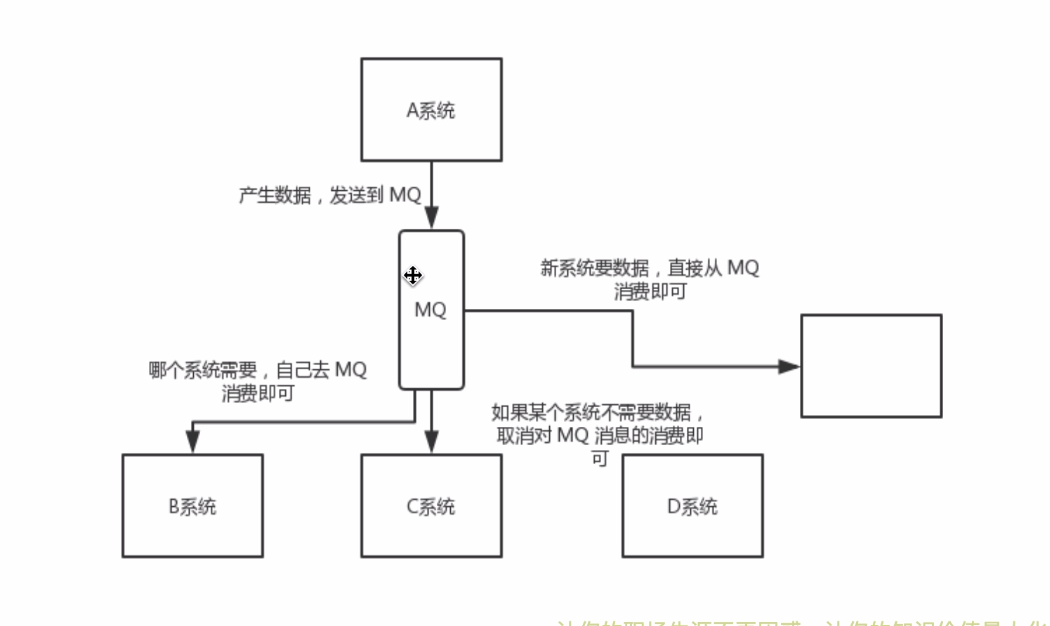
(2) 异步
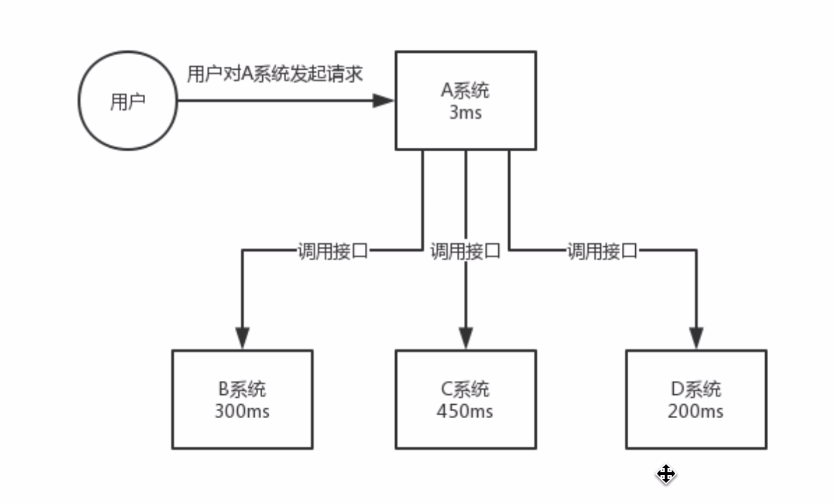
耗时 3 + 300 + 450 + 200 ms 则用户发送请求,将近1秒后才能返回响应
使用MQ后
耗时: 3ms
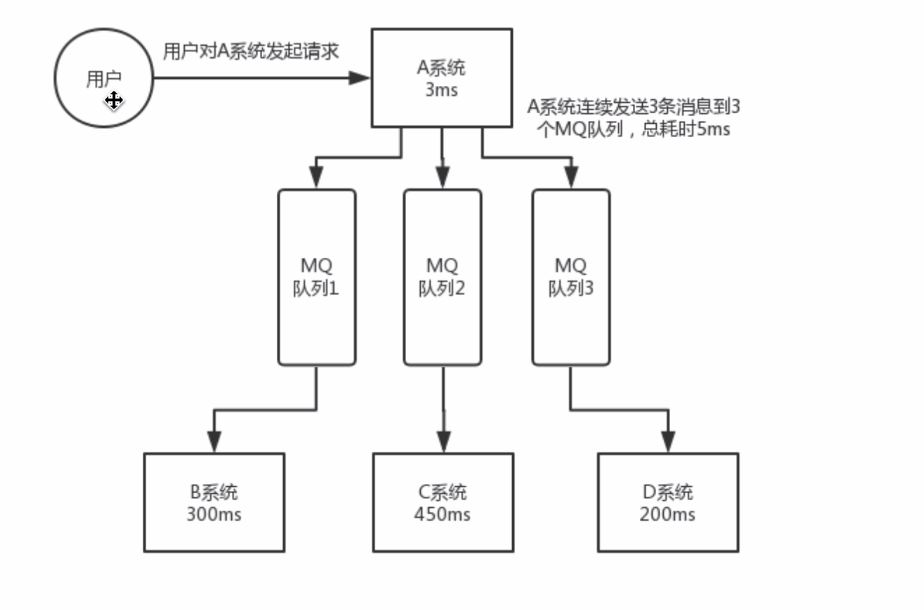
2: 场景
1.核心应用
1.解耦 订单系统->物流系统
2.异步 用户注册->发送邮件,初始化信息
3.削峰 秒杀->日志处理
2.跨平台、多语言
3.分布式事务、最终一致性
4.RPC调用上下游对接,数据变动-> 通知下下属
3: 缺点
(1) 系统可用性降低: MQ出现问题怎么办,如何保证消息队列到可用性
(2) 系统复杂度提高: 需要考虑消息重复、丢失、顺序性
(3) 一致性问题: A成功,BC成功,如果D失败,造成数据不一致
主流产品比较
| 对比方向 | 概要 |
| 吞吐量 | ActiveMQ和RabbitMQ万级的,RocketMQ和kafka 十万级甚至是百万级别 |
| 可用性 | 都可以实现高可用。 ActiveMQ和RabbitMQ基于主从架构实现高可用 ;RocketMQ基于分布式架构; |
| kafka也是分布式,一个数据多个副本,少数机器宕机,不会丢失数据 | |
| 时效性 | RabbitMQ 基于erlang开发, 所以并发能力很强,性能极其好,延迟很低,达到微妙级,其他三个都是ms 级 |
| 功能支持 | 除了kafka,其他三个功能较为完备。kafka功能简单,主要支持简单都MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 消息丢失 | ActiveMQ和RabbitMQ丢失的可能性非常低,RacketMQ和kafka理论上不会丢失 |
| 对比内容 | RabbitMQ | ActiveMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 所属机构/公司 | GoPivotal | Apache | Alibaba | Apache |
| 是否开源 | 开源 | 开源 | 开源 | 开源 |
| 技术文档完备 | 高 | 高 | 高 | 高 |
| 快速入门 | 提供 | 提供 | 提供 | 提供 |
| 成熟度 | 成熟 | 成熟 | 成熟 | 成熟 |
| 数据可靠性 | 可靠 | 可靠 | 可靠 | 可靠 |
| 集群 | 支持 | 支持 | 支持 | 支持 |
| 负载均衡 | 支持 | 支持 | 支持 | 支持 |
| 部署方式 | 独立 | 独立 | 独立 | 独立 |
| 客户端支持语言 | 多种 | 多种 | 多种 | 多种 |
| 开发语言 | ErLang | Java | Java | Scala && Java |
| 批量操作 | 不支持 | 支持 | 支持 | 支持 |
| 有序性支持 | 单客户端有序 | 支持 | 支持 | 支持 |
| 管理界面 | 较好 | 一般 | 命令行界面 | 命令行界面 |
| 消息延时 | 微秒级 | 微秒级 | 毫秒级 | 毫秒级 |
| 事务支持 | 不支持 | 支持 | 支持 | 不支持 |
| 社区活跃度 | 高 | 高 | 中 | 高 |
| 商业支持 | 无 | 无 | 阿里云 | 无 |
| 协议支持 | AMQP等多种 | AMQP等多种 | 自定义协议 | 自有协议,HTTP |
| 消息丢失概率 | 低 | 低 | 无 | 无 |
| 可用性 | 主从 | 主从 | 分布式 | 分布式 |
| 单机吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| 部署难度 | 低 | 低 | 低 | 中 |
| 持久化 | 内存、文件,数据堆积影响效率 | 内存、文件、数据库 | 磁盘 | 磁盘,无限数据堆积 |
| 消费方式 | push/pull | push/pull | push/pull | pull |
| 参考: https://hanchao.blog.csdn.net/article/details/99974373 |
注意:部分资料从网络收集整理,若有错误,请指正,多谢。

