数据挖掘复习总结
该掌握的题型有:
1、熟练计算支持度和置信度
计算支持度方法如下:

计算置信度方法如下:

例子如下:
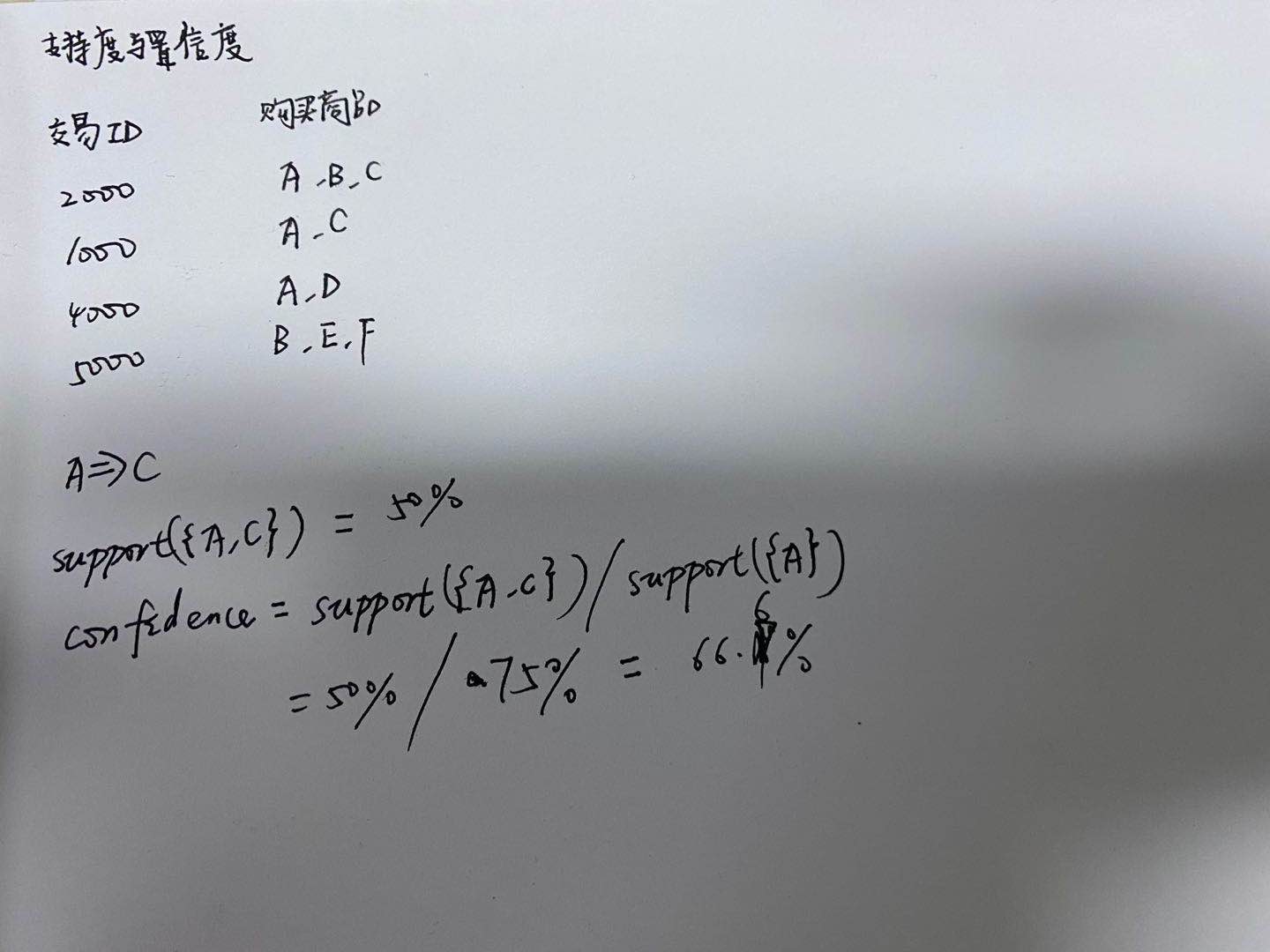
2、运用Apriori算法求频繁挖掘项集
方法如下:

例题如下:
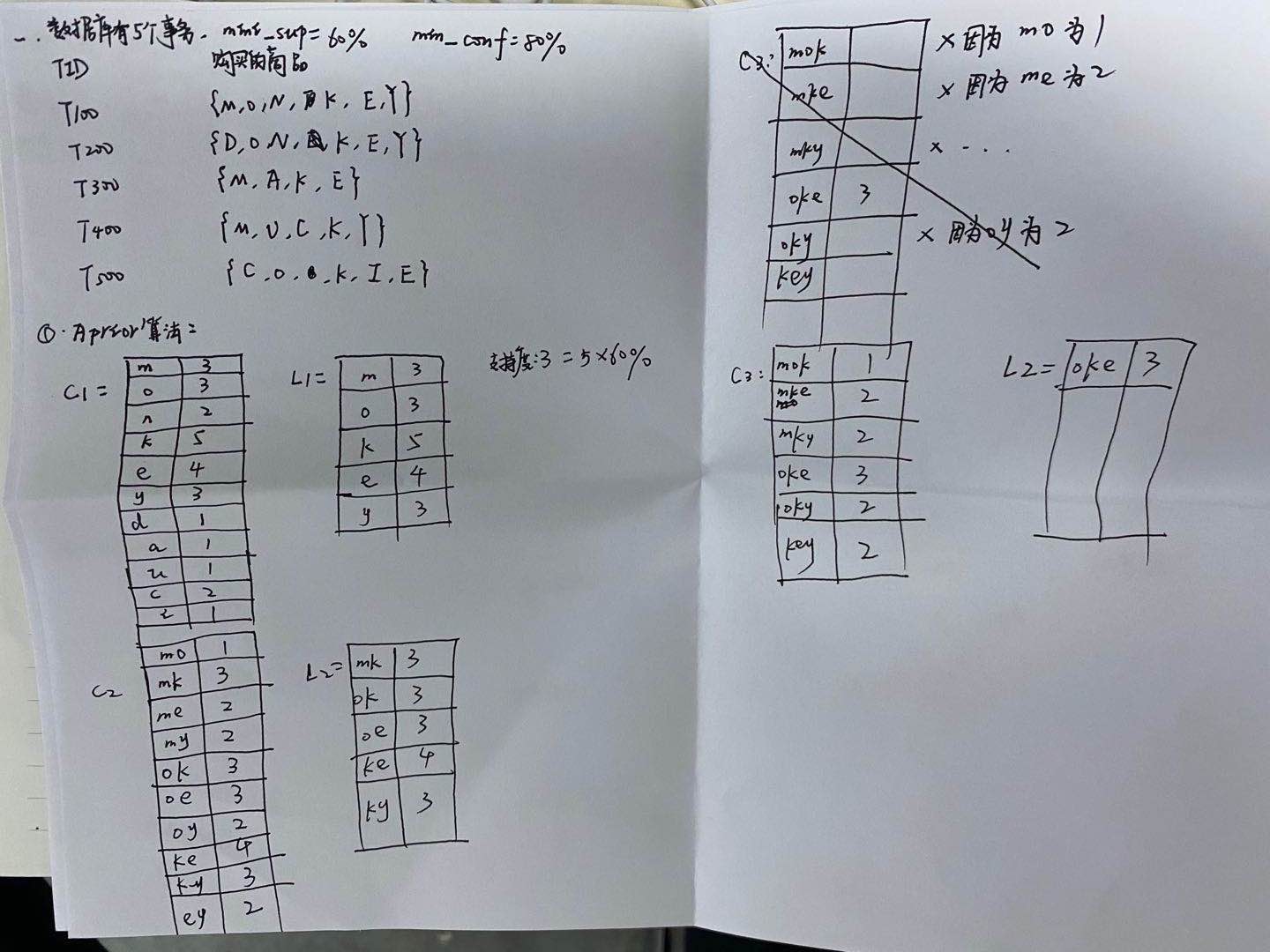
3、运用FP-growth算法求频繁挖掘项集
方法如下:

例题如下:
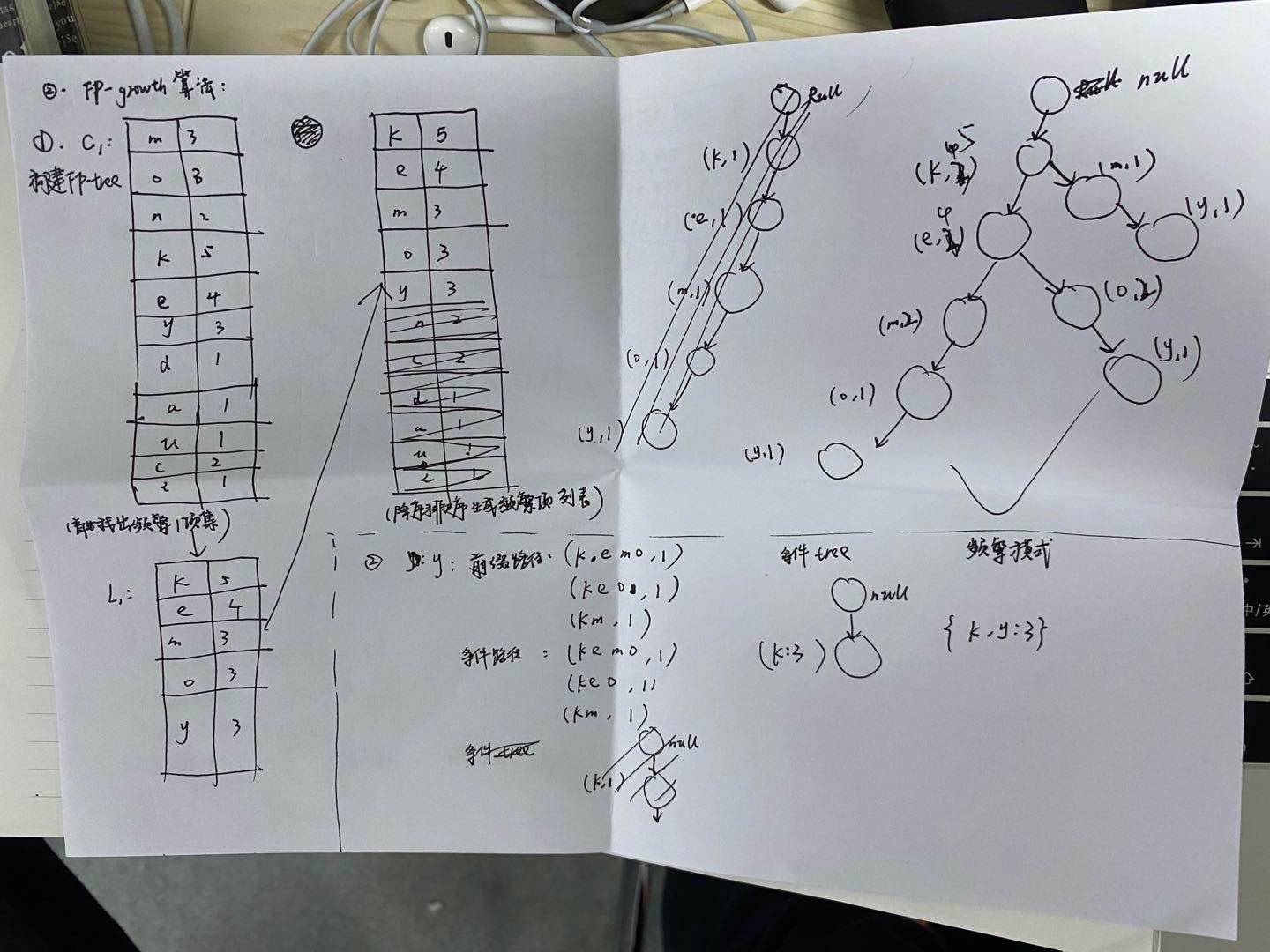
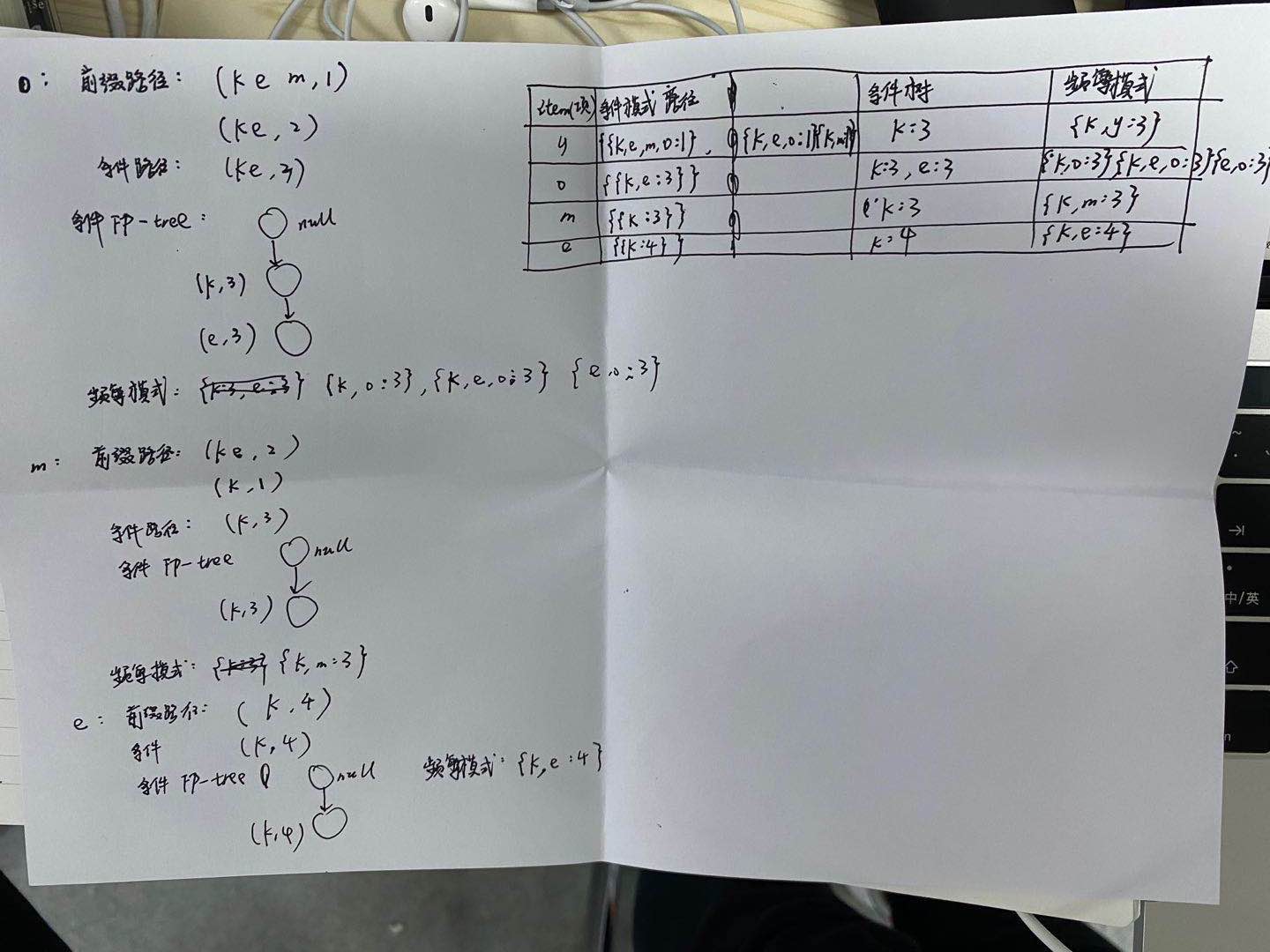
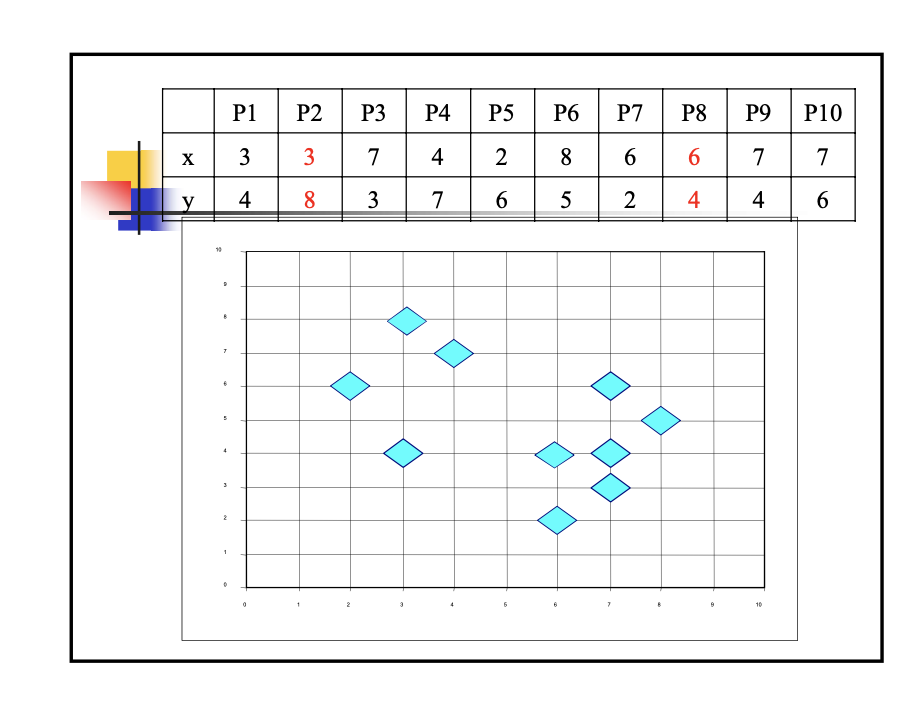
4、运用k-means算法进行相关题目的计算

例题如下:

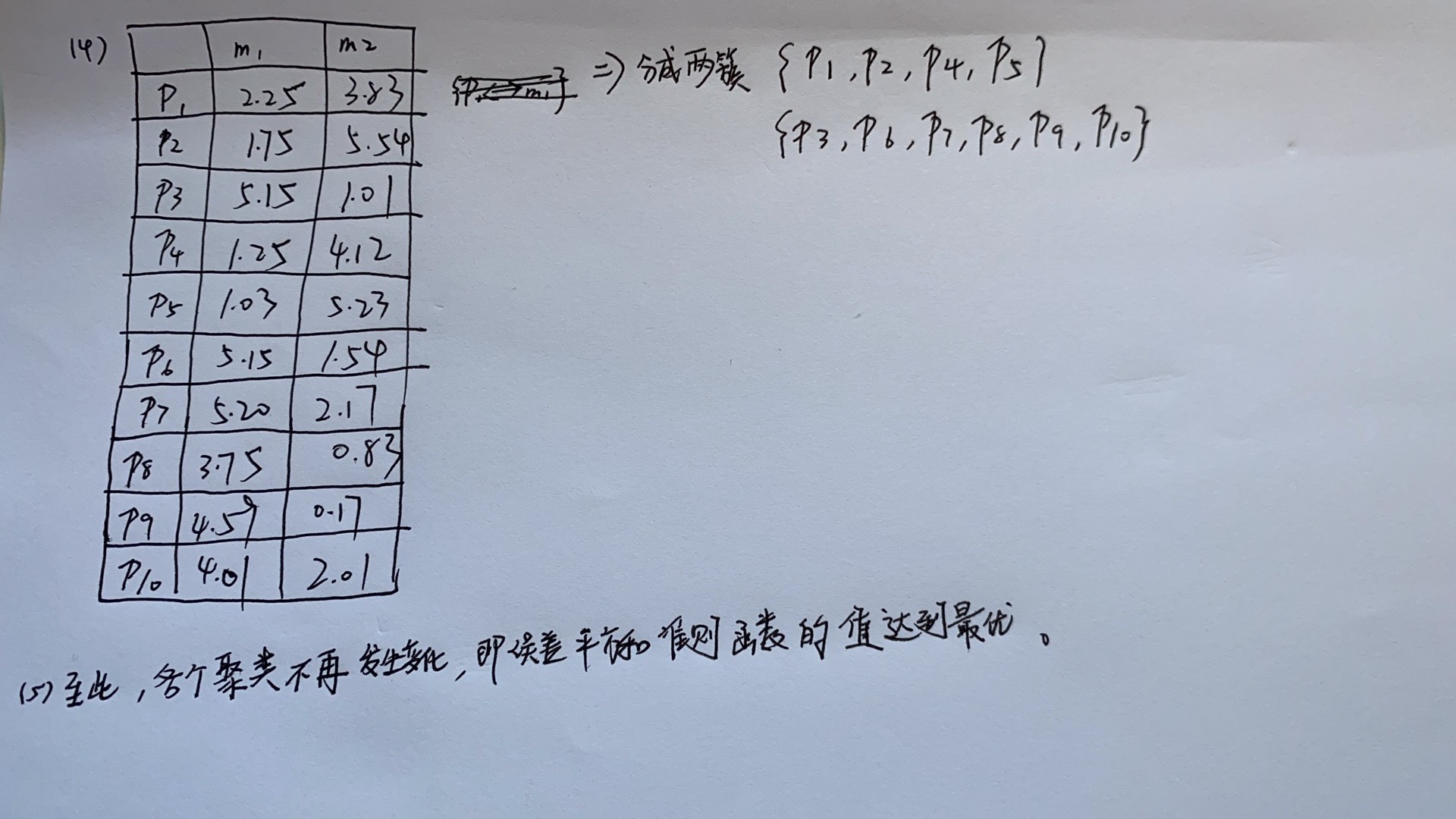
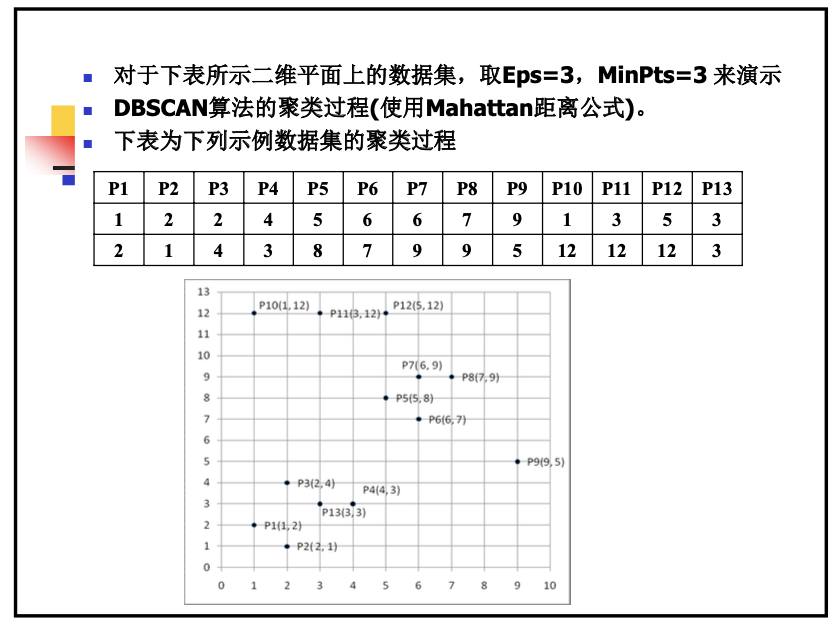
5、运用DBscan算法进行相关关题目的计算


例题如下:

6、贝叶斯朴素算法的相关计算
公式:
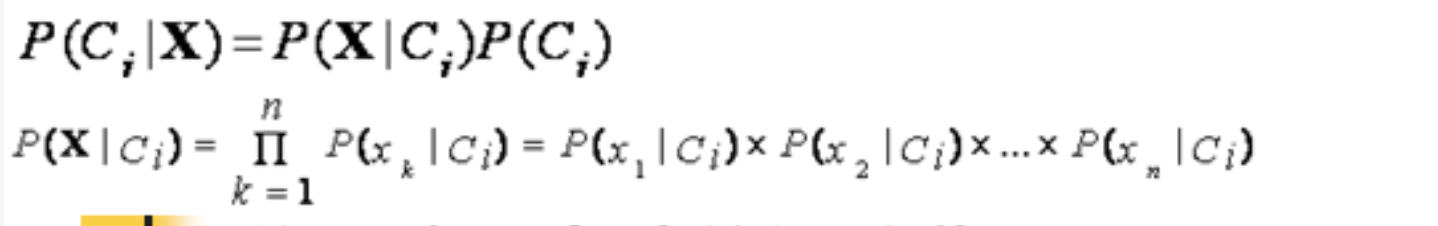
例题如下:
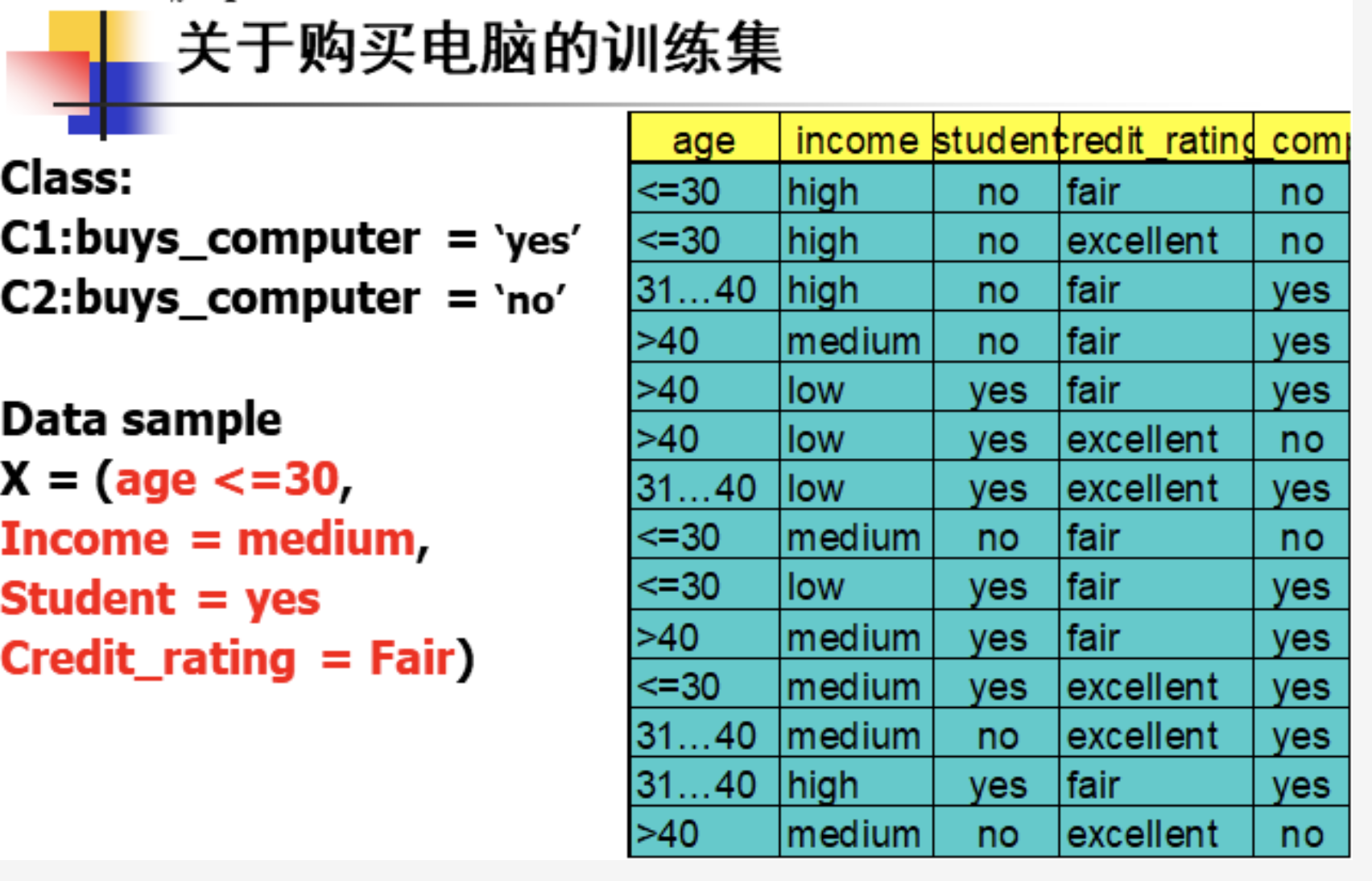

7、决策树相关计算
信息增益相关计算:
公式一:
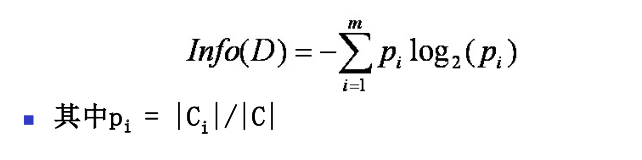
公式二:
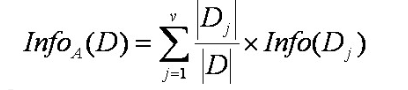

信息增益计算公式:
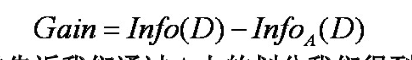
例题如下:
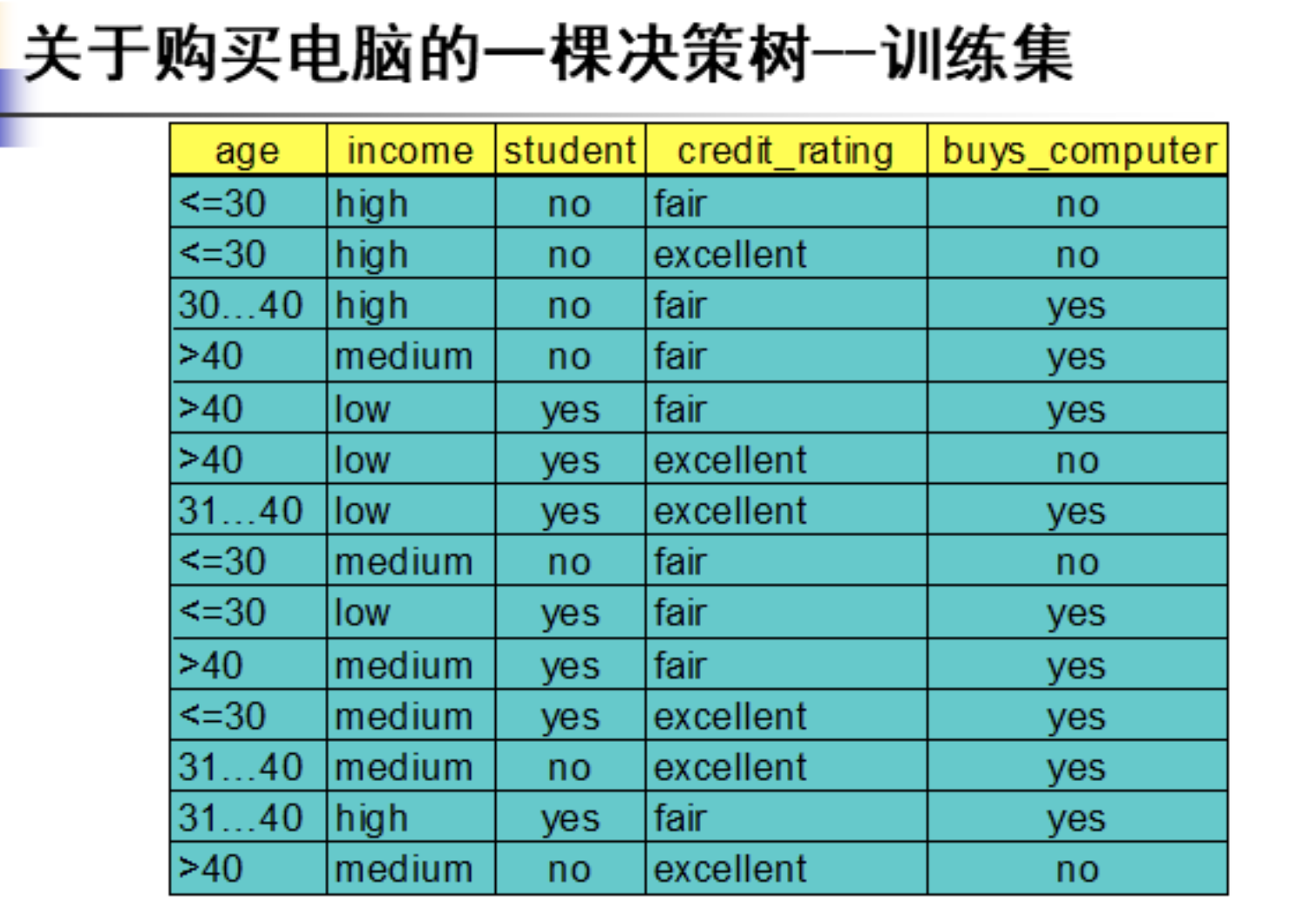


信息增益率:
公式一:
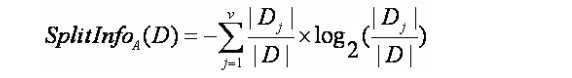
公式二:
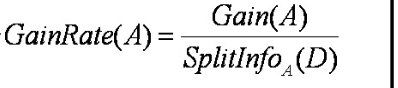
例题如下:
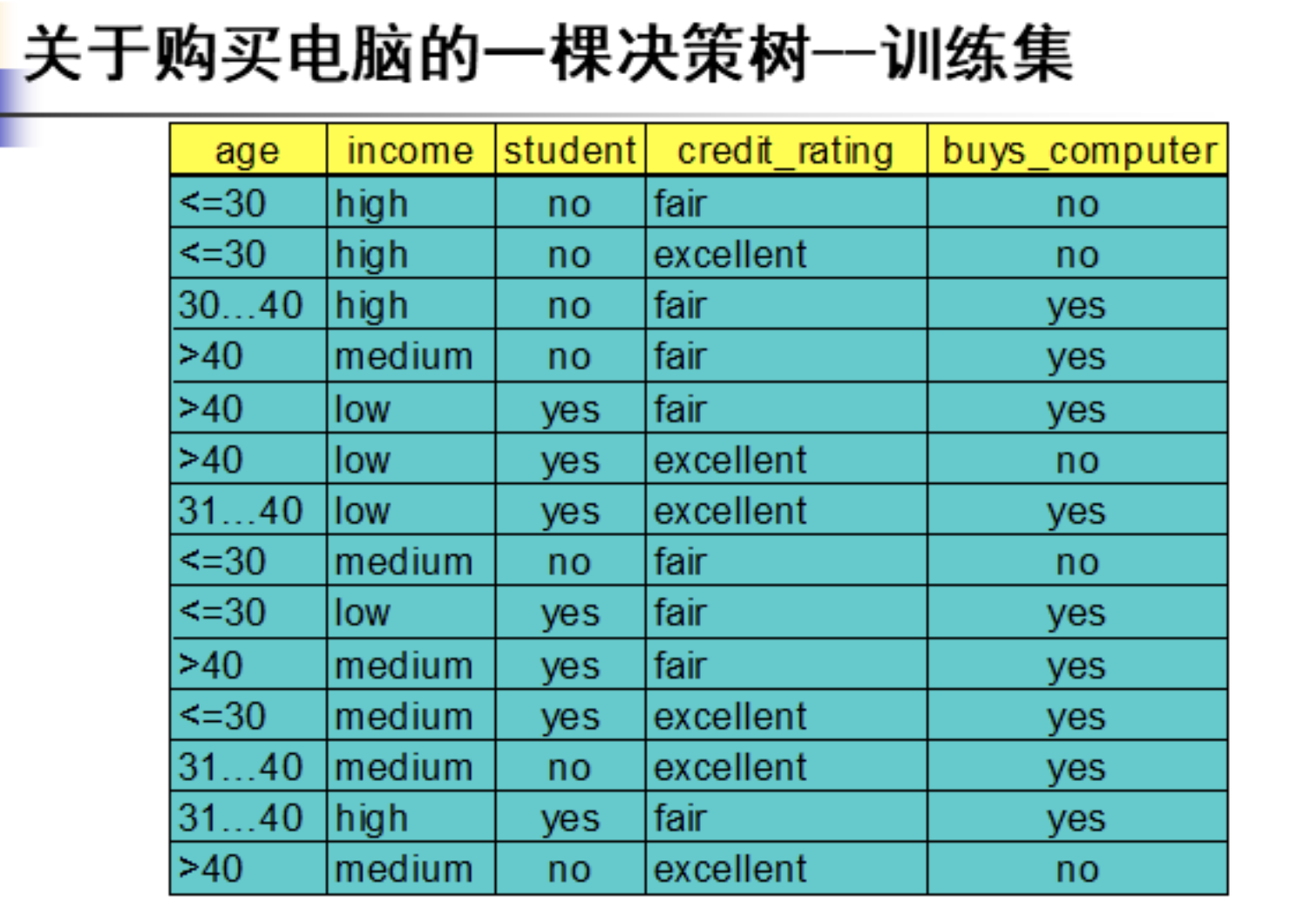

gini指数:
公式一:
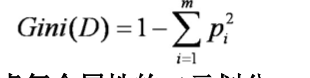
公式二:
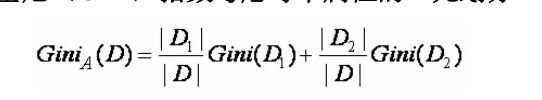
公式三:
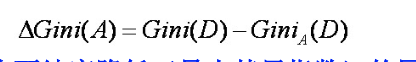
例题如下:
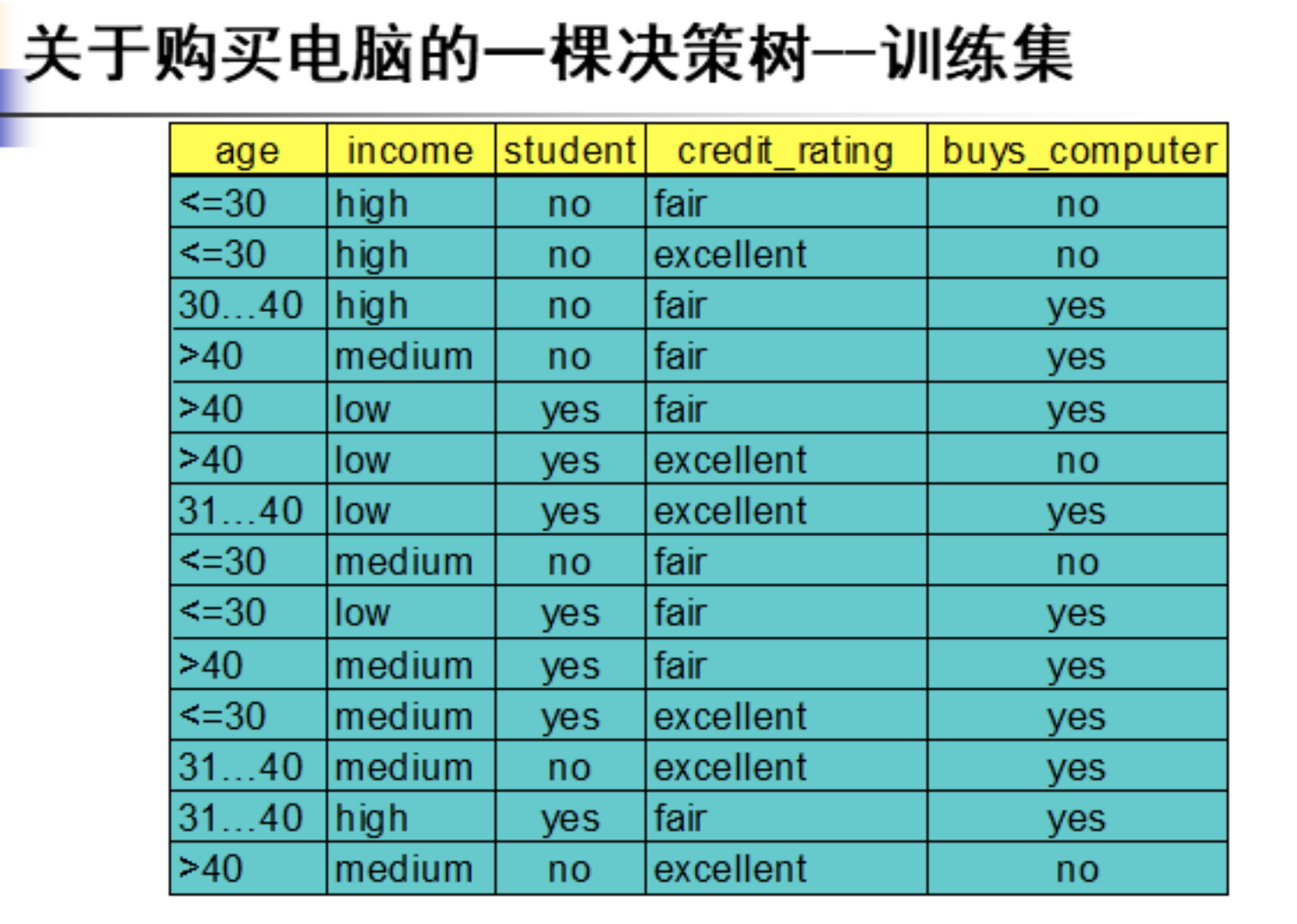



8、度量各种数据的相异性和相似性
题型一:标称属性的邻近度量

例题如下:

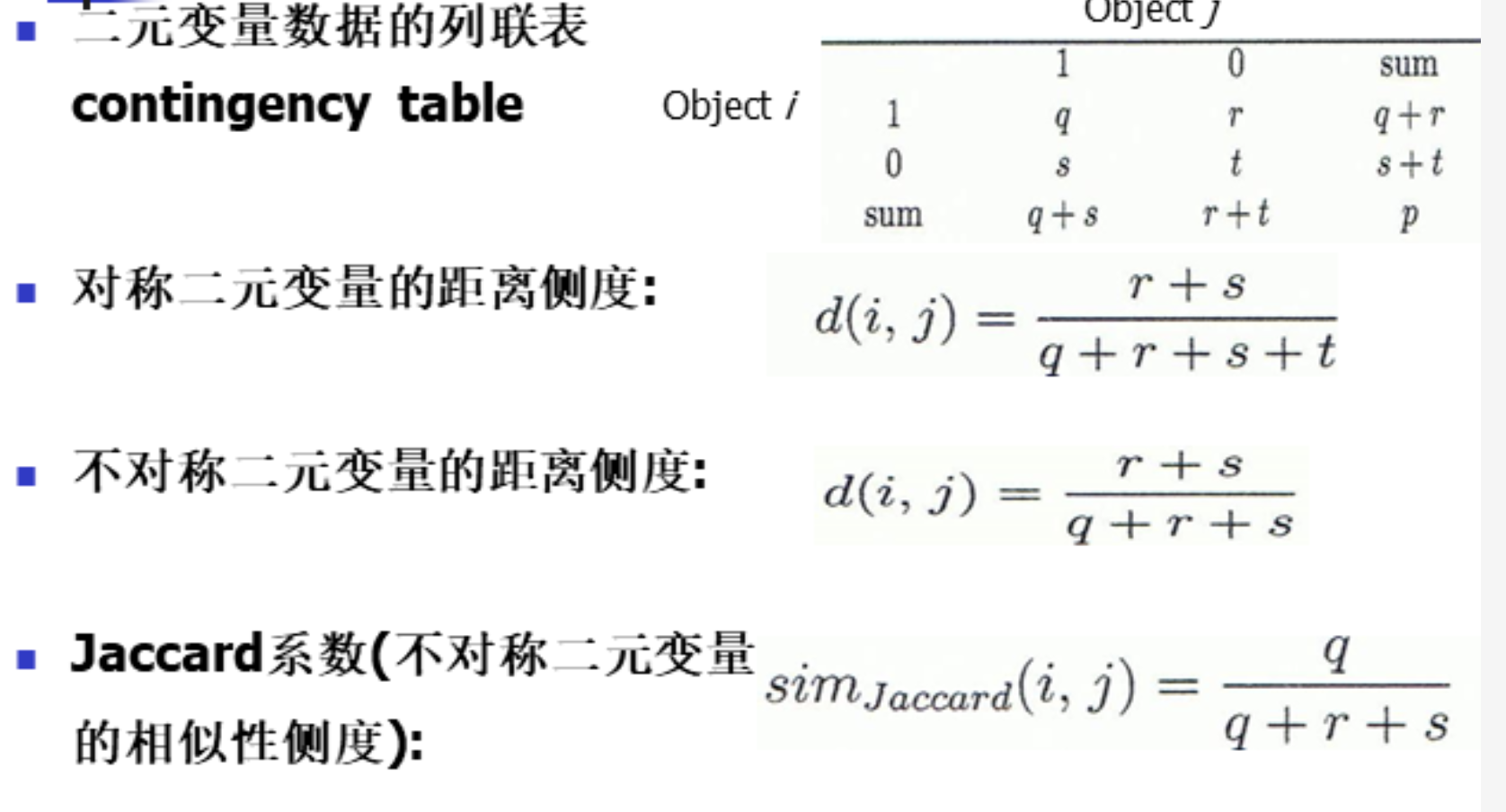
题型二:二元属性的相异度量

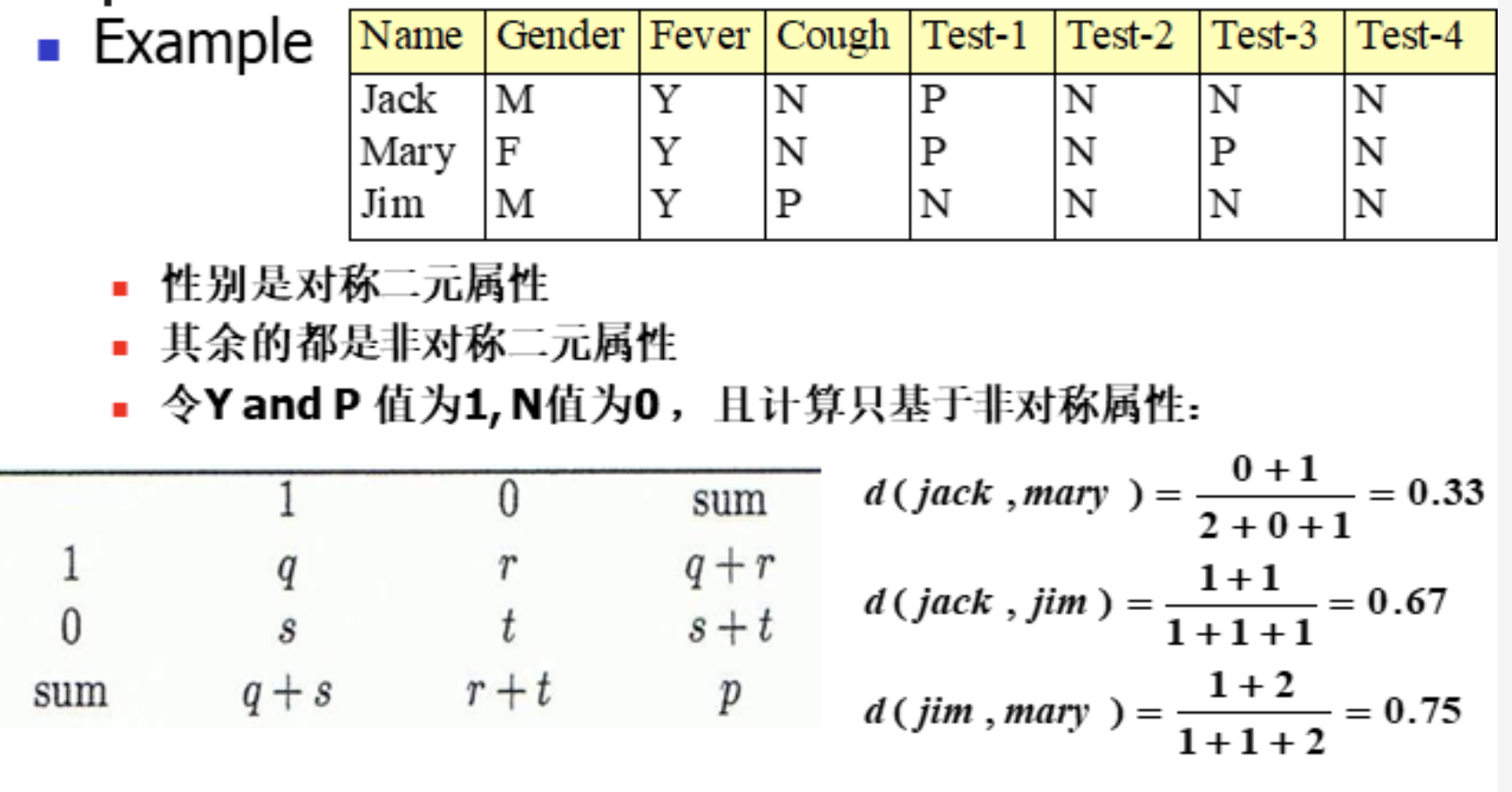
例题如下:
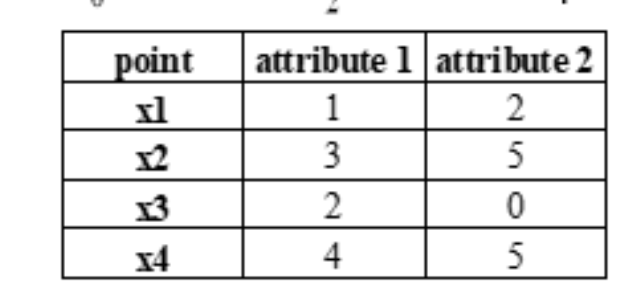
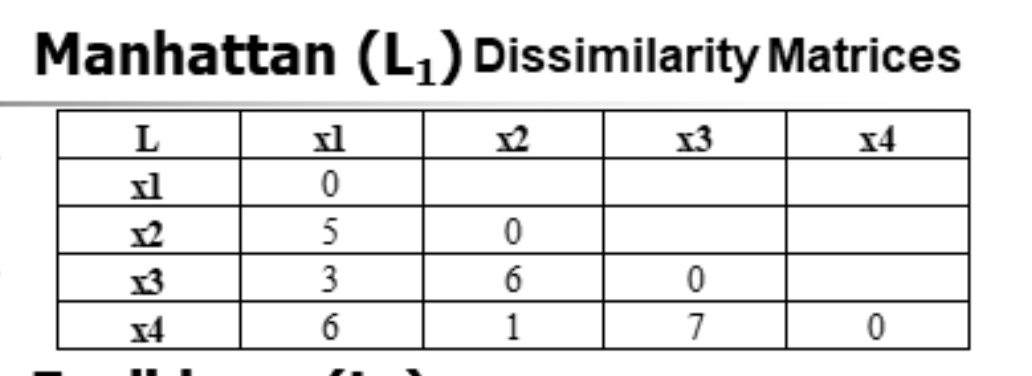
题型三:曼哈坦距离

例题如下:
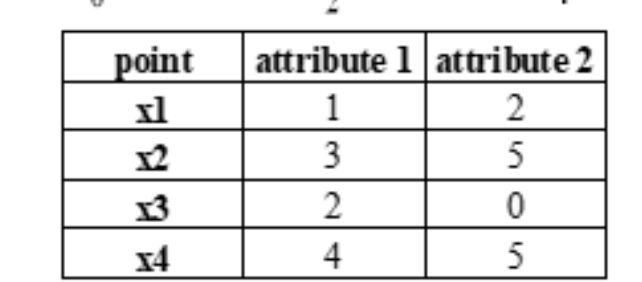
题型四:欧几里得距离

例题如下:
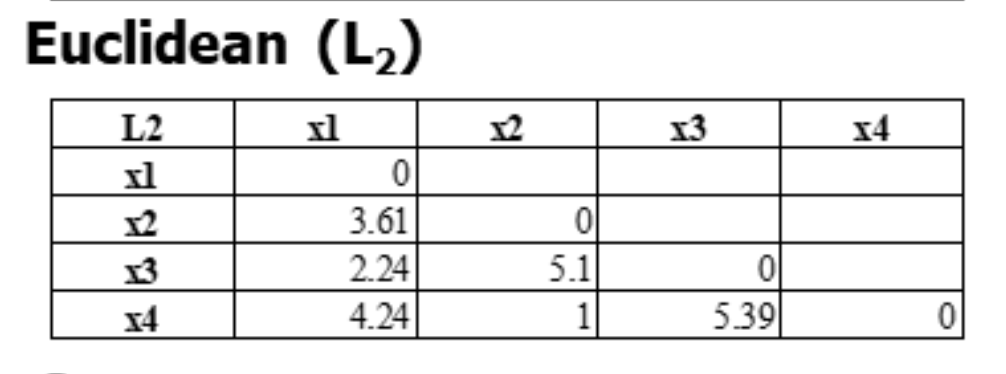
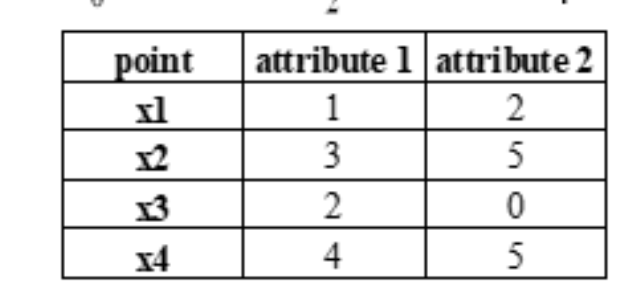
题型五:上确界距离

例题如下:
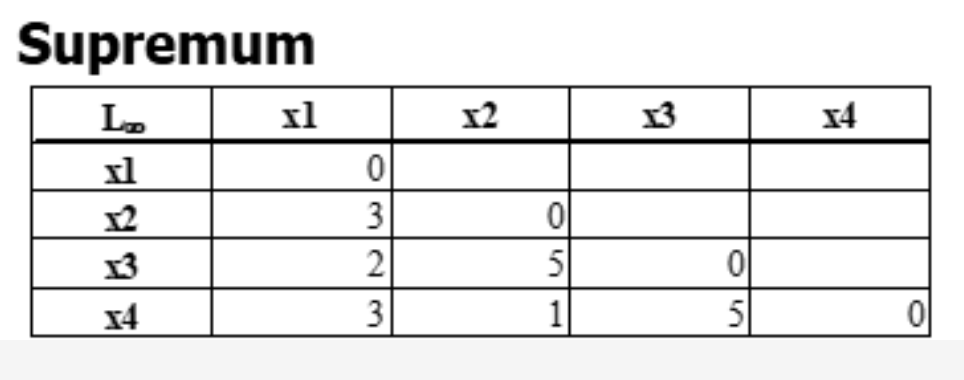
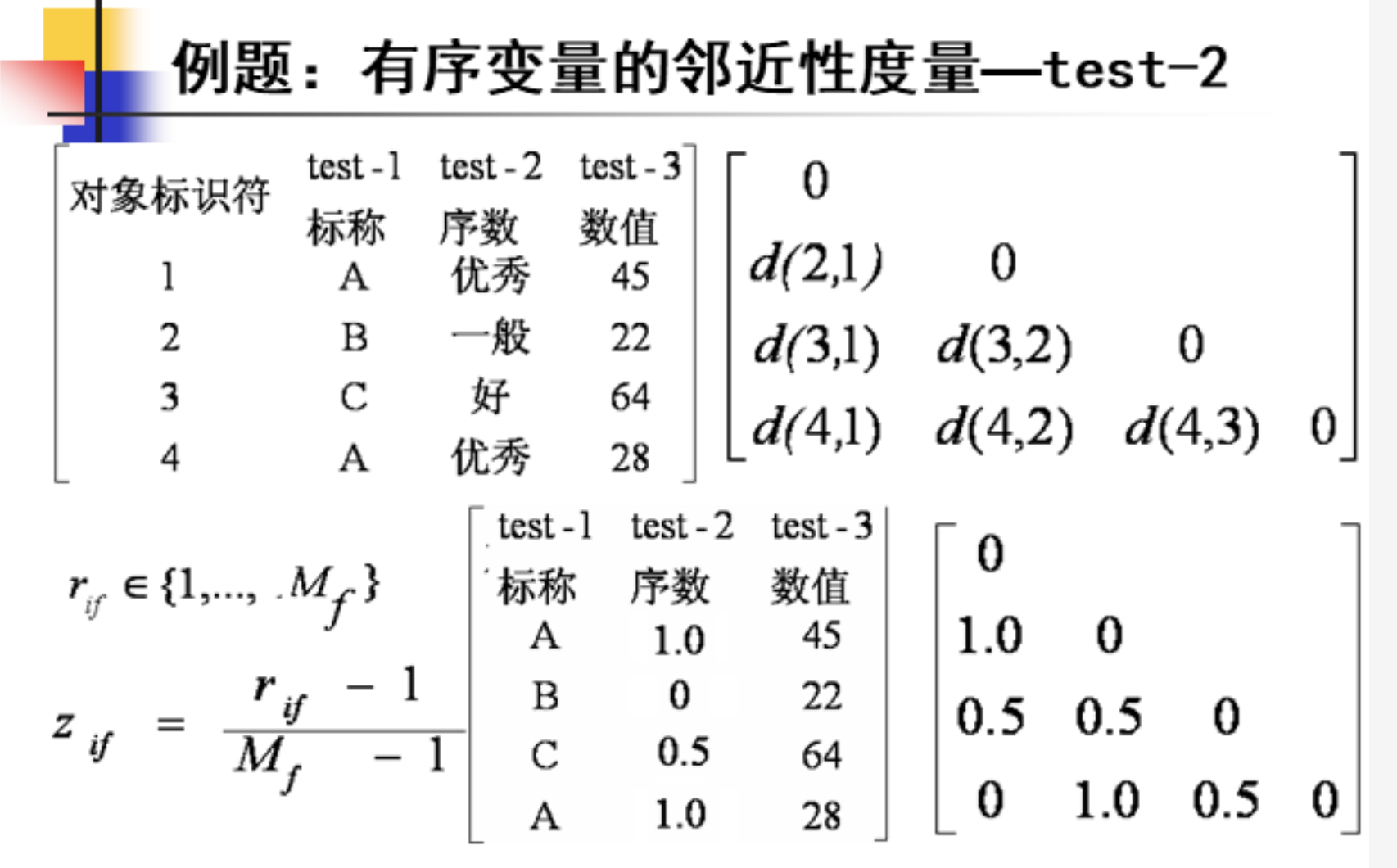
题型六:有序变量的邻近性度量

例题如下:
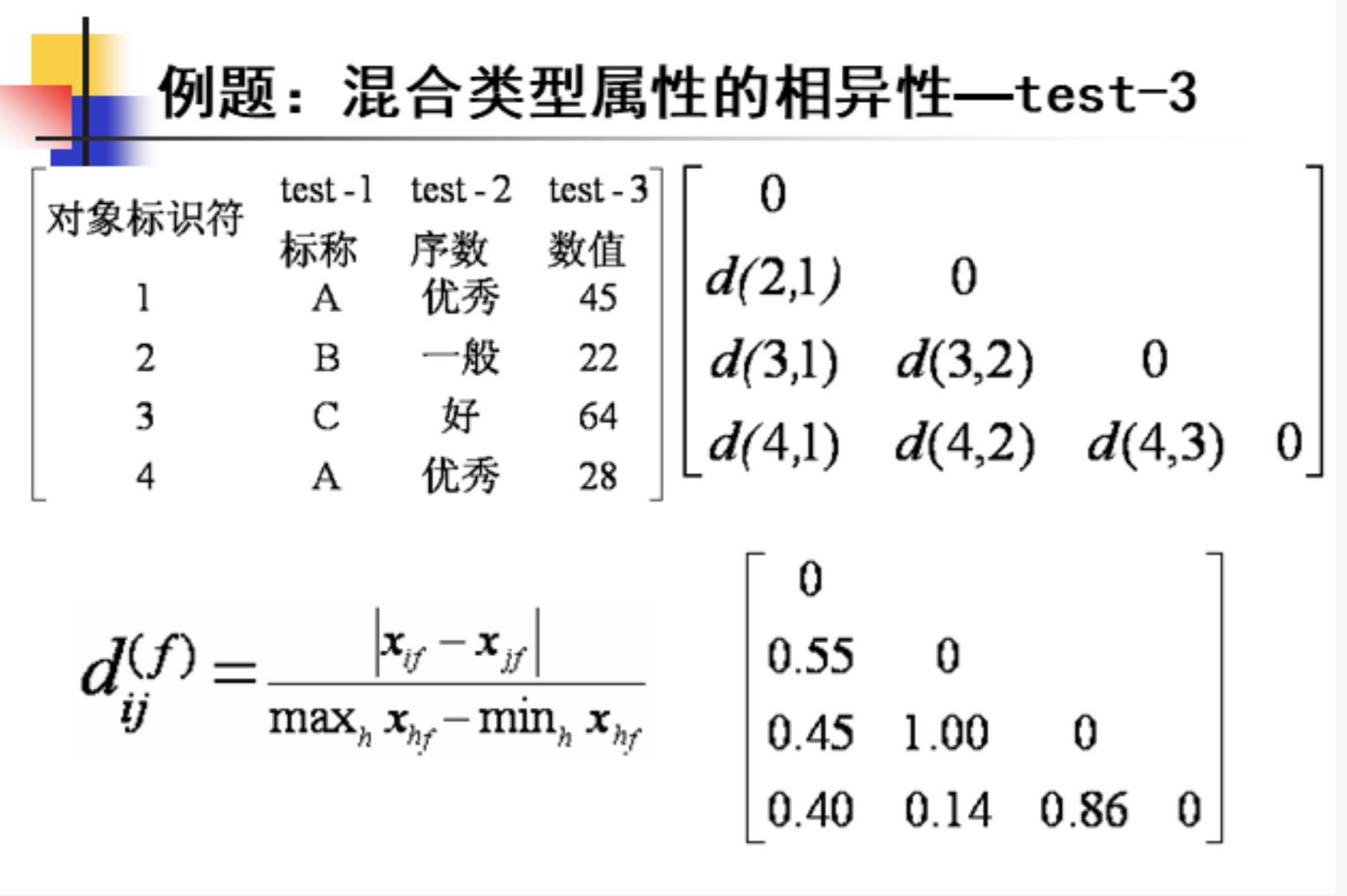
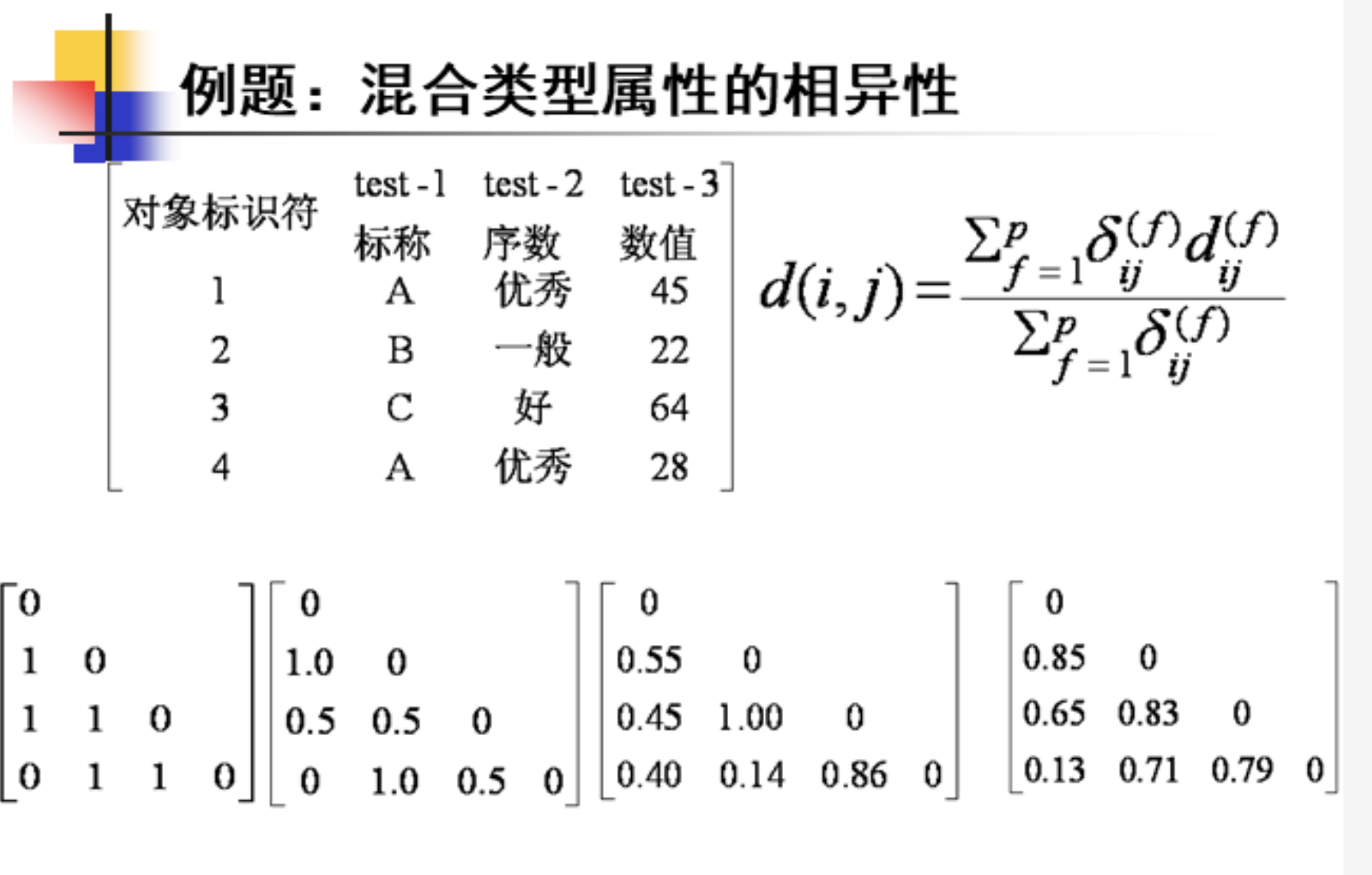
题型七:混合类型属性的相异性

例题如下:
题型八:余弦相似性

例题如下:

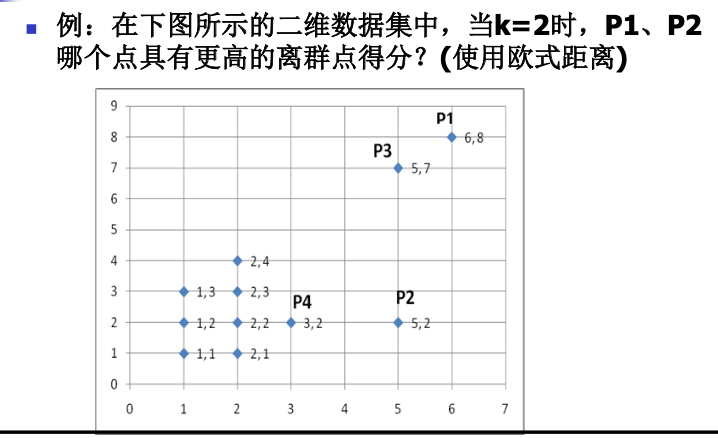
题型九:基于距离的离群点检测

例题如下:
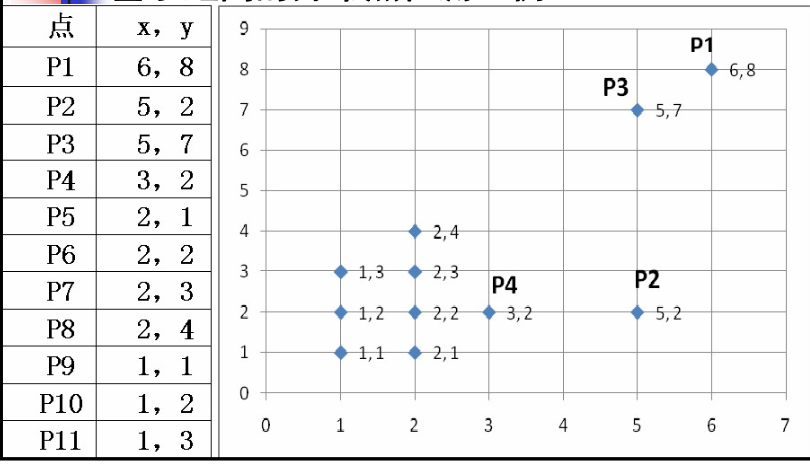

题型十:基于聚类的离群点检测
离群因子定义一计算方法:
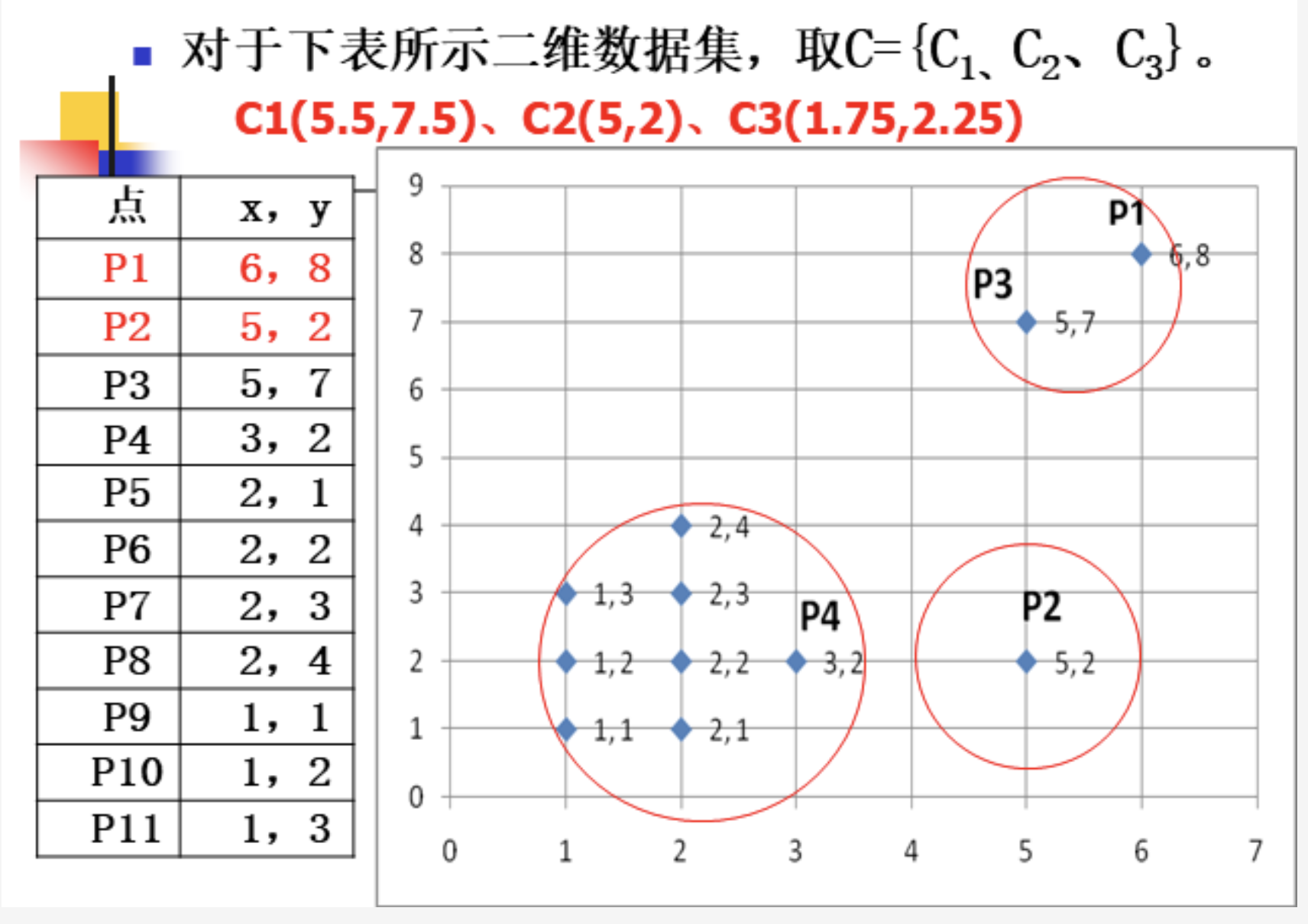


离群因子定义二计算方法:
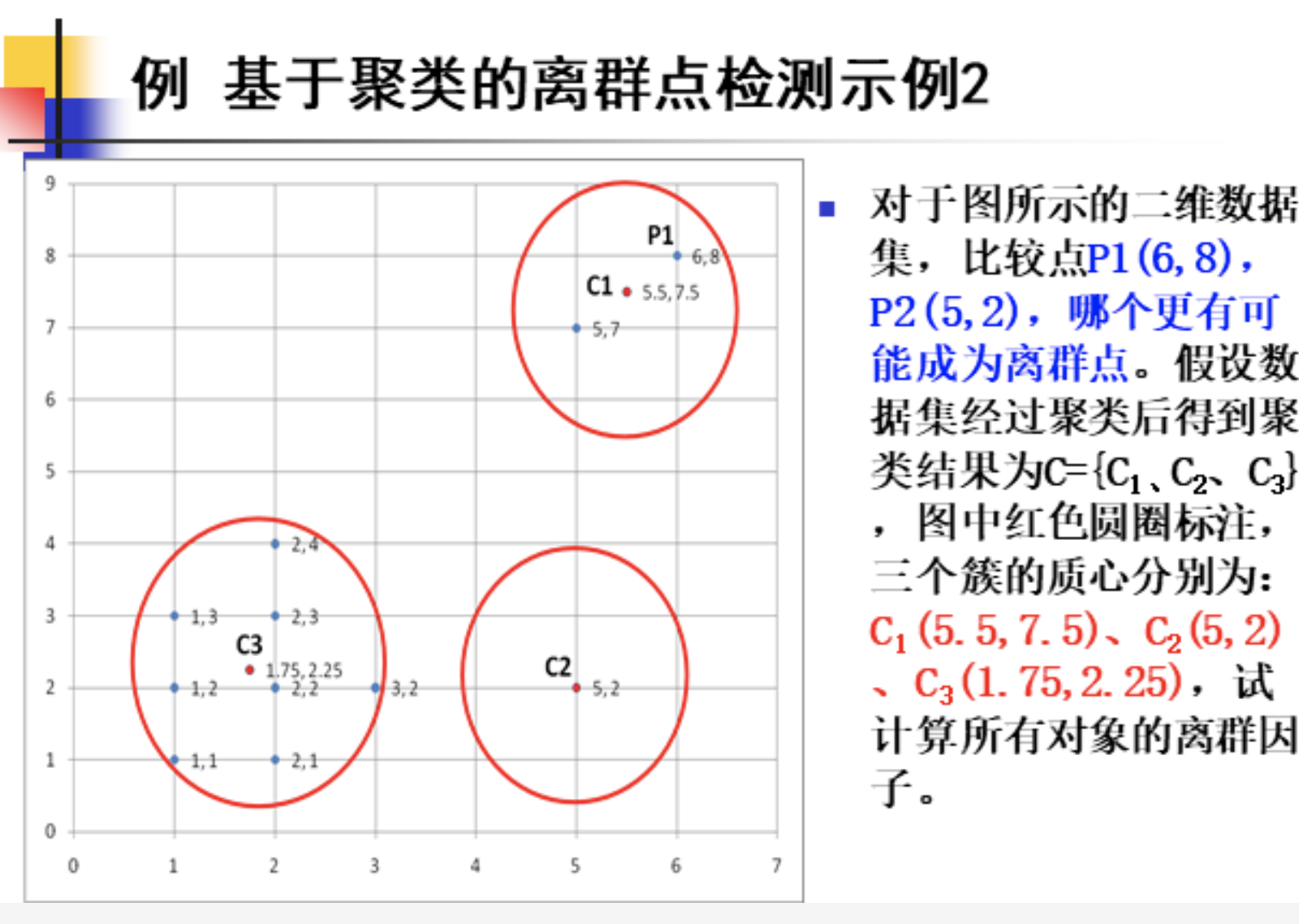
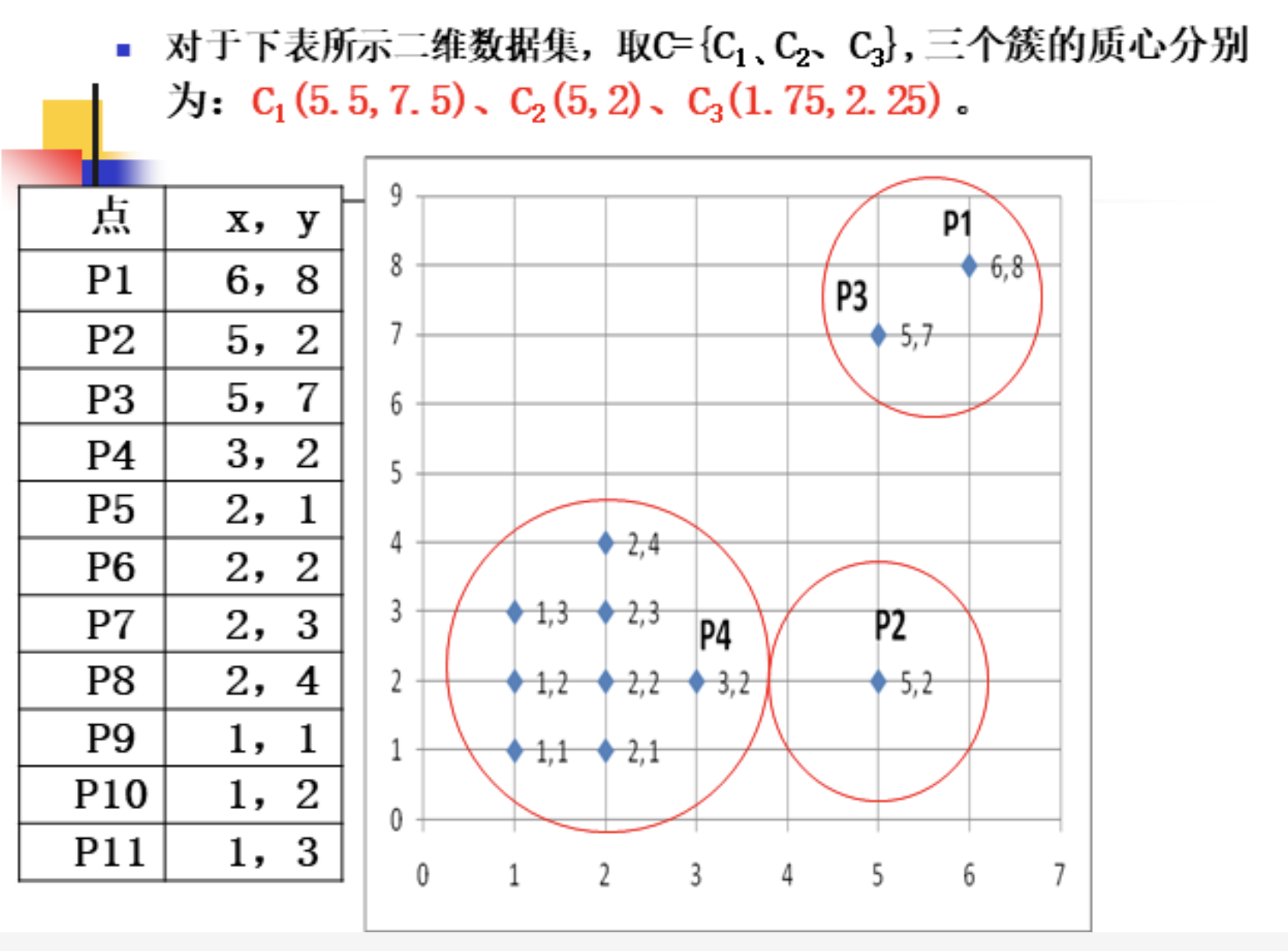

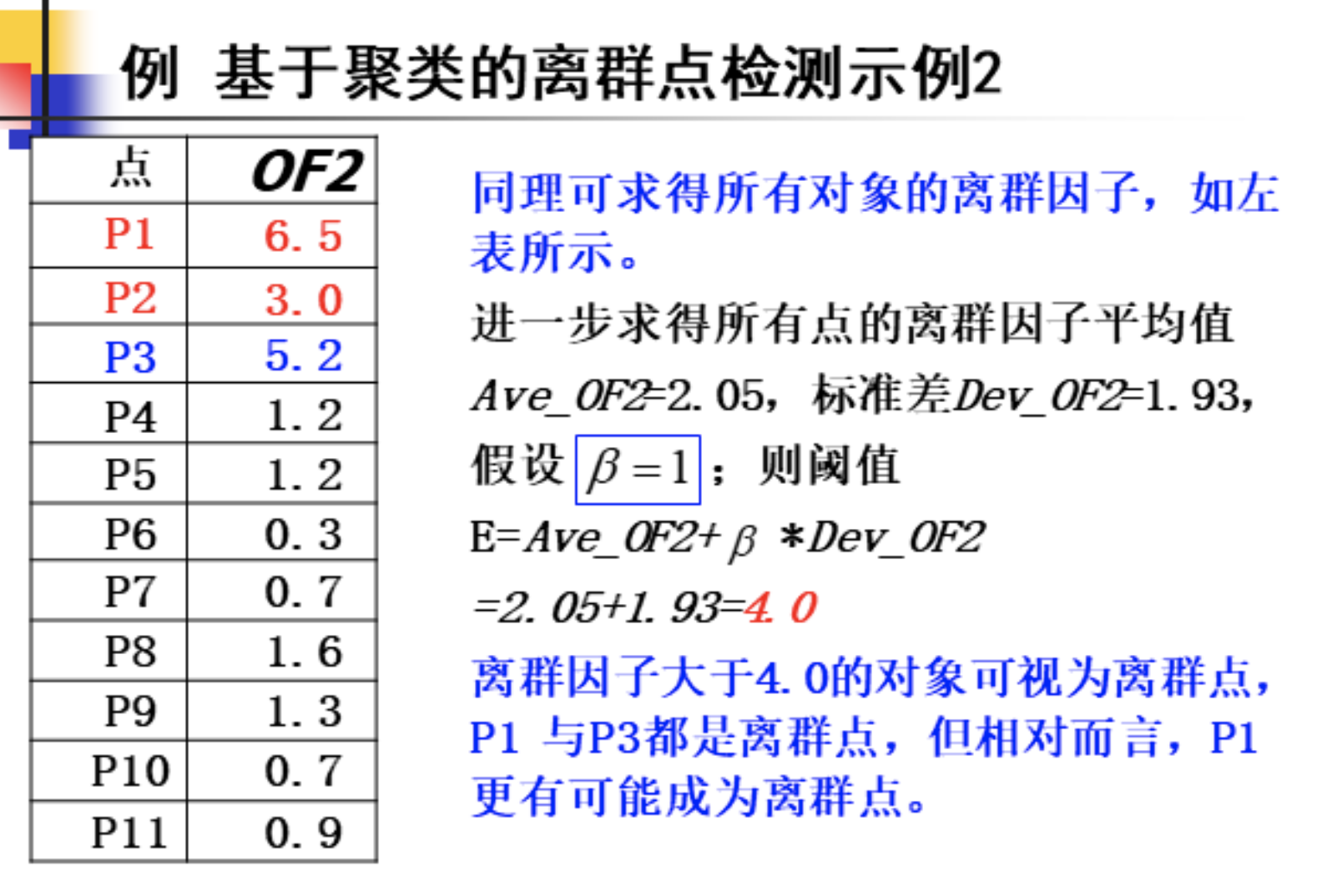
离群因子定义三计算方法:



