


正则表达式
正则表达式非常强大,学好不易,需要经常用。
入门前先安装一个小工具:Match Tracer 下载地址:http://www.regex-match-tracer.com/
- RegexBuddy(更好用):http://www.regexbuddy.com/download.html
下面分点学习,并结合小工具练习。
一、常见元字符:
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \W | 匹配不是字母、数字、下划线的字符 |
| \d | 匹配数字, 相当于[0-9] |
| \D | 匹配不是数字的字符 |
| \s | 匹配任意不可见字符, 包括空格、制表符、换行符等 |
| \S | 匹配任意可见字符 |
| ^ | 匹配字符串的开始位置 |
| $ | 匹配字符串的结束位置 |
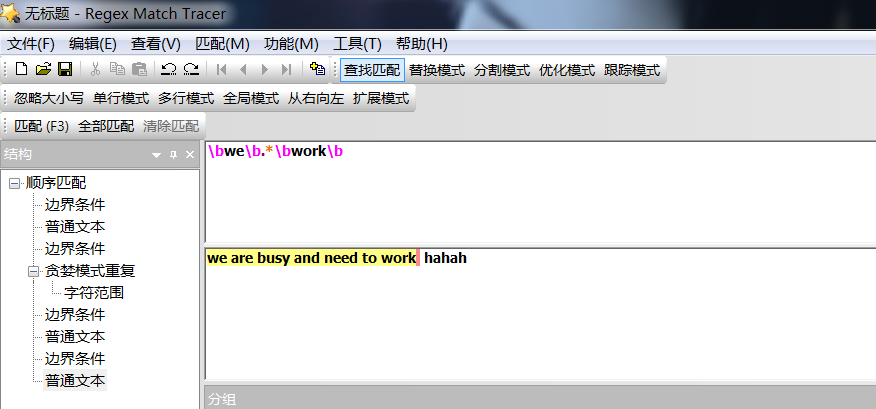
二、字符转义
- 比如你想找.和\或者*,这时你需要写成\. \\ 和 \*
三、重复
| 元字符 | 含义 |
|---|---|
| * | 重复任意次, 相当于 |
| ? | 重复0次或1次, 相当于 |
| + | 重复1次或更多次, 相当于 |
| 重复n次 | |
| 重复n次或者大于n次 | |
| 重复n到m次 |
四、字符集合
上面介绍的元字符,可以看到查找数字、字母或数字、空格是很简单的因为有了对应的这些字符的集合,但是,如果想匹配a b c d e中任意一个字符,这就自定义字符集合。
- 正则可以通过[ ]来实现自定义字符,[abcde]就是匹配abcde中任意一个字符,【.?!】匹配标点符号(. ?或 !)。甚至可以这样[0-9a-zA-Z]
五、分支条件
满足几种匹配规则,则可以使用'|'把不同规则分开。例如带区号的电话(可能7位,可能8位):010-66887144,使用分支条件:0\d{2}-\d{8}|0\d{2}-\d{7}
六、分组
例如 想匹配IP地址,单纯((\d{1,3}).){3}\d{1,3},会出现匹配到333.444.555.111这种不存在的ip,这时候就需要用到分组。下面给出完整IP地址分组表达式
-
IP表达式:((25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d).){3}((((25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d))。
-
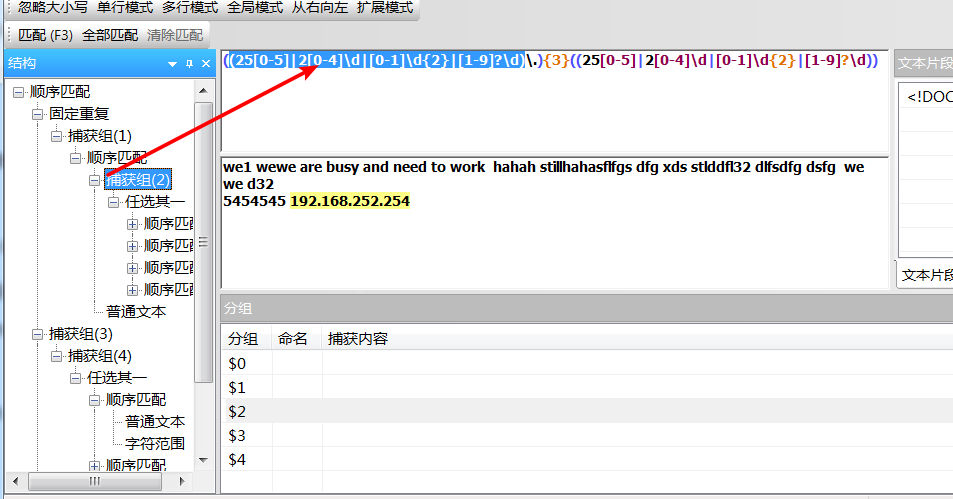
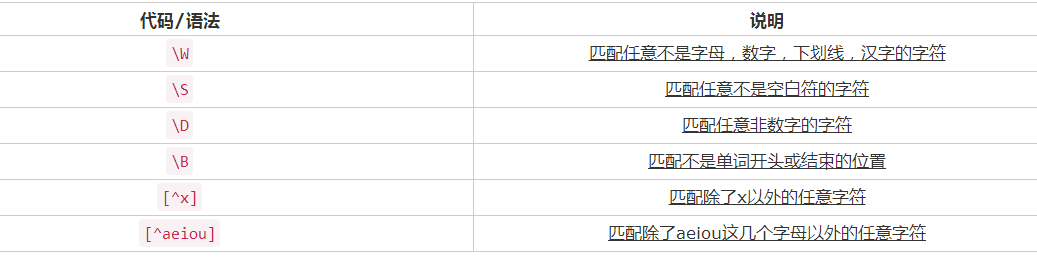
七、反义
八、向后引用
- 前面我们讲到了分组,使用小括号指定一个表达式就可以看做分组。默认情况下每个分组会拥有组号,规则:从左向右,以分组的左括号为标志,
九、注释
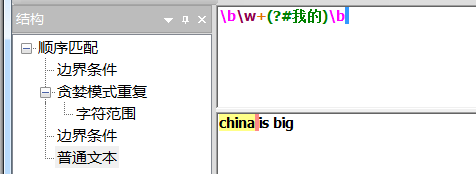
- 正则表达式可以包含注释进行解析说明,通过语法(?#comment)来实现,例如\b\w+(?#字符串)\b。要包含注释的话,最好的是启用"忽略模式里的空白符"选项,这样在编写表达式时任意添加空格、Tab、换行、而实际使用这些都将被忽略。
十、贪婪与懒惰
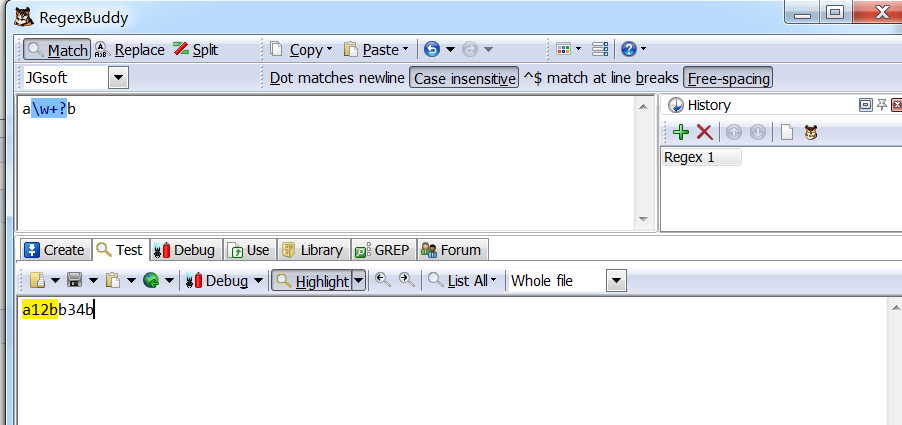
- 当正则表达式包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符,这就是贪婪模式。以表达式a\w+b为例,如果搜索a12b34b,会尽可能匹配更多的个数,最后就会匹配整个a12b34b,而不是a12b。但是如果想匹配出a12怎么办?这就需要懒惰模式,尽可能匹配个数较少的情况,因此需要改写成:a\w+?b,使用?启动懒惰模式。
| 语法 | 含义 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
十一、一般正则表达式的实现库都提供了用来改变正则表达式处理选项的方式,
| 名称 | 说明 |
|---|---|
| IgnoreCase(忽略大小写) | 匹配时不区分大小写。 |
| Multiline(多行模式) | 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) |
| Singleline(单行模式) | 更改.的含义,使它与每一个字符匹配(包括换行符\n)。 |
| IgnorePatternWhitespace(忽略空白) | 忽略表达式中的非转义空白并启用由#标记的注释。 |
| ExplicitCapture(显式捕获) | 仅捕获已被显式命名的组。 |
