<Linux内核源码>文件系统VFS内核4.0.4版本基本概念源码
题外话:Linux内核从2.x和3.x到现在最新的4.x变化非常大,最直观的表现就是很多书上的内核代码已经无法直接继续使用,所以看看新的源码是非常有意义的!
(下文中的内核源码都来自于 kernel 4.0.4 版本,本人都验证过正确,正文假设读者对 linux系统下mount命令有操作经验。另外,linux内核源码中关于文件操作的代码量比内存管理或者设备管理多了不止一个数量级,所以想要把每一 个地方完全说清楚是远在我能力之外的..这篇文章的意义就是帮助建立起来一个超级块,索引和目录的有层次的模型。以下的代码中我尽量保留了源码中的英文注 释,然后对于比较重要的部分都进行了翻译注解)
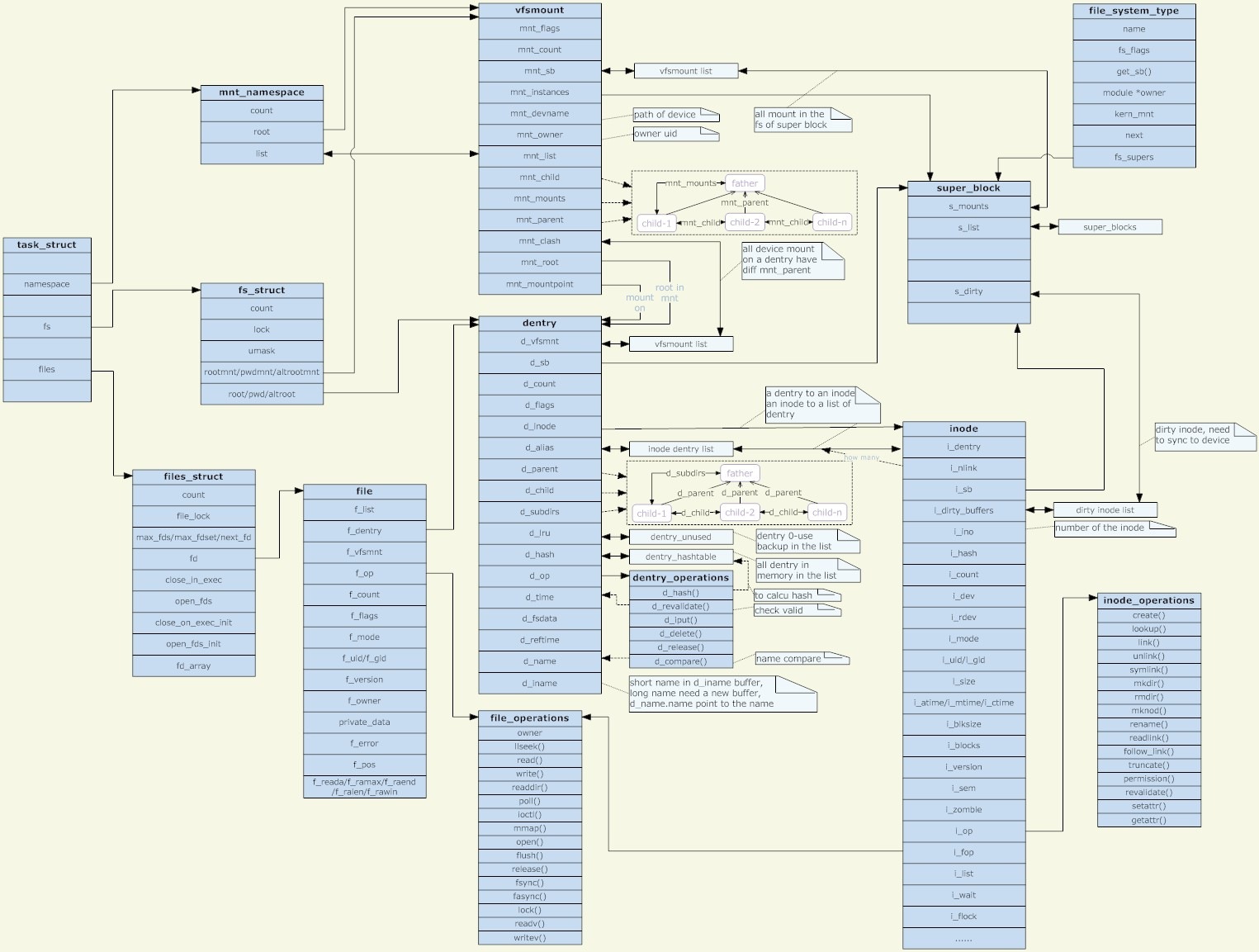
一. VFS(Virtual File System)处理文件系统挂载最基本的数据结构---vfsmount
vfsmount 这个结构体的功能不深入讨论,但是必须清楚的一点是每个文件系统都有一个这样的结构。首先必须要知道这个结构体是做什么用的,当文件系统要进行挂载工作的 时候,是与之对应的vfsmount结构体被添加到内核之中的一个全局链表---mount_hashtable数组链表之中。 mount_hashtable是个数组,每一个成员都是一个hash链表,例如在进行文件搜索的时候,遍历到一个“特殊的目录“(比如U盘挂载的目录) 时,就会进行从mount_table找到对应的链表头部,再遍历整个hash链表直到找到与之对应的vfsmount结构,然后将该特殊目录的目录结构 体dentry(下文详述)进行替换,使之成为新文件系统的根目录。如下是vfsmount结构体:
(一些较早的vfsmount结构体成员定义有十几个但是这里就只剩下了3个成员)
二. 文件系统“三大元老”
(1)super_block超级块
超级块代表了整个文件系统的本身,一般来讲,超级块与vfsmount虽然一样是和整个文件系统一一对应的关系,但是super_block负责的是控 制的部分,而vfsmount单纯是挂载方面。这些在之后的文件操作之中详细再说,超级块和下面要说的索引结点和目录结点都是运用了C语言来实现面向对象编程, 用一个结构体来作为C++中的虚表或者JAVA中的接口。超级块结构体保存的是文件系统设定的文件块的大小,超级块的操作函数,和整个文件系统中的所有索 引结点。不同文件系统的控制会包含不同的控制信息,而super_block结构体保存了这些我们需要的结构体信息。super_block结构体的每个 成员都是推荐理解而不是强记,一是容易忘记,二是版本迭代太快,当然除非工作需要~
 View Code
View Code
附:file_system_type结构体,可以跳过
View Code
(2)目录结点 dentry
文 件系统一般是以树状结构进行管理的,目录是最直观的表现,所有的目录一层一层组织,最终汇聚于根目录。对于这个树状结构是用dentry结构体进行组织 的。正如在linux中目录本身也是一个特殊的文件。每一个文件都一个dentry,这个dentry都被递归地链接到上层,直到根目录。为了加快进行查 找的速度,内核同样使用了hash表来缓存dentry,被称作dentry cache,这个数据结构使用的非常的频繁,因为往往要反复对同一个文件继续操作,如果每次操作都需要在文件系统中进行一次搜索的话时间代价是非常高的, 所以大部分的遍历查找dentry之前都要先对dentry cache内进行查找。
View Code
(3)索引结点对象 inode
索引结点对象和目录结点对象的最大不同在于:目录结点对象指的是逻辑意义上的文件,而索引结点对象指的是物理意义上 的文件,目录项在磁盘上并没有与之对应的映像,而每个索引节点在磁盘上都个与之对应的映像。inode就代表了一个文件,inode保存了文件的大小,创 建时间,文件的块的大小等参数,因为指向文件的路径可以有多个(比如ln命令产生的文件),而inode只有一个!inode结构和文件系统是无关 的,inode在文件的整个生命周期都存在,而且包含了磁盘上的维护的数据。
View Code
三. 内核中的文件对象 file
这个结构体实际上是和vfs架构没有联系的,只是在linux内核之中的文件对象,每当打开一个文件,内核之中就会创建一个对之相关联的file结构,并且传递给文件上进行操作的任何函数。在文件的所有实例都被释放了之后,内核中的file结构也就会被释放。
View Code
总结归纳:
(1)vfsmount,super_block,dentry,inode 结构在内核之中都有一个全局的hash表缓存用来加快访问的速度,每个hash数组存着hash链表将相同种类的结点种类放在同一个链表中,并专门设置一 个成员变量用来访问在hash链表中与之相邻的结点。
(2)file和dentry更多是逻辑意义上的,super_block和inode更多是物理意义上的。
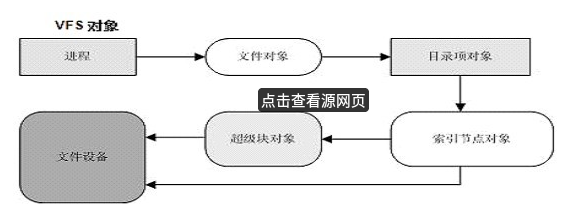
(3)最后献上一张图,个人认为是总结linux文件系统结构最全面的一张图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号