常用性能调优策略及在风控场景下应用
 性能调优也是有迹可寻的,本文梳理了在实际开发过程中沉淀的通用性能优化策略,并且结合风控系统服务内使用场景,帮助读者理解性能调优相关可行策略,从而建立性能优化 SOP 概念,以后出现问题即可参照优化流程改造即可。
性能调优也是有迹可寻的,本文梳理了在实际开发过程中沉淀的通用性能优化策略,并且结合风控系统服务内使用场景,帮助读者理解性能调优相关可行策略,从而建立性能优化 SOP 概念,以后出现问题即可参照优化流程改造即可。
引言
性能调优也是有迹可寻的,本文梳理了在实际开发过程中沉淀的通用性能优化策略,并且结合风控系统服务内使用场景,帮助读者理解性能调优相关可行策略,从而建立性能优化 SOP 概念,以后出现问题即可参照优化流程改造即可。
性能优化策略
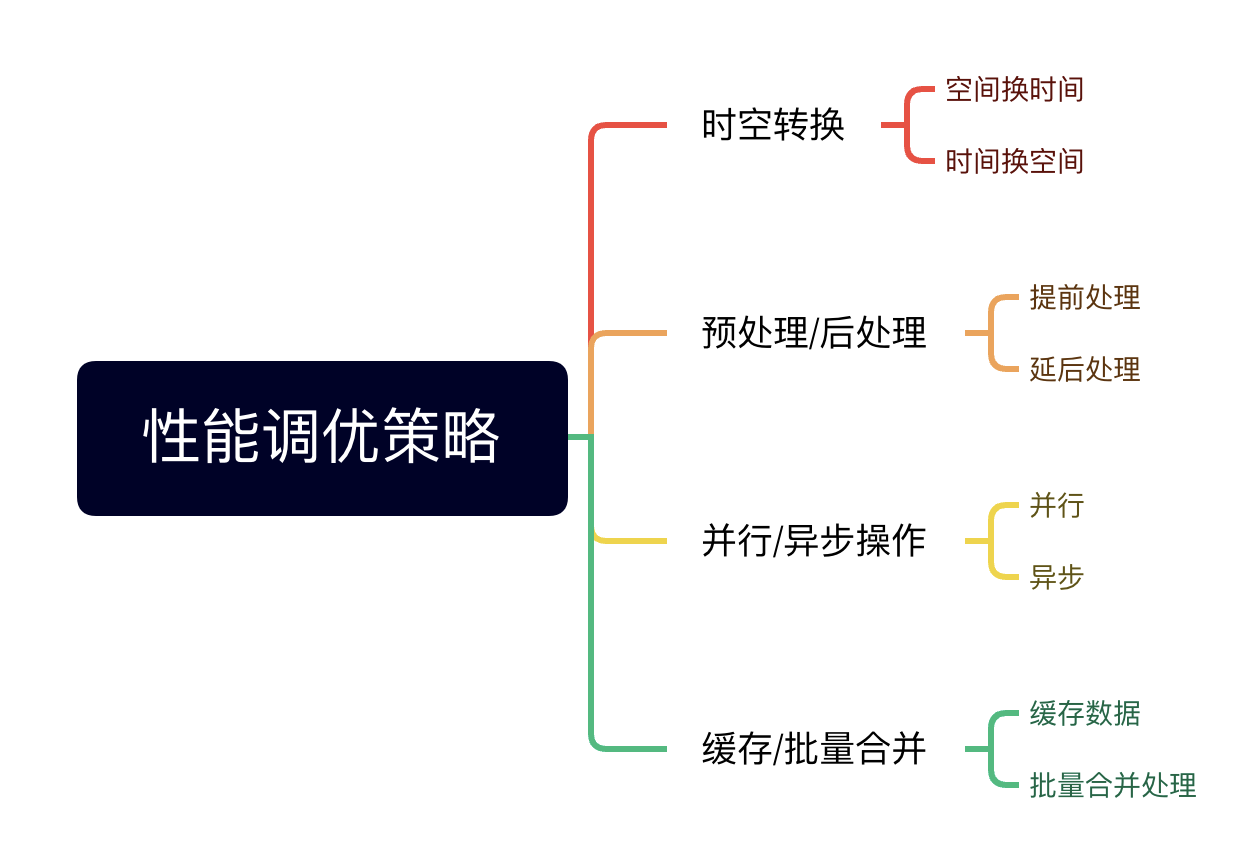
时空转换
刷过算法题目的都知道评分条件有:时间复杂度、空间复杂度,两样消耗都很小的话,评分越高,即优秀的算法。
但在实际开发过程中,一般二者不可兼得。要么占用空间小运行时间长一点,要么追求效率则占用空间就多一点。我们要做的就是在特定的需求场景中,极力优化其中的一方,此时往往需要牺牲另一方来达到目的。
空间换时间
在当前业务场景下,追求的是极致性能,即响应速度要足够快,比如开屏页的打开速度,如果每次打开 H5 都去服务端请求页面的渲染数据,再加上用户所在城市不同,从纽约用户访问北京,比北京本地用户访问肯定慢很多。那此时就有了 **CDN **这种工具。运营商的 CDN 节点遍布全球,页面在开发完毕后,直接推送到全球各地的 CDN 中缓存起来,这样用户访问时只需要命中最近的 CDN 节点,速度自然而然就上去了,但是付出了空间的成本。
在风控场景内也有类似场景,决策引擎为了极致性能,也需要空间换取时间:
- 配置数据缓存:决策流数据关联复杂,如果每次都去和 DB 或者数据中心交互,I/O 耗时大,得不偿失。本地缓存一道 + 更新触发反而是更好的选择。
- 短期缓存:热点信息且在一段时间内不会改变的(或者能容忍一段时间不变的),接入缓存会更利于查询速度。
时间换空间
此策略反其道而行,用时间换取空间。此时,“空间比较宝贵”,比如内存相对于磁盘来说就很宝贵,但是存放在磁盘内再调度起来使用时,需要一定的时间来获取。

在风控场景内,同样存在很多场景:
- 节省空间成本:“云上”服务器相对“云下”自建 IDC 机房是更贵的空间资源,所以风控将大量非实时的数据放在云下服务器计算,云上服务需要用的时候,需要付出一定的调用时间即可:跨机房调用(专线带宽争抢占用)需要额外多消耗 5~10 ms
- 设备指纹采集数据压缩上传:风控依赖设备指纹,设备指纹是内嵌在应用 APP 内采集机器本身信息的 SDK,大量的设备信息如果不压缩上传会占用很多带宽,影响占用了正常的用户请求。压缩后,节省了空间,但是付出的代价就是,每次都需要额外付出压缩/解压的耗时。
预处理/后处理
提前处理
预处理主要是为了提速。比如 CPU 和内存的预取操作,将内存中的指令和数据,提前存放到缓存中,从而加快执行的速度。
决策引擎为了保证策略的执行 RT 控制到 200ms 内,需要优化压缩执行策略的时间,假设一个策略再怎么优化,执行时间也是超过 200ms 的,那此时可以在上一个事件(场景)提前触发预处理操作。
举例:用户发单时需要判定群组风险,但访问群组是比较耗时,那可以在用户进入发单前先触发查询群组信息并缓住,真正发单时直接读取上次结果即可。同样的,我们可以在用户登录时触发一些操作,利于后续风控事件感知。
延后处理
不到必要时刻坚决不执行,节省成本。运用这一策略最有名的例子,就是 COW(Copy On Write,写时复制)。假设多个线程都想操作一份数据,一般情况下,每个线程可以自己拷贝一份,放到自己的空间里面。但是拷贝的操作很费时间。系统如果采用惰性处理,就会将拷贝的操作推迟。如果多个线程对这份数据只有读的请求,那么同一个数据资源是可以共享的,因为“读”的操作不会改变这份数据。当某个线程需要修改这一数据时(写操作),系统就将资源拷贝一份给该线程使用,允许改写,这样就不会影响别的线程。
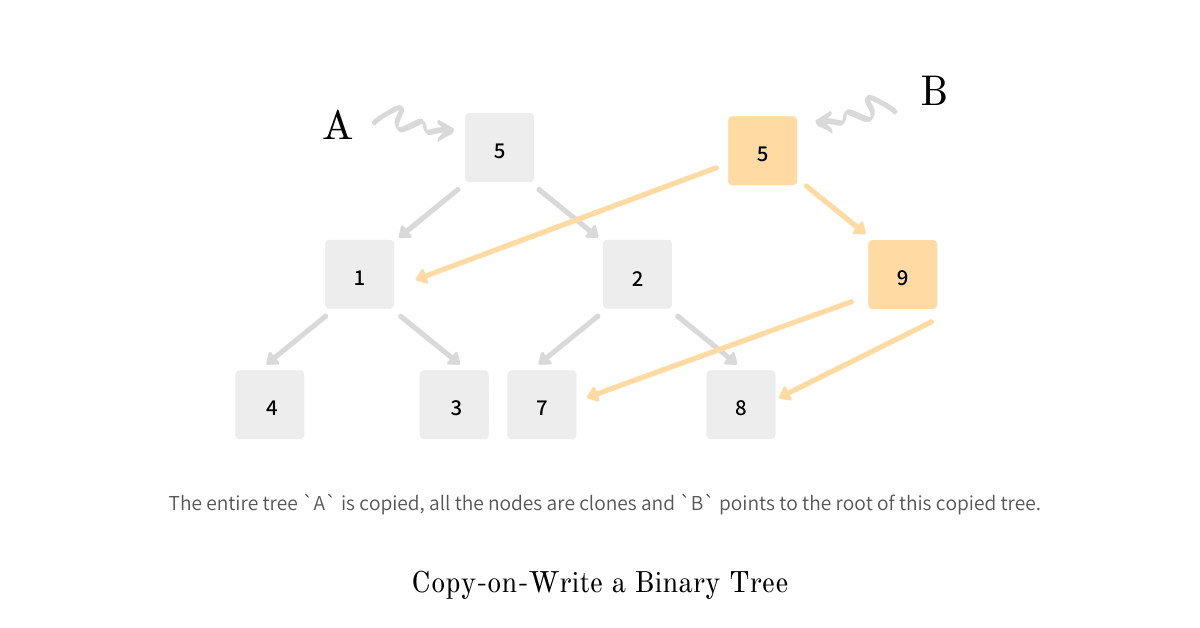
延后操作在风控中主要为了节省成本,决策引擎为了极致的性能,很多变量(或者叫特征/指标)都是一次性并行加载的,但此时有的变量是第三方收费指标,比如 IP、同盾、蚁盾等,预加载的好处显而易见,但是也极大的增加了成本:用户有可能还未走到付费变量决策节点时就被拒或者白名单直接通过,此时这部分用户提前请求三方就是极大的浪费。只有真正走到付费策略时,才会去请求,此时成本最小。
并行/异步操作
并行
一个人干不完的活,那就多找几个人一起干!并行操作,处理效率高(前提是机器多核心),时间大大缩短,极大缩短了 RT 时间。绝大多数互联网服务器,要么使用多进程,要么使用多线程来处理用户的请求,以充分利用多核 CPU。另外一种情况就是在有 IO 阻塞的地方,也是非常适合使用多线程并行操作的,因为这种情况 CPU 基本上是空闲状态,多线程可以让 CPU 多干点活。
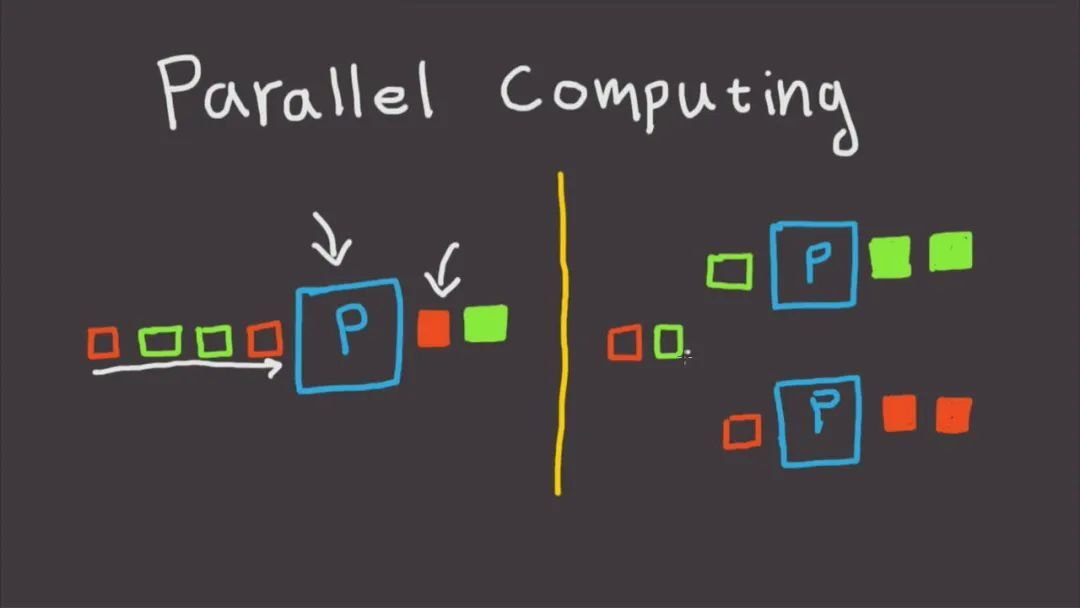
决策引擎如果执行策略都是同步执行的话,几分钟可能都执行不完,运用并行,充分发挥 CPU 多个核心的性能,那么此时性能瓶颈就是最长的那块木板,只要专攻优化它就好了。
异步
异步相对同步来说,就是是否等待结果还是立即返回。同步操作在碰到内部有大量 I/O 操作时,性能损耗极大,此时采用异步操作,系统的吞吐行会有极大的提升。但是有利有弊,异步操作也增加了程序的复杂度,需要考虑失败补偿等额外的操作。
此类场景在风控系统中也是随处可见:
- MQ 消息:天然的异步处理,依托于消息消费机制削峰填谷特性,在大耗时操作动作,且业务不需要同步返回情况下,非常适合用消息来处理,比如离线决策。
- 埋点、监控采样:不在业务关心的流程内发起的操作,为了不影响 RT,需要将额外的操作异步处理。
缓存/批量合并
数据缓存
缓存的目的就是为了加速,这个我们从学习程序语言开始就基本达成的共识,基本上各个系统内只要有性能考虑的,多少都会用到缓存。我们常用的一些工具,也穿插了缓存的影子,比如:
- IOC 控制反转:不仅仅是依赖注入,同时也节省了创建 bean 的时间
- 线程池中活跃线程:池化概念目的是增速,池本身就是一个缓存容器,频繁的创建池内对象,得不偿失,此时固定一批在池内,用完即还,极大的避免了创建新对象的开销。

批量合并处理
批操作一般是遇到 I/O 操作时才会使用,一次性尽量多的查询到多的数据,减少网络耗时时间(注意,这不是绝对,思考一下为何需要分页,在时间和空间找平衡)。
常见批操作如下:
- 数据库查询批处理:在处理多条数据时一次性 in 查询出来,避免频繁的单条循环查询
- redis 扫描数据:可以使用 scan 类命令,而不是频繁的 get (注:会造成 redis hold 住,需要平衡 key 的个数)
总结
性能调优可以有多种手段,有时从不同的角度,能发挥奇效,当然前提是得在业务可接受的成本内,不考虑实际是不切实际的。
如上介绍的性能调优策略,这些是在日常开发过程中总结思考沉淀的,希望能够帮助读者建立一个性能优化 SOP,能有通用的摸排手段,做到用时心中有数。
往期精彩
欢迎关注公众号:咕咕鸡技术专栏
个人技术博客:https://jifuwei.github.io/

参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号