scrapy使用
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 在spiders目录下,生成爬虫

- 编辑这个爬虫文件
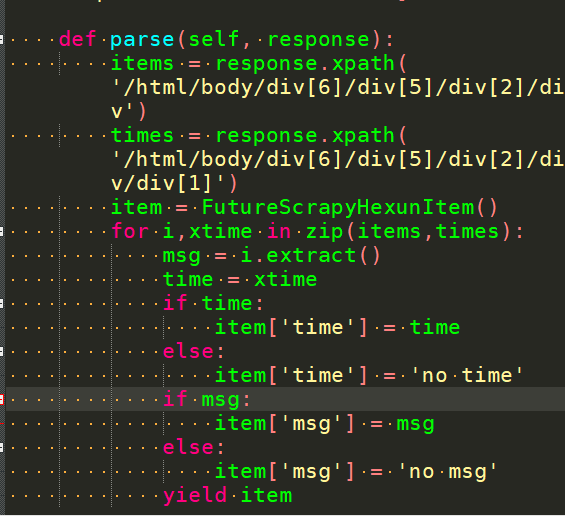
-
记得修改settings.py文件
-
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5514.400 QQBrowser/10.1.1660.400'
2
# Obey robots.txt rules
#不遵守机器人规则 有些它不让去的我们也要去
ROBOTSTXT_OBEY = False
3
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = {
'cls.pipelines.ClsPipeline': 300,
}
-
-
- 在spiders目录下,生成爬虫
- 存储内容 (pipelines.py):设计管道存储爬取内容
- 往mongodb数据库存

- 往mongodb数据库存

